
当您在面对大数据计算任务频繁且存在大量相似子查询场景时,DataWorks支持自动化治理,智能推荐物化视图,为您提供了一种智能化、自动化的解决方案。当您启用此功能时,DataWorks能够自动识别和分类MaxCompute中的相似子查询,并生成物化视图推荐,您可以按需一键生成物化视图,从而显著提升计算效率和节省计算资源。
功能介绍
DataWorks自动化治理中的物化视图功能依托于MaxCompute的物化视图推荐与管理能力,可快速扫描识别DataWorks调度场景下MaxCompute SQL中存在的大量相似子查询,并基于这些相似子查询推荐视图生成SQL用于快速创建物化视图。
视图创建完成后,DataWorks将同步创建产出视图数据的节点并发布至生产环境调度中,DataWorks上原存在相似子查询的下游节点将统一挂载在产出视图数据的节点下,依靠调度依赖关系,DataWorks会优先调度产出视图数据的节点,当下游节点使用公共子查询时,从已生成数据的物化视图中查询,以此减少数据的重复计算,达到治理目的。
支持地域:华东1(杭州)、华东2(上海)、华南1(深圳)、华北2(北京)、西南1(成都)。

前提条件
-
已新增MaxCompute数据源。详情请参见绑定MaxCompute计算资源。
-
已在MaxCompute中开启物化视图智能分析。详情请参见物化视图推荐与管理。
使用流程
-
开启物化视图推荐。
DataWorks数据开发模块中绑定的MaxCompute项目,开启物化视图推荐后,当需要满足以下条件时,将会在物化视图推荐页面生成物化视图推荐。
-
周期任务至少连续运行3天以上。
-
公共子查询中的输入数据量大于1,000,000行。
-
公共子查询中需要包含JOIN或AGG(聚合,Aggregation)等涉及数据重组计算的运算符。
-
-
查看物化视图推荐和创建物化视图。
您可以查看并判断其物化视图推荐是否合理,进行物化视图的创建治理任务。
如果创建物化视图时,配置了创建物化视图刷新节点和增加物化视图任务依赖,则物化视图创建成功后,将会在DataWorks调度场景下生效。
在具备相似计算的节点任务前,自动新增一个可动态刷新的物化视图节点,当原表任务或上游节点产出后,先进行物化视图刷新,产出最新数据,下游节点再从此物化视图中获取数据。
-
管理物化视图。
您可以管理本空间通过物化视图推荐创建的物化视图,查看本工作空间下物化视图的命中情况,对生效情况不符合预期的物化视图进行详情分析或删除。
操作步骤
步骤一:开启和停用物化视图推荐
开启和停用物化视图推荐需要工作空间管理员进行操作。
-
进入数据治理中心页面。
-
单击顶部治理工作台,然后在左侧导航栏单击物化视图。
-
选择工作空间后,单击物化视图推荐设置,在需要开启智能物化视图推荐的项目后开启智能推荐开关。
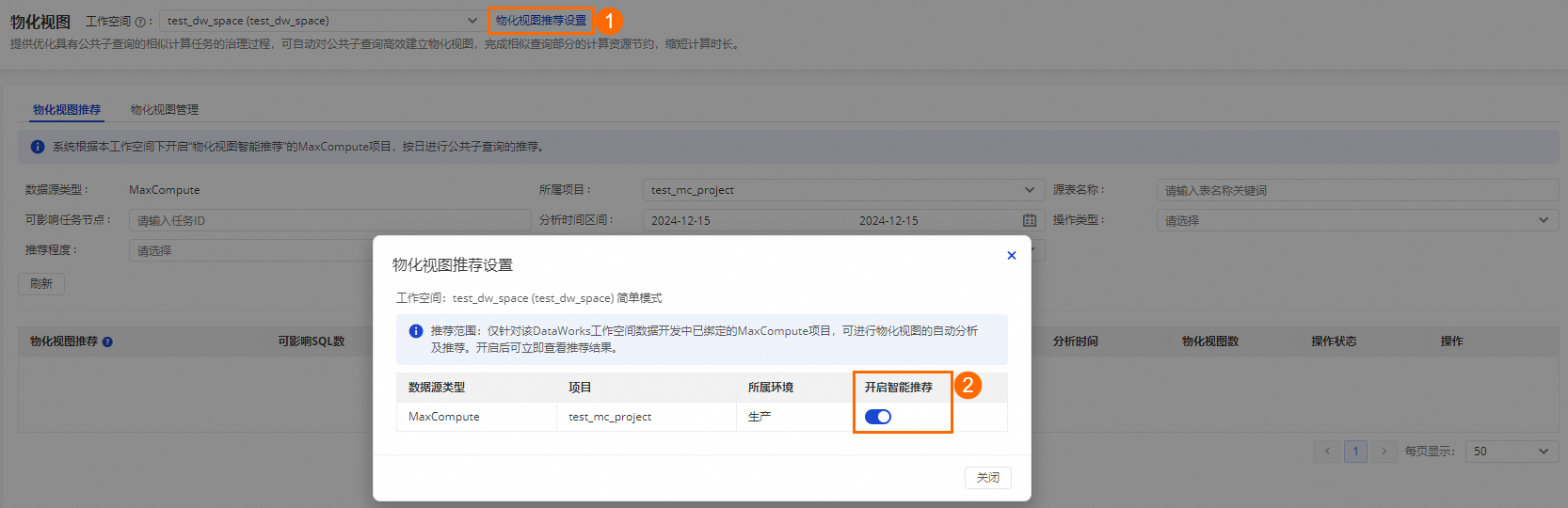
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在右侧页面中单击进入数据治理中心。
步骤二:查看物化视图推荐
该模块能够自动识别可创建的物化视图,以及其关联的计算任务,相关责任人可判定其是否合理,进行物化视图的创建治理。
为了更精准地生成物化视图推荐,开启物化视图推荐后,需要满足以下条件,才能在物化视图推荐页面查看到相关推荐。
-
周期任务至少连续运行3天以上。
-
公共子查询中的输入数据量大于1,000,000行。
-
公共子查询中需要包含JOIN或AGG(聚合,Aggregation)等涉及数据重组计算的运算符。
-
在的顶部切换工作空间,然后单击物化视图推荐页签。
-
修改所属项目、分析时间区间等筛选条件,查看是否有可推荐的物化视图生成项。
如果在分析时间区间存在可推荐的物化视图生成项,可查看如下信息。
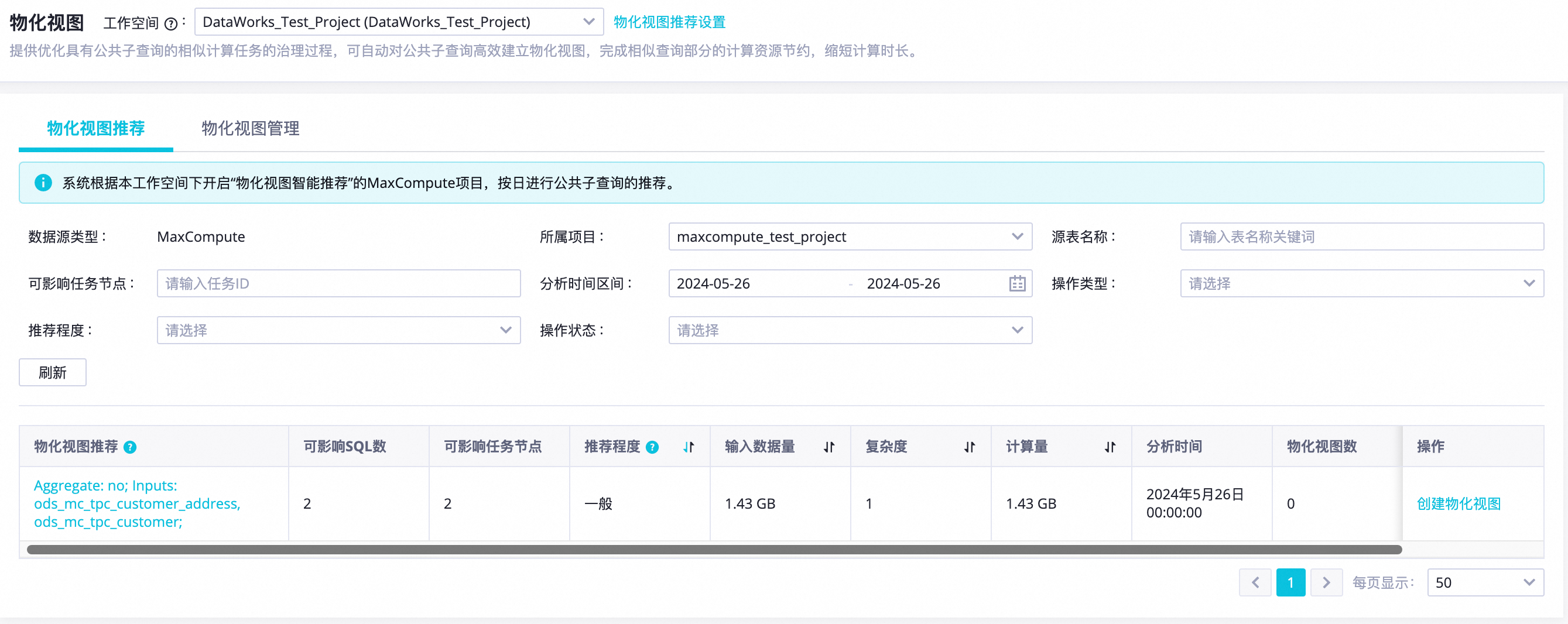
关键参数说明:
-
物化视图推荐列显示的物化视图推荐任务标识包含公共子查询的摘要信息。格式:
Aggregate: xx; Inputs: xx, xx;,其中:-
Aggregate:表示推荐的公共子查询是否包含聚合操作。
-
Inputs:列出公共子查询使用的所有源表表名称。
-
-
可影响SQL数:当前公共子查询被多少其他任务作业使用。
-
可影响节点数:当前公共子查询被多少调度节点使用。
-
推荐程度:基于子查询的重复次数、复杂度、输入记录数计算推荐程度。
-
-
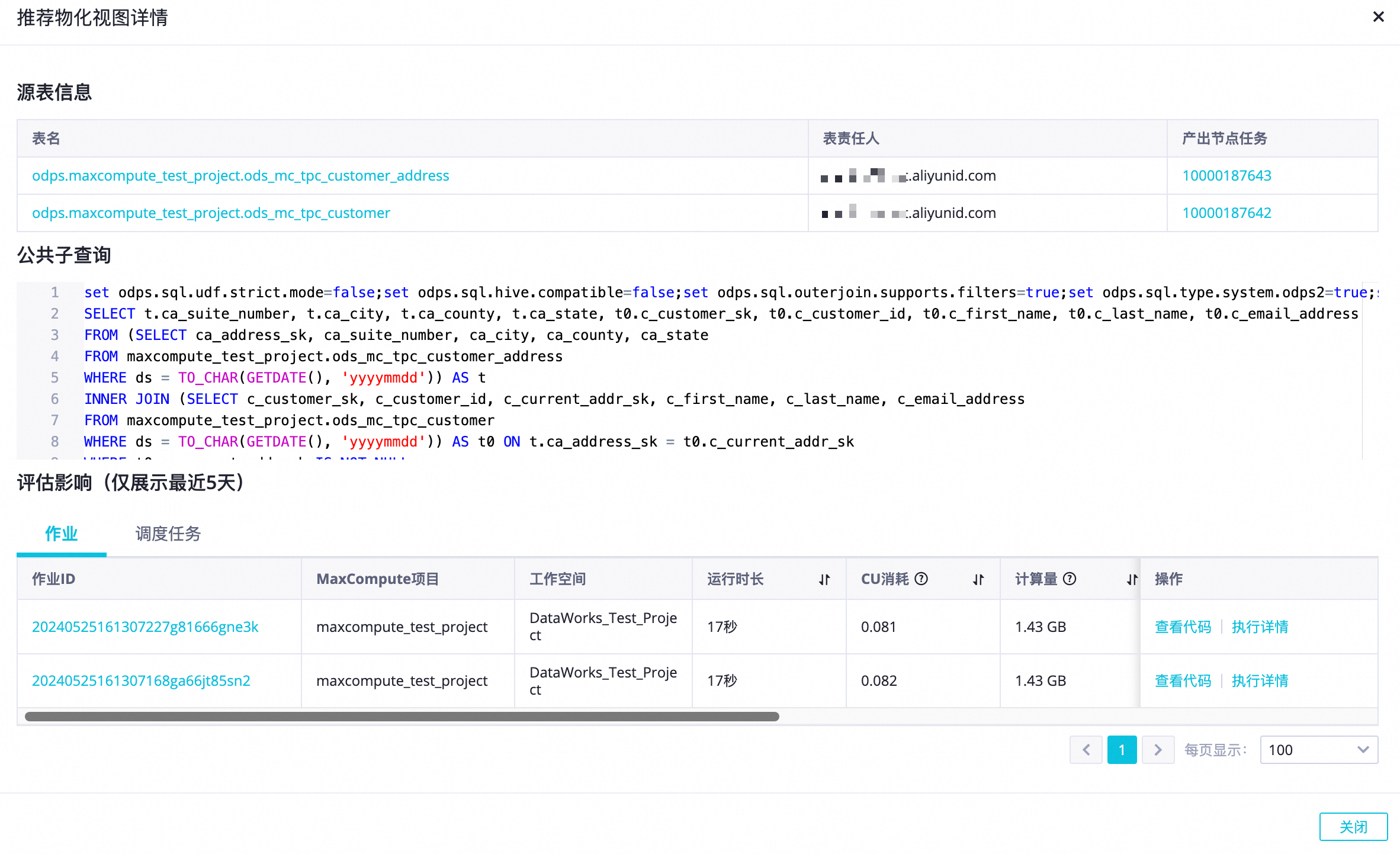
单击物化视图推荐列的任务标识,查看子查询的详细信息(源表信息、涉及的公共子查询以及相关作业及调度任务)。
步骤三:创建物化视图
-
结合实际业务需要与推荐详情,在物化视图推荐页面,选择是否创建物化视图。如需创建,单击操作列的创建物化视图。
-
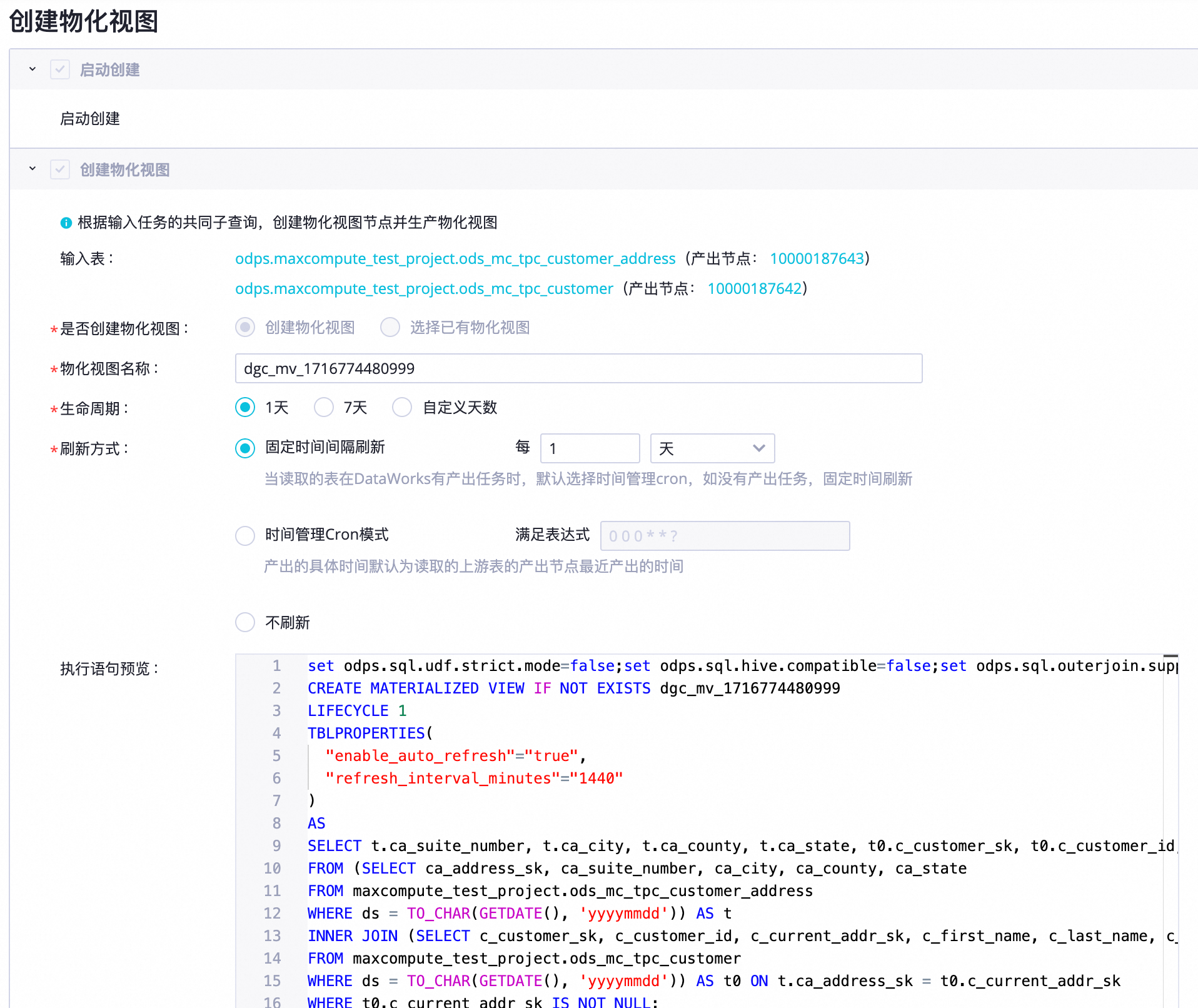
在创建物化视图页面配置物化视图的具体参数。
-
配置项-创建物化视图:根据输入任务的共同子查询,创建物化视图节点并生产物化视图。
参数
说明
输入表
自动获取,无需修改。
是否创建物化视图
首次创建时,默认为创建物化视图,无需修改。
说明如果已存在相同输入表的物化视图,则可按需配置选择已有物化视图。
物化视图名称
自定义。
生命周期
支持1天、7天和自定义天数。
刷新方式
物化视图的刷新方式。
-
固定时间间隔刷新
当读取的表在DataWorks有产出任务时,默认选择时间管理cron模式,如没有产出任务,固定时间刷新。
-
时间管理Cron模式
产出的具体时间默认为读取的上游表的产出节点最近产出的时间。
-
不刷新
执行语句预览
查看物化视图的SQL语句预览。
-
-
(可选)配置项-创建物化视图刷新节点:创建可动态刷新物化视图节点,原表任务产出后即可动态执行物化视图刷新,物化最新数据。
配置物化视图节点刷新名称和节点运行超时时间。

-
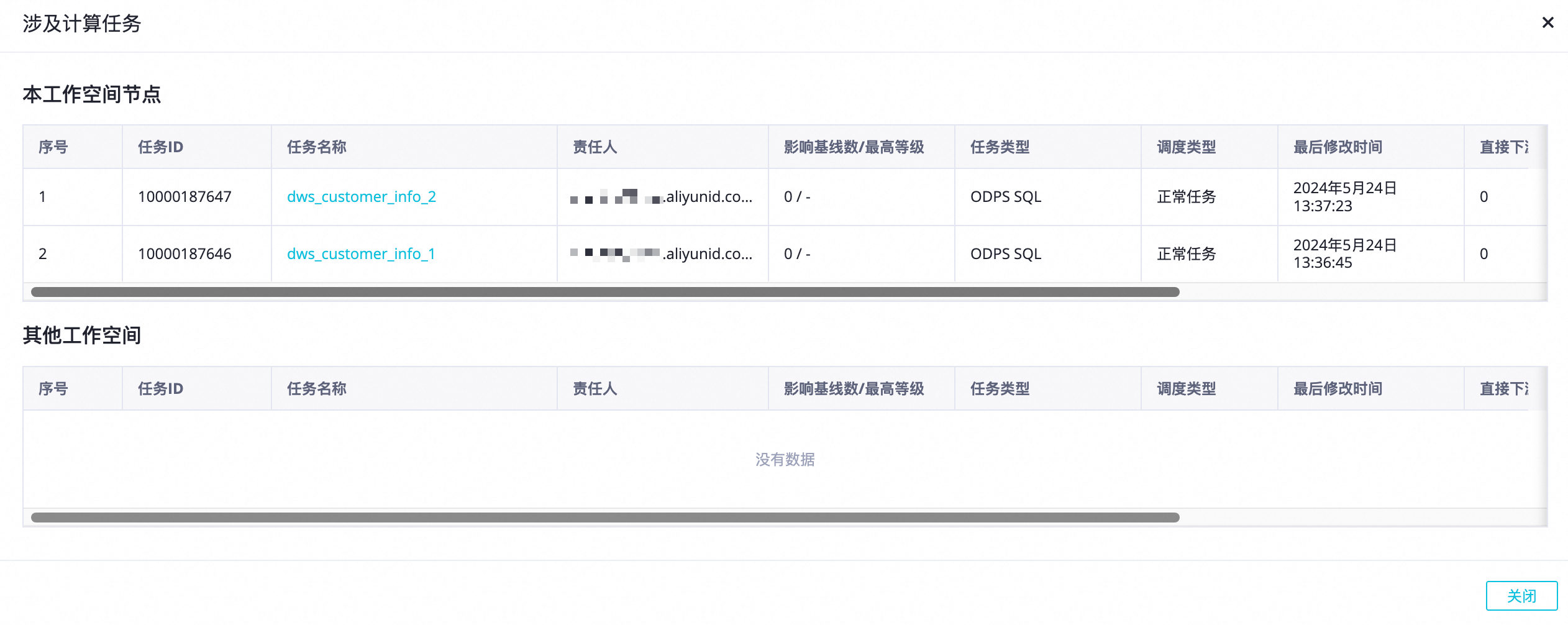
(可选)配置项-增加物化视图任务依赖:对具备相似计算的节点任务,增加物化视图节点任务为上游调度依赖节点,以提高增量数据的查询命中率。
该区域展示涉及的计算任务,包括本空间和其它空间的任务节点个数。你可以单击查看详情,查看具体的任务节点详情。
-
-
单击创建并执行,等待DataWorks自动创建物化视图,您可以在物化视图推荐页面的操作状态列查看创建状态,或单击操作列的查看详情查看具体创建进度。
-
操作状态包括:
-
待创建:未通过DataWorks发起物化视图创建。
-
已创建:物化视图创建成功。
-
创建中:已通过DataWorks发起物化视图创建流程,但尚未执行完成。
-
创建失败:已通过DataWorks发起物化视图创建流程,但中途出现创建失败的情况。
-
-
查看详情,展示物化视图创建详情。
-


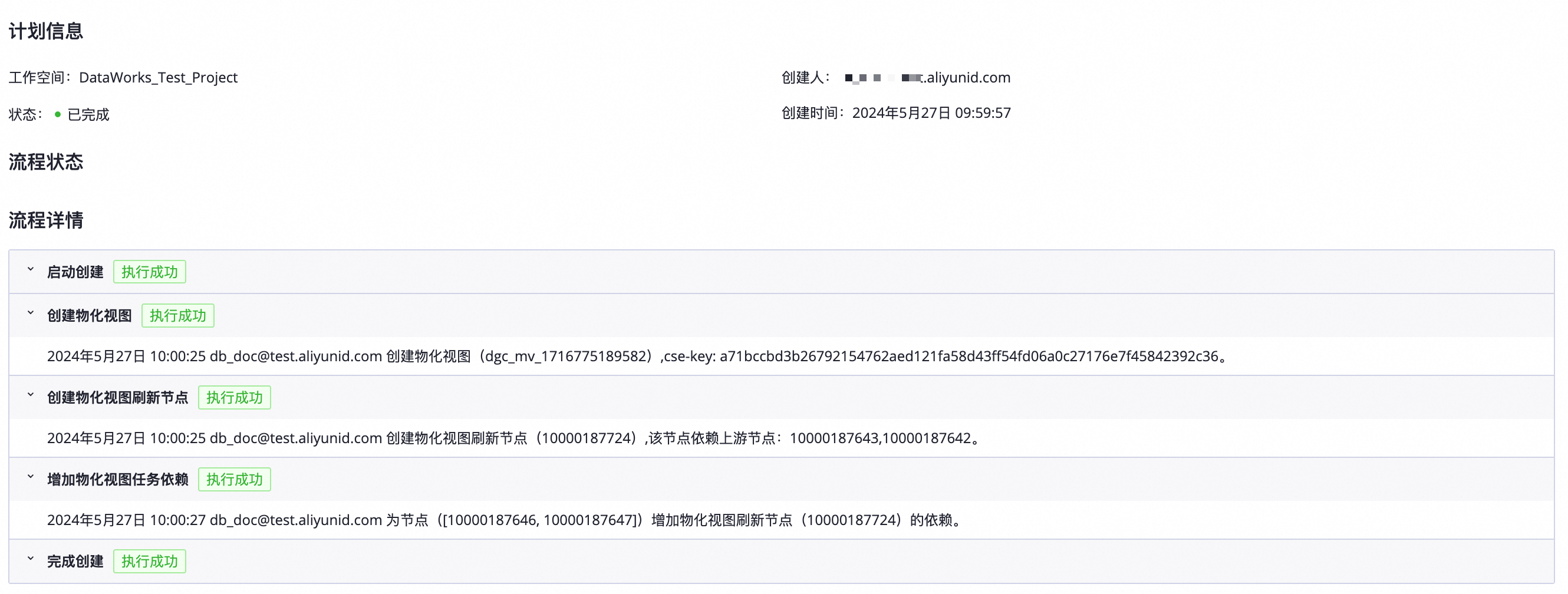
如果在创建物化视图时,配置了创建物化视图刷新节点和增加物化视图任务依赖,则在对应的任务流程中,具备相似计算的节点任务前,将新增一个物化视图刷新节点,该节点的责任人为创建物化视图的创建人。
步骤四:管理物化视图
您可以管理本空间通过物化视图推荐创建的物化视图,查看本工作空间下物化视图的命中情况,对未按预期生效的物化视图进行详情分析或删除。
-
在顶部切换工作空间,然后单击物化视图管理页签。
-
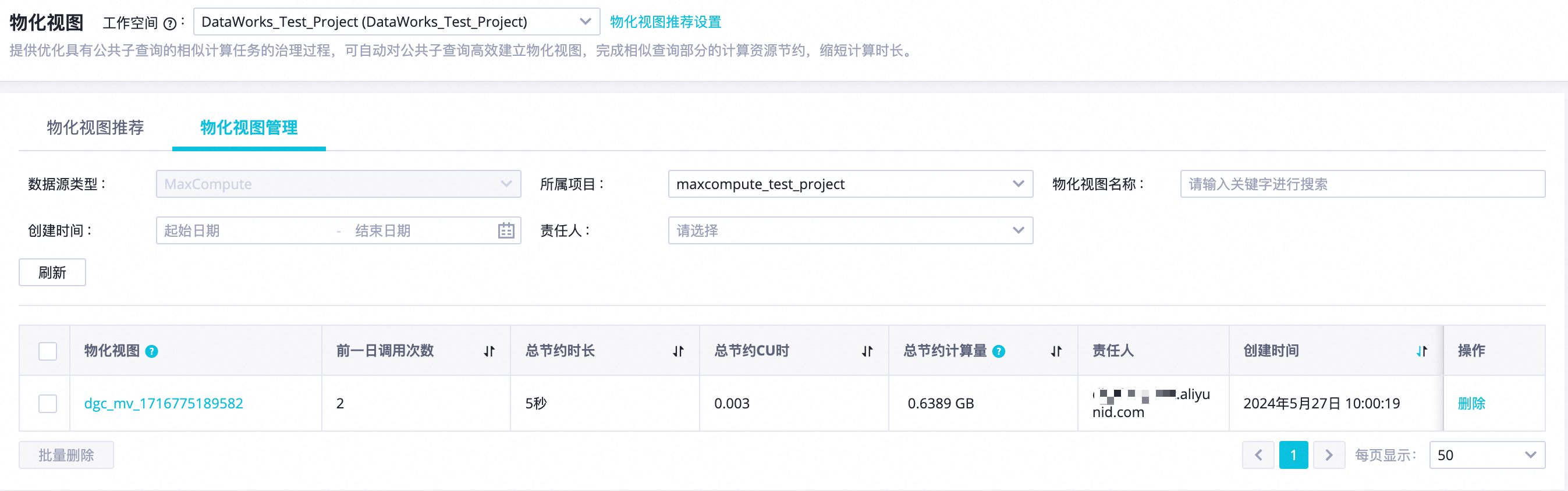
修改所属项目等筛选条件,查看已通过物化视图推荐创建的物化视图。
重要如果您MaxCompute项目的配额(Quota)为按量付费模式,则:
总节约计算量=计算输入数据量×SQL复杂度。MaxCompute SQL作业按照计算量×单价收取费用。详情请参见MaxCompute计算费用(按量付费)。-
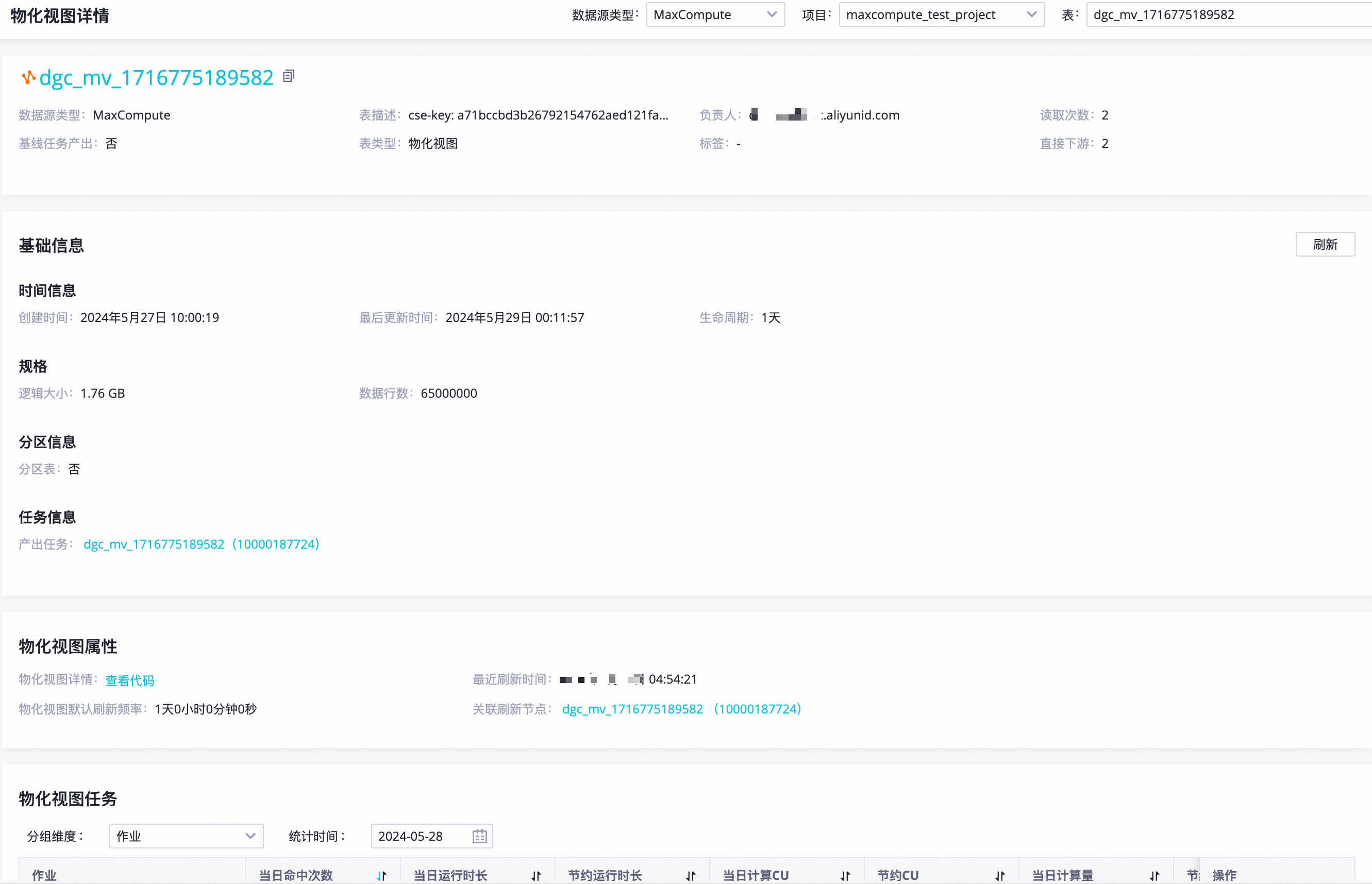
您可以单击物化视图列的物化视图标识,查看物化视图详情。
-
您可以单击操作列的删除,删除物化视图。
-
配置示例
本示例使用的测试数据来自MaxCompute公共数据集,具体请参见TPC-DS数据,实际使用时,请使用您的业务数据相关表进行配置。
数据准备
-
绑定MaxCompute计算资源并在中将其绑定。
-
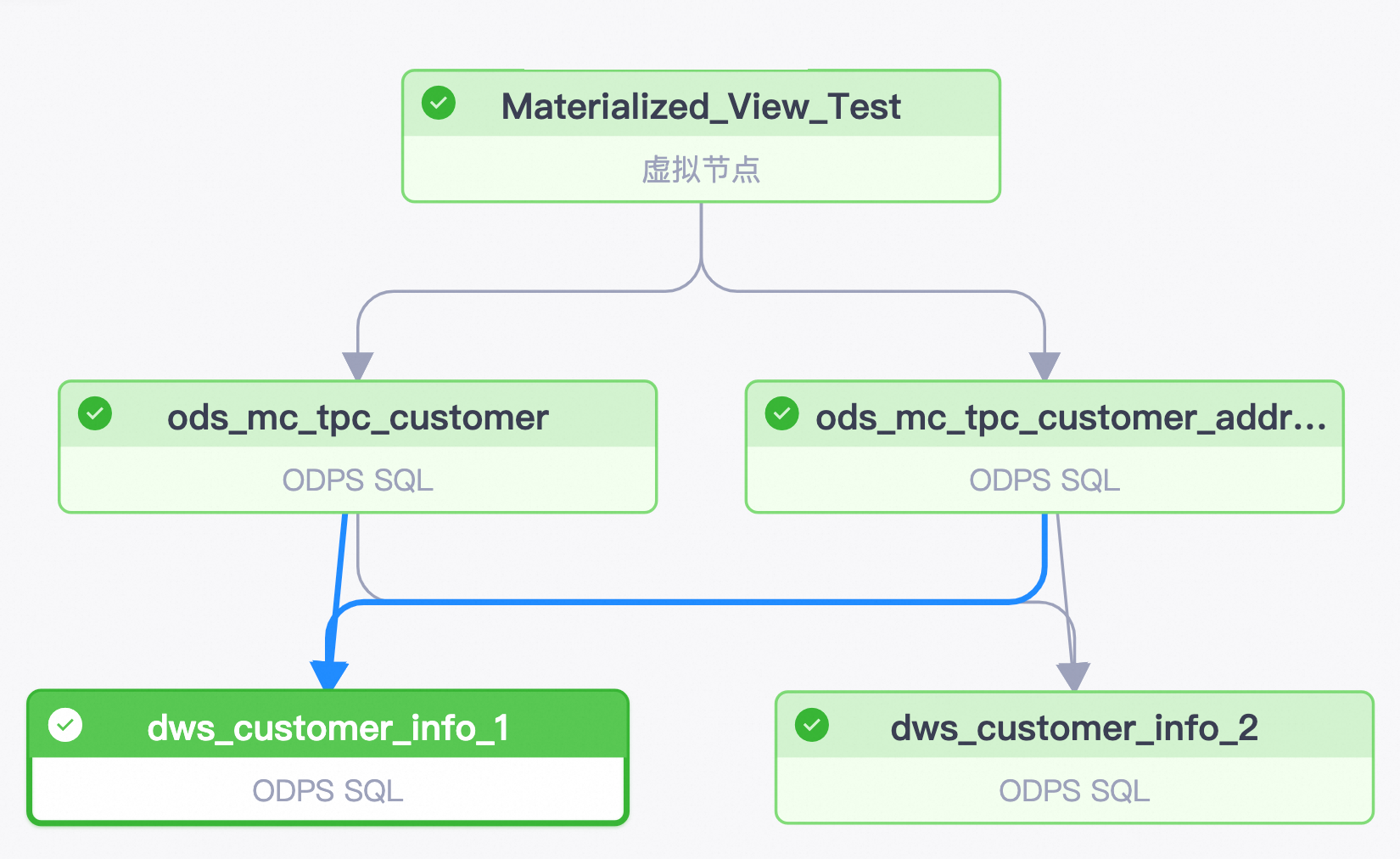
在数据开发中创建虚拟节点
Materialized_View_Test,作为下游任务的根节点。 -
在数据开发中按照示例分别创建四个ODPS节点。
其中,
dws_customer_info_1和dws_customer_info_2存在公共子查询,从ods_mc_tpc_customer和ods_mc_tpc_customer_address获取数据。ods_mc_tpc_customer
调度参数参数名为
bday,参数值为$[yyyymmdd]。CREATE TABLE IF NOT EXISTS ods_mc_tpc_customer ( c_customer_sk BIGINT NOT NULL ,c_customer_id CHAR(16) NOT NULL ,c_current_cdemo_sk BIGINT ,c_current_hdemo_sk BIGINT ,c_current_addr_sk BIGINT ,c_first_shipto_date_sk BIGINT ,c_first_sales_date_sk BIGINT ,c_salutation CHAR(10) ,c_first_name CHAR(20) ,c_last_name CHAR(30) ,c_preferred_cust_flag CHAR(1) ,c_birth_day BIGINT ,c_birth_month BIGINT ,c_birth_year BIGINT ,c_birth_country VARCHAR(20) ,c_login CHAR(13) ,c_email_address CHAR(50) ,c_last_review_date_sk CHAR(10) ) COMMENT 'TABLE COMMENT' PARTITIONED BY (ds STRING COMMENT '分区') LIFECYCLE 90; SET odps.namespace.schema=TRUE; INSERT OVERWRITE TABLE ods_mc_tpc_customer PARTITION(ds='${bday}') select * from BIGDATA_PUBLIC_DATASET.TPCDS_10T.customer;ods_mc_tpc_customer_address
调度参数参数名为
bday,参数值为$[yyyymmdd]。CREATE TABLE IF NOT EXISTS ods_mc_tpc_customer_address ( ca_address_sk BIGINT NOT NULL ,ca_address_id CHAR(16) NOT NULL ,ca_street_number CHAR(10) ,ca_street_name VARCHAR(60) ,ca_street_type CHAR(15) ,ca_suite_number CHAR(10) ,ca_city VARCHAR(60) ,ca_county VARCHAR(30) ,ca_state CHAR(2) ,ca_zip CHAR(10) ,ca_country VARCHAR(20) ,ca_gmt_offset DECIMAL(5,2) ,ca_location_type CHAR(20) ) COMMENT 'TABLE COMMENT' PARTITIONED BY (ds STRING COMMENT '分区') LIFECYCLE 90; SET odps.namespace.schema=TRUE; INSERT OVERWRITE TABLE ods_mc_tpc_customer_address PARTITION(ds='${bday}') select * from BIGDATA_PUBLIC_DATASET.TPCDS_10T.customer_address;dws_customer_info_1
调度参数参数名为
bday,参数值为$[yyyymmdd]。CREATE TABLE IF NOT EXISTS dws_customer_info_1 ( c_customer_sk BIGINT NOT NULL ,c_customer_id CHAR(16) NOT NULL ,c_first_name CHAR(20) ,c_last_name CHAR(30) ,c_email_address CHAR(50) ,ca_suite_number CHAR(10) ,ca_city VARCHAR(60) ,ca_county VARCHAR(30) ,ca_state CHAR(2) ) COMMENT 'TABLE COMMENT' PARTITIONED BY ( ds STRING COMMENT '分区' ) LIFECYCLE 90 ; INSERT OVERWRITE TABLE dws_customer_info_1 PARTITION (ds = '${bday}') SELECT t02.c_customer_sk ,t02.c_customer_id ,t02.c_first_name ,t02.c_last_name ,t02.c_email_address ,t03.ca_suite_number ,t03.ca_city ,t03.ca_county ,t03.ca_state FROM ( SELECT * FROM ods_mc_tpc_customer_address WHERE ds = '${bday}' ) t03 JOIN ( SELECT * FROM ods_mc_tpc_customer WHERE ds = '${bday}' ) t02 ON t03.ca_address_sk = t02.c_current_addr_sk ;dws_customer_info_2
调度参数参数名为
bday,参数值为$[yyyymmdd]。CREATE TABLE IF NOT EXISTS dws_customer_info_2 ( c_customer_sk BIGINT NOT NULL ,c_customer_id CHAR(16) NOT NULL ,c_first_name CHAR(20) ,c_last_name CHAR(30) ,c_email_address CHAR(50) ,ca_suite_number CHAR(10) ,ca_city VARCHAR(60) ,ca_county VARCHAR(30) ,ca_state CHAR(2) ) COMMENT 'TABLE COMMENT' PARTITIONED BY ( ds STRING COMMENT '分区' ) LIFECYCLE 90 ; INSERT OVERWRITE TABLE dws_customer_info_2 PARTITION (ds = '${bday}') SELECT t02.c_customer_sk ,t02.c_customer_id ,t02.c_first_name ,t02.c_last_name ,t02.c_email_address ,t03.ca_suite_number ,t03.ca_city ,t03.ca_county ,t03.ca_state FROM ( SELECT * FROM ods_mc_tpc_customer_address WHERE ds = '${bday}' ) t03 JOIN ( SELECT * FROM ods_mc_tpc_customer WHERE ds = '${bday}' ) t02 ON t03.ca_address_sk = t02.c_current_addr_sk ; -
保存并提交,发布到生产环境后,可以在运维中心看到周期任务流程如下:
开启物化视图
-
MaxCompute中开启物化视图智能分析。详情请参见物化视图推荐与管理。
-
在DataWorks治理中心中开启物化视图推荐。详情请参见步骤一:开启和停用物化视图推荐。
-
等待周期任务运行三天以上后,在DataWorks治理中心中查看物化视图推荐。
说明本示例使用的测试数据为TPC-DS数据的10T数据规格,满足物化视图推荐要求,如果您在物化视图推荐中未查看到已生成的推荐,请查看您的数据是否符合推荐要求:
-
周期任务至少连续运行3天以上。
-
公共子查询中的输入数据量大于1,000,000行。
-
公共子查询中需要包含JOIN或AGG(聚合,Aggregation)等涉及数据重组计算的运算符。
-
创建物化视图
-
单击物化视图推荐操作列的创建物化视图。详情请参见步骤三:创建物化视图。
说明默认已选中创建物化视图刷新节点和增加物化视图任务依赖,无需修改。
-
单击创建并执行,您可以在物化视图推荐页签,查看创建详情。
-
物化视图创建成功后,即可在下一次调度任务中看到,重复的子查询将从物化视图刷新节点中查询。
