
本文将介绍如何快速入门上手湖仓一站式迁移中心。
快速开始:新建迁移场景
通过探查Agent, 探知客户源端有哪些大数据组件及集群。
在“一站式迁移”菜单下新增迁移场景,配置好要迁移的源端数据源,目标端数据源以及源和目标的映射关系,一个迁移场景可以包含多组数据迁移+多组调度集群迁移。
step1. 新建场景基础信息

step2.创建源端数据源

新建数据源: 创建源端待迁移的数据源,数据源类型分为数据集群数据源和调度集群数据源。
hive数据源配置(为例):
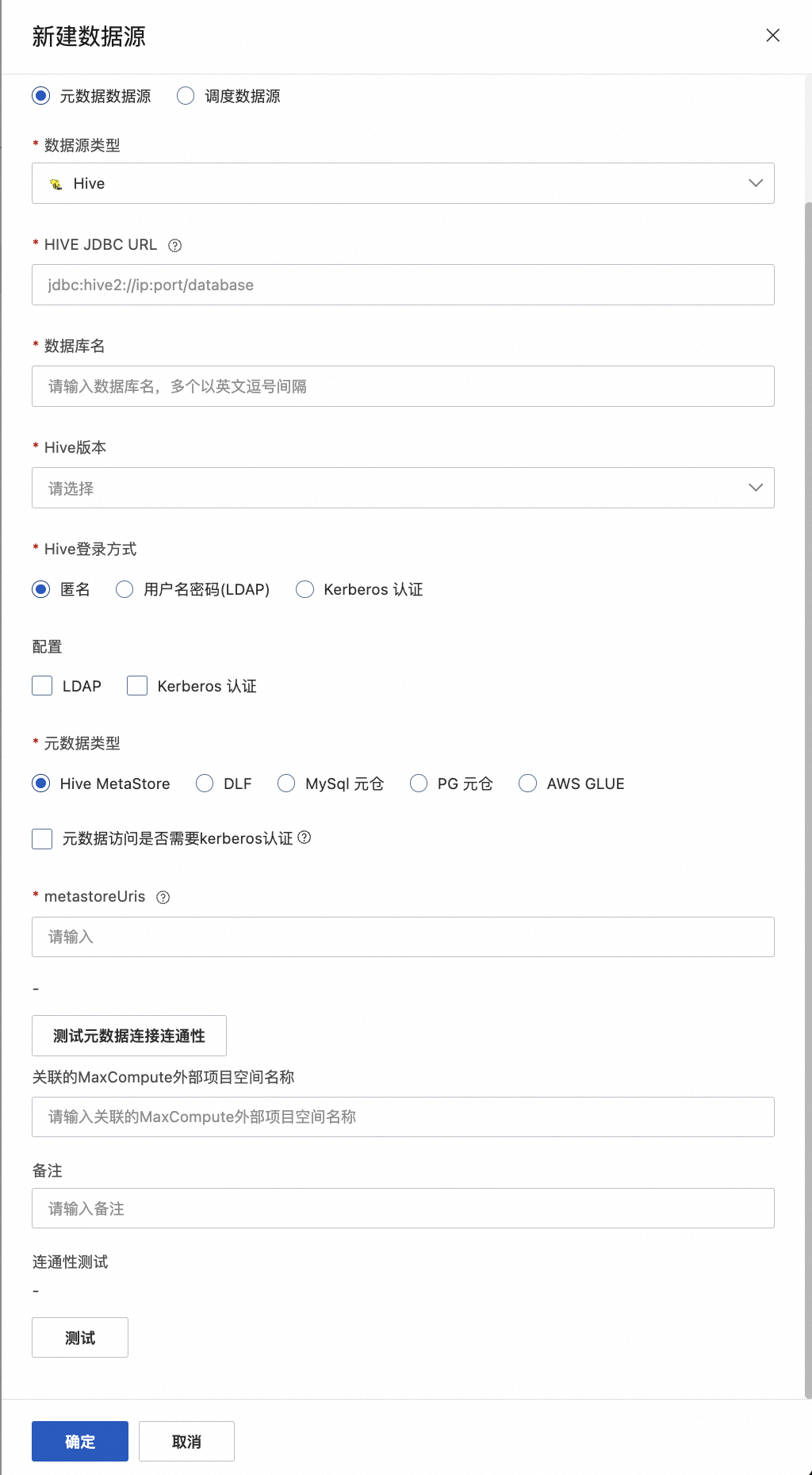
说明:
配置项名称 | 子项名称 | 说明 |
数据源名称 | 不能包含字符、数字、汉字之外的特殊字符, 编辑时不可修改; 全局唯一 | |
数据源类型 | Hive | |
Hive JDBC URL | 访问HiveServer2的Jdbc地址,例如:jdbc:hive2://ip:port/database; 注意,若开启了Kerberos认证,jdbc链接串格式为: jdbc:hive2://ip:port/database;principal=your principal | |
数据库名 | Hive database | |
Hive版本 | 1.x,2.x,3.x | |
Hive登录方式 | Hive Jdbc的登录方式,分为匿名、LDAP、Kerberos认证三种 | |
配置 | 配置选项 | 主要是配置需要的认证数据:如LDAP的用户名密码、Kerberos登录所需的认证文件,本配置项是多选项
|
LDAP-用户名 | LDAP用户名 | |
LDAP-密码 | LDAP密码 | |
Kerberos 认证-keytab文件 | 上传keytab文件 | |
Kerberos 认证-conf文件 | 上传conf文件 | |
Kerberos 认证-principal | kerberos principal | |
元数据类型及访问配置 | 1.Hive Metastore | |
元数据访问是否需要kerberos认证 | 请检查集群配置上hive.metastore.sasl.enabled是否等于true, 如果是的话这里需要勾选kerberos认证,并且在上述配置中配置对应的Kerberos认证文件信息。 | |
metastoreUris | hive metastore url 示例:thrift://10.0.2.165:9083 | |
2.DLF | 通过DLF获取Metastore连接 | |
Endpoint | 访问DLF的endpoint, 要求工具所在机器能够连通 | |
AccessKey ID | ⽤于访问DLF的AccessKey ID | |
AccessKey Secret | ⽤于访问DLF的AccessKey Secret | |
数据目录 | 需要进行校验的数据所在的Catalog 注: CatalogId一定要与上述的JDBC URL对应上 | |
DLF Settings | 其他dlf配置信息 | |
3.MySQL元仓 | ||
jdbcURL | 示例:jdbc:mysql://rm-xxxx.mysql.rds.aliyuncs.com/hive_meta_db?createDatabaseIfNotExist=true&characterEncoding=UTF-8 | |
用户名 | ||
密码 | ||
4.PG元仓 | ||
jdbcURL | 示例:jdbc:postgresql://rm-xxxx.mysql.rds.aliyuncs.com/hive_meta_db?createDatabaseIfNotExist=true&characterEncoding=UTF-8 | |
用户名 | ||
密码 | ||
5.AWS Glue | ||
AccessKey ID | ||
Access Secret | ||
Region |
MaxCompute数据源配置:
配置项名称 | 说明 |
数据源名称 | 不能包含英文字符、数字、汉字之外的特殊字符, 编辑时不可修改 |
数据源类型 | MaxCompute |
ODPS Endpoint | 访问MaxCompute的endpoint, 要求工具所在机器能够连通 mc.endpoint 示例:http://service.cn-shanghai.maxcompute.aliyun.com/api |
AccessKey ID | ⽤于访问MaxCompute的AccessKey ID |
AccessKey Secret | ⽤于访问MaxCompute的AccessKey Secret |
Default Project | MMA会使⽤这个项⽬的配额在MaxCompute上执⾏sql |
Tunnel Endpoint | 数据校验不依赖此项,随便填 |
调度集群数据源以DolphinScheduler为例:

可以选择直接上传dolphin调度系统的源信息zip包,也可以选择连接api获取相关待迁移信息
配置项名称 | 说明 |
数据源名称 | 不能包含英文字符、数字、汉字之外的特殊字符, 编辑时不可修改 |
数据源类型 | DolphinScheduler |
版本 | DolphinScheduler版本选择 |
连接地址 | DolphinScheduler系统服务访问地址 |
令牌 | 访问Token(AccessToken):在使用API接口获取dolphin调度系统数据时,需要通过OAuth2.0等机制获取的访问令牌。 |
项目名称 | 访问相关API, 需DolphinScheduler系统项目空间信息 |
创建数据源完成后,需测试连通性是否正常。

step3.创建目标端数据源
创建方式同Step2
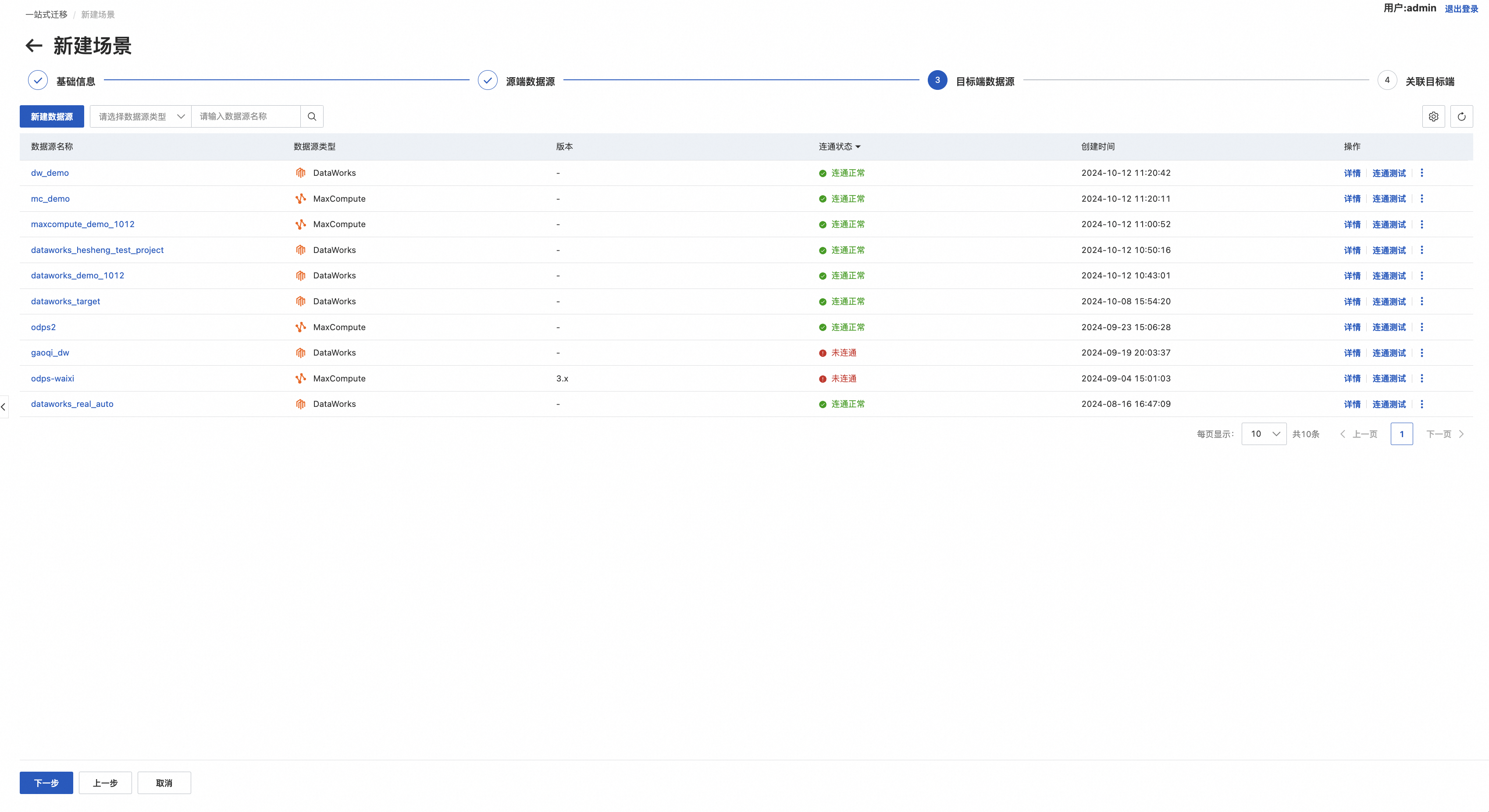
step4.关联目标端
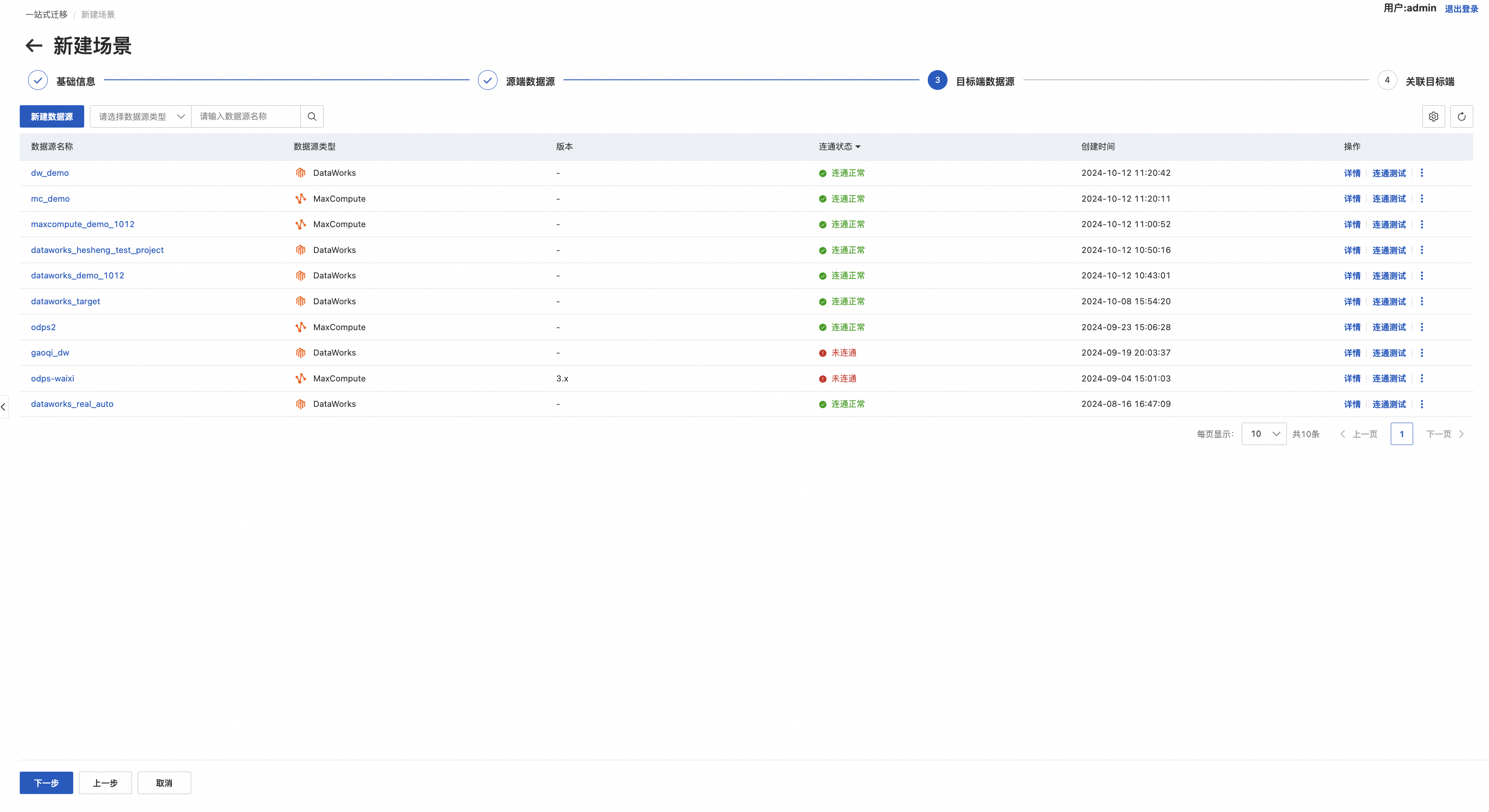
该列表以源端数据源(集群)为主视角,展示与目标端数据源(集群)的关联关系,点击操作栏下的“关联目标端数据源”可以选择相应的目标端数据源进行关联,该映射关系将作为实际迁移时的源与目标应色号关系。

点击“完成”进行保存。
设置Pipeline(一站式迁移)
创建场景完成后,需要设置该迁移场景
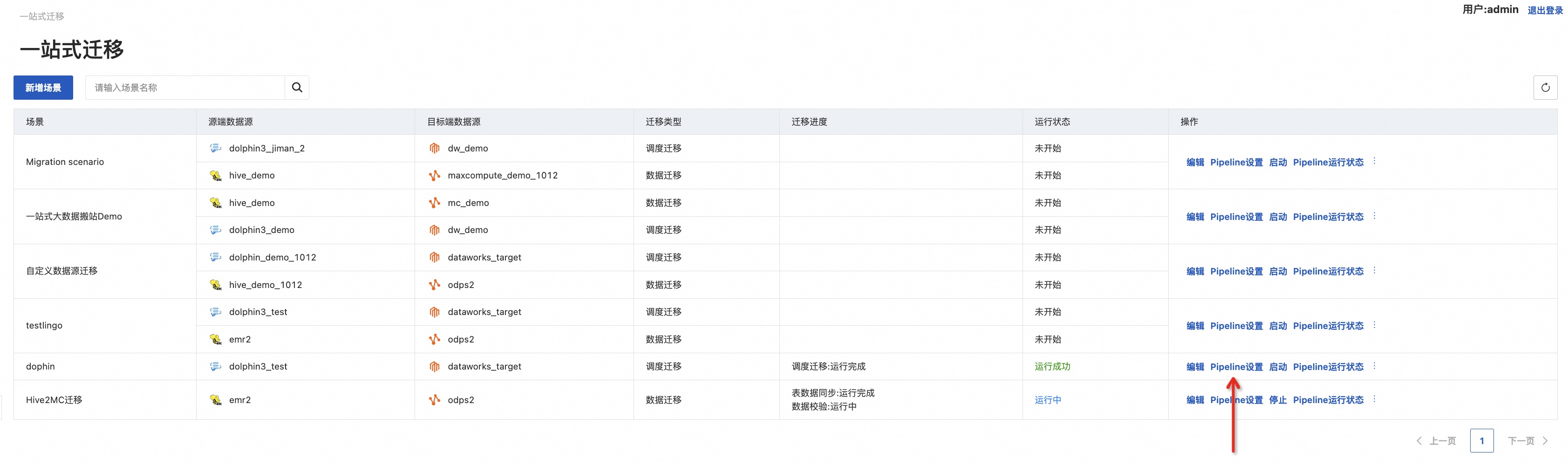
我们会基于迁移场景,初始化迁移Pipeline的DSL,您只需在如下界面进行迁移偏好配置:
1.集群探查设置
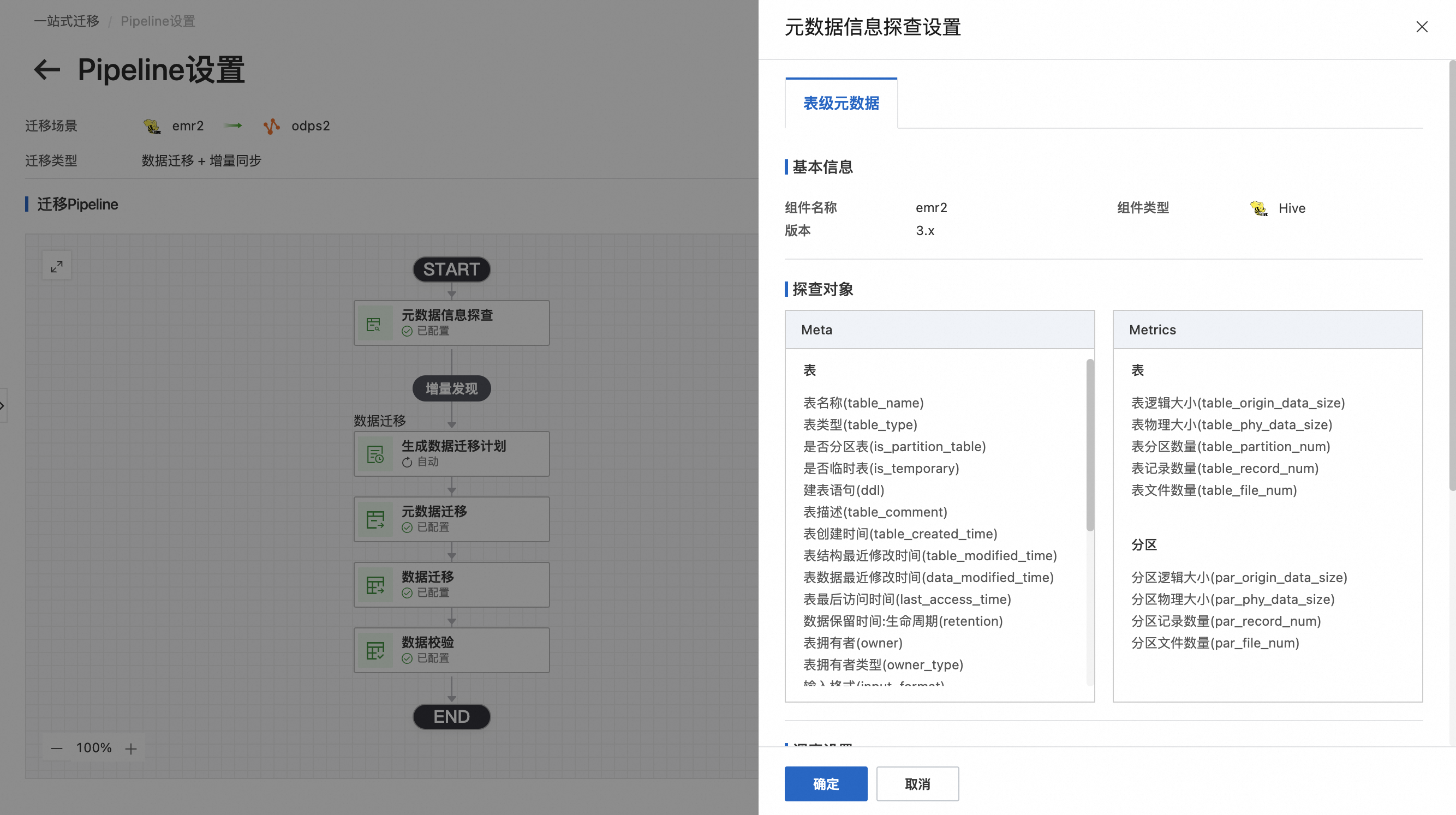
数据集群探查: 以hive至mc迁移举例,支持配置定时调度的cron表达式
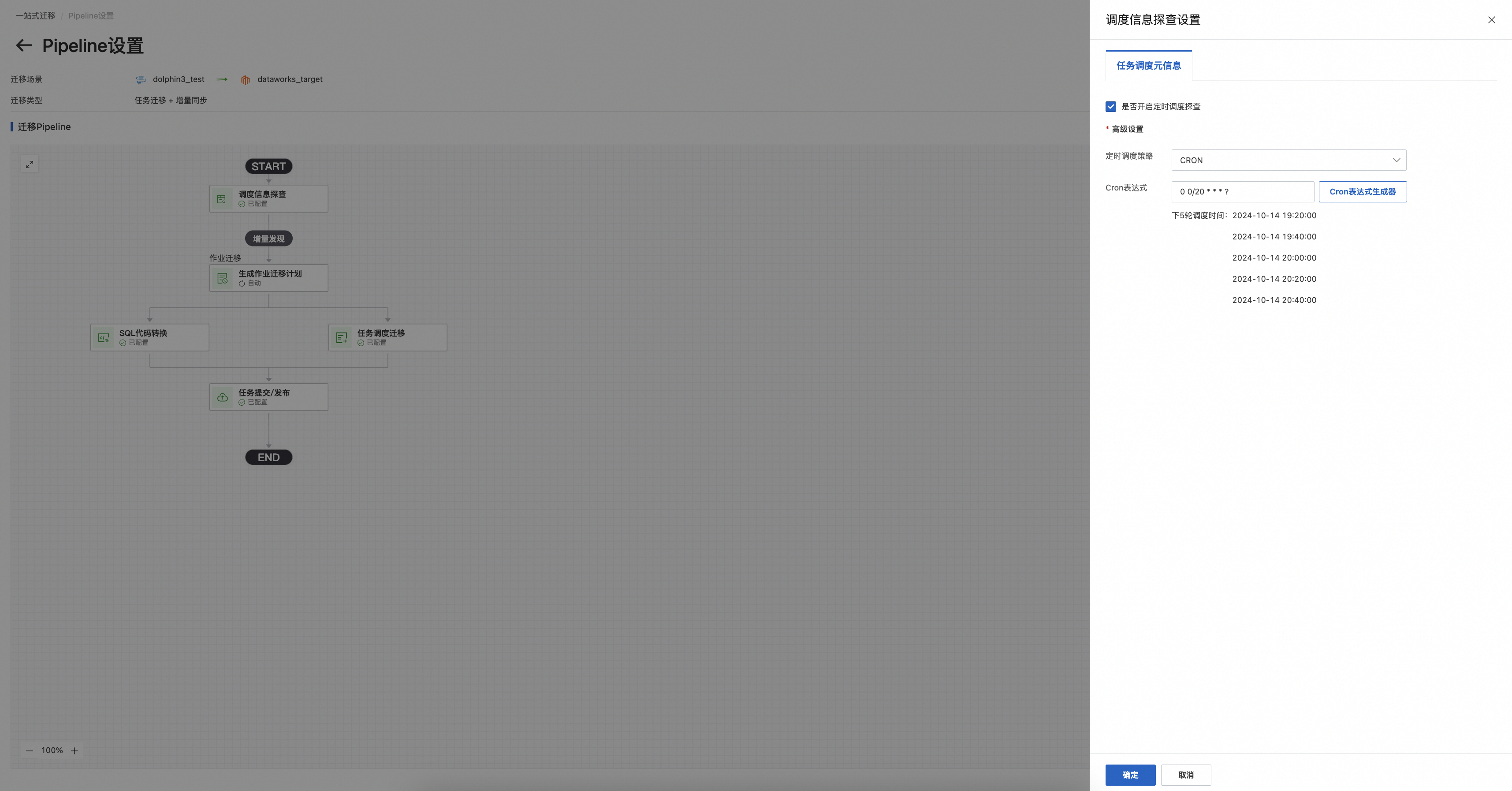
调度集群探查:以dolphin至DataWorks迁移举例,支持配置定时调度的cron表达式
2.元数据迁移&数据迁移设置
以hive2mc场景为例,元数据迁移和数据迁移设置复用。
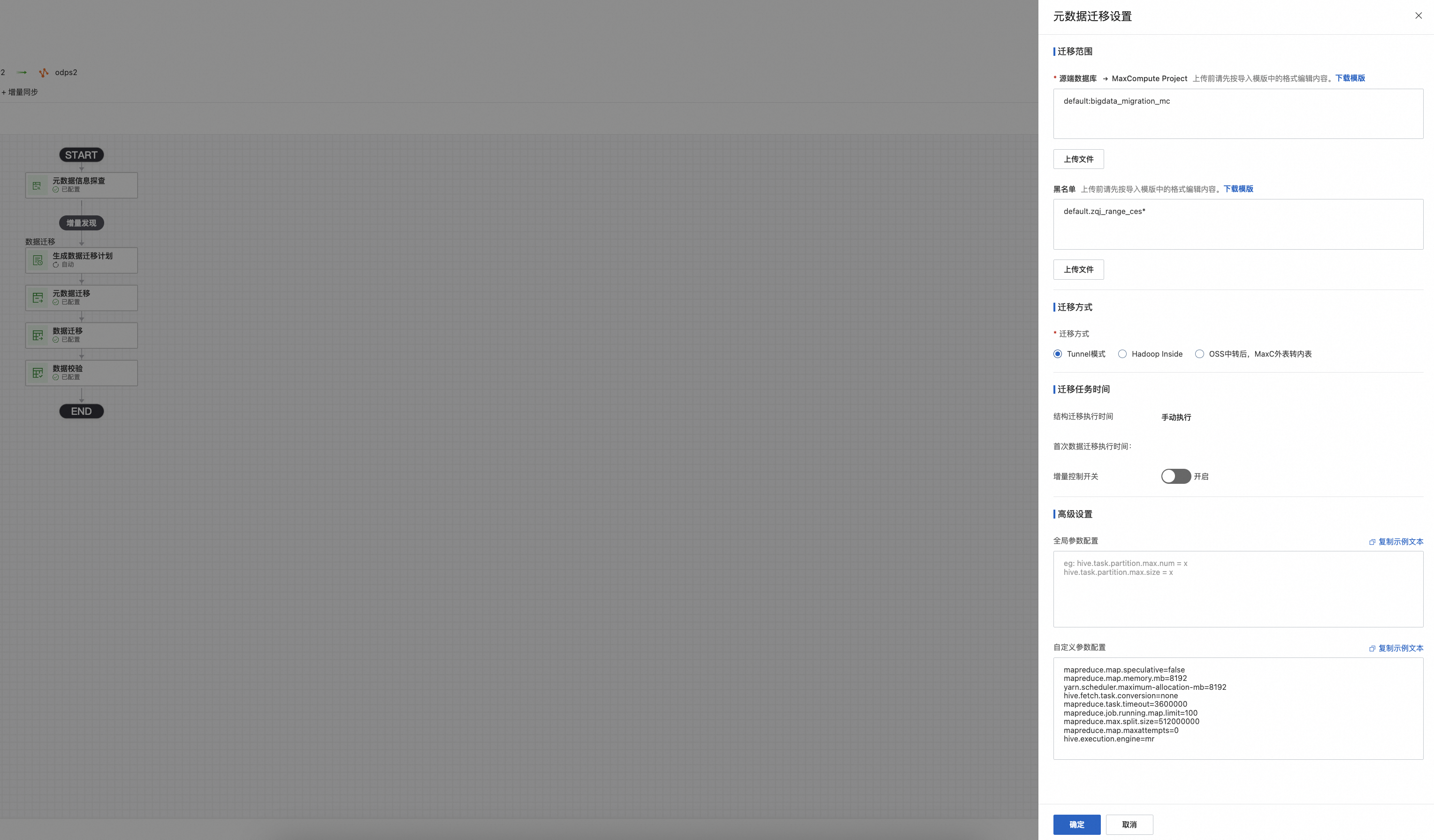
1)填写源端hive db->目标端MaxCompute Project的映射关系,支持“下载模板”维护信息后上传

2)黑名单: 迁移时忽略。 填写方式dbname.tablename, dbname.*(代表该db下全部表)

3)选择迁移方式
Hive UDTF(Tunnel):
1.通过Hive MetaStore获取Hive元数据,包括所有表名、表Schema、分区信息、数据量、更新时间等
2.在MaxCompute端根据获取到的元数据信息(以及工作台任务指令下发的迁移范围)进行建表和分区
3.向源端Hive提交执行UDTF的SQL命令
4.UDTF调用MaxCompute的Tunnel SDK向目标端写入数据
OSS中转、MaxC外表转内表:
1.通过阿里云OSS在线迁移服务将Hive数据(HDFS/S3/OBS等)迁移到阿里云OSS
2.通过Hive MetaStore获取Hive元数据,包括所有表名、表Schema、分区信息、数据量、更新时间等
3.根据获取到的Hive元数据以及OSS路径信息(和HDFS对应)在目标端MaxCompute创建OSS外表和外表对应的普通表
4.从外表查询数据并插入普通表 :insert 普通表 from select oss外表,将数据从OSS导入MaxCompute
4)高级设置
全局参数:
hive.task.partition.max.num=50 :单个任务处理的最多分区数量(可选)
hive.task.partition.max.size=5 : 单个任务处理的最大数据量(单位G)(可选)
自定义参数:
eg: mapreduce.map.speculative=false:是否启动 map 阶段的推测执行,默认为true
mapreduce.map.memory.mb=8192: 1个map任务可使用的资源上限
yarn.scheduler.maximum-allocation-mb=8192:yarn最大可申请内存量
hive.fetch.task.conversion=none:所有涉及hdfs的读取查询都走mapreduce任务
mapreduce.task.timeout=3600000 (单位ms)
mapreduce.job.running.map.limit=100:同时执行的 map 任务数量
mapreduce.max.split.size=512000000
mapreduce.map.maxattempts=0
hive.execution.engine=mr
3.数据校验设置
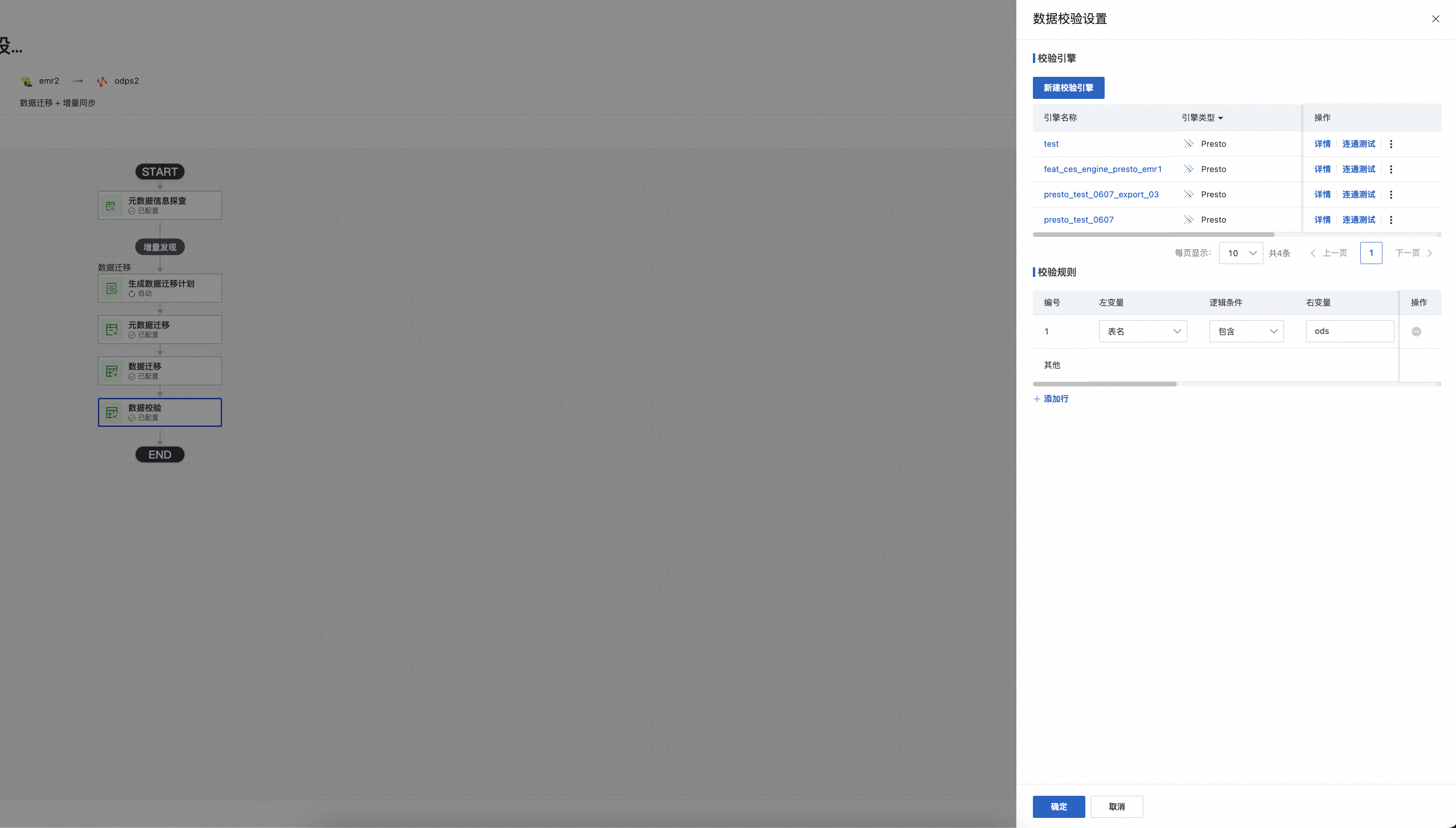
1)新建校验引擎
2)选择校验规则:
左变量:表名,表中数据类型
逻辑条件:等于,包含,不包含
右变量:左变量为表名时, 填写关键词; 左变量为数据类型, 源端校验执行引擎、目标端校验引擎
校验模式:数据量(count)比对,指标比对,弱内容比对,自定义比对,全文比对,空值率比对
差异容忍率:支持填写规则支持添加行和删除已有行
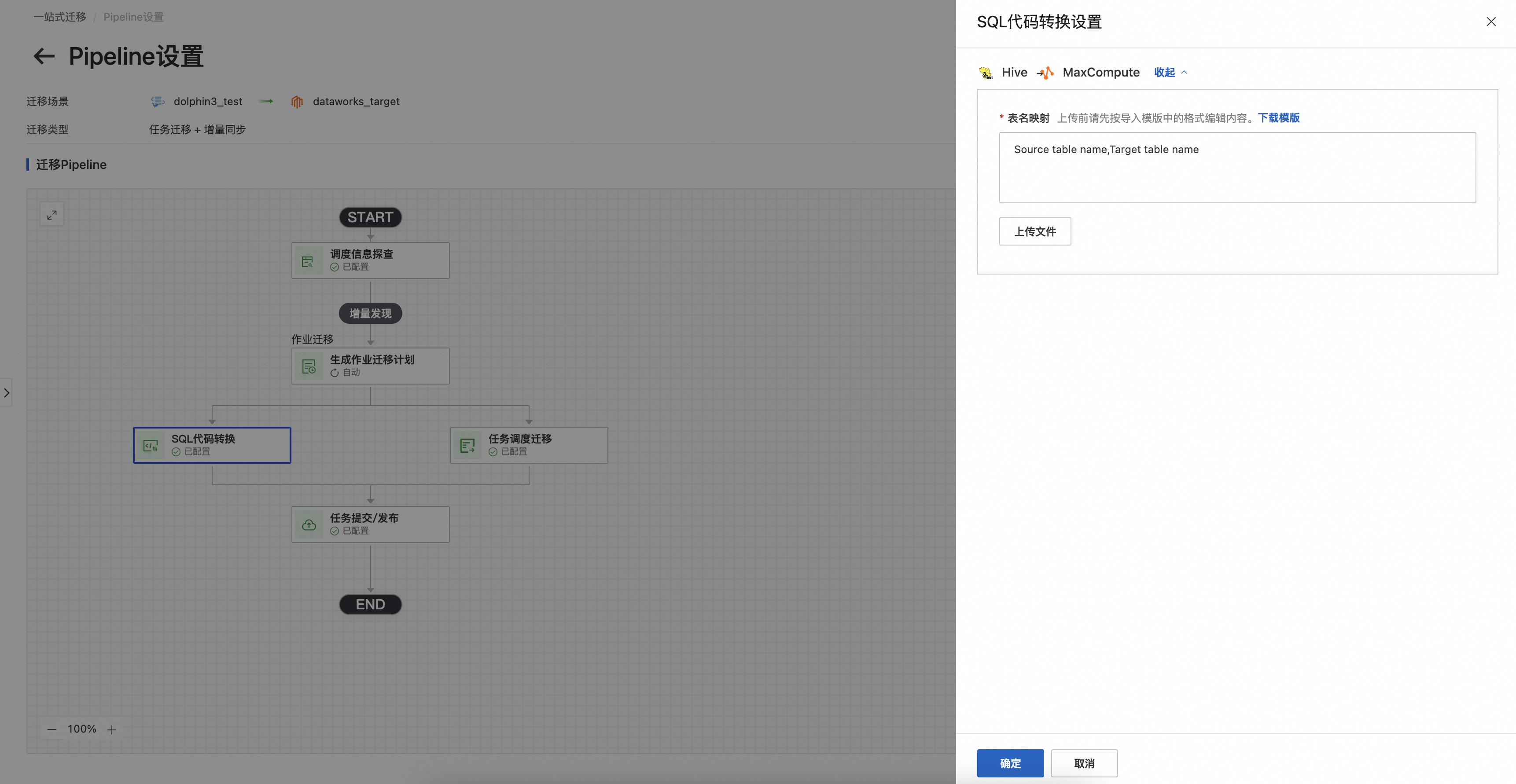
4.SQL代码转换设置
上传表映射文件,提供源端三元组和目标端三元组的映射关系,例如hive集群的db.tablename与目标端MaxCompute集群的project.tablename的映射关系
5.任务调度迁移设置
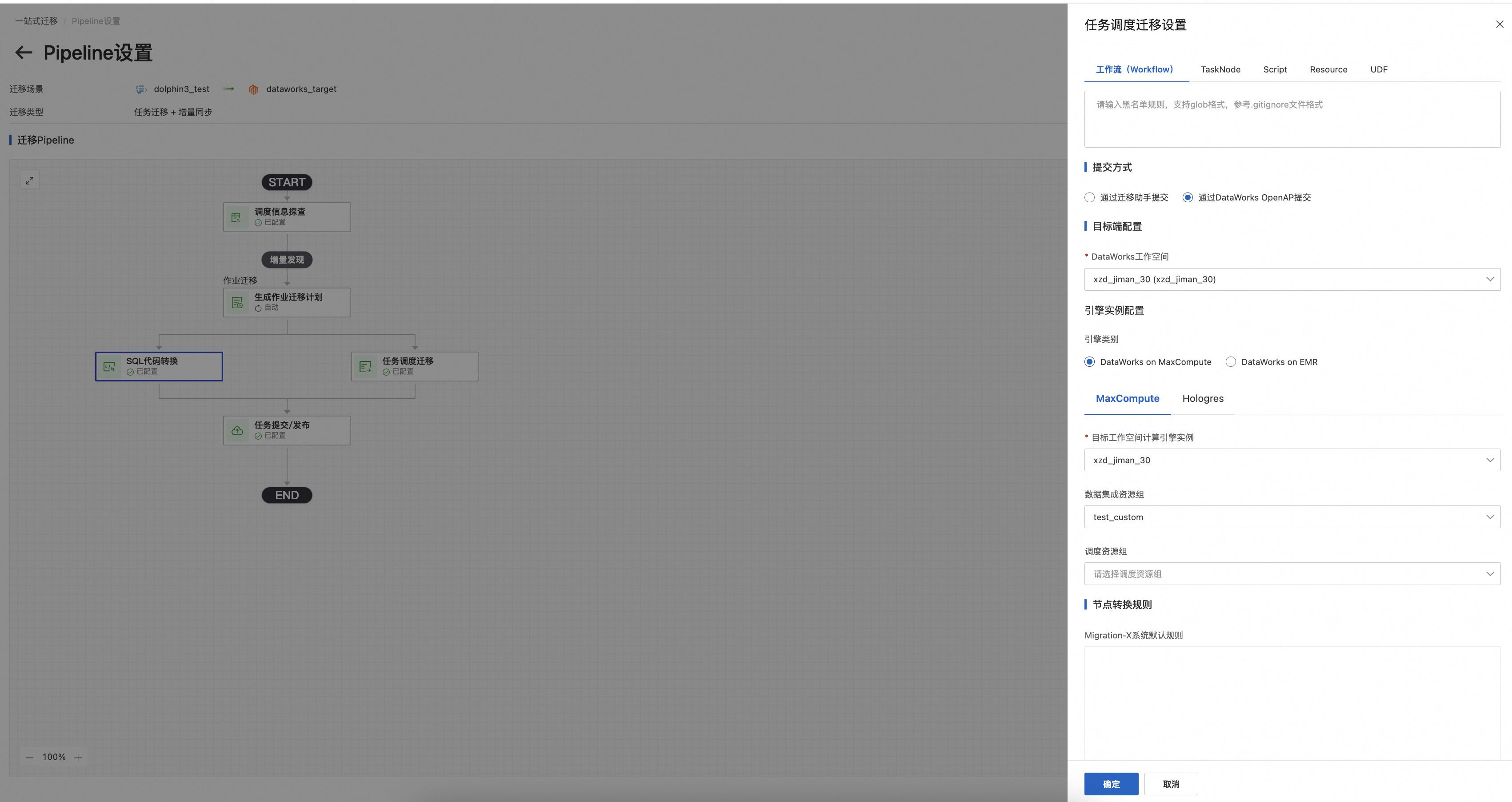
1)黑名单:支持设置workflow,tasknode等对象黑名单
2) 支持通过迁移助手提交,也支持通过DataWorks Openapi提交,推荐后者
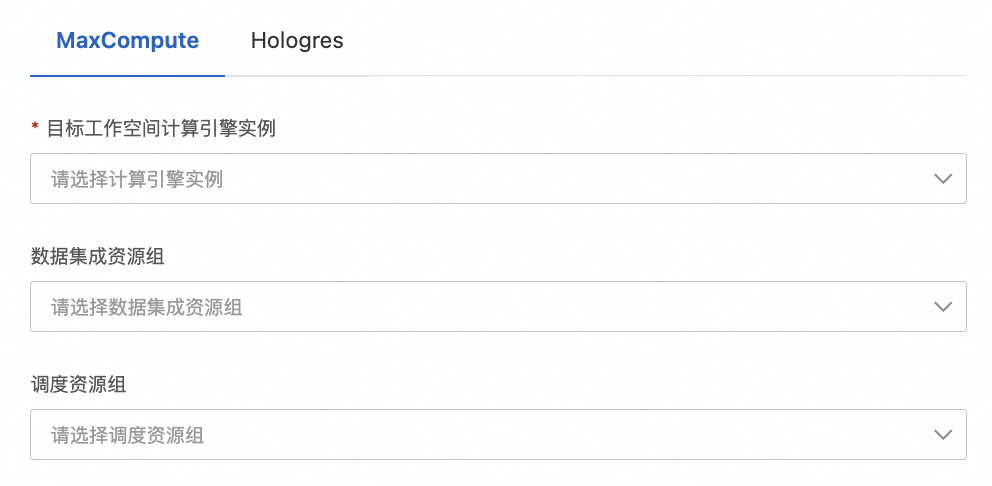
3) 需要选择目标端引擎信息
4)编辑默认规则
{
"format": "SPEC",
"locale": "zh_CN",
"skipUnSupportType": true,
"transformContinueWithError": true,
"specContinueWithError": true,
"tempTaskTypes": [
"SPARK",
"HIVECLI"
],
"skipTaskCodes": [],
"settings": {
"workflow.converter.shellNodeType": "EMR_SHELL",
"workflow.converter.commandSqlAs": "EMR_SQL",
"workflow.converter.sparkSubmitAs": "EMR_SPARK",
"workflow.converter.target.unknownNodeTypeAs": "DIDE_SHELL",
"workflow.converter.mrNodeType": "EMR_MR",
"workflow.converter.target.engine.type": "EMR",
"workflow.converter.dolphinscheduler.sqlNodeTypeMapping": {
"POSTGRESQL": "EMR_HIVE",
"MYSQL": "EMR_HIVE",
"HIVE": "EMR_HIVE",
"CLICKHOUSE": "CLICK_SQL"
}
}
}tempTaskTypes内填需自定义处理的节点类型,不填以默认规则转换(settings里如果有相应节点转换规则的话),填写将以自定义规则为准,且保留原始内容;
5)自定义转换插件&规则
使用自定义转换规则,需先下载转换插件自定义工程,进行上传后方可使用

自定义转换规则配置:
{
"if.use.migrationx.before": false,
"if.use.default.convert": true,
"conf": [
{
"rule": {
"settings": {
"workflow.converter.shellNodeType": "DIDE_SHELL",
"workflow.converter.commandSqlAs": "DIDE_SHELL",
"workflow.converter.sparkSubmitAs": "ODPS_SPARK",
"workflow.converter.target.unknownNodeTypeAs": "DIDE_SHELL",
"workflow.converter.mrNodeType": "ODPS_MR",
"workflow.converter.target.engine.type": "MaxCompute",
"workflow.converter.dolphinscheduler.sqlNodeTypeMapping": {
"POSTGRESQL": "ODPS_SQL",
"MYSQL": "ODPS_SQL",
"HIVE": "ODPS_SQL"
}
}
},
"nodes": "all, name, idsStr"
}
]
}项目中可自定义节点类型转换规则,与默认规则冲突时以自定义为准。
可以配置多段json, 圈选nodes范围所使用的转换规则,即项目中源端不同类型的shell可通过圈选相应类型的nodes范围转换成目标端上不同的节点类型。
6)提交设置

提交至目标端DataWorks时对应元素的状态偏好管理,以上配置完成好,点击保存。
运行Pipeline一站式迁移
1. 启动
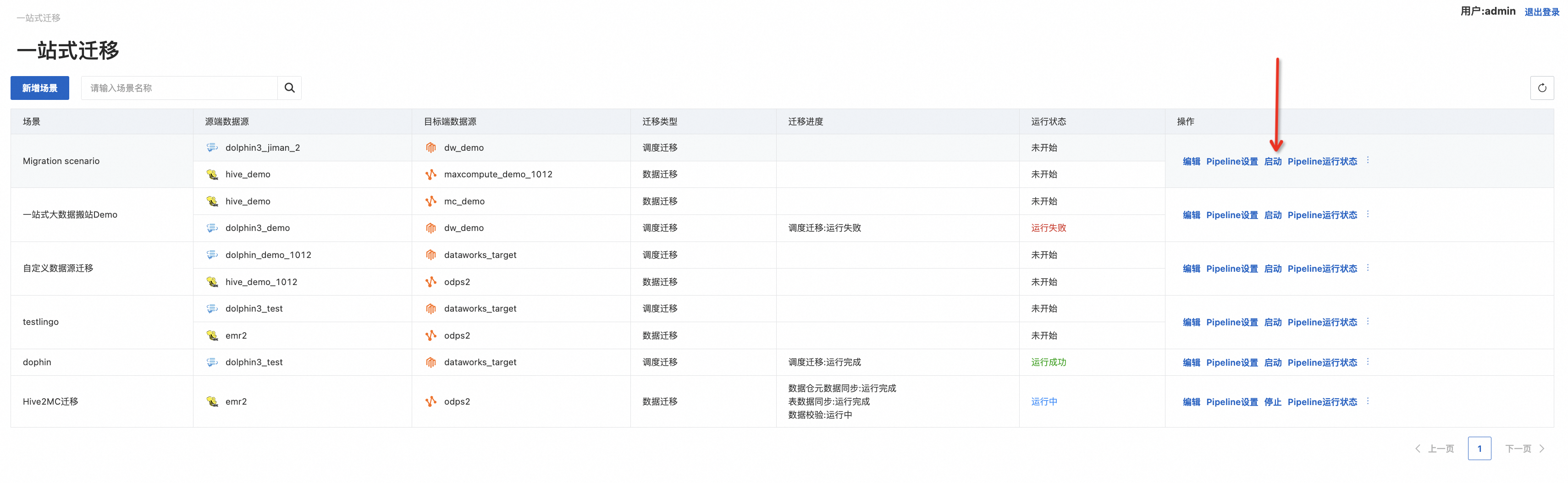
点击“运行状态”查看一站式迁移运行进展,下图可看到探查任务批次,根据集群探查任务设置的时间可以看到相应的探查任务,和每次探查到的结果。
2. 集群探查
数据集群探查示例:

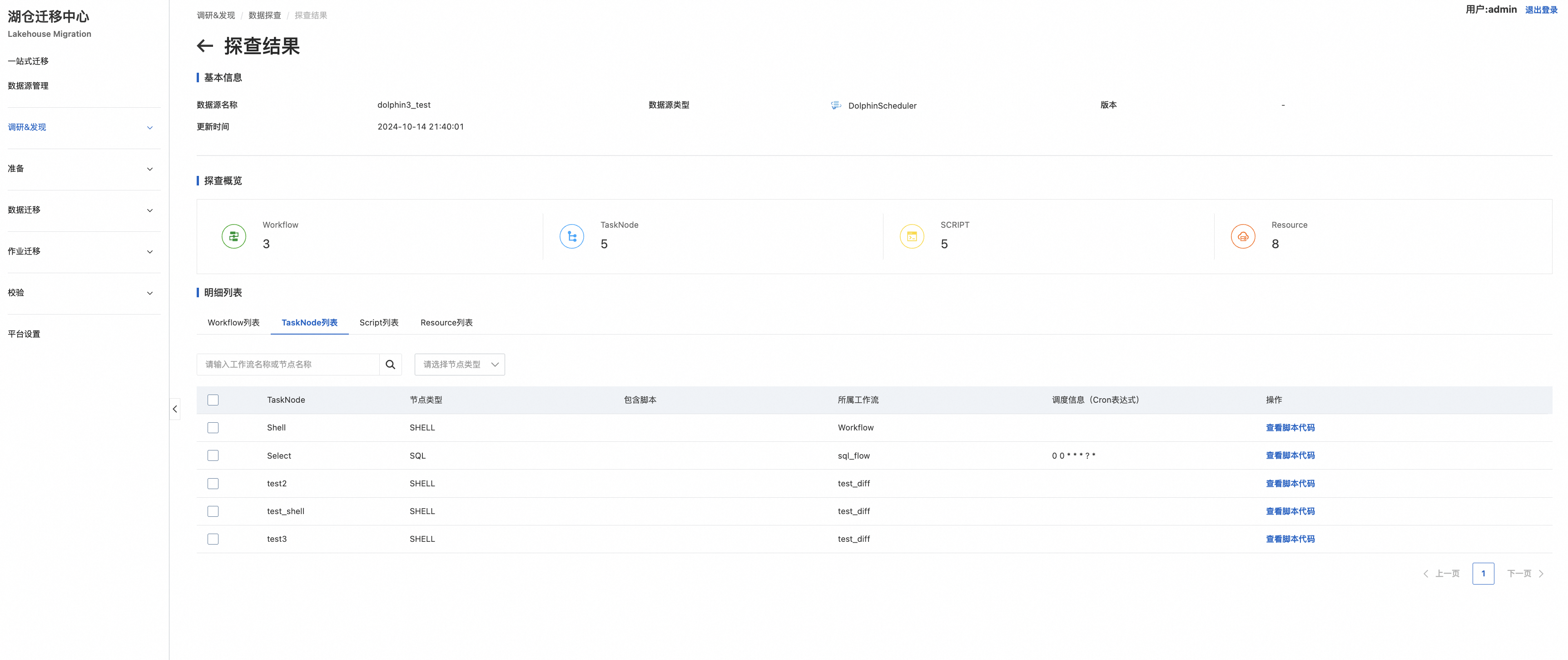
探查结果详情:

调度集群探查示例:
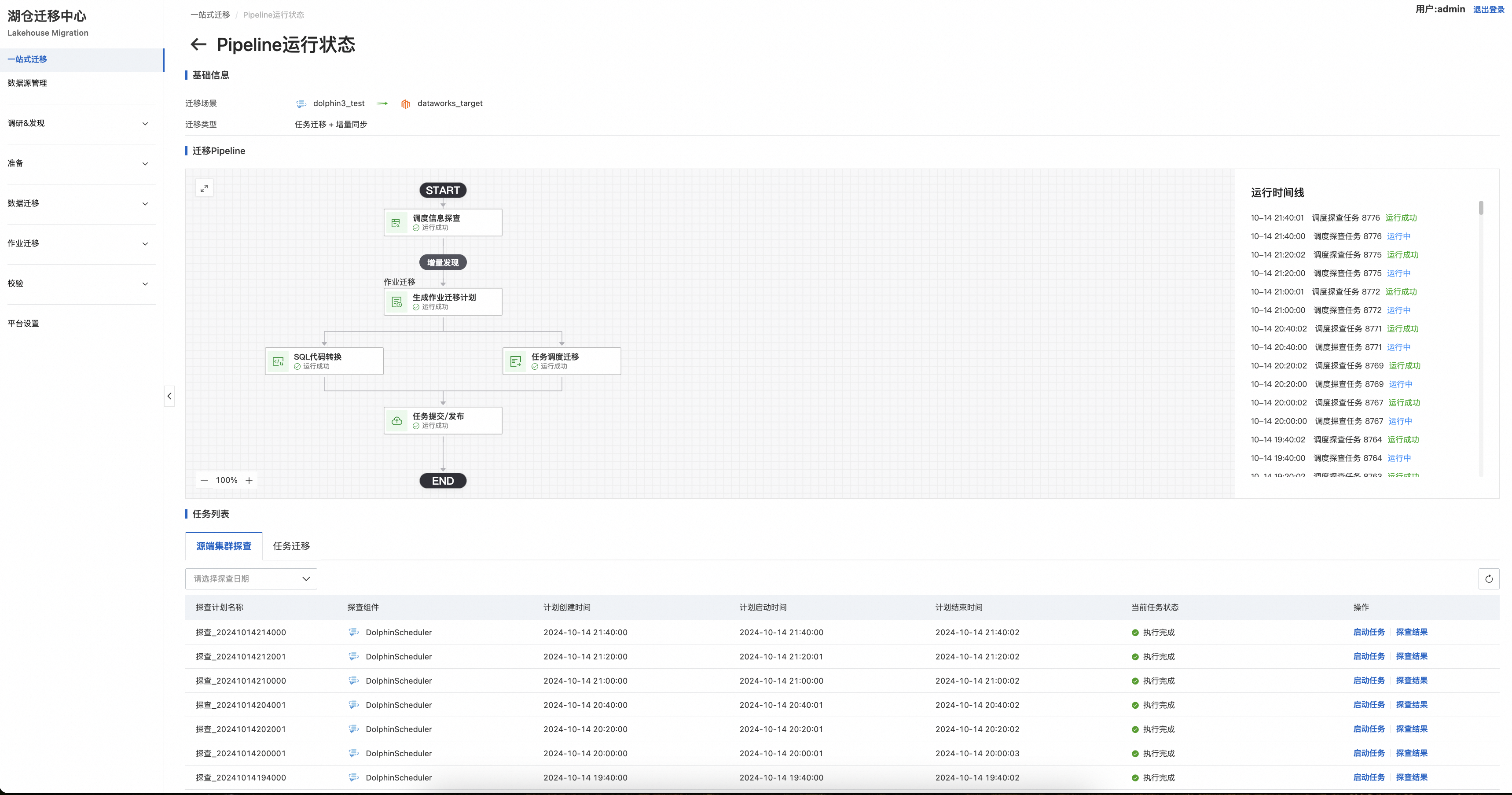
探查结果详情:
3. 数据迁移
首次对源端集群的数据探查,会自动生成存量数据迁移任务。后续每次探查均为与前一次集群探查任务结果进行比对,判断出增量部分,自动化生成增量数据迁移任务。原子级的对象(表或分区)会按照结构迁移-》数据迁移-〉数据校验的顺序依次执行,三环任务均完成并通过校验,视为单个对象迁移成功。
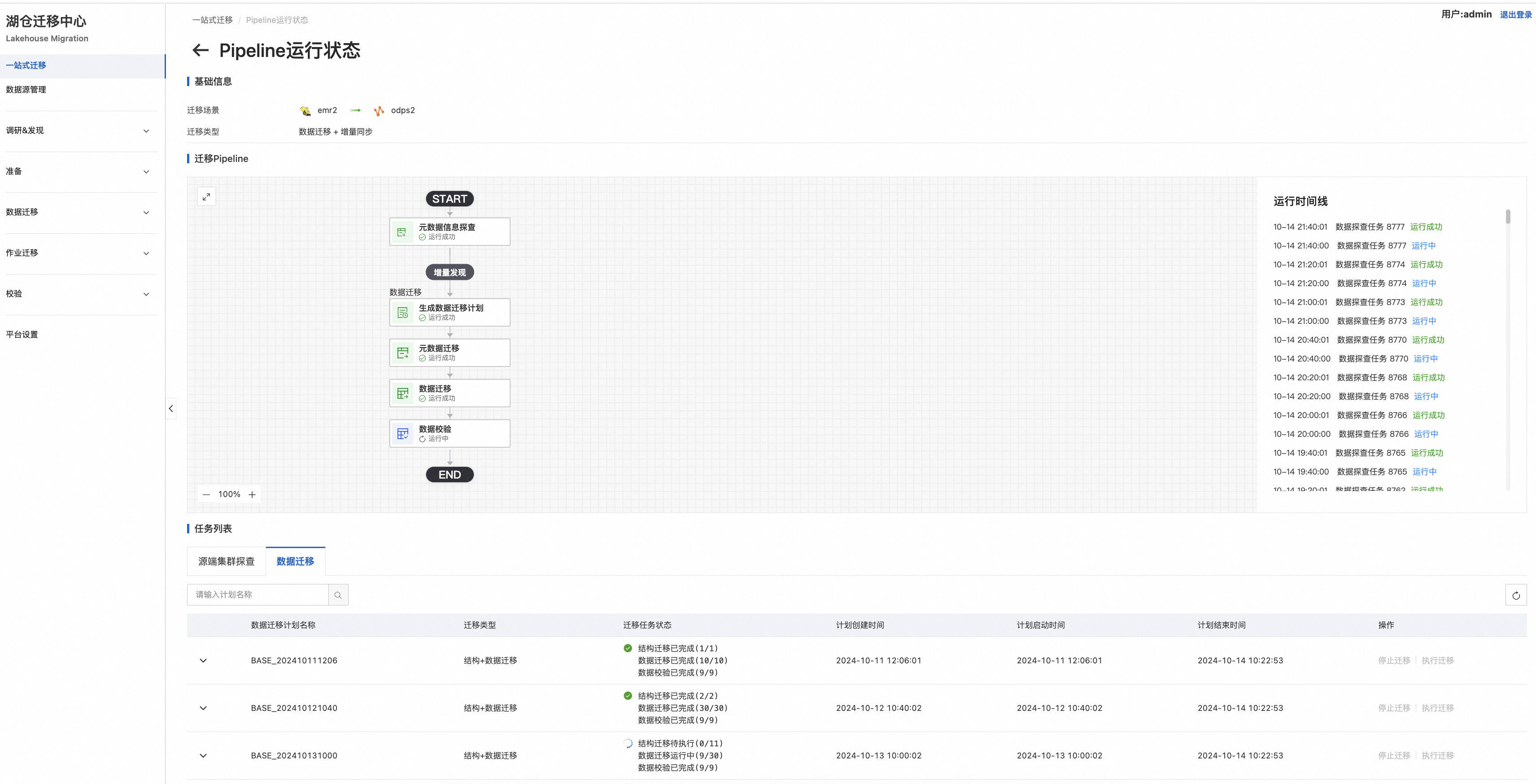
可通过如下入口查看本次迁移任务详情:

以数据迁移详情界面为例:

支持单次任务的统计信息展示,面向迁移失败原子对象提供“重试”入口
4. 调度迁移
每次对源端集群的调度探查均会自动生成相应批次的待迁移任务实例,需要手动执行转换,和提交至目标端。

转换报告:
