
本文为您介绍阿里云实时计算Blink独享或共享集群(Blink计算引擎和Bayes开发平台)的业务迁移至实时计算Flink版时的迁移限制、迁移方案和常见问题。
迁移限制
由于Blink作业的State和Flink的State无法兼容复用,因此所有的迁移工作均采用冷迁移方式,即Blink作业需停止后再切换成Flink作业后启动,迁移过程中会存在业务中断的情况。
Bayes开发平台权限体系无法对应实时计算Flink版平台,需要您重新进行授权。
仅支持线上作业迁移,不支持开发态(多版本)作业迁移。
Blink和Flink支持的Connector类型不完全一致,迁移前需评估Blink中使用的Connector是否在目标Flink版本上支持。如果不支持,则暂无法进行迁移,但您可以通过自定义Connector的方式进行。
注意事项
如果Blink作业Java代码中设置了stateBackend,在迁移到实时计算Flink版时,需要去掉相关的设置语句。例如,假如Blink Java代码中有如下设置。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new NiagaraStateBackend(checkpointPath, true, niagaraConfig));需要删除env.setStateBackend(new NiagaraStateBackend(checkpointPath, true, niagaraConfig))语句,同时POM文件中可以删除Blink stateBackend的相关依赖,因为VVR引擎默认使用GeminiStateBackend,无需额外配置。
迁移方案
阿里云实时计算Blink独享或共享集群(Blink计算引擎和Bayes开发平台)的业务迁移至实时计算Flink版的流程图,如下所示。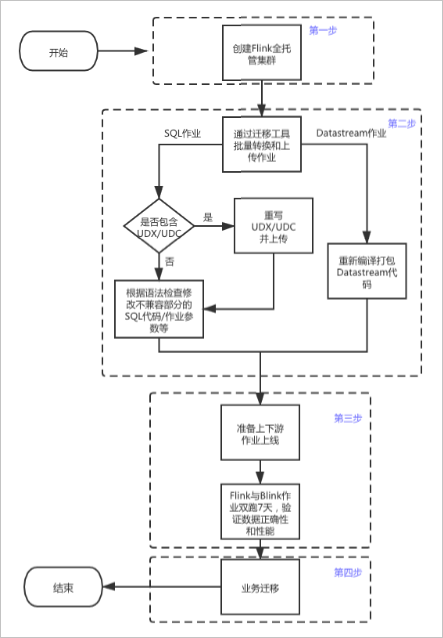
主要包括以下几个环节:
使用和Blink独享或共享集群相同的阿里云账号创建实时计算Flink版工作空间,以便将Bayes作业迁移过来。
为了保证上下游迁移后的网络连通性,创建实时计算Flink版工作空间时,请选择和Blink独享或共享集群相同的Region和VPC。创建实时计算Flink版的步骤详情,请参见开通实时计算Flink版。
使用迁移工具迁移作业,并完成作业转化。
利用实时计算Flink产品提供的迁移工具进行作业迁移。
为了提高迁移效率,实时计算Flink产品提供了Bayes迁移VVP的迁移工具。该工具可以将Bayes平台上的作业转换为实时计算开发控制台的作业,针对SQL作业,迁移工具会自动完成Blink和Flink SQL语法的转换。迁移操作详情请参见迁移工具。
进一步确认与处理,完成作业转化。
通过新任务和原有任务并行双跑的方式,验证迁移后数据正确性、业务性能和业务稳定性。
在目标Flink集群上线并运行迁移后的Flink作业,建议您将相同逻辑的Flink作业和Blink的作业一起跑一段时间(建议至少7天)来比对验证数据的正确性、业务性能和稳定性。双跑验证时,建议将上下游存储进行相应的替换。通常可以读同一个上游,结果写入到不同的下游系统或同一个下游系统的不同表,进行对比数据验证。双跑验证需要关注的详情如下:
数据正确性验证
数据质量是实时计算数据产出对业务的重要保障,和实时计算任务日常变更一样,迁移工作也需要对新任务产出的数据质量进行验证。通常,建议您采用迁移新任务和原有任务并行双跑的方式,在新运行一段时间,满足数据对比条件后,验证新任务和原有任务的数据产出是否一致,达到预期的数据质量。理想情况下,迁移的新任务数据产出和原任务完全一致,就无需进行额外的差异分析。
实时任务7x24小时持续在运行,但在大部分情况下产出的数据还是具备时间周期特性的,这就给数据对比提供了可行性。例如,聚合任务按小时或天维度计算聚合值,清洗任务加工任务按天分区表等。在数据对比时就可以根据对应的时间周期来进行对比。例如小时周期的任务实际已完整处理数据多个小时后,就可以对比处理过的小时数据,而天维度的聚合值,通常就需要等待新任务处理完完整的一天数据后才能对比。
根据任务产出的生成周期特性和数据规模,您可以结合业务的实际情况,使用恰当的对比方法。对比方法详情如下表所示。
数据规模
对比
中小数据规模
建议进行全量数据对比。
较大数据规模
如果全量对比的代价高、可行性低,则可以考虑采用抽样的方式进行,但需注意抽样方式的合理性, 避免单一性产生对比漏洞从而误判数据质量。
业务性能验证
主要对比作业的吞吐和延时情况来判断新作业性能是否符合需求。如果业务延时性能不满足业务需求,则需进行调优,您可以开启Autopilot自动调优功能。详情请参见配置自动调优。
业务稳定性验证
业务稳定性和数据质量同样重要,任务的稳定性通常要求实现较长时间的平稳运行(建议至少7天)。进入稳定性观察期后,建议开启和原任务相同级别的监控、报警设置,期间主要观察任务运行时的处理延迟、有无异常Failover以及Checkpoint情况是否健康等。如果达到了和原有任务同等或更高的稳定性,那稳定性验证就完成了。
替换结果表,迁移后的作业正式上线运行。
第三步中的数据正确性、业务性能和稳定性确认后,即可开展业务迁移工作,即将Flink作业中使用的备用结果表替换原有任务的结果表,提供给业务方使用,并将原有生产链路停止下线,整个迁移工作就圆满结束了。
常见问题
Q:如果测试数据不一致,应该从哪些方面进行排查与修改?
A:
双方的测试数据是否一致。
启动位点是否一致。
UDX是否写的没有问题。
SQL的内置函数是否用的一致。
修改后重新上线再对比数据。