
本文以Pytorch训练场景和vLLM推理场景为例,对在ACK集群中运行的GPU容器的AI Profiling检测结果进行分析,重点阐述如何通过在线性能检测结果的可视化页面,分析Python进程、CPU调用、系统调用、CUDA库和CUDA核函数的执行过程,定位性能瓶颈,找到性能调优方向,从而提升GPU利用率和应用效率。
Pytorch训练示例
示例环境
框架:Pytorch 2.6.0
模型:ResNet18
数据:Cifar10
GPU:NVIDIA A10
Profiling时长:5s
开启Profiling项:all
结果分析
观察GPU函数调用的时间占比:以下示例中,可以发现整体的GPU繁忙时间,包括核函数执行(cuda_runtime和Kernel)、显存操作(Memset)以及CUDA同步(cuda_sync)占比并不高,且核函数执行时间的占比符合预期。
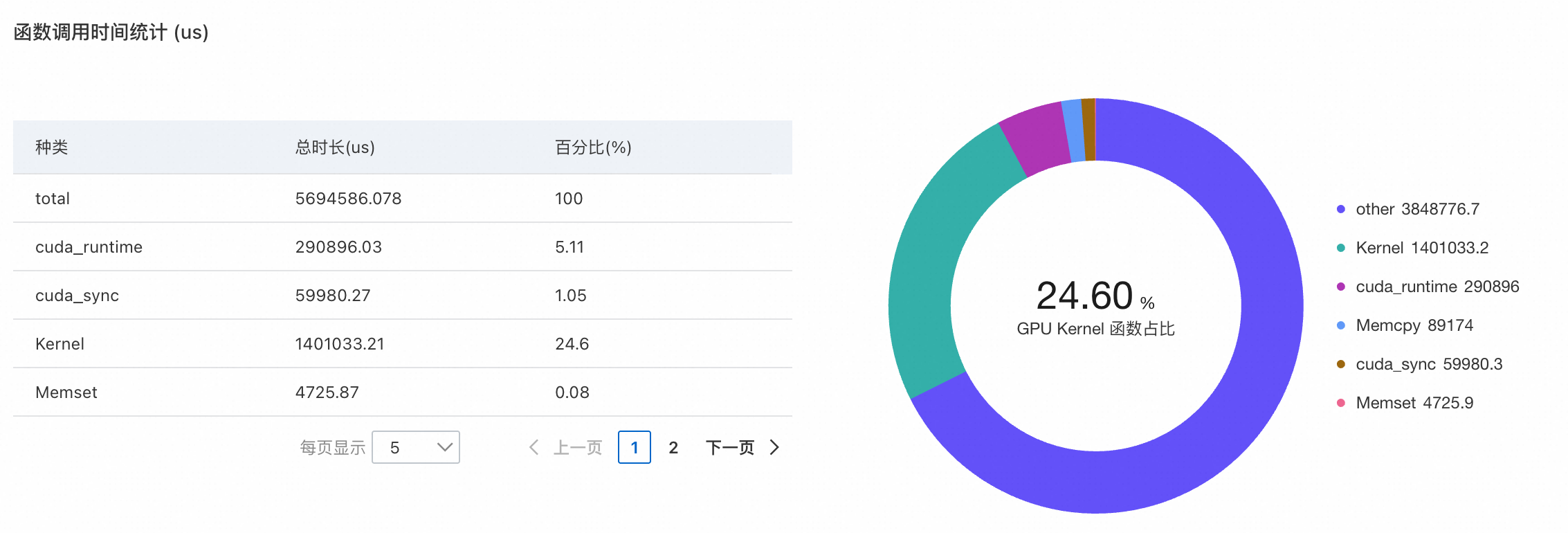
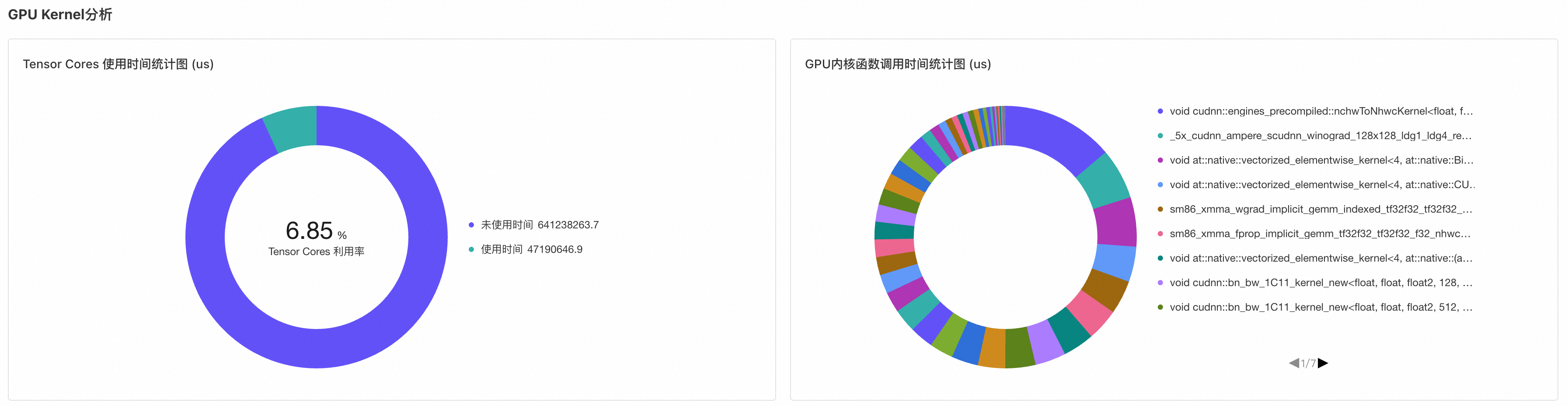
观测GPU核函数的分布:在本示例中,核函数主要运行在非Tensor Core上,导致Tensor Core的利用率较低。同时,主要执行的核函数集中在cuDNN、cuBLAS等向量运算中,如矩阵乘法等。这些细节可用于评估自定义CUDA核函数的性能优劣。

分析TimeLine:具体分析一个训练步骤,包括数据加载、前向传播、后向传播和优化器更新。在各个步骤的交界处做标记,Python部分的TimeLine如下,可以清晰地分辨各个部分的执行情况。
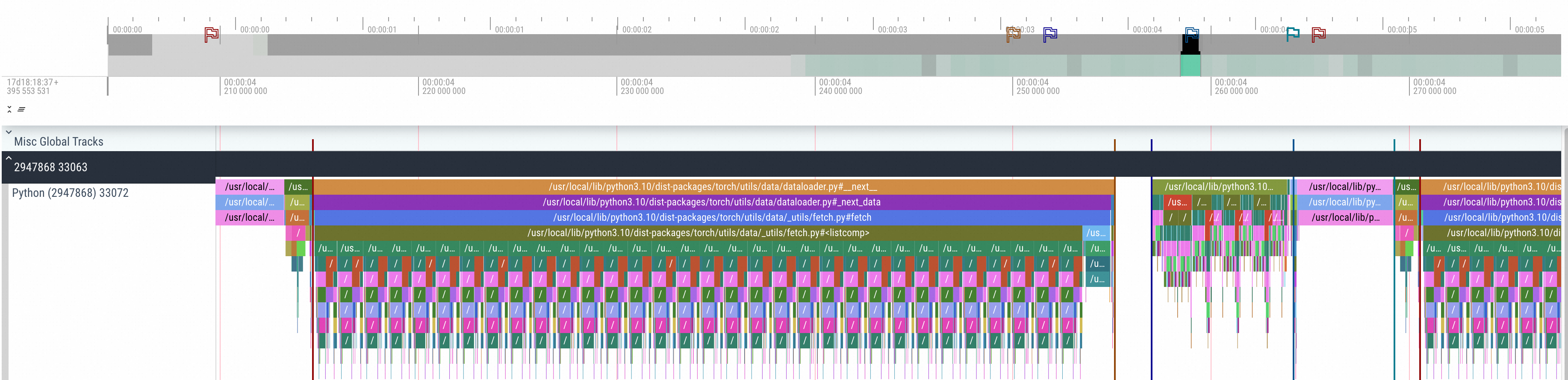
通过上图可以明显观测到在整个TimeLine上,DataLoad的时间占比高于其他步骤,而在DataLoad上还有一段空白的时间。进一步观测CUDA核函数的部分,可以清晰地发现,在DataLoad开始的前半段,上一个Step的Optimizer更新的核函数还在执行。DataLoad结束后开始进行数据的传输(cuMemCpyH2D),将加载的数据从Host传输到GPU Device上。数据传输结束后基于不同阶段进行相应的计算。

通过分析,我们可以总结出提高整体GPU利用率的关键措施主要包括以下几个方面:
优化数据加载:
增加Dataloader个数。
Dataloader开启Pin Memory。
设置数据加载和计算重叠。
提升GPU利用率:
自动混合精度。
增大Batch Size。
vLLM推理示例
示例环境
框架:vLLM 0.5.0
模型:Qwen2-7B
GPU:NVIDIA A10
Profiling时长:5s
开启Profiling项:all
结果分析
模型加载
查看模型加载的整体流程:放大视图可以清晰地看到整个模型的加载过程分为三个步骤:数据读取、数据拷贝和Decoding。

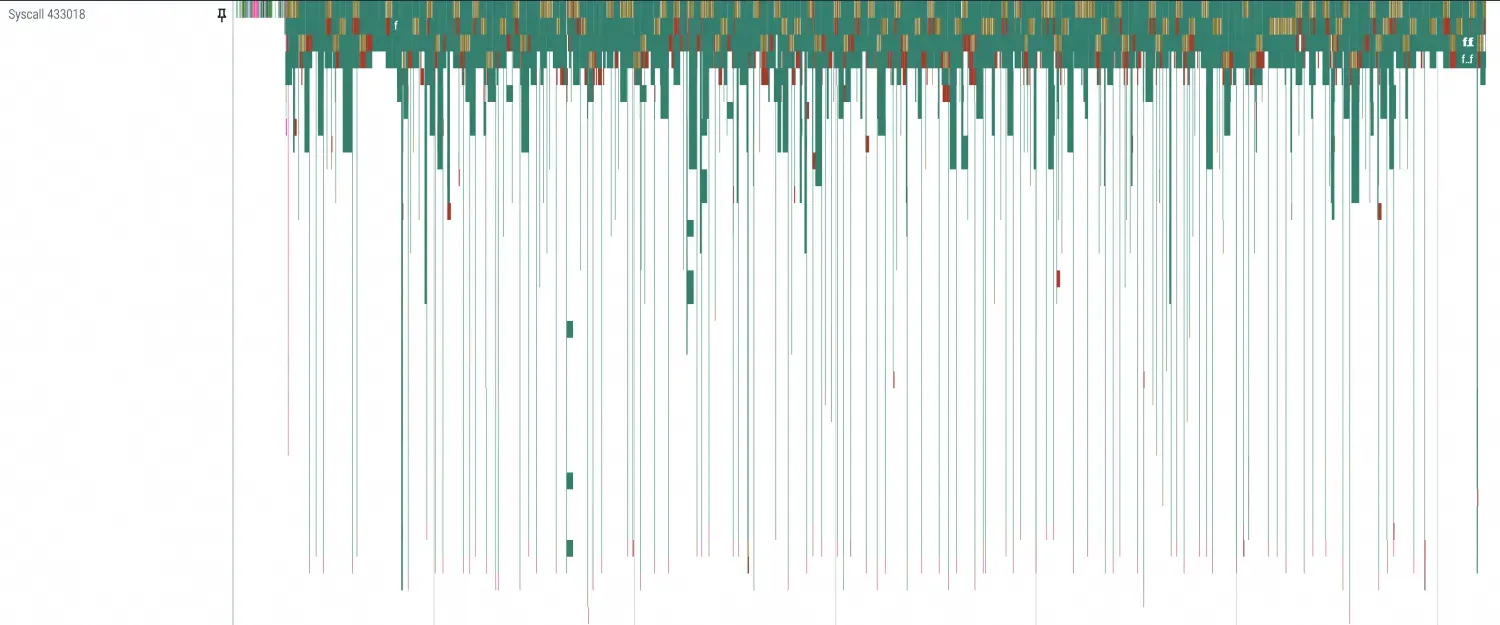 在Python profiling中可以用分隔线将其各个阶段分隔开,如下图所示。由于该示例为首次启动,因此未使用PageCache,数据传输所占用的时间显得尤为明显。
在Python profiling中可以用分隔线将其各个阶段分隔开,如下图所示。由于该示例为首次启动,因此未使用PageCache,数据传输所占用的时间显得尤为明显。
分别查看各个阶段的Profiling项效果:放大视图可以看到主要区别集中在这几个系统调用中(openat、mmap、read、ioctl),都是与 I/O 相关的操作。由于读取模型时主要使用
safetensors.torch.load_file随机读取,因此会频繁出现mmap和read的调用。
通过数据传输过程可以看到系统调用主要集中在poll、epoll、futex中,同时CPU也在频繁地使用多核和核的切换,CUDA调用方面则是进行了和模型safetensor数量相同的cuMemcpyHtoD的传输。因此,可以结合vLLM的模型加载过程判断出模型数据传输大概的路径(磁盘或者网络 -> 内存(PageCache) -> GPU显存)。后续在图中补充网络和磁盘IO的数据就可以更加清晰地观察。

观察Decoding的过程,重点关注GPU相关库的调用:每个批次中执行的矩阵乘法及其上下游调用(如 cuLaunchKernel、cuMemcpyDtoD、cublasGemmEx)呈现得较为规律,都能和对应Python的Decoding方法进行对齐,所以也是可以较为明显的分出其所代表的阶段。

模型推理
本示例通过手动模拟的NCCL-Hang来展示问题的发现与推测过程。
由于NCCL Hang通常表现为陷入内核态或NCCL层面的通信/O阻塞,因此可以通过模拟不同进程间的NCCL通信中断来重现场景。使用以下命令分别进行进程的挂起和恢复,模拟NCCL的中断和恢复过程。
kill -STOP <PID> kill -CONT <PID>正常无中断的推理时长:

开启了5s中断的推理时长:

在进程被主动中断的过程中,可以通过观察以上现象得知,Demo示例每次推理大约需要15s左右,然后模拟中断了5s左右,最终恢复后推理请求的总时长变为了20s左右,符合设定预期。
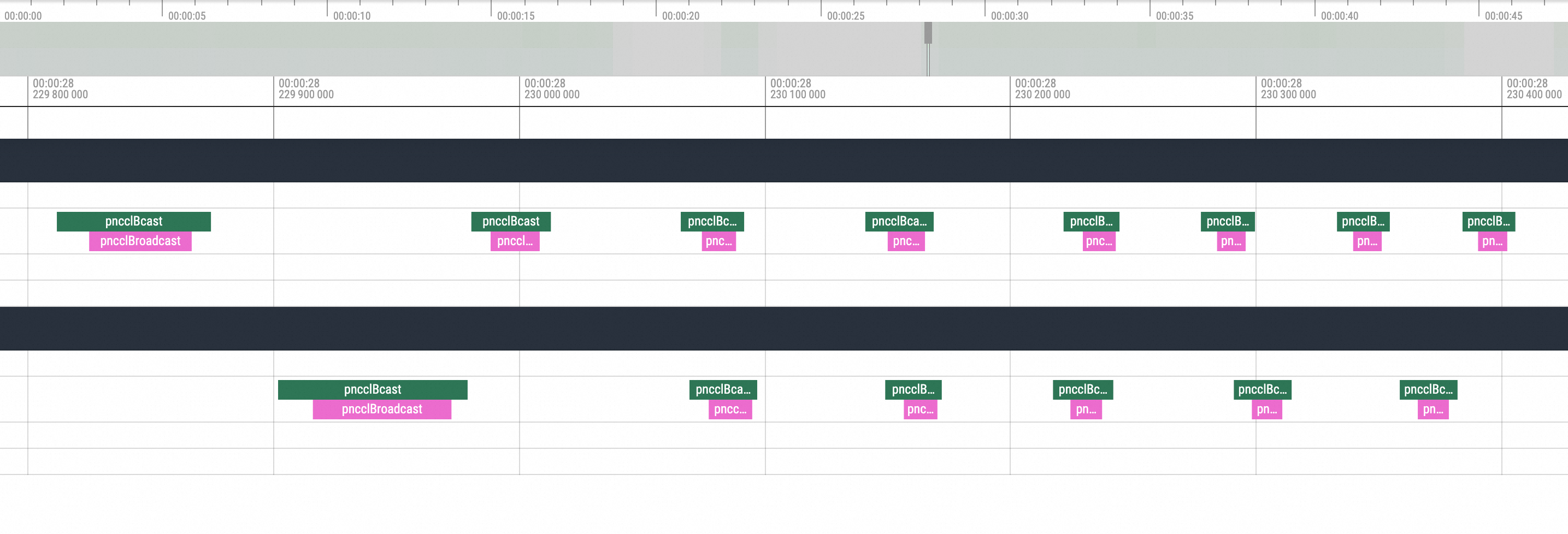
经过观察,vLLM的每一次推理过程是由多个推理计算的部分组成,如下图红框部分,大致流程为
cuda memory copy H2D -> nccl broadcast -> cublas compute -> nccl send and recv -> cuda memory copy D2H。所以NCCL可能中断的点为broadcast和send and recv的过程。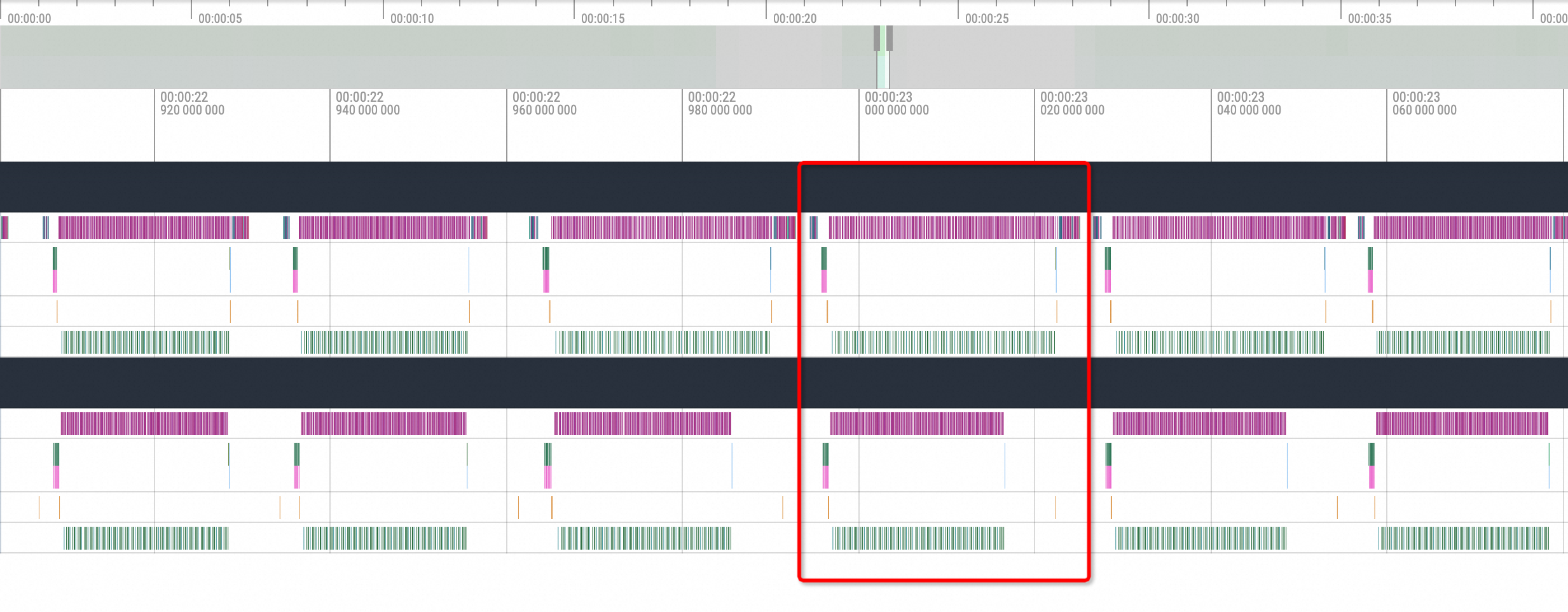
中断时间点决定了阻塞的NCCL动作,开启60s仅GPU的Profiling,并将Profiling出的数据转换为Chrome Tracing的格式化数据,介绍两种NCCL被阻塞的情况:
nccl send and recv可视化结果如下所示:
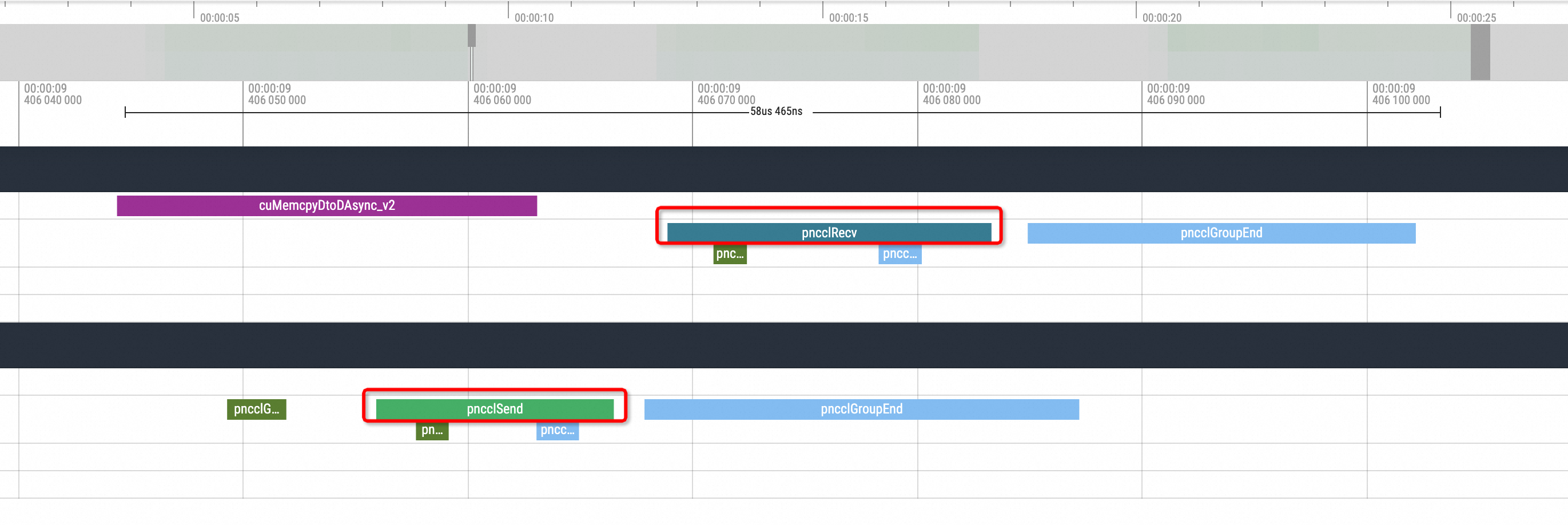
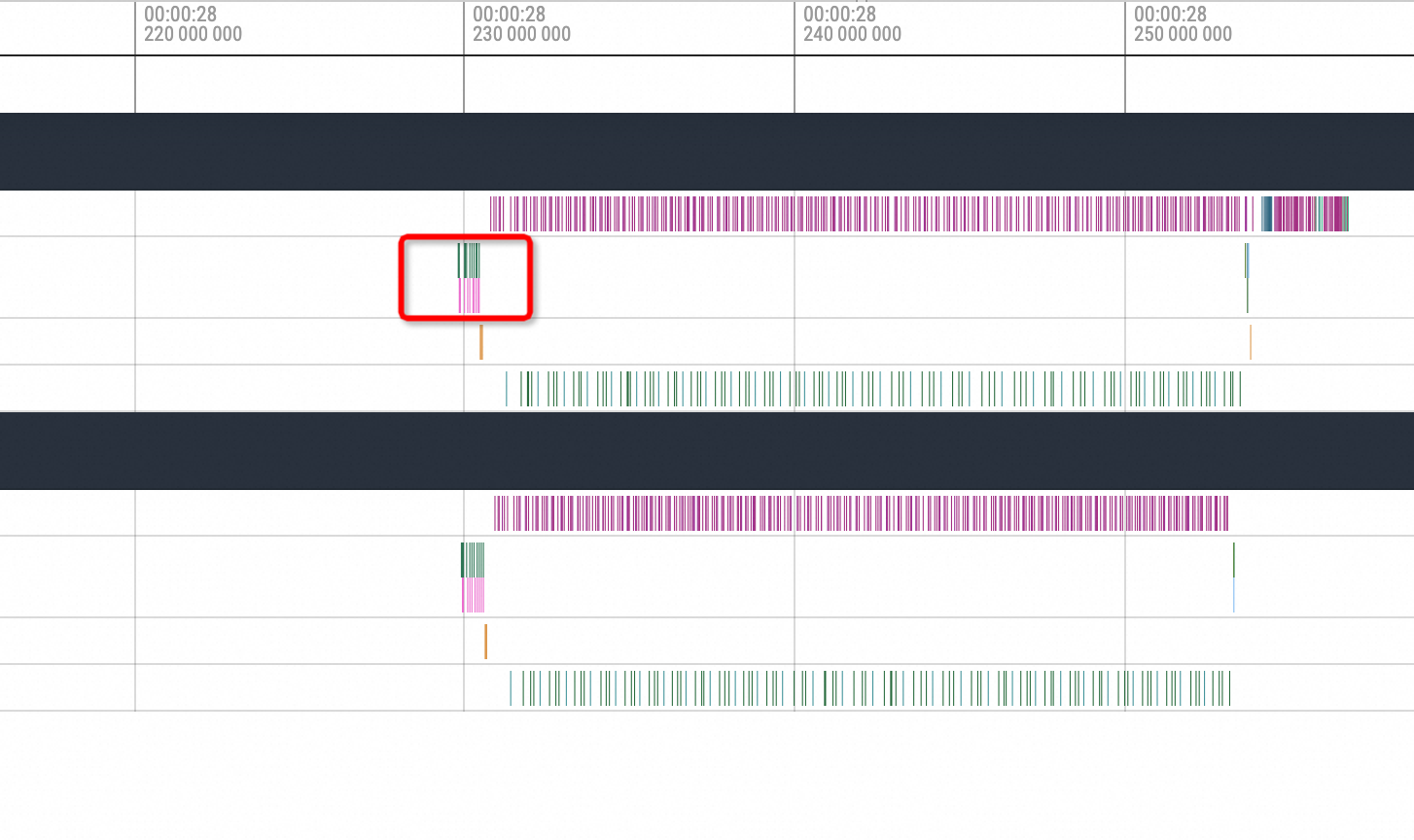
首先看正常情况,在一次推理的结尾的时间内通常在其中一个副本会有一次pnccl Send,另一个副本会有一次相对应的pnccl Recv。而在开启了NCCL Hang模拟的情况下,可以看到Profiling视图会出现如下的情况:
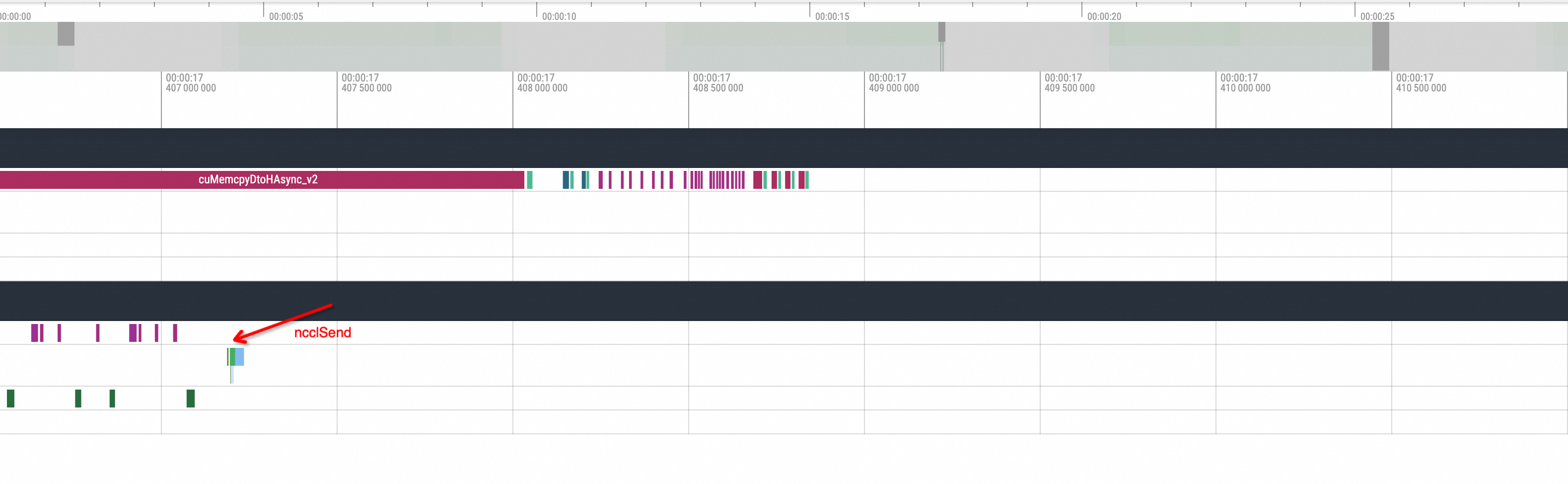
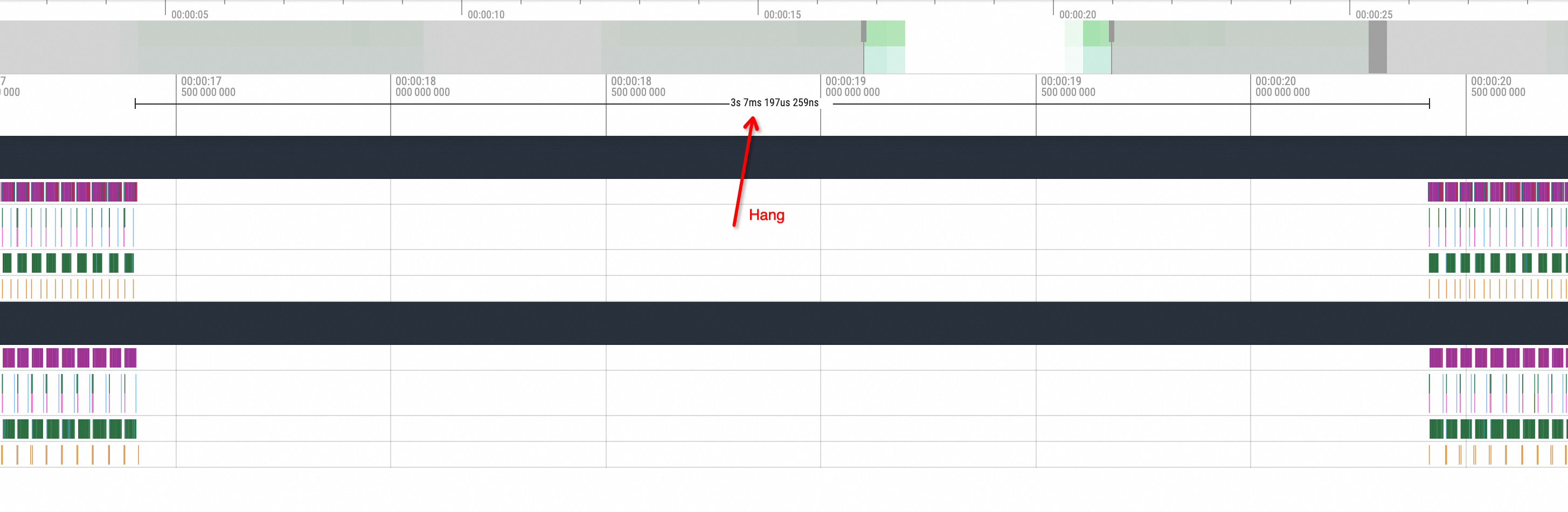
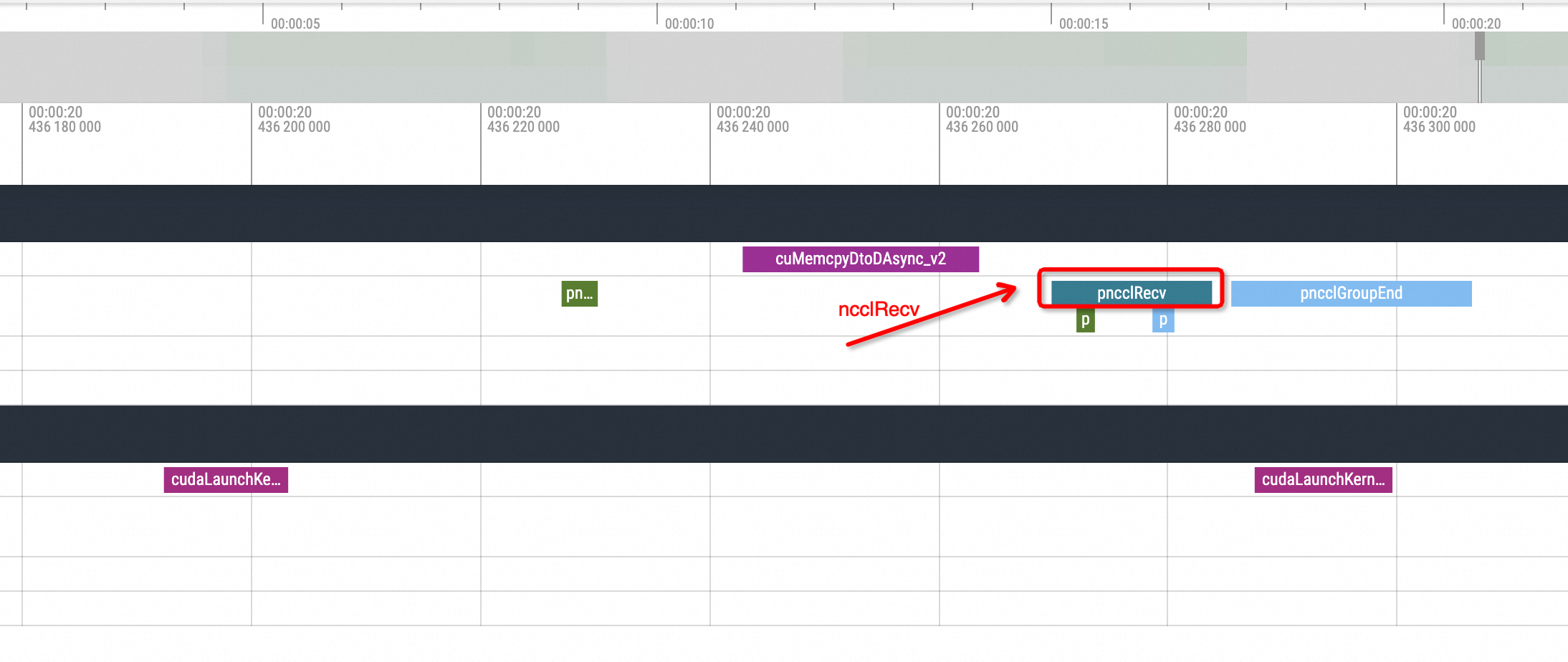
即其中的一个副本在发出ncclSend调用后,另一个副本没有与之对应的ncclRecv动作调用发生,整个GPU相关方法的调用进入了一段时间的空闲状态。等待进程状态恢复后另一个副本才执行了对应的ncclRecv动作,所以在不知道其底层逻辑的情况下,大致可以推测为NCCL Hang的问题导致了这一现象。
nccl broadcast以下是在
nccl broadcast之前执行Hang操作的效果图: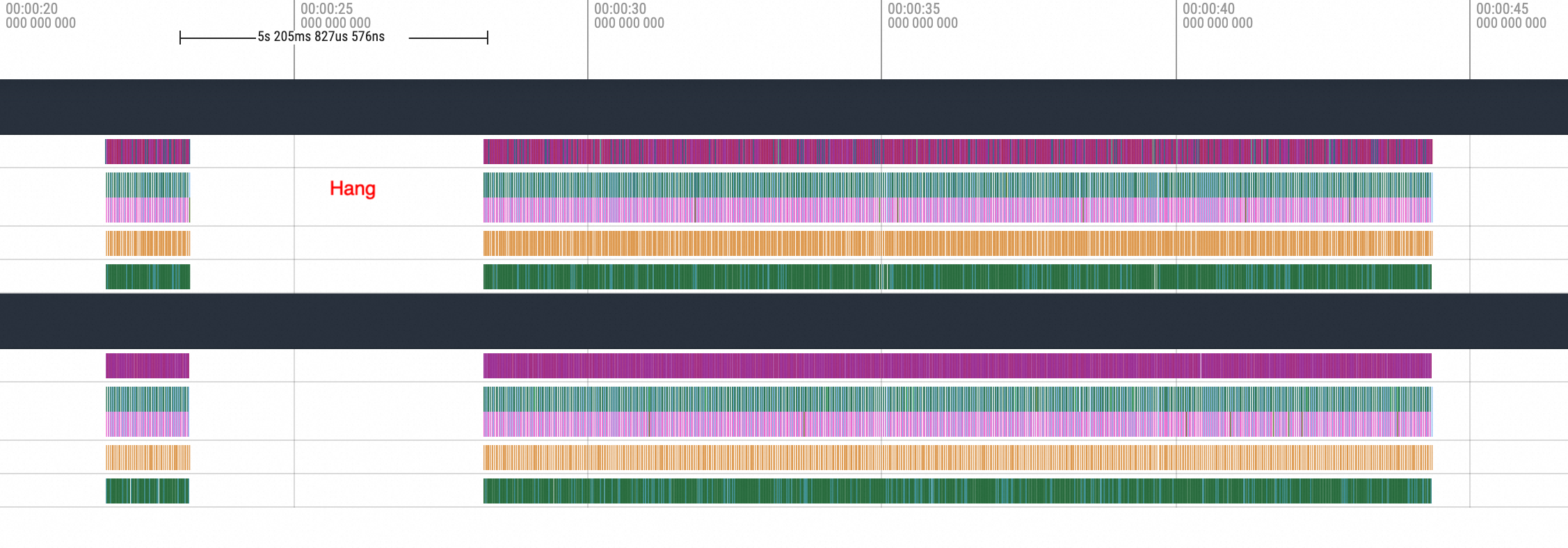
Zoom In到Hang之前所执行的方法。
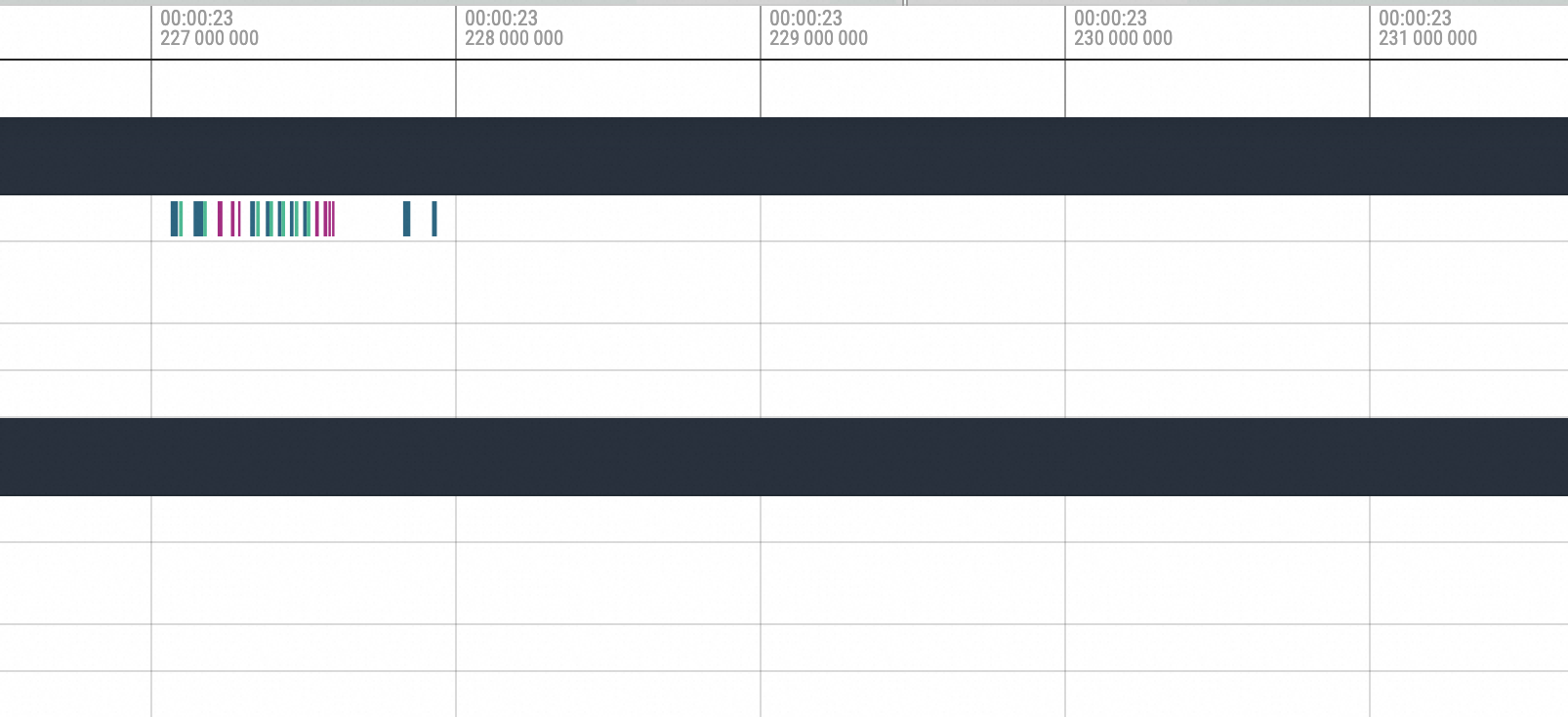
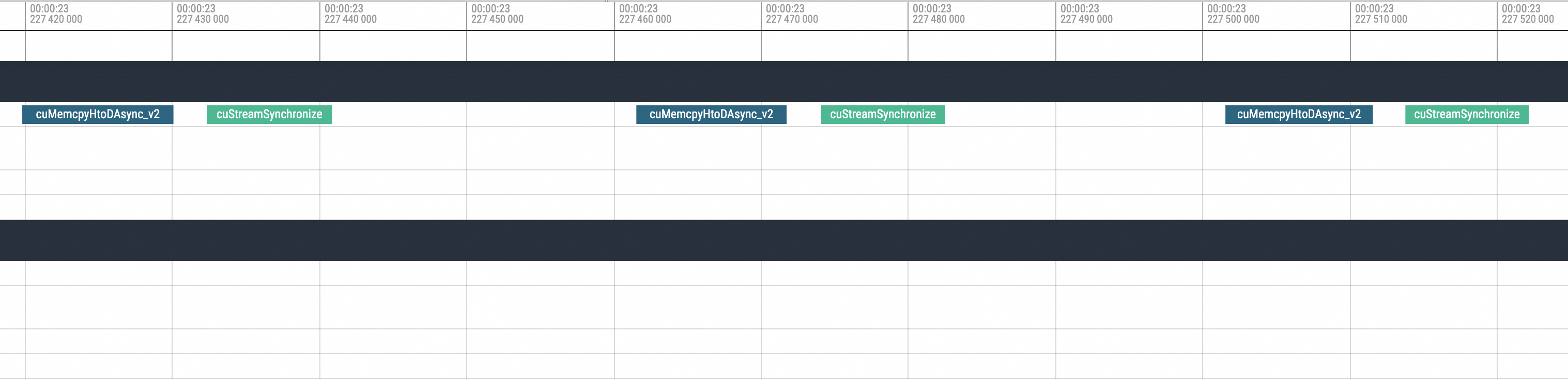
可以很明显看到是cuMemcpyH2D的执行,执行完毕之后进程就Hang住了。接着拉到Hang恢复后的位置,如下图所示:
Zoom In到对应位置,可以看到Hang恢复后第一个执行的就是NCCL的broadcast动作,然后才进行后续的标准动作。所以由此现象也可以大致推断为是NCCL Hang导致的问题。
- 本页导读
- Pytorch训练示例
- 示例环境
- 结果分析
- vLLM推理示例
- 示例环境
- 结果分析
