
Logstore中的时序数据通过SPL指令处理后,可以调用时序SPL函数进行结果可视化。
函数列表
函数名称 | 说明 |
函数名称 | 说明 |
时间转换函数:将秒级时间戳转为纳秒级,适用于高精度场景。 | |
时间序列预测函数:基于历史数据预测未来趋势,适用于监控、分析和规划。 | |
异常检测函数:基于机器学习算法,识别时间序列中的异常点或异常模式,适用于监控、告警和数据分析等场景。 | |
时间序列分解与异常检测函数:基于时间序列分解算法,将原始数据拆分为趋势、季节性和残差分量,并通过统计方法分析残差分量以识别异常点,适用于实时监控、根因分析及数据质量检测等场景。 | |
用于时间序列分析的下钻函数,允许在时间分组统计的基础上,进一步对特定时间段内的数据进行细粒度分析。 |
second_to_nano函数
时间转换函数,用于将秒级时间戳转换为纳秒级时间戳。它通常用于处理日志中的时间字段,尤其是在需要更高精度时间戳的场景下。
精度:确保数据库和应用程序支持足够的精度,以处理纳秒级别的时间数据。
数据类型:需要选择合适的数据类型来存储纳秒级的数据,比如
BIGINT,以避免溢出或精度丢失。
语法
second_to_nano(seconds)参数说明
参数 | 说明 |
参数 | 说明 |
seconds | 秒级时间戳(可以是整数或浮点数)。 |
返回值
返回对应的纳秒级时间戳(以整数形式表示)。
示例
统计不同时间段(纳秒级)不同请求的数量。
查询分析语句
* | extend ts = second_to_nano(__time__) | stats count=count(*) by ts,request_method输出结果
series_forecast函数
用于时间序列预测。它基于历史时间序列数据,利用机器学习算法对未来的时间点进行预测。该函数常用于监控、趋势分析和容量规划等场景。
使用限制
已经通过make-series构造出series格式数据,并且时间单位为纳秒。
每行的时间点数量至少为31个 。
语法
series_forecast(array(T) field, bigint periods)或
series_forecast(array(T) field, bigint periods, varchar params)参数说明
参数 | 说明 |
参数 | 说明 |
field | 输入时间序列的指标列。 |
periods | 期望预测结果中时间点的数量。 |
params | 可选。算法参数,json 格式。 |
返回值
row(
time_series array(bigint),
metric_series array(double),
forecast_metric_series array(double),
forecast_metric_upper_series array(double),
forecast_metric_lower_series array(double),
forecast_start_index bigint,
forecast_length bigint,
error_msg varchar)列名 | 类型 | 说明 |
列名 | 类型 | 说明 |
time_series | array(bigint) | 纳秒级时间戳数组。包含输入时间段的时间戳和预测时间段的时间戳。 |
metric_series | array(double) | metric 数组,长度和 time_series 一致。 对原始输入 metric 进行修改(修改 NaN 等)并用 NaN 扩充预测时间段。 |
forecast_metric_series | array(double) | 预测结果数组,长度和 time_series 一致。 包含对输入 metric 的拟合值以及预测时间段的预测值。 |
forecast_metric_upper_series | array(double) | 预测结果上界数组,长度和 time_series 一致。 |
forecast_metric_lower_series | array(double) | 预测结果下界数组,长度和 time_series 一致。 |
forecast_start_index | bigint | 表示时间戳数组中预测时间段的起始下标。 |
forecast_length | bigint | 表示时间戳数组中预测时间段时间点的数量。 |
error_msg | varchar | 错误信息。为 null 则表示该行时间序列预测成功,否则展示失败原因。 |
示例
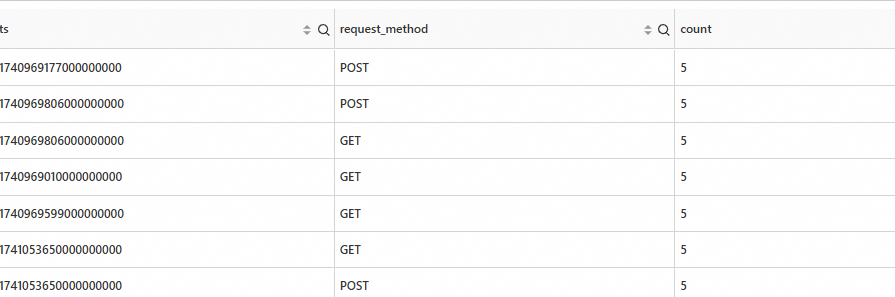
统计不同request_method接下来10个时间点的数量。
SPL语句
* | extend ts = second_to_nano(__time__ - __time__ % 60) | stats latency_avg = max(cast(status as double)), inflow_avg = min(cast (status as double)) by ts, request_method | make-series latency_avg default = 'last', inflow_avg default = 'last' on ts from 'min' to 'max' step '1m' by request_method | extend test=series_forecast(inflow_avg, 10)输出结果

算法参数
"pred":"10min" | 期望预测结果中时间点的间隔, 单位支持 |
"uncertainty_config": {"interval_width": 0.9999} |
|
"seasonality_config": {"seasons": [{"name": "month", "period": 30.5, "fourier_order": 1}]} |
|
series_pattern_anomalies函数
用于检测时间序列数据中异常模式。它基于机器学习算法,能够自动识别时间序列中的异常点或异常模式,适用于监控、告警和数据分析等场景。
使用限制
已经通过make-series构造出series格式数据,并且时间单位为纳秒。
每行的时间点数量至少为11个 。
语法
series_pattern_anomalies(array(T) metric_series)参数说明
参数 | 说明 |
参数 | 说明 |
metric_series | 输入时间序列的指标列,仅支持数值类型。 |
返回值
row(
anomalies_score_series array(double),
anomalies_type_series array(varchar)
error_msg varchar)
) 列名 | 类型 | 说明 |
列名 | 类型 | 说明 |
anomalies_score_series | array(double) | 异常分数序列,与输入时间序列相对应。范围为 [0,1] 代表每个时间点的异常分数。 |
anomalies_type_series | array(varchar) | 异常类型描述序列,与输入时间序列相对应。代表每个时间点的异常类型。非异常的时间点表示为null。 |
error_msg | varchar | 错误信息。值为null则表示该行时间序列异常检测成功,否则展示失败原因。 |
示例
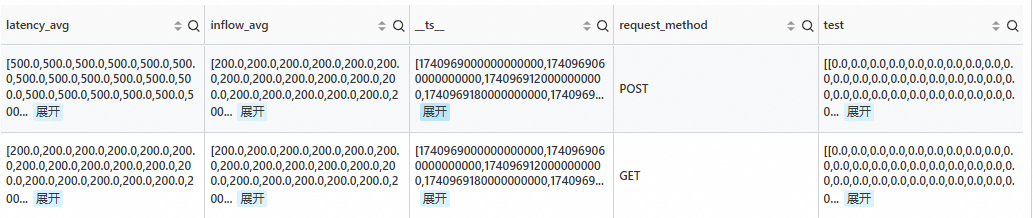
检测当前时间点的序列是否有异常。
SPL语句
* | extend ts = second_to_nano(__time__ - __time__ % 60) | stats latency_avg = max(cast(status as double)), inflow_avg = min(cast (status as double)) by ts, request_method | where request_method is not null | make-series latency_avg default = 'last', inflow_avg default = 'last' on ts from 'min' to 'max' step '1m' by request_method | extend test=series_pattern_anomalies(inflow_avg)输出结果
series_decompose_anomalies函数
用于时间序列分解和异常检测的函数。它基于时间序列分解算法,将原始时间序列数据拆分为趋势分量、季节性分量和残差分量,并通过分析残差分量来检测异常点。
使用限制
已经通过make-series构造出series格式数据,并且时间单位为纳秒。
每行的时间点数量至少为11个 。
语法
series_decompose_anomalies(array(T) metric_series)或
series_decompose_anomalies(array(T) metric_series, varchar params)参数说明
参数 | 说明 |
参数 | 说明 |
metric_series | 输入时间序列的指标列。 |
params | 可选。算法参数,json 格式。 |
返回值
row(
metric_baseline_series array(double)
anomalies_score_series array(double),
anomalies_type_series array(varchar)
error_msg varchar)
) 列名 | 类型 | 说明 |
列名 | 类型 | 说明 |
metric_baseline_series | array(double) | 算法拟合的 metric 数据。 |
anomalies_score_series | array(double) | 异常分数序列,与输入时间序列相对应。范围为 [0,1] 代表每个时间点的异常分数。 |
anomalies_type_series | array(varchar) | 异常类型描述序列,与输入时间序列相对应。代表每个时间点的异常类型。非异常的时间点表示为 null。 |
error_msg | varchar | 错误信息。值为null则表示该行时间序列异常检测成功,否则展示失败原因。 |
示例
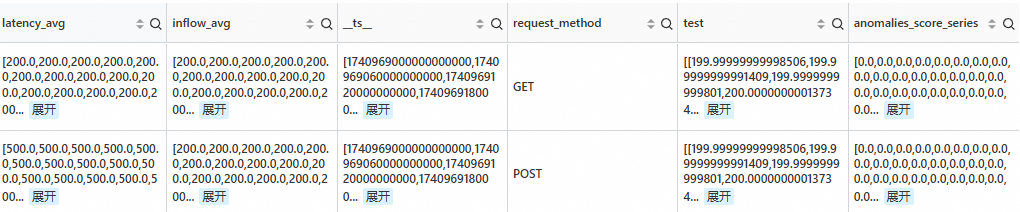
对所有时间线异常检测之后,保留最近 5 min 异常分数值大于等于0的时间线。
SPL语句
* | extend ts = second_to_nano(__time__ - __time__ % 60) | stats latency_avg = max(cast(status as double)), inflow_avg = min(cast (status as double)) by ts, request_method | where request_method is not null | make-series latency_avg default = 'last', inflow_avg default = 'last' on ts from 'min' to 'max' step '1m' by request_method | extend test=series_decompose_anomalies(inflow_avg, '{"confidence":"0.005"}') | extend anomalies_score_series = test.anomalies_score_series | where array_max(slice(anomalies_score_series, -5, 5)) >= 0输出结果
算法参数
参数 | 类型 | 示例 | 描述 |
参数 | 类型 | 示例 | 描述 |
auto_period | string | "true" | 只能设置 "true" 或 "false"。表示是否开启时序周期自动检测。如果设置为 "true",自定义的 period_num 和 period_unit 不生效。 |
period_num | string | "[1440]" | 序列周期包含多少个时间点。可以输入多个周期长度,目前服务只考虑长度最长的一个周期。 |
period_unit | string | "[\"min\"]" | 序列周期的每个时间点的时间单位。可以输入多个时间单位,时间单位的数量必须和设置的周期的数量相同。 |
period_config | string | "{\"cpu_util\": {\"auto_period\":\"true\", \"period_num\":\"720\", \"period_unit\":\"min\"}}" | 如果需要针对不同的特征设置不同的周期,可以配置 period_config 字段,prediod_config 中的字段名为要设置的特征的名称,字段值为 object,在其中设置 auto_period,period_num,period_unit 三个字段。 |
trend_sampling_step | string | "8" | 时序分解时对于趋势成分的下采样率,需要可以转换成正整数。采样率越大,趋势成分的拟合速度越快,趋势成分的拟合精度会降低。默认为 "1"。 |
season_sampling_step | string | "1" | 时序分解时对于周期成分的下采样率,需要可以转换成正整数。采样率越大,周期成分的拟合速度越快,周期成分的拟合精度降低,默认为 "1"。 |
batch_size | string | "2880" | 异常分析时使用滑动窗口的形式分段处理。batch_size 表示窗口的大小。窗口越小,分析的速度越快,准确度可能会降低。默认窗口的大小与序列的长度一致。 |
confidence | string | "0.005" | 异常分析的敏感度,需要可以转换成浮点数,取值范围是(0,1.0)。数值越小,算法对异常的敏感度越低,检测到的异常数量减少。 |
confidence_trend | string | "0.005" | 在分析趋势项时,对于异常的敏感度。设置该参数后自动忽略 confidence。数值越小,算法对于趋势项的异常的敏感度越低,趋势项检测到的异常数量减少。 |
confidence_noise | string | "0.005" | 在分析残差项时,对于异常的敏感度。设置该参数后自动忽略 confidence。数值越小,算法对于残差项的异常的敏感度越低,残差项检测到的异常数量减少。 |
series_drilldown函数
用于时间序列分析的下钻函数,允许在时间分组统计的基础上,进一步对特定时间段内的数据进行细粒度分析。
语法
series_drilldown(array(varchar) label_0_array,array(varchar) label_1_array,array(varchar) label_2_array, ... ,array(array(bigint)) time_series_array,array(array(double)) metric_series_array,bigint begin_time,bigint end_time)或
series_drilldown(array(varchar) label_0_array,array(varchar) label_1_array,array(varchar) label_2_array, ... ,array(array(bigint)) time_series_array,array(array(double)) metric_series_array,bigint begin_time,bigint end_time,varchar config)参数说明
参数 | 说明 |
参数 | 说明 |
label_x_array | 数组中每个元素为对应时间序列的label。函数重载最多支持 7 个 label array。 |
time_series_array | 外层数组中每个元素为一个 time series。 |
metric_sereis_array | 外层数组中每个元素为一个 metric series |
begin_time | 需要进行根因下探的开始时间点,一般设置为异常的开始时间,单位为纳秒。 |
end_time | 需要进行根因下探的结束时间点,一般设置为异常的结束时间,单位为纳秒。 |
config | 可选。算法参数,json 格式。 |
返回值
row(dirlldown_result varchar, error_msg varchar)列名 | 类型 | 说明 |
列名 | 类型 | 说明 |
dirlldown_result | varchar | 下探的结果,JSON格式。 |
error_msg | varchar | 错误信息。为 null 则表示该行时间序列预测成功,否则展示失败原因。 |
示例
SPL语句
* | extend ts= (__time__- __time__%60)*1000000000 | stats access_count = count(1) by ts, Method, ProjectName | extend access_count = cast( access_count as double) | make-series access_count = access_count default = 'null' on ts from 'sls_begin_time' to 'sls_end_time' step '1m' by Method, ProjectName | stats m_arr = array_agg(Method), ProjectName = array_agg(ProjectName), ts_arr = array_agg(__ts__), metrics_arr = array_agg(access_count) | extend ret = series_drilldown(ARRAY['Method', 'Project'], m_arr, ProjectName, ts_arr, metrics_arr, 1739192700000000000, 1739193000000000000, '{"fill_na": "1", "gap_size": "3"}') | project ret输出结果

- 本页导读 (1)
- 函数列表
- second_to_nano函数
- 语法
- 参数说明
- 返回值
- 示例
- series_forecast函数
- 使用限制
- 语法
- 参数说明
- 返回值
- 示例
- series_pattern_anomalies函数
- 使用限制
- 语法
- 参数说明
- 返回值
- 示例
- series_decompose_anomalies函数
- 使用限制
- 语法
- 参数说明
- 返回值
- 示例
- 算法参数
- series_drilldown函数
- 语法
- 参数说明
- 返回值
- 示例
