
智能阈值报警是针对云监控中的云资源实例的监控指标推出的智能报警功能,它自动适配并拟合监控指标的历史数据,展示报警阈值边界,发现监控指标突增或突降的异常行为,为您业务的稳定性提供保障。
什么是智能阈值
智能阈值基于机器学习算法动态识别历史数据模式特征(例如:监控指标的周期性、整体趋势和波动大小等),并融合具体的云产品的监控指标信息,自动针对每个实例计算出上下阈值的报警边界。
应用场景
在不同业务场景下,云资源实例的监控指标的数值水位、周期变化、方差波动等统计特点会呈现不同状态,例如:您的流量日间大、夜间小,会导致ECS实例或CDN域名的网关流量、消息队列任务堆积等监控指标出现日夜波峰和波谷;IO密集型业务和计算密集型任务会导致不同ECS实例的CPU或负载(load.1m、load.5m和load.15m)出现不同负载水位。
由于单指标报警规则设置了固定的报警阈值,所以无法应对以上复杂场景,导致经常出现部分高负载实例持续报警,而低水位负载实例业务异常下达不到报警阈值或达到阈值后业务问题已持续半小时以上。因此,云监控为了更好地提升您的报警体验,缩短异常问题发现时间,推出基于机器学习算法结合专家规则经验的智能阈值功能。其核心算法可以动态识别历史数据模式特征,例如:监控指标的周期模式、波动、水位大小等,融合具体产品的监控指标信息,自动针对每个实例产出上下阈值报警边界。智能阈值报警可供您可视化查看算法阈值效果,并提供不同敏感度调参能力,具备基本的白盒化功能。
产品优势
智能阈值与单指标或多指标报警规则相比,优势如下:
报警降噪
智能阈值会采集每个实例的指标数据,利用鲁棒性时序分解和预测等模型适配,适应不同实例指标的数据水位和业务变化,并基于历史报警聚类和相似度匹配,进一步过滤异常噪声提升报警准确度,可以更有效地应对以下场景:
不同实例指标水位差异
例如:某游戏行业拥有分别用于离线计算和在线服务的ECS实例,通常采取同样的报警模板(CPU利用率、负载和内存使用率等监控指标大于80报警),导致较高负载水位的实例出现持续误报。
定时任务导致负载突增
例如:某用户使用云数据库RDS作为存储服务,且设置了每日零点定时清理30天以前的历史数据的定时任务。但是当定时任务运行时,RDS的IOPS使用率瞬间接近100%产生报警,然后迅速恢复正常,每日定时发生误报。
针对以上业务场景下,采用智能阈值报警可有效降低80%~90%的误报,提升您对业务异常的关注和监控运维体验。
自动异常发现
云产品实例指标的异常问题通常由于上下游业务、流量变化或云实例部署应用、数据变更导致。智能阈值报警可以快速发现业务异常,例如:公网SLB实例连接、消息队列堆积量上涨等服务相关问题。您可以通过智能阈值检测基础资源ECS指标异常,辅助定位业务异常的根因。
当您配置单指标或多指标报警规则时,往往将阈值水位设置较高而避免过多误报,且整体覆盖应用分组或全部资源,无法针对具体业务和实例调优。智能阈值报警规则可以更快速、更精准地发现指标的突升或突降异常变化,且可以更有效地应对以下场景:
代码变更后的指标异常发现
例如:某开发人员变更应用代码后,程序发生内存泄露问题导致Full GC,CPU使用率明显上涨,但无法触发高水位的单指标报警。
业务不可用前的及时预警
例如:上游业务流量的突然上涨,智能阈值规则的异常快速发现能力,可以在达到高水位单指标阈值前报警,避免业务由于后续持续的高流量导致下游整体业务不可用。
在以上业务场景下,智能阈值针对各主要云产品的核心监控指标,可以有效地在指标异常发生3分钟内召回85%以上问题及故障。
降低阈值配置维护成本
智能阈值无需输入具体数值,只需要创建一条智能阈值报警规则,选择对应的报警条件(边界以外、高于上边界和低于下边界)即可完成阈值的相关设置,显著降低配置维护成本,且可以更有效地应对以下场景:
配置阈值的具体数值
当您在配置ECS实例的流量、带宽和QPS等没有物理上限类型的监控指标的报警规则时,通常不知道设置什么数值最为合适,这些监控指标的数值可能会有数量级的差异,无法找到通用且合适的数值。当ECS实例的流量、带宽和QPS等监控指标的实际数值随着运维变更或业务变化,而需要对阈值进行维护时,适当调整数值避免误报或漏报。
多条规则实现不同阈值、不同时段的报警
当部分监控指标在不同时段有明显的波峰或波谷时,需要配置多条规则并指定不同的生效时间来实现。
最佳实践
云服务器ECS基础资源报警降噪
某用户的单台云服务器ECS负责离线渲染任务,其他ECS负责线上业务支持。离线渲染使用的ECS内存使用率明显高于其他线上任务ECS。该用户使用单指标报警规则时统一配置内存使用率大于80%,负责离线渲染的ECS持续报警一周,报警200条,配置智能阈值后效果如下图,一周报警5条以内,误报收敛95%。
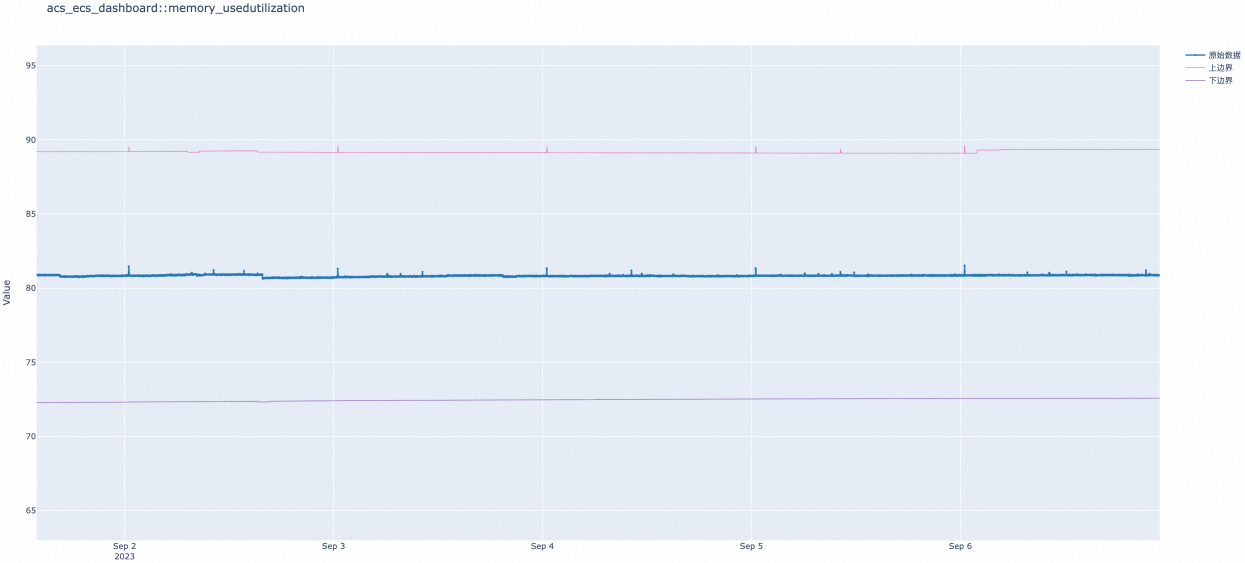
除了云服务器ECS的内存使用率,其他指标也适用于报警降噪最佳实践,现推荐以下监控指标配置智能阈值报警规则。
典型异常 | 异常可能原因 | 监控指标 | 报警条件 |
典型异常 | 异常可能原因 | 监控指标 | 报警条件 |
负载过高、负载波动较大或负载持续峰值 | 系统资源不足、进程异常(死循环、内存泄露等)、进程数量突增、某些应用程序或系统服务在某些时候突然产生了大量的请求或数据处理操作。 |
| 高于上边界 |
请求量突增、请求量波动较大或请求量持续峰值 | 应用程序或系统服务出现了异常;磁盘I/O性能不足、磁盘容量不足;某些应用程序或服务在某些时候进行了大量的磁盘读或磁盘写操作。 |
| 边界以外 |
连接数过高、连接数波动较大或连接数持续峰值 | 系统负载过高、TCP连接池不足、应用程序或者服务出现异常,某些应用程序或者服务在某些时候进行了大量的TCP 连接操作。 | (Agent)network.tcp.connection_state | 边界以外 |
云数据库RDS定时任务导致的误报收敛
某用户业务运行过程中包含每日凌晨清理历史数据的定时任务,云数据库RDS的MySQL的QPS会在定时任务执行时瞬间飙升。单指标报警规则会在定时任务执行时触发误报,更改为智能阈值报警规则后不再出现定时误报情况。
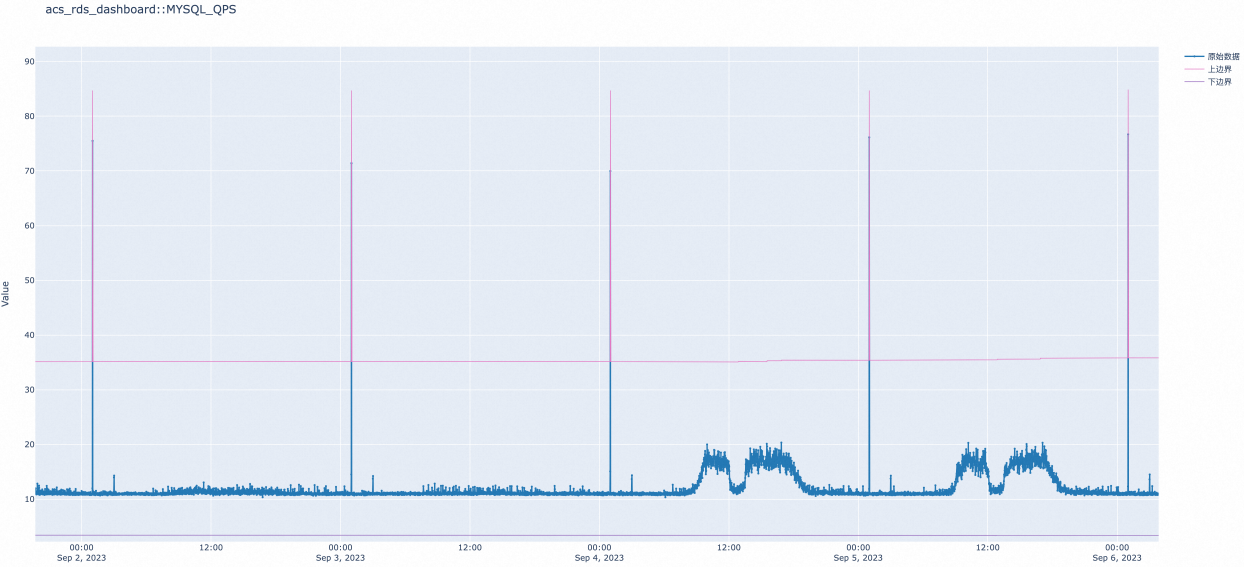
除了云数据库RDS的MySQL的QPS指标,还有其他指标也适用于定时任务的误报收敛,现推荐以下监控指标配置智能阈值报警规则。
典型异常 | 异常可能原因 | 监控指标 | 报警条件 |
典型异常 | 异常可能原因 | 监控指标 | 报警条件 |
RDS实例性能波动较大 | 系统负载过高或数据库连接池不足;应用程序或服务在某些时候进行了大量的查询操作。 |
| 高于上边界 |
对象存储OSS或CDN业务异常发现
作为业务的存储依赖和加速内容分发优化组件,对象存储OSS和CDN的异常会直接影响业务功能的可用性,但一般情况下应用可用性监控无法覆盖对象存储OSS和CDN组件的可用性,导致当对象存储OSS或CDN发生异常时无法触发报警。
例如:CDN的BPS发生跌零现象,智能阈值可以及时发现并召回CDN异常,并发送报警通知。
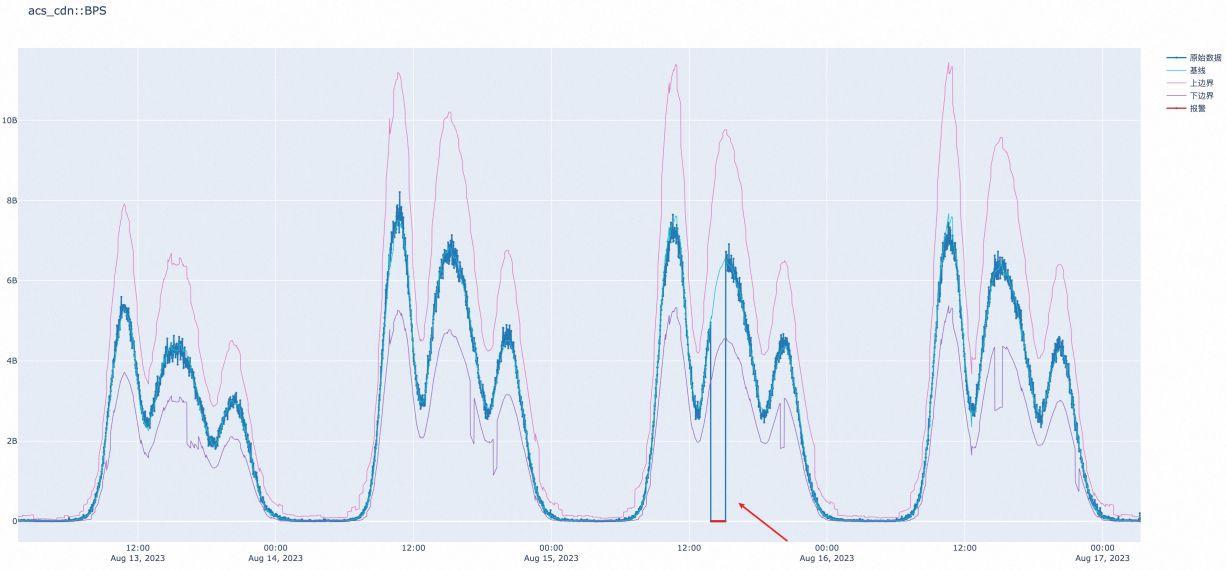
使用智能阈值报警规则可以快速的对对象存储OSS和CDN做监控报警覆盖,在服务不可用之前提前发现异常,现推荐以下监控指标配置智能阈值报警规则。
云产品 | 典型异常 | 异常可能原因 | 监控指标 | 报警条件 |
云产品 | 典型异常 | 异常可能原因 | 监控指标 | 报警条件 |
对象存储OSS | 请求成功数突降或请求错误数突增 | 网络连接不稳定或存在问题;对象存储OSS文件无权限、不存在等;API调用自身代码问题。 |
| 低于下边界 |
| 高于上边界 | |||
流量突增、流量突降、流量波动较大或流量持续峰值 | 网络连接不稳定或存在问题;应用程序或服务在某些时候发送了大量请求。 |
| 边界以外 | |
CDN | 访问量突增、访问量突降、访问量波动较大、访问量持续峰值或响应时间增加 | 系统负载过高、缓存不足、CDN节点不足;用户访问量突增;请求失败后大量请求重试等。 | 边缘网络带宽 每秒访问次数 下行流量 | 边界以外 |
边缘响应时间 | 高于上边界 | |||
命中率下跌 | 需要请求源站,加速失效 | 边缘字节命中率 | 低于下边界 |
消息队列Kafka版运维配置简化
由于消息队列Kafka版的部分监控指标(例如:实例消息发送次数、实例消息消费条数等)量级和业务相关,以及不同Group和Topic消息消费情况同样差异显著,使您难以设定一个通用的阈值适配不同业务下的消息队列监控,容易引发故障漏报或发现不及时等问题。
智能阈值可以凭借自动化报警能力简化报警规则配置和维护成本,2分钟~3分钟快速发现异常,有效降低业务的MTTR(故障恢复时长)。
例如:Kafka消息堆积量突增,智能阈值及时召回异常并报警。
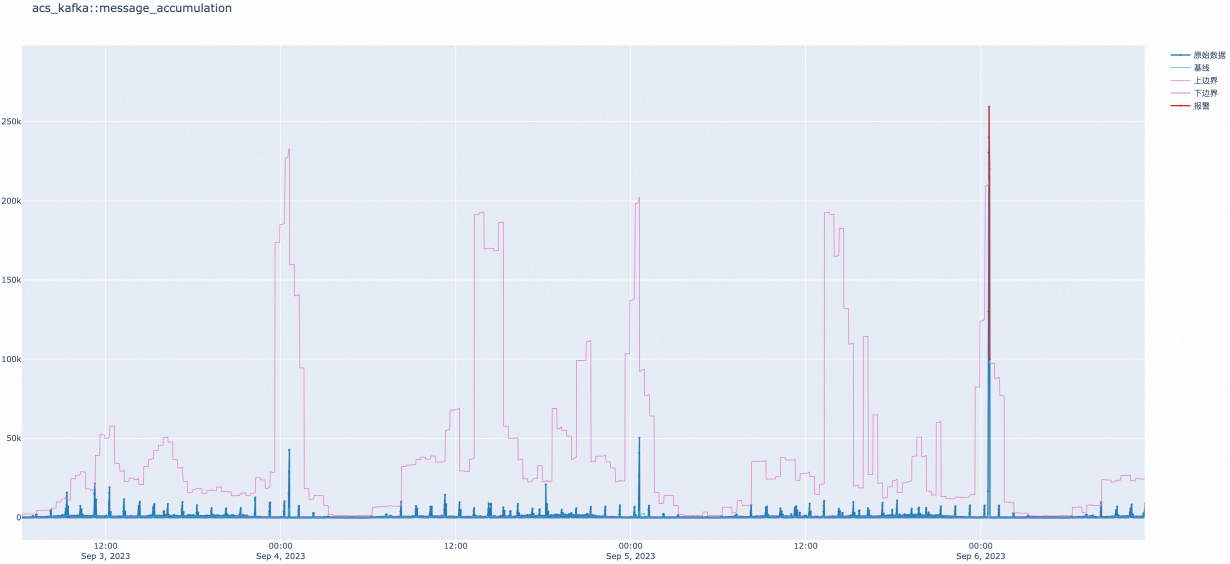
现推荐以下消息队列Kafka版的监控指标配置智能阈值报警规则。
典型异常 | 异常可能原因 | 监控指标 | 报警条件 |
典型异常 | 异常可能原因 | 监控指标 | 报警条件 |
流量突增或流量突降 | 大量用户访问应用程序或进行了某些大量数据传输的操作;应用程序出现了异常或者网络流量被恶意程序占用。 |
| 边界以外 |
消息堆积 | 系统资源不足、进程异常(死循环、内存泄露等)、进程数量突增、某些应用程序或系统服务在某些时候突然产生了大量的请求或数据处理操作。 |
| 高于上边界 |
连接数过高、连接数波动较大或连接数持续峰值 | 系统负载过高、TCP连接池不足、应用程序或服务出现异常、某些应用程序或服务在某些时候进行了大量的TCP连接操作。 |
| 边界以外 |
- 本页导读 (1)
- 什么是智能阈值
- 应用场景
- 产品优势
- 报警降噪
- 自动异常发现
- 降低阈值配置维护成本
- 最佳实践
- 云服务器ECS基础资源报警降噪
- 云数据库RDS定时任务导致的误报收敛
- 对象存储OSS或CDN业务异常发现
- 消息队列Kafka版运维配置简化
