
本案例将以视频社交平台的'猜你喜欢'和'详情页相关推荐'为例,通过推荐算法为用户呈现最符合其兴趣的视频内容为背景,为您介绍在DataWorks中如何使用阿里云PAI的协同过滤算法挖掘深层次的数据关联性,实现视频的个性化推荐。
背景信息
协同过滤算法是一种用于个性化推荐的技术,它可以基于用户间的行为相似性或物品间的相似性为用户推荐物。本案例中,I2I视频相似度模型算法将通过调用阿里云PAI中的协同过滤算法etrec完成,更多召回和排序算法您可参考EasyRec。
请注意,实际的推荐算法应用比本案例要复杂得多,本案例仅旨在为初学者提供一个推荐算法的基础教程。
注意事项
-
本案例提供的数据仅作为阿里云大数据开发治理平台DataWorks数据应用体验使用,所有数据均为模拟数据。
-
本案例可能会产生少量DataWorks调度费用、MaxCompute计算与存储费用和PAI计算费用。收费详情请参见DataWorks计费逻辑、MaxCompute计费逻辑、PAI Designer计费逻辑。
-
本案例通过命令建表,在实际开发中,您可通过DataWorks可视化功能创建,详情请参见:创建并使用MaxCompute表。
-
本案例中的,数据开发部分任务可以通过ETL工作流模板一键导入。在导入模板后,您可以前往目标工作空间,并自行完成后续操作。
-
仅空间管理员角色可导入ETL模板至目标工作空间,为账号授权空间管理员角色详情请参见空间级模块权限管控。
-
导入ETL工作流模板,详情请参见ETL工作流快速体验。
-
ETL工作流模板快捷入口,请点击视频个性化推荐(协同过滤)。
-
前提条件
-
已创建DataWorks工作空间,详情请参见创建工作空间。
-
DataWorks工作空间已开启调度PAI算法服务,若空间还未开启调度PAI算法,您可前往管理中心开启,详情请参见:管理控制概述。
-
已创建MaxCompute数据源并绑定至工作空间,详情请参见创建MaxCompute数据源并绑定至工作空间。
相关概念
-
I2I(Item-to-Item):基于item之间的相关性来推荐其他item的内容推荐算法,本案例中item特指视频。
-
U2I(User-to-Item):本案例中指用户对item(视频)的交互行为,如曝光、点击、点赞。
-
U2I2I召回:结合了 U2I(User-to-Item)和 I2I(Item-to-Item)推荐逻辑的表,用于存储推荐系统根据用户历史行为和物品相关性生成的召回列表。
-
召回(Recall):是推荐系统流程中的一步,它的目的是从大量候选物品中筛选出有可能对用户感兴趣的一个子集,本案例中物品特指视频。
-
视频交互方式(用户行为事件/event):“视频有曝光给用户”(expr)、“用户浏览了视频"(click)、“用户点赞了视频“(praise)
实施策略
实施策略如下:
-
相似视频挖掘(I2I):通过用户的视频交互行为数据挖掘视频与视频之间的相关性,您可基于此案例修改为您的数据来制作符合您业务场景的详情页相关内容推荐。
-
用户兴趣点发现(U2I):利用用户的视频交互历史数据,并结合时间衰减效应确定其兴趣点,即用户已经表达过感兴趣的视频。
-
视频个性化推荐构建与生成(U2I2I):基于兴趣点,再通过I2I(Item-to-Item)相关度模型算法扩展感兴趣的视频范围,精确计算用户对视频内容的兴趣得分,并根据此生成个性化推荐列表,以满足每位用户的独特偏好。
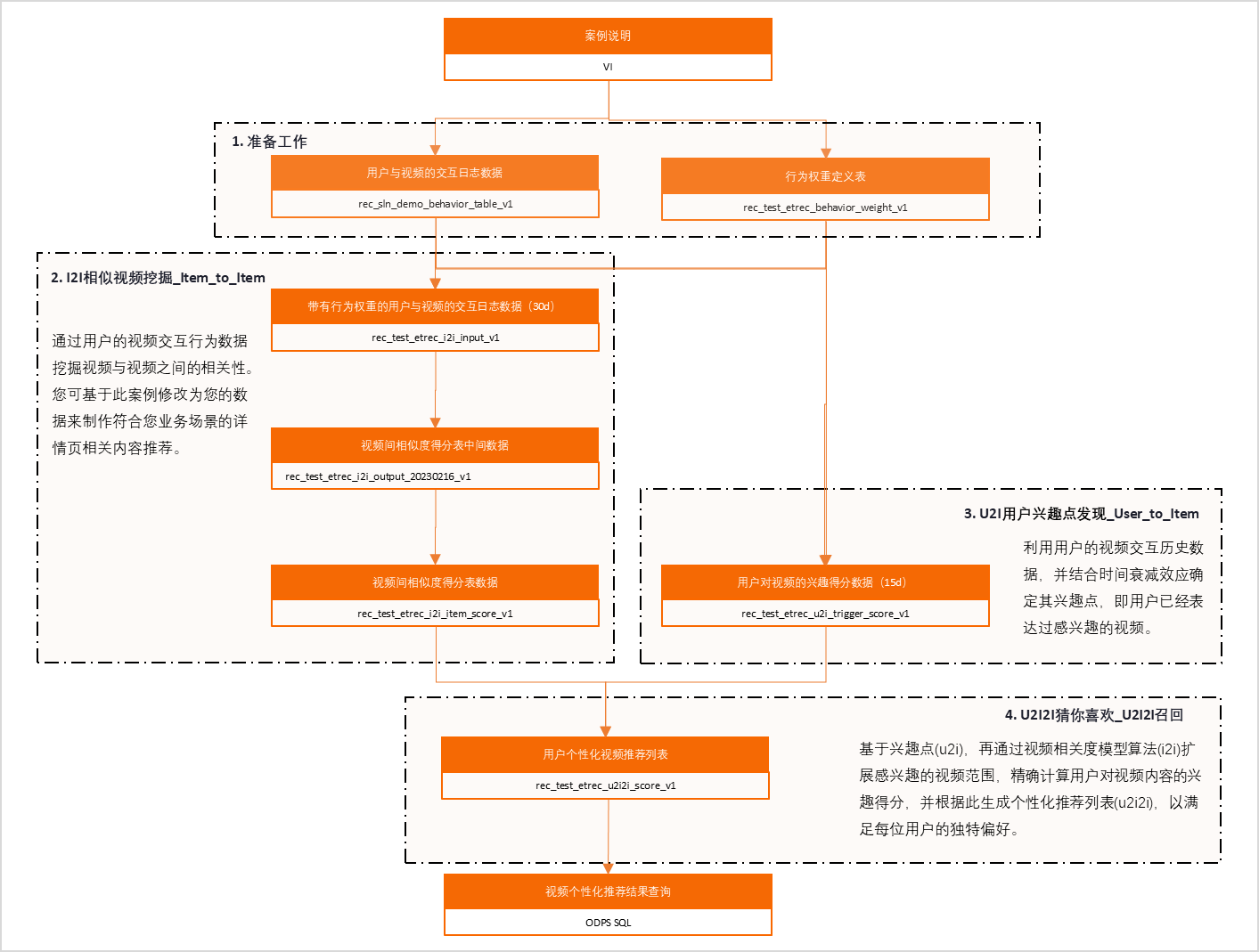
开发前准备
进入数据开发页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据开发。
-
创建业务流程。
-
鼠标悬停至
 图标,单击新建业务流程。
图标,单击新建业务流程。 -
在新建业务流程对话框中,输入业务名称和描述。本案例业务流程名为体验案例_视频个性化推荐。
-
单击新建。
-
-
新建节点。
在左侧目录树中,双击步骤2中创建的业务流程名称,进入业务流程面板,并通过拖拽组件以及拉线的方式在业务流程画布中编排整个流程。
本案例中会使用到两个类型节点:虚拟节点和ODPS SQL节点。
-
虚拟节点将作为整个视频个性化推荐业务流程的起始节点,用于管理整个业务流程;
-
ODPS SQL任务用于执行SQL任务数据计算及加工逻辑,其中视频相似度计算将通过在ODPS SQL节点代码中调用PAI-EasyRec算法服务实现。
-
-
任务流程图预览。
本案例预计将创建以下业务流程。其中,为便于快速辨别每一个任务加工逻辑,本案例使用节点组功能对节点进行分组,节点代码请参照后续步骤。
该业务流程包含以下阶段与节点:起始虚拟节点视频个性化推荐案例,数据准备阶段包含rec_sln_demo_behav和rec_test_etrec_beh节点,I2I相似视频挖掘阶段包含多个rec_test_etrec_i2i节点,U2I用户兴趣点发现阶段包含rec_test_etrec_u2i节点,U2I2I猜你喜欢阶段包含rec_test_etrec_u2i节点,最终汇聚到视频个性化推荐结果节点。在DataStudio中,双击左侧业务流程树中的体验案例_视频个性化推荐进入编辑,从中间节点面板将所需节点(ODPS SQL、虚拟节点等)拖拽至画布,并通过连线建立节点间的依赖关系。
任务开发:数据准备
-
本阶段需要创建一个虚拟节点和两个ODPS SQL节点:
-
虚拟节点:
视频个性化推荐案例说明。 -
两个ODPS SQL节点:
rec_sln_demo_behavior_table_v1和rec_test_etrec_behavior_weight_v1。
-
-
视频个性化推荐案例节点通过连线连接到数据准备分组中的两个SQL节点:❶ rec_sln_demo_behav...和❷ rec_test_etrec_beh...,即主节点依赖于这两个数据准备节点先完成执行。
rec_sln_demo_behavior_table_v1
-
表数据:用户与视频的交互日志数据表,该表记录了用户对各个视频内容的交互行为,每一行代表用户每一次视频交互记录。
-
节点说明:当前案例需要最近30天的用户与视频的交互日志数据进行训练,所以需要确保该表至少有30天的数据。阿里云PAI(公共数据集)已提供该数据,本节点将直接读取后写入。
-
在
rec_sln_demo_behavior_table_v1节点编辑页面,输入如下示例代码:-- 表定义:“用户与视频的交互日志数据” -- 表数据:该表记录了用户对各个视频内容的交互行为,每一行代表用户每一次视频交互记录与权重。 CREATE TABLE IF NOT EXISTS rec_sln_demo_behavior_table_v1 ( request_id STRING COMMENT '埋点ID/请求ID' ,user_id STRING COMMENT '用户唯一ID' ,exp_id STRING COMMENT '用户唯一ID' ,page STRING COMMENT '页面' ,net_type STRING COMMENT '网络型号' ,event_time BIGINT COMMENT '行为时间' ,item_id STRING COMMENT '内容ID' ,event STRING COMMENT '行为类型' ,playtime DOUBLE COMMENT '播放时长/阅读时长' ) COMMENT '视频个性化推荐(协同过滤)-用户与视频的交互日志数据' PARTITIONED BY ( ds STRING ) LIFECYCLE 7 ; -- 用户与视频的交互日志数据准备,原始数据由阿里云PAI提供,可直接读取。 INSERT OVERWRITE TABLE rec_sln_demo_behavior_table_v1 PARTITION (ds) SELECT * FROM pai_online_project.rec_sln_demo_behavior_table WHERE ds > "20221231" AND ds < "20230217" ;
rec_test_etrec_behavior_weight_v1
-
表数据:行为权重定义,用于记录用户行为事件(event)权重定义如下:
-
expr:视频有曝光给用户的行为,事件权重定义为0,即不考虑曝光事件。
-
click:用户浏览了视频的行为,权重定为1。
-
praise:用户点赞视频的行为,权重定为3。
-
-
节点说明:在实际训练前,需要定义视频浏览场景下各行为权重,将用户对某视频的不同行为,例如点赞、点击等进行量化,以此帮助算法准确评估用户对视频内容的兴趣强度。
-
在
rec_test_etrec_behavior_weight_v1节点编辑页面,输入如下示例代码:-- 表定义: “行为权重定义表” CREATE TABLE IF NOT EXISTS rec_test_etrec_behavior_weight_v1 ( event STRING ,weight DOUBLE COMMENT '行为权重' ) COMMENT '视频个性化推荐(协同过滤)-行为权重表' LIFECYCLE 7 ; -- 1. 数据写入:本案例将"用户浏览视频"(click)行为权重定为“1”;将"用户点赞视频"(praise)行为权重定为"3",将"视频有曝光给用户"(expr)权重定义为0"。 -- 2. 业务意义:用户与视频的交互日志数据关联该表后可为每个用户的每一次交互(例如点赞、点击等)赋予相应的权重,通过数值量化用户不同行为帮助算法准确评估用户对视频内容的兴趣强度。 INSERT OVERWRITE TABLE rec_test_etrec_behavior_weight_v1 VALUES ('expr',0.0) ,('click',1.0) ,('praise',3.0) ;
任务开发:相似视频挖掘(I2I)
-
本阶段需要创建三个ODPS SQL节点:
-
rec_test_etrec_i2i_input_v1节点。 -
rec_test_etrec_i2i_output_20230216_v1节点。 -
rec_test_etrec_i2i_item_score_v1节点。
-
-
数据准备区域的rec_sln_demo_behav...和rec_test_etrec_beh...节点分别连线至I2I相似视频挖掘区域的第一个rec_test_etrec_i2i...节点,I2I区域内三个rec_test_etrec_i2i...节点依次串联。
rec_test_etrec_i2i_input_v1
-
表数据:带有行为权重的用户与视频的交互日志数据表,该表记录了用户对各个视频内容的交互行为,并通过预先定义的行为权重量化了这些行为。
-
节点说明:将过去30天内的用户视频访问行为数据”rec_sln_demo_behavior_table_v1“与行为权重数据”rec_test_etrec_behavior_weight_v1“结合,生成带有行为权重的用户历史偏好统计数据(即带有量化了用户对视频的喜好程度的日志数据)写入到"rec_test_etrec_i2i_input_v1"表最新分区,本案例以写入20230216分区为例。
-
在
rec_test_etrec_i2i_input_v1节点编辑页面,输入如下示例代码:-- 1. 表定义:“带有行为权重的用户与视频的交互日志数据(30天)” -- 2. 表数据:该表记录了用户对各个视频内容的交互行为,并通过预先定义的行为权重量化了这些行为。 -- 每一行代表用户每一次视频交互记录与权重,即每条记录通常代表一个用户对一个视频的单次行为(例如,一次查看视频、一次点赞视频等)。 -- 若用户对同一个视频存在多次行为,那么该表会存储这个用户对该视频的多条行为记录。 -- 3. 业务意义:该表将作为物品间相关度(Item-to-Item,I2I)推荐引擎的输入数据,权重的引入可体现用户对视频不同行为 -- 在推荐系统中的影响力,可帮助算法准确评估用户对视频内容的兴趣强度。 CREATE TABLE IF NOT EXISTS rec_test_etrec_i2i_input_v1 ( user_id STRING COMMENT '用户ID' ,item_id STRING COMMENT '内容ID' ,event STRING COMMENT '行为类型' ,event_time BIGINT COMMENT '行为发生时间' ,weight DOUBLE COMMENT '行为权重' ) COMMENT '视频个性化推荐(协同过滤)-带有行为权重的用户与视频的交互日志数据' PARTITIONED BY ( ds STRING ) LIFECYCLE 7 ; -- 过去30天内的用户与视频的交互日志数据"rec_sln_demo_behavior_table_v1"与行为权重数据"rec_test_etrec_behavior_weight_v1"结合, -- 生成结合行为权重的历史偏好统计数据写入到rec_test_etrec_i2i_input_v1表最新分区,本案例以写入20230216分区为例。 INSERT OVERWRITE TABLE rec_test_etrec_i2i_input_v1 PARTITION (ds = '20230216') SELECT CAST(sq0.user_id AS STRING) user_id ,CAST(sq0.item_id AS STRING) item_id ,sq0.event ,sq0.event_time ,sq1.weight FROM ( -- 获取过去30天的用户视频访问行为数据 SELECT * FROM rec_sln_demo_behavior_table_v1 WHERE ds > TO_CHAR(DATEADD(TO_DATE('20230216','yyyymmdd'),-30,'dd'),'yyyymmdd') AND ds <= '20230216' ) sq0 JOIN ( -- 去除"视频有曝光给用户"(expr)事件数据、保留"用户浏览了视频"(click)、"用户点赞了视频"(praise)的事件数据 SELECT * FROM rec_test_etrec_behavior_weight_v1 WHERE weight > 0 ) sq1 ON sq0.event = sq1.event ;
rec_test_etrec_i2i_output_20230216_v1
-
表数据:视频间相关度得分临时表,该表包含每个视频内容与其他视频内容之间的相关度得分,每一行记录某个视频与其相关度最高的N个视频。
-
节点说明:使用阿里云PAI协同过滤算法PAI—eTrec,基于带有行为权重的用户与视频的交互日志数据”rec_test_etrec_i2i_input_v1“计算视频间相关度,得分数据写入rec_test_etrec_i2i_output_20230216_v1表。
-
在
rec_test_etrec_i2i_output_20230216_v1节点编辑页面,输入如下示例代码:-- 当前节点将产出"rec_test_etrec_i2i_output_20230216_v1"表数据 -- 1. 表定义:"视频间相关度得分临时表" -- 2. 表数据:该表包含每个视频内容与其他视频内容之间的相关度得分,每一行记录某个视频与其相关度最高的N个视频。 -- 3. 业务意义:通过相关性度量方法来计算矩阵中视频内容之间的相关性,这些得分由阿里云PAI提供的协同过滤算法PAI-eTrec根据用户交互行为和设定的权重计算得出。 -- 删除之前可能存在的以2023年2月16日为分区的item-to-item输出表,以便本次算法运行可正常创建该表并往该表写入数据。 DROP TABLE IF EXISTS rec_test_etrec_i2i_output_20230216_v1 ; -- 使用PAI命令进行item-to-item计算 -- 1. 数据流:使用阿里云PAI协同过滤算法PAI-eTrec,基于带有行为权重的用户与近30天用户与视频的交互日志数据"rec_test_etrec_i2i_input_v1"计算视频间相关度,得分数据写入表"rec_test_etrec_i2i_output_20230216_v1"。 -- 2. 其中,-DtopN代表每个视频仅返回与之最相关的前100个视频。更多参数说明,请参见:https://help.aliyun.com/document_detail/172063.html PAI -name pai_etrec -project algo_public -DinputTableName="rec_test_etrec_i2i_input_v1" -DinputTablePartitions="ds=20230216" -DuserColName="user_id" -DitemColName="item_id" -DsimilarityType="wbcosine" -DtopN="100" -DmaxUserBehavior="1000" -DminUserBehavior="2" -Doperator="add" -DitemDelimiter=";" -DkvDelimiter="," -DoutputTableName="rec_test_etrec_i2i_output_20230216_v1" -Dlifecycle="7" ; -- 查询视频间相关度得分表"rec_test_etrec_i2i_output_20230216_v1" -- 表中的每一行代表一个特定的视频(itemid),以及与该视频相关的一组其他视频及它们的相关度得分(similarity), ------------------------------------------------------------------- -- itemid similarity -- 视频1的ID 相关视频2的id:相关视频2的得分;相关视频3的视频id:相关视频3的得分 ------------------------------------------------------------------- -- select * from rec_test_etrec_i2i_output_20230216_v1 limit 10;
rec_test_etrec_i2i_item_score_v1
-
表数据:视频间相关度得分数据,每一行都表示两个视频之间的一个唯一的相关度得分,对rec_test_etrec_i2i_output_20230216_v1表数据进行拆分展平。
-
节点说明:将相关度得分数据"rec_test_etrec_i2i_output_20230216_v1"进行了转换和简化,以便于后续的查询和使用,具体转换和简化策略,请分别打开当前节点及上游节点”rec_test_etrec_i2i_output_20230216_v1“对比查看。
-
在
rec_test_etrec_i2i_item_score_v1节点编辑页面,输入如下示例代码:-- 表定义:视频间相关度得分数据(拆分similarity字段) -- 表数据:每一行都表示两个视频之间的一个唯一的相关度得分 CREATE TABLE IF NOT EXISTS rec_test_etrec_i2i_item_score_v1 ( trigger_id STRING COMMENT '触发推荐的视频id(I2I中的左边的item)' ,item_id STRING COMMENT '基于触发推荐的视频trigger_id,计算出与其相关的视频' ,item_score STRING COMMENT '基于用户的共同观看行为计算得到的上述两个视频的相关度评分' ) COMMENT '视频个性化推荐(协同过滤)-视频间相关度得分数据(eTrec I2I item score)' PARTITIONED BY ( ds STRING ) LIFECYCLE 7 ; -- 加工过程:对视频间相关度得分表中间表"rec_test_etrec_i2i_output_20230216_v1"的"similarity"字段进行拆分, -- 写入视频间相关度得分表"rec_test_etrec_i2i_item_score_v1"最新分区,本案例以写入20230216分区为例。 -- 拆分目的:让每一对相关视频及其得分都被单独一行存储,便于使用这些得分来构建推荐。 INSERT OVERWRITE TABLE rec_test_etrec_i2i_item_score_v1 PARTITION (ds = '20230216') SELECT itemid trigger_id ,SPLIT(itemid_score,',')[0] item_id ,SPLIT(itemid_score,',')[1] item_score FROM rec_test_etrec_i2i_output_20230216_v1 LATERAL VIEW EXPLODE(SPLIT(similarity,';')) subview0 AS itemid_score ; -- 查询拆分后的视频间相关度得分表数据rec_test_etrec_i2i_item_score_v1 ------------------------------------------------------------------- -- trigger_id item_id item_score -- 视频1的ID 相关视频2的id 相关视频2的得分 -- 视频1的ID 相关视频3的id 相关视频3的得分 ------------------------------------------------------------------- -- select * from rec_test_etrec_i2i_item_score_v1 where ds = '20230216';
任务开发:用户兴趣点发现(U2I)
-
本阶段需要创建一个ODPS SQL节点:
rec_test_etrec_u2i_trigger_score_v1节点。 -
在工作流画布中,从数据准备区域的 rec_test_etrec_beh... 节点的输出端拖出连线,连接到U2I用户兴趣点发现区域的 rec_test_etrec_u2i... 节点的输入端,建立两个节点之间的依赖关系。
rec_test_etrec_u2i_trigger_score_v1
-
表数据:用户对视频的兴趣得分数据表,从U2I中通过数值量化用户对各个视频内容的兴趣程度,对用户和某视频的所有单次行为记录权重进行汇总,代表用户对某视频的喜好程度。
-
节点说明:基于用户近15天的视频访问行为数据“rec_sln_demo_behavior_table_v1”与行为权重数据"rec_test_etrec_behavior_weight_v1“,并考虑时间衰减因素,计算得出用户对各视频内容的兴趣得分,并为每个用户保留得分最高的100个视频,推荐的视频信息写入"rec_test_etrec_u2i_trigger_score_v1"。
-
在
rec_test_etrec_u2i_trigger_score_v1节点编辑页面,输入如下示例代码:-- 1. 表定义:“用户对视频的兴趣得分数据”。 -- 2. 表数据:从用户行为中派生出的感兴趣的视频得分(User-to-Item,U2I),通过数值量化用户对各个视频内容的兴趣程度,这些数值(得分),表示用户的偏好,表中存储的每一行记录代表1个用户对1个视频的兴趣得分,通过汇总每个用户和每个视频的所有单次行为权重计算用户对视频的感兴趣程度(用户的历史偏好)。 -- 3. 业务意义:后续该表将被用来为用户推荐他们可能感兴趣的视频内容。 CREATE TABLE IF NOT EXISTS rec_test_etrec_u2i_trigger_score_v1 ( user_id STRING COMMENT '用户ID' ,item_id STRING COMMENT '用户交互过的视频ID' ,trigger_score DOUBLE COMMENT '用户对于视频的偏好得分,即通过数值量化用户对视频的兴趣程度或者偏好强度。得分基于用户的历史行为数据(如视频点击、点赞等)和行为权重(如视频点击权重为1,点赞行为权重为3)计算得出的。例如,如果一个用户多次点击观看某个视频,则这个视频的偏好得分会更高。' ,rk BIGINT COMMENT '得分排序,表示根据用户对视频的感兴趣程度按照触发得分从高到低的顺序进行排名,有助于在推荐场景中对用户优先推荐得分高的视频。' ) COMMENT '视频个性化推荐(协同过滤)-用户对视频的兴趣得分数据' PARTITIONED BY ( ds STRING ) LIFECYCLE 7 ; -- 基于用户行为数据“rec_sln_demo_behavior_table_v1”与行为权重数据"rec_test_etrec_behavior_weight_v1“,并考虑时间衰减因素,计算得出用户对各视频内容的兴趣得分, -- 并为每个用户保留得分最高的100个视频写入rec_test_etrec_u2i_trigger_score_v1。 -- 1. 选择行为数据:从用户行为数据“rec_sln_demo_behavior_table_v1”中选择最近15天的用户行为数据,确保推荐是基于用户当前的行为趋势。 -- 2. 关联行为权重:将用户行为数据与"rec_test_etrec_behavior_weight_v1”权重数据进行连接,为每种事件(例如点击、点赞)赋予预先定义好的权重,去除曝光记录。 -- 3. 应用时间衰减:用DATEDIFF函数计算行为发生时间与当前日期的差距,并应用时间衰减函数来调整行为权重。时间衰减函数通过指数衰减使旧的行为对总得分的贡献变得更小, -- 保证推荐系统能够适应用户兴趣的变化,即可基于用户最新喜好为用户推荐视频。 -- 4. 计算得分:对每个用户和每个视频(user_id, item_id)的行为权重进行求和,计算总的触发得分trigger_score。如果用户对同一个视频有多个行为记录, -- 这些行为的权重都将被累加以得出最终的 trigger_score。 -- 5. 排序和取TopN:使用ROW_NUMBER()函数,按trigger_score降序排列来对每个用户的视频得分进行排序。每个用户的得分和排序反映了对该用户最有吸引力的视频内容, -- 推荐系统可以利用这些数据来生成个性化的视频推荐。 INSERT OVERWRITE TABLE rec_test_etrec_u2i_trigger_score_v1 PARTITION (ds = '20230216') SELECT * FROM ( SELECT CAST(sq2.user_id AS STRING) user_id ,CAST(sq2.item_id AS STRING) item_id -- 对每个用户和每个视频(user_id, item_id)的行为权重进行求和,计算总的触发得分trigger_score。如果用户对同一个视频有多个行为记录,这些行为的权重都将被累加以得出最终的 trigger_score。 ,SUM(sq2.weight) trigger_score -- 使用ROW_NUMBER()函数按得分降序排名 ,ROW_NUMBER() OVER (PARTITION BY sq2.user_id ORDER BY SUM(sq2.weight) DESC ) rk FROM ( SELECT sq0.user_id ,sq0.item_id -- 通过指数衰减函数 EXP(-0.2 * 时间差) 来调整行为的权重 ,sq1.weight * EXP(-0.2 * DATEDIFF(TO_DATE('20230216','yyyymmdd'),TO_DATE(ds,'yyyymmdd'),'dd')) weight FROM ( -- 获取最近15天的行为数据,确保推荐是基于用户当前的行为趋势,即确保推荐的是符合用户当前的喜好的视频 SELECT * FROM rec_sln_demo_behavior_table_v1 WHERE ds > TO_CHAR(DATEADD(TO_DATE('20230216','yyyymmdd'),-15,'dd'),'yyyymmdd') AND ds <= '20230216' ) sq0 JOIN ( -- 去除权重为0的行为,后续将从行为数据中去除那些视频投放记录中有推送给用户,但用户未点击查看视频的记录 SELECT * FROM rec_test_etrec_behavior_weight_v1 WHERE weight > 0 ) sq1 ON sq0.event = sq1.event ) sq2 GROUP BY sq2.user_id ,sq2.item_id ) sq3 WHERE sq3.rk <= 100 ;
任务开发:猜你喜欢(U2I2I)
-
本阶段需要创建两个ODPS SQL节点:
-
rec_test_etrec_u2i2i_score_v1节点。 -
视频个性化推荐结果查询节点。
-
-
工作流DAG从顶部虚拟节点视频个性化推荐案例向下分支至数据准备区域的两个SQL节点,再连接到I2I相似视频挖掘区域的三个串联SQL节点;右侧U2I用户兴趣点发现区域的SQL节点同样向下连接至U2I2I猜你喜欢区域的SQL节点。需将I2I相似视频挖掘的最后一个节点拖拽连线至U2I2I猜你喜欢节点,建立依赖关系。
视频个性化推荐构建与生成的数据加工逻辑:
-
结合U2I与I2I得分:对于每个用户,选择其触发得分较高的视频(即用户有明显兴趣的视频),并找到与这些视频相关的其他视频及其相关度得分。
-
计算推荐得分:通过用户对一个已经表达过感兴趣的视频(触发视频得分)与该视频与其他视频的相关度得分(I2I)之间的乘积。这个乘积代表了用户可能对其他某个视频感兴趣程度。
-
汇总与排序:对于每个用户,对所有视频的计算结果进行汇总,得到每个其他视频的综合得分。
rec_test_etrec_u2i2i_score_v1
-
表数据:用户个性化视频推荐列表,该表包含用户已显示出兴趣的视频(用户的历史偏好),也有用户可能会感兴趣的其他视频(推测喜好)。
-
节点说明:基于用户对视频的直接兴趣得分(U2I,User-to-Item),即用户对这些视频的兴趣程度数据“rec_test_etrec_u2i_trigger_score_v1”,以及视频间的相关度得分,即两个视频内容的相似程度数据(I2I,即 Item-to-Item)"rec_test_etrec_i2i_item_score_v1",生成最终的个性化推荐列表数据写入"rec_test_etrec_u2i2i_score_v1"。
-
在
rec_test_etrec_u2i2i_score_v1节点编辑页面,输入如下示例代码:-- 1. 表定义:“用户个性化视频推荐列表”。在算法场景下该表属性为:U2I2I召回表。 -- 2. 表数据:该表存储了最终的个性化推荐列表。 -- 3. 业务意义:基于用户的视频喜好数据,用户已显示出兴趣的视频(用户的历史偏好(User-to-Item,U2I)), 并通过视频内容的相关 -- 性来扩展推荐范围,推荐用户可能会感兴趣的其他视频(基于内容的推荐(Item-to-Item,I2I)),提供一种更综合的个性化视频推荐列表。 CREATE TABLE IF NOT EXISTS rec_test_etrec_u2i2i_score_v1 ( user_id STRING COMMENT '用户ID' ,item_ids STRING COMMENT '根据u2i2i计算得到topN的视频,其中包含了推荐的视频ID和视频对应的得分,格式为物品ID:得分。物品ID和得分之间用冒号:分隔,而不同的物品得分对则使用逗号,分隔。' ) COMMENT '视频个性化推荐(协同过滤)-用户个性化视频推荐列表(eTrec u2i2i召回表)' PARTITIONED BY ( ds STRING ) LIFECYCLE 7 ; -- 1. 数据流:基于用户对视频的直接兴趣得分(U2I,User-to-Item),即用户对这些视频的兴趣程度数据“rec_test_etrec_u2i_trigger_score_v1”, -- 以及视频间的相关度得分(I2I,Item-to-Item),即两个视频内容的相关程度数据(例如视频内容相关程度)"rec_test_etrec_i2i_item_score_v1", -- 生成最终的个性化推荐列表数据写入"rec_test_etrec_u2i2i_score_v1" -- 2. 加工逻辑: -- 2.1 结合U2I与I2I得分:对于每个用户,选择其触发得分较高的视频(即用户有明显兴趣的视频),并找到与这些视频相关的其他视频及其相关度得分。 -- 2.2 计算推荐得分:通过用户对一个已经表达过感兴趣的视频(触发视频得分)与该视频与其他视频的相关度得分(I2I)之间的乘积。这个乘积代表了用户可能对其他某个视频感兴趣程度。 -- 2.3 汇总与排序:对于每个用户,对所有视频的计算结果进行汇总,得到每个其他视频的综合得分。 -- 3. 排序和筛选: -- 3.1 Top-N排序:对计算出的视频综合得分进行降序排序,并筛选出得分最高的前100个视频。 -- 3.2 排名:使用窗口函数ROW_NUMBER()按用户分组进行排序,并且对每个用户,只保留综合得分最高的100个视频。 -- 注意:本案例最终推荐结果中包含用户已看过的视频,您可再次加工从推荐列表中去除已看过的视频。 INSERT OVERWRITE TABLE rec_test_etrec_u2i2i_score_v1 PARTITION (ds = '20230216') SELECT sq3.user_id -- 将每个用户的推荐视频和相应的得分通过':'合并成一个单独的字段 ,WM_CONCAT(',',CONCAT(sq3.item_id,':',sq3.u2i_score)) item_ids FROM ( SELECT sq2.user_id ,sq2.item_id ,ROUND(SUM(sq2.trigger_relation_score),4) u2i_score -- 为每个用户推荐的每个视频分配一个排名 ,ROW_NUMBER() OVER (PARTITION BY sq2.user_id ORDER BY SUM(sq2.trigger_relation_score) DESC ) rn FROM ( SELECT sq0.user_id ,sq1.item_id -- 用户可能对相关视频感兴趣的程度 = 用户对特定视频的兴趣得分(U2I得分)* 该视频与另一个视频的相关度得分(I2I得分) -- 例如:如果用户对某个视频表现出高兴趣(U2I得分高),且该视频与另一个视频非常相关(I2I得分高),那么用户也很可能对这个相关的视频感兴趣。 ,sq0.trigger_score * sq1.item_score trigger_relation_score FROM ( -- 获取最新的用户对视频的兴趣得分数据 SELECT * FROM rec_test_etrec_u2i_trigger_score_v1 WHERE ds = '20230216' ) sq0 JOIN ( -- 获取最新的视频相关性得分数据 SELECT * FROM rec_test_etrec_i2i_item_score_v1 WHERE ds = '20230216' ) sq1 ON sq0.item_id = sq1.trigger_id ) sq2 GROUP BY sq2.user_id ,sq2.item_id ) sq3 -- 控制最终的推荐列表中只包含了综合得分最高的前100个视频。 WHERE sq3.rn <= 100 GROUP BY sq3.user_id ;
任务运行:业务流程
所有SQL任务全部编辑成功后,您可通过如下方式运行整个业务流程:
-
在数据开发(DataStudio)页面,双击打开业务流程。
-
在工具栏单击
 图标,在单击运行业务流程对话框中确认按钮,运行整个业务流程。
图标,在单击运行业务流程对话框中确认按钮,运行整个业务流程。运行结束后,即可在页面下方查看运行日志和结果。
结果查询
创建查询节点
-
本阶段需要创建一个ODPS SQL节点:
视频个性化推荐结果查询,该节点依赖上述所有任务: -
工作流DAG中,顶部虚拟节点视频个性化推荐案例连接至数据准备组(含rec_sln_demo_behav和rec_test_etrec_beh两个SQL节点),数据准备组分别连接至I2I相似视频挖掘组(含三个rec_test_etrec_i2i节点纵向串联)和U2I用户兴趣点发现组(含rec_test_etrec_u2i节点),两组汇合连接至U2I2I猜你喜欢组(含rec_test_etrec_u2i节点),最后需手动将该节点与底部视频个性化推荐结果节点进行连线。
-
表定义:通过上述步骤已经实现了视频个性化推荐,创建查询节点,编写SQL查询语句,查看推荐结果。
-
在
视频个性化推荐结果查询节点编辑页面,输入如下示例代码:--@exclude_input=rec_test_etrec_u2i2i_score_v1 --@exclude_input=rec_test_etrec_u2i_trigger_score_v1 --@exclude_input=rec_test_etrec_i2i_item_score_v1 --@exclude_input=rec_test_etrec_i2i_output_20230216_v1 --@exclude_input=rec_test_etrec_i2i_input_v1 --@exclude_input=rec_test_etrec_behavior_weight_v1 --@exclude_input=rec_sln_demo_behavior_table_v1 --odps sql --********************************************************************-- --author:dataworks_demo2 --create time:2024-01-04 18:16:50 --********************************************************************-- -- 查询用户与视频的交互日志数据 select * from rec_sln_demo_behavior_table_v1 where ds='20230216' limit 10; -- 查询行为权重定义表 select * from rec_test_etrec_behavior_weight_v1 limit 10; -- 查询带有行为权重的用户与视频交互日志数据 select * from rec_test_etrec_i2i_input_v1 where ds='20230216' limit 10; -- 查询视频间相关度得分临时表 select * from rec_test_etrec_i2i_output_20230216_v1 limit 10; -- 查询视频间相关度得分数据 select * from rec_test_etrec_i2i_item_score_v1 where ds='20230216' limit 10; -- 查询用户对视频的兴趣得分数据 select * from rec_test_etrec_u2i_trigger_score_v1 where ds='20230216' limit 10; -- 查询用户个性化视频推荐列表 select * from rec_test_etrec_u2i2i_score_v1 where ds='20230216' limit 10; SELECT '====================================可进入当前节点再次运行查看结构化结果集====================================';
运行查询节点
运行整个业务流程之后,单独运行视频个性化推荐结果查询节点查看推荐结果,具体操作如下所示:
-
双击打开
视频个性化推荐结果查询节点编辑页面。 -
在工具栏单击
 图标,单独运行该节点,查看运行结果。
图标,单独运行该节点,查看运行结果。运行结果在结果[7]标签页中展示,包含
user_id(用户ID)、item_ids(推荐视频ID及对应分数,如248507619:0.1859)、ds(日期分区)三列,呈现每个用户的个性化视频推荐列表。
附录:使用ETL工作流模板
DataWorks ETL工作流模板已内置该案例,您直接导入本案例相关代码,具体操作如下:
-
登录DataWorks控制台,点击左侧导航栏的,进入ETL工作流模板页面。
-
在ETL工作流模板页面选择视频个性化推荐(协同过滤)业务流程,单击查看详情进入模板页面,点击载入模板。
-
在载入模板对话框中,选择对应的工作空间,并在MaxCompute配置中,选择在数据源名称下拉列表选择数据源,点击确认载入模板。
资源释放
若您在案例测试完成之后,想要清理与释放当前案例生成的资源,您可参考以下文档处理:
-
删除表:批量删除MaxCompute表。
-
下线任务:下线任务。
后续步骤
为便于理解,本案例选择使用固定分区(20230216)进行演示,您可基于此案例制作符合您业务场景的详情页相关内容推荐,并结合调度参数支持的格式,将任务发布到生产周期调度中,实现数据的自动更新。详情请参见:发布任务、管理周期任务。
相关文档
-
了解虚拟节点相关操作,详情请参见:虚拟节点。
-
了解MaxCompute节点的ODPS SQL节点,详情请参见:创建并管理MaxCompute节点。
-
了解更多开发ODPS SQL任务,详情请参见:开发ODPS SQL任务。
-
了解更多运维中心的周期任务调度,详情请参见:周期任务基本运维操作。