
在Kubernetes集群中使用ECI来运行Spark作业具有弹性伸缩、自动化部署、高可用性等优势,可以提高Spark作业的运行效率和稳定性。本文介绍如何在ACK Serverless集群中安装Spark Operator,使用ECI来运行Spark作业。
背景信息
Apache Spark是一个在数据分析领域广泛使用的开源项目,它常被应用于众所周知的大数据和机器学习工作负载中。从Apache Spark 2.3.0版本开始,您可以在Kubernetes上运行和管理Spark资源。
Spark Operator是专门针对Spark on Kubernetes设计的Operator,开发者可以通过使用CRD的方式,提交Spark任务到Kubernetes集群中。使用Spark Operator有以下优势:
能够弥补原生Spark对Kubernetes支持不足的部分。
能够快速和Kubernetes生态中的存储、监控、日志等组件对接。
支持故障恢复、弹性伸缩、调度优化等高阶Kubernetes特性。
准备工作
创建ACK Serverless集群。
在容器服务管理控制台上创建ACK Serverless集群。具体操作,请参见创建ACK Serverless集群。
如果您需要通过公网拉取镜像,或者训练任务需要访问公网,请配置公网NAT网关。
您可以通过kubectl管理和访问ACK Serverless集群,相关操作如下:
如果您需要通过本地计算机管理集群,请安装并配置kubectl客户端。具体操作,请参见通过kubectl连接Kubernetes集群。
您也可以在CloudShell上通过kubect管理集群。具体操作,请参见在CloudShell上通过kubectl管理Kubernetes集群。
创建OSS存储空间。
您需要创建一个OSS存储空间(Bucket)用来存放测试数据、测试结果和测试过程中的日志等。关于如何创建OSS Bucket,请参见创建存储空间。
安装Spark Operator
安装Spark Operator。
在容器服务管理控制台的左侧导航栏,选择市场>应用市场。
在应用目录页签,找到并单击ack-spark-operator。
单击右上角的一键部署。
在弹出面板中选择目标集群,按照页面提示完成配置。
创建ServiceAccount、Role和Rolebinding。
Spark作业需要一个ServiceAccount来获取创建Pod的权限,因此需要创建ServiceAccount、Role和Rolebinding。YAML示例如下,请根据需要修改三者的Namespace。
apiVersion: v1 kind: ServiceAccount metadata: name: spark namespace: default --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: namespace: default name: spark-role rules: - apiGroups: [""] resources: ["pods"] verbs: ["*"] - apiGroups: [""] resources: ["services"] verbs: ["*"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: spark-role-binding namespace: default subjects: - kind: ServiceAccount name: spark namespace: default roleRef: kind: Role name: spark-role apiGroup: rbac.authorization.k8s.io
构建Spark作业镜像
您需要编译Spark作业的JAR包,使用Dockerfile打包镜像。
以阿里云容器服务的Spark基础镜像为例,设置Dockerfile内容如下:
FROM registry.aliyuncs.com/acs/spark:ack-2.4.5-latest
RUN mkdir -p /opt/spark/jars
# 如果需要使用OSS(读取OSS数据或者离线Event到OSS),可以添加以下JAR包到镜像中
ADD https://repo1.maven.org/maven2/com/aliyun/odps/hadoop-fs-oss/3.3.8-public/hadoop-fs-oss-3.3.8-public.jar $SPARK_HOME/jars
ADD https://repo1.maven.org/maven2/com/aliyun/oss/aliyun-sdk-oss/3.8.1/aliyun-sdk-oss-3.8.1.jar $SPARK_HOME/jars
ADD https://repo1.maven.org/maven2/org/aspectj/aspectjweaver/1.9.5/aspectjweaver-1.9.5.jar $SPARK_HOME/jars
ADD https://repo1.maven.org/maven2/org/jdom/jdom/1.1.3/jdom-1.1.3.jar $SPARK_HOME/jars
COPY SparkExampleScala-assembly-0.1.jar /opt/spark/jarsSpark镜像如果较大,则拉取需要较长时间,您可以通过ImageCache加速镜像拉取。更多信息,请参见管理ImageCache和使用ImageCache加速创建Pod。
您也使用阿里云Spark基础镜像。阿里云提供了Spark2.4.5的基础镜像,针对Kubernetes场景(调度、弹性)进行了优化,能够极大提升调度速度和启动速度。您可以通过设置Helm Chart的变量enableAlibabaCloudFeatureGates: true的方式开启,如果想要达到更快的启动速度,可以设置enableWebhook: false。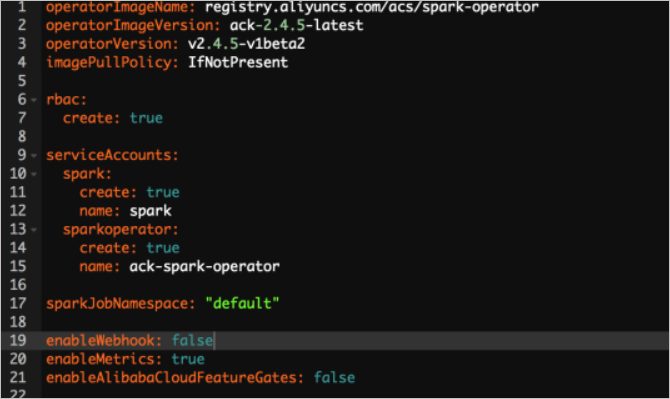
编写作业模板并提交作业
创建一个Spark作业的YMAL配置文件,并进行部署。
创建spark-pi.yaml文件。
一个典型的作业模板示例如下。更多信息,请参见spark-on-k8s-operator。
apiVersion: "sparkoperator.k8s.io/v1beta2" kind: SparkApplication metadata: name: spark-pi namespace: default spec: type: Scala mode: cluster image: "registry.aliyuncs.com/acs/spark:ack-2.4.5-latest" imagePullPolicy: Always mainClass: org.apache.spark.examples.SparkPi mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.5.jar" sparkVersion: "2.4.5" restartPolicy: type: Never driver: cores: 2 coreLimit: "2" memory: "3g" memoryOverhead: "1g" labels: version: 2.4.5 serviceAccount: spark annotations: k8s.aliyun.com/eci-kube-proxy-enabled: 'true' k8s.aliyun.com/eci-auto-imc: "true" tolerations: - key: "virtual-kubelet.io/provider" operator: "Exists" executor: cores: 2 instances: 1 memory: "3g" memoryOverhead: "1g" labels: version: 2.4.5 annotations: k8s.aliyun.com/eci-kube-proxy-enabled: 'true' k8s.aliyun.com/eci-auto-imc: "true" tolerations: - key: "virtual-kubelet.io/provider" operator: "Exists"部署一个Spark计算任务。
kubectl apply -f spark-pi.yaml
配置日志采集
以采集Spark的标准输出日志为例,您可以在Spark driver和Spark executor的envVars字段中注入环境变量,实现日志的自动采集。更多信息,请参见自定义配置ECI日志采集。
envVars:
aliyun_logs_test-stdout_project: test-k8s-spark
aliyun_logs_test-stdout_machinegroup: k8s-group-app-spark
aliyun_logs_test-stdout: stdout提交作业时,您可以按上述方式设置driver和executor的环境变量,即可实现日志的自动采集。
配置历史服务器
历史服务器用于审计Spark作业,您可以通过在Spark Applicaiton的CRD中增加SparkConf字段的方式,将event写入到OSS,再通过历史服务器读取OSS的方式进行展现。配置示例如下:
sparkConf:
"spark.eventLog.enabled": "true"
"spark.eventLog.dir": "oss://bigdatastore/spark-events"
"spark.hadoop.fs.oss.impl": "org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem"
# oss bucket endpoint such as oss-cn-beijing.aliyuncs.com
"spark.hadoop.fs.oss.endpoint": "oss-cn-beijing.aliyuncs.com"
"spark.hadoop.fs.oss.accessKeySecret": ""
"spark.hadoop.fs.oss.accessKeyId": ""
阿里云也提供了spark-history-server的Chart,您可以在容器服务管理控制台的市场>应用市场页面,搜索ack-spark-history-server进行安装。安装时需在参数中配置OSS的相关信息,示例如下:
oss:
enableOSS: true
# Please input your accessKeyId
alibabaCloudAccessKeyId: ""
# Please input your accessKeySecret
alibabaCloudAccessKeySecret: ""
# oss bucket endpoint such as oss-cn-beijing.aliyuncs.com
alibabaCloudOSSEndpoint: "oss-cn-beijing.aliyuncs.com"
# oss file path such as oss://bucket-name/path
eventsDir: "oss://bigdatastore/spark-events"安装完成后,您可以在集群详情页面的服务中看到ack-spark-history-server的对外地址,访问对外地址即可查看历史任务归档。
查看作业结果
查看Pod的执行情况。
kubectl get pods预期返回结果:
NAME READY STATUS RESTARTS AGE spark-pi-1547981232122-driver 1/1 Running 0 12s spark-pi-1547981232122-exec-1 1/1 Running 0 3s查看实时Spark UI。
kubectl port-forward spark-pi-1547981232122-driver 4040:4040查看Spark Applicaiton的状态。
kubectl describe sparkapplication spark-pi预期返回结果:
Name: spark-pi Namespace: default Labels: <none> Annotations: kubectl.kubernetes.io/last-applied-configuration: {"apiVersion":"sparkoperator.k8s.io/v1alpha1","kind":"SparkApplication","metadata":{"annotations":{},"name":"spark-pi","namespace":"default"...} API Version: sparkoperator.k8s.io/v1alpha1 Kind: SparkApplication Metadata: Creation Timestamp: 2019-01-20T10:47:08Z Generation: 1 Resource Version: 4923532 Self Link: /apis/sparkoperator.k8s.io/v1alpha1/namespaces/default/sparkapplications/spark-pi UID: bbe7445c-1ca0-11e9-9ad4-062fd7c19a7b Spec: Deps: Driver: Core Limit: 200m Cores: 0.1 Labels: Version: 2.4.0 Memory: 512m Service Account: spark Volume Mounts: Mount Path: /tmp Name: test-volume Executor: Cores: 1 Instances: 1 Labels: Version: 2.4.0 Memory: 512m Volume Mounts: Mount Path: /tmp Name: test-volume Image: gcr.io/spark-operator/spark:v2.4.0 Image Pull Policy: Always Main Application File: local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar Main Class: org.apache.spark.examples.SparkPi Mode: cluster Restart Policy: Type: Never Type: Scala Volumes: Host Path: Path: /tmp Type: Directory Name: test-volume Status: Application State: Error Message: State: COMPLETED Driver Info: Pod Name: spark-pi-driver Web UI Port: 31182 Web UI Service Name: spark-pi-ui-svc Execution Attempts: 1 Executor State: Spark - Pi - 1547981232122 - Exec - 1: COMPLETED Last Submission Attempt Time: 2019-01-20T10:47:14Z Spark Application Id: spark-application-1547981285779 Submission Attempts: 1 Termination Time: 2019-01-20T10:48:56Z Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SparkApplicationAdded 55m spark-operator SparkApplication spark-pi was added, Enqueuing it for submission Normal SparkApplicationSubmitted 55m spark-operator SparkApplication spark-pi was submitted successfully Normal SparkDriverPending 55m (x2 over 55m) spark-operator Driver spark-pi-driver is pending Normal SparkExecutorPending 54m (x3 over 54m) spark-operator Executor spark-pi-1547981232122-exec-1 is pending Normal SparkExecutorRunning 53m (x4 over 54m) spark-operator Executor spark-pi-1547981232122-exec-1 is running Normal SparkDriverRunning 53m (x12 over 55m) spark-operator Driver spark-pi-driver is running Normal SparkExecutorCompleted 53m (x2 over 53m) spark-operator Executor spark-pi-1547981232122-exec-1 completed查看日志获取结果。
NAME READY STATUS RESTARTS AGE spark-pi-1547981232122-driver 0/1 Completed 0 1m当Spark Applicaiton的状态为Succeed或者Spark driver对应的Pod状态为Completed时,可以查看日志获取结果。
kubectl logs spark-pi-1547981232122-driver Pi is roughly 3.152155760778804
- 本页导读 (1)
- 背景信息
- 准备工作
- 安装Spark Operator
- 构建Spark作业镜像
- 编写作业模板并提交作业
- 配置日志采集
- 配置历史服务器
- 查看作业结果