
实时UV计算主要依赖Hologres与Flink结合完成,本文将为您介绍Hologres如何进行实时UV精确去重。
前提条件
开通Hologres并连接开发工具,示例使用HoloWeb,详情请参见连接HoloWeb并执行查询。
准备并搭建好Flink集群环境,您可以使用阿里云Flink全托管或者开源Flink。
背景信息
Hologres与Flink有着强大的融合优化,支持Flink数据高通量实时写入,写入即可见,支持Flink SQL维表关联,以及作为CDC Source事件驱动开发。因此实时UV去重主要通过Flink和Hologres来实现,场景架构图如下所示。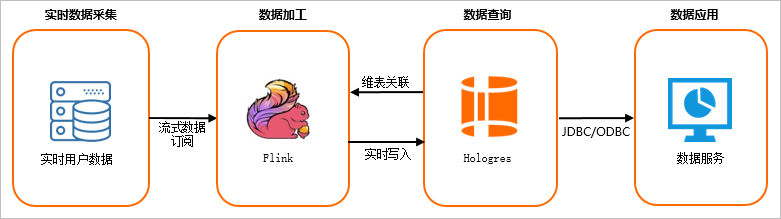
Flink实时订阅实时采集的数据,数据源可以来源于日志数据,如Kafka等。
Flink对数据做进一步加工处理,将流式数据转化为表与Hologres维表进行JOIN操作,实时写入Hologres。
Hologres对Flink实时写入的数据实时处理。
最终查询的数据对接上层数据应用,如数据服务、Quick BI等。
实时UV计算方案流程
Flink与Hologres有着非常强的融合性,再结合Hologres天然支持的RoaringBitmap,完成实时UV计算,实时对用户标签去重,详细方案流程如下图所示。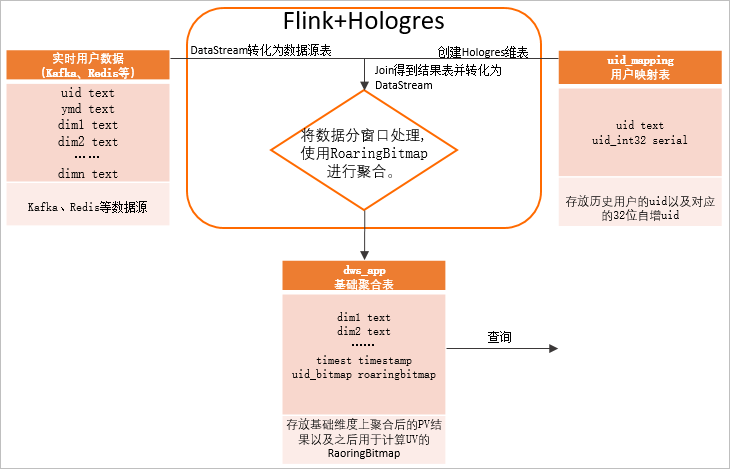
Flink实时订阅用户数据,这些数据可以来源于Kafka、Redis等,并通过DataStream转化为数据源表。
在Hologres中创建用户映射表,存放历史用户的uid以及对应的32位自增uid。
说明常见的业务系统或者埋点中的用户ID很多是字符串类型或Long类型,因此需要使用uid_mapping类型构建一张映射表。RoaringBitmap类型要求用户ID必须是32位int类型且越稠密越好(即用户ID最好连续)。映射表利用Hologres的SERIAL类型(自增的32位int)来实现用户映射的自动管理和稳定映射。
在Flink中,将Hologres中的用户映射表作为Flink维表,利用Hologres维表的insertIfNotExists特性结合自增字段实现高效的uid映射。维表与数据源表进行Join关联,并将Join得到的结果转化为流式数据DataStream。
Hologres中创建聚合结果表,Flink把维表关联的结果数据按照时间窗口进行处理,根据查询维度使用RoaringBitmap函数。
查询时,与离线方式相似,直接按照查询条件查询聚合结果表,并对其中关键的RoaringBitmap字段做
or运算后并统计基数,即可得出对应用户数。
这样的方式,可以较细粒度的实时得到用户UV、PV数据,同时便于根据需求调整最小统计窗口(如最近5分钟的UV),实现类似实时监控的效果,更好的在大屏等BI展示。相较于以天、周、月等为单位的去重,更适合在活动日期进行更细粒度的统计,并且通过简单的聚合,也可以得到较大时间单位的统计结果。如果加工聚合的粒度较细,但查询时缺少相应的过滤条件或聚合维度,则也会在查询时引起较多的二次聚合操作,对性能有不利影响。
该方案数据链路简单,可以任意维度灵活计算,只需要一份Bitmap存储,也没有存储爆炸问题,还能保证实时更新,从而实现更实时、开发更灵活、功能更完善的多维分析数仓。
操作步骤
在Hologres中创建相关基础表
创建用户映射表
在Hologres创建表uid_mapping为用户映射表,命令语句如下所示。用于映射uid到32位int类型。如果原始uid已经是int32类型,此步骤可忽略。
常见的业务系统或者埋点中的用户ID很多是字符串类型或Long类型,因此需要使用uid_mapping类型构建一张映射表。RoaringBitmap类型要求用户ID必须是32位int类型且越稠密越好(即用户ID最好连续)。映射表利用Hologres的SERIAL类型(自增的32位int)来实现用户映射的自动管理和稳定映射。
由于是实时数据,在Hologres中该表为行存表,以提高Flink维表实时JOIN的QPS。
需要开启相应GUC使用优化的执行引擎对包含serial字段的表进行写入,详情请参见Fixed Plan加速SQL执行。
--开启GUC,支持含有Serial类型列的Fixed Plan写入 alter database <dbname> set hg_experimental_enable_fixed_dispatcher_autofill_series=on; alter database <dbname> set hg_experimental_enable_fixed_dispatcher_for_multi_values=on; BEGIN; CREATE TABLE public.uid_mapping ( uid text NOT NULL, uid_int32 serial, PRIMARY KEY (uid) ); --将uid设为clustering_key和distribution_key便于快速查找其对应的int32值 CALL set_table_property('public.uid_mapping', 'clustering_key', 'uid'); CALL set_table_property('public.uid_mapping', 'distribution_key', 'uid'); CALL set_table_property('public.uid_mapping', 'orientation', 'row'); COMMIT;创建聚合结果表
创建表dws_app为聚合结果表,用于存放在基础维度上聚合后的结果。
使用RoaringBitmap函数前需要创建RoaringBitmap extension,同时也需要Hologres实例为 V0.10及以上版本。
CREATE EXTENSION IF NOT EXISTS roaringbitmap;相比离线结果表,此结果表增加了时间戳字段,用于实现以Flink窗口周期为单位的统计,结果表DDL如下。
BEGIN; CREATE TABLE dws_app( country text, prov text, city text, ymd text NOT NULL, --日期字段 timetz TIMESTAMPTZ, --统计时间戳,可以实现以Flink窗口周期为单位的统计 uid32_bitmap roaringbitmap, -- 使用roaringbitmap记录uv PRIMARY KEY (country, prov, city, ymd, timetz)--查询维度和时间作为主键,防止重复插入数据 ); CALL set_table_property('public.dws_app', 'orientation', 'column'); --日期字段设为clustering_key和event_time_column,便于过滤 CALL set_table_property('public.dws_app', 'clustering_key', 'ymd'); CALL set_table_property('public.dws_app', 'event_time_column', 'ymd'); --group by字段设为distribution_key CALL set_table_property('public.dws_app', 'distribution_key', 'country,prov,city'); COMMIT;
Flink实时读取数据并更新聚合结果表
在Flink中的完整示例源码请参见alibabacloud-hologres-connectors examples,下面是在Flink中的具体操作步骤。
Flink流式读取数据源(DataStream)并转化为源表(Table)
在Flink中使用流式读取数据源,数据源可以是CSV文件,也可以来源于Kafka、Redis等,可以根据业务场景准备。在Flink中转化为源表的代码示例如下。
// 此处使用csv文件作为数据源,也可以是kafka/redis等 DataStreamSource odsStream = env.createInput(csvInput, typeInfo); // 与维表join需要添加proctime字段 Table odsTable = tableEnv.fromDataStream( odsStream, $("uid"), $("country"), $("prov"), $("city"), $("ymd"), $("proctime").proctime()); // 注册到catalog环境 tableEnv.createTemporaryView("odsTable", odsTable);将源表与Hologres维表(uid_mapping)进行关联
在Flink中创建Hologres维表,需要使用
insertIfNotExists参数,即查询不到数据时自行插入,uid_int32字段便可以利用Hologres的Serial类型自增创建。将Flink源表与Hologres维表进行关联(JOIN),代码示例如下。-- 创建Hologres维表,其中insertIfNotExists表示查询不到则自行插入 String createUidMappingTable = String.format( "create table uid_mapping_dim(" + " uid string," + " uid_int32 INT" + ") with (" + " 'connector'='hologres'," + " 'dbname' = '%s'," //Hologres DB名 + " 'tablename' = '%s',"//Hologres 表名 + " 'username' = '%s'," //当前账号access id + " 'password' = '%s'," //当前账号access key + " 'endpoint' = '%s'," //Hologres endpoint + " 'insertifnotexists'='true'" + ")", database, dimTableName, username, password, endpoint); tableEnv.executeSql(createUidMappingTable); -- 源表与维表join String odsJoinDim = "SELECT ods.country, ods.prov, ods.city, ods.ymd, dim.uid_int32" + " FROM odsTable AS ods JOIN uid_mapping_dim FOR SYSTEM_TIME AS OF ods.proctime AS dim" + " ON ods.uid = dim.uid"; Table joinRes = tableEnv.sqlQuery(odsJoinDim);将关联结果转化为DataStream
通过Flink时间窗口处理,结合RoaringBitmap进行对指标进行去重处理,代码示例如下所示。
DataStream<Tuple6<String, String, String, String, Timestamp, byte[]>> processedSource = source -- 筛选需要统计的维度(country, prov, city, ymd) .keyBy(0, 1, 2, 3) -- 滚动时间窗口;此处由于使用读取csv模拟输入流,采用ProcessingTime,实际使用中可使用EventTime .window(TumblingProcessingTimeWindows.of(Time.minutes(5))) -- 触发器,可以在窗口未结束时获取聚合结果 .trigger(ContinuousProcessingTimeTrigger.of(Time.minutes(1))) .aggregate( -- 聚合函数,根据key By筛选的维度,进行聚合 new AggregateFunction< Tuple5<String, String, String, String, Integer>, RoaringBitmap, RoaringBitmap>() { @Override public RoaringBitmap createAccumulator() { return new RoaringBitmap(); } @Override public RoaringBitmap add( Tuple5<String, String, String, String, Integer> in, RoaringBitmap acc) { -- 将32位的uid添加到RoaringBitmap进行去重 acc.add(in.f4); return acc; } @Override public RoaringBitmap getResult(RoaringBitmap acc) { return acc; } @Override public RoaringBitmap merge( RoaringBitmap acc1, RoaringBitmap acc2) { return RoaringBitmap.or(acc1, acc2); } }, -- 窗口函数,输出聚合结果 new WindowFunction< RoaringBitmap, Tuple6<String, String, String, String, Timestamp, byte[]>, Tuple, TimeWindow>() { @Override public void apply( Tuple keys, TimeWindow timeWindow, Iterable<RoaringBitmap> iterable, Collector< Tuple6<String, String, String, String, Timestamp, byte[]>> out) throws Exception { RoaringBitmap result = iterable.iterator().next(); // 优化RoaringBitmap result.runOptimize(); // 将RoaringBitmap转化为字节数组以存入Holo中 byte[] byteArray = new byte[result.serializedSizeInBytes()]; result.serialize(ByteBuffer.wrap(byteArray)); // 其中 Tuple6.f4(Timestamp) 字段表示以窗口长度为周期进行统计,以秒为单位 out.collect( new Tuple6<>( keys.getField(0), keys.getField(1), keys.getField(2), keys.getField(3), new Timestamp( timeWindow.getEnd() / 1000 * 1000), byteArray)); } });写入Hologres聚合结果表
经过Flink去重处理的数据写入至Hologres结果表dws_app,但需要注意的是Hologres中RoaringBitmap类型在Flink中对应Byte数组类型,Flink中代码如下。
-- 计算结果转换为表 Table resTable = tableEnv.fromDataStream( processedSource, $("country"), $("prov"), $("city"), $("ymd"), $("timest"), $("uid32_bitmap")); -- 创建Hologres结果表, 其中Hologres的RoaringBitmap类型通过Byte数组存入 String createHologresTable = String.format( "create table sink(" + " country string," + " prov string," + " city string," + " ymd string," + " timetz timestamp," + " uid32_bitmap BYTES" + ") with (" + " 'connector'='hologres'," + " 'dbname' = '%s'," + " 'tablename' = '%s'," + " 'username' = '%s'," + " 'password' = '%s'," + " 'endpoint' = '%s'," + " 'connectionSize' = '%s'," + " 'mutatetype' = 'insertOrReplace'" + ")", database, dwsTableName, username, password, endpoint, connectionSize); tableEnv.executeSql(createHologresTable); -- 写入计算结果到dws_app表 tableEnv.executeSql("insert into sink select * from " + resTable);
数据查询
在Hologres中对聚合结果表(dws_app)进行UV计算。按照查询维度做聚合计算,查询Bitmap基数,得出Group By条件下的用户数。
示例一:查询某天内各个城市的uv
-- 运行下面RB_AGG运算查询,可执行参数先关闭三阶段聚合开关(默认关闭),性能更好,此步骤可选 set hg_experimental_enable_force_three_stage_agg=off; SELECT country ,prov ,city ,RB_CARDINALITY(RB_OR_AGG(uid32_bitmap)) AS uv FROM dws_app WHERE ymd = '20210329' GROUP BY country ,prov ,city ;示例二:查询某段时间内各个省份的UV、PV
-- 运行下面RB_AGG运算查询,可执行参数先关闭三阶段聚合开关(默认关闭),性能更好,此步骤可选 set hg_experimental_enable_force_three_stage_agg=off; SELECT country ,prov ,RB_CARDINALITY(RB_OR_AGG(uid32_bitmap)) AS uv ,SUM(pv) AS pv FROM dws_app WHERE time > '2021-04-19 18:00:00+08' and time < '2021-04-19 19:00:00+08' GROUP BY country ,prov ;
可视化展示
计算出UV、PV后,大多数情况需要使用BI工具以更直观的方式可视化展示,由于需要使用RB_CARDINALITY和RB_OR_AGG进行聚合计算,需要使用BI的自定义聚合函数的能力,常见的具备该能力的BI包括Apache Superset和Tableau。
Apache Superset
Apache Superset连接Hologres,详情请参见Apache Superset。
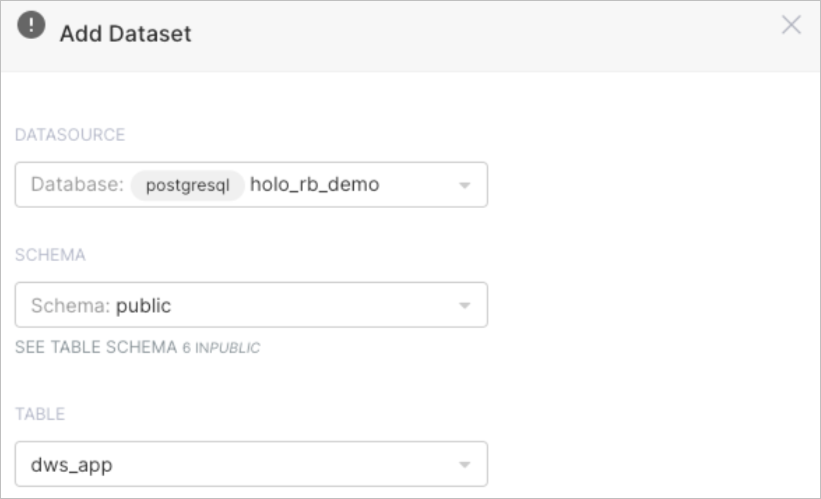
设置dws_app表作为数据集。
在数据集中创建一个名称为UV的单独Metrics,表达式如下。
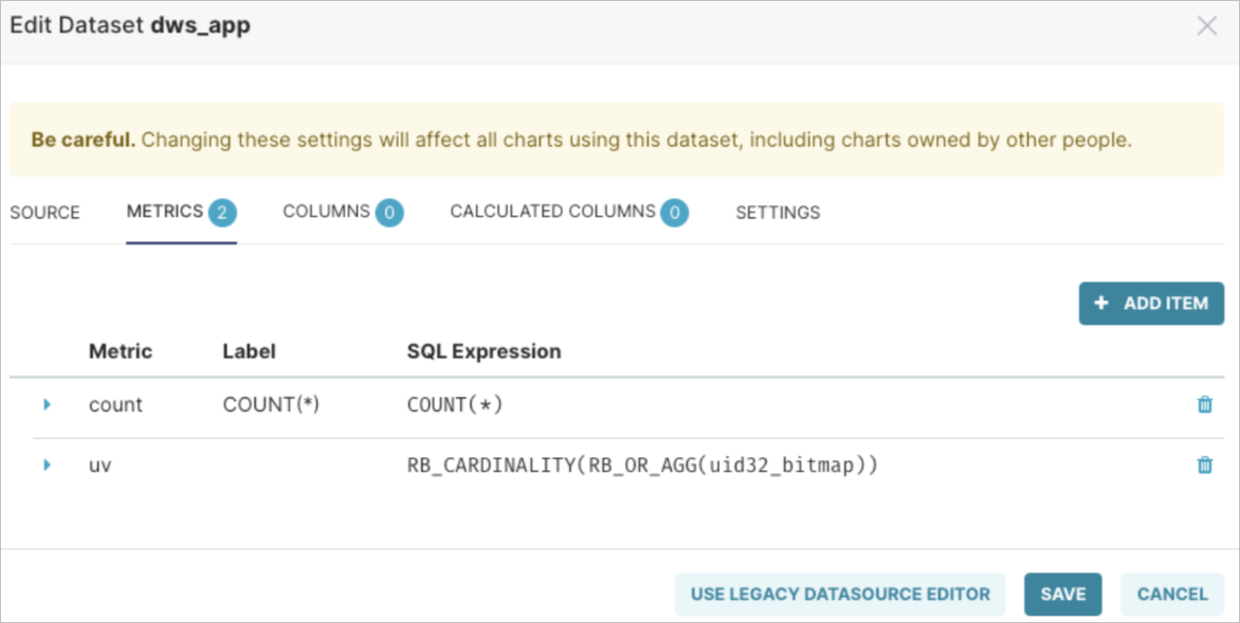
RB_CARDINALITY(RB_OR_AGG(uid32_bitmap))完成后您就可以开始探索数据了。
(可选)创建Dashboard。
创建仪表板请参见Create Dashboard。
Tableau
Tableau连接Hologres,详情请参见Tableau。
可以使用Tableau的直通函数直接实现自定义函数的能力,详细介绍请参见直通函数。
创建一个计算字段,表达式如下。
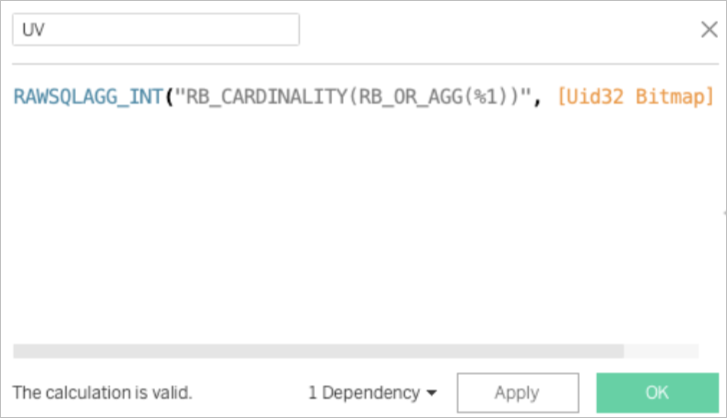
RAWSQLAGG_INT("RB_CARDINALITY(RB_OR_AGG(%1))", [Uid32 Bitmap])完成后您就可以开始探索数据了。
(可选)创建Dashboard。
创建仪表板请参见Create a Dashboard。