
大语言模型的训练和推理过程存在高能耗及长响应时间等问题,这些问题限制了其在资源有限场景中使用。为了解决这些问题,PAI提出了模型蒸馏功能。该功能支持将大模型知识迁移到较小模型,从而在保留大部分性能的同时,大幅降低模型的规模和对计算资源的需求,为更多的实际应用场景提供支持。本文将以通义千问2(Qwen2)大语言模型为基础,为您介绍大语言模型数据增强和蒸馏解决方案的完整开发流程。
使用流程
该解决方案的完整开发流程如下:
您可以参照数据格式要求和数据准备策略准备相应的训练数据集。
您可以在PAI-Model Gallery中使用预置的指令增广模型(Qwen2-1.5B-Instruct-Exp或Qwen2-7B-Instruct-Exp),根据已准备好的数据集中的指令语义信息,自动扩写更多相似的指令。指令增广有助于提升大语言模型的蒸馏训练的泛化性。
您可以在PAI-Model Gallery中使用预置的指令优化模型(Qwen2-1.5B-Instruct-Refine或Qwen2-7B-Instruct-Refine),将已准备好的数据集中的指令(以及增广的指令)进行优化精炼。指令优化有助于提升大语言模型的语言生成能力。下表对比展示了Qwen2-7B-Instruct模型在接收简略与详细指令输入时的输出情况,表明指令的优化对模型输出有显著的提升作用。
指令
回复
优化后的指令
优化后的回复
请解释一下“重力”是什么。
请详细解释“重力”是什么,包括它的定义、产生的原因以及在自然界中的作用。
写一首关于春天的诗。
创作一首表达春天美景与生机的诗歌。
注意事项:
1. 请在诗中描绘春天的自然景象,如花朵、树木、小溪等。
2. 表达春天带来的希望和活力。
3. 保持诗歌的节奏和韵律。
4. 诗歌长度在20至30行之间。
您可以在PAI-Model Gallery中使用预置的教师大语言模型(通义千问2-72B-Instruct)对训练数据集中的指令生成回复,从而将对应教师大模型的知识进行蒸馏。
您可以在PAI-Model Gallery中使用生成完成的指令-回复数据集,蒸馏训练对应较小的学生模型,用于实际的应用场景。
前提条件
在开始执行操作前,请确认您已完成以下准备工作:
已开通PAI(DLC、EAS)后付费,并创建默认工作空间,详情请参见开通PAI并创建默认工作空间。
已创建OSS存储空间(Bucket),用于存储训练数据和训练获得的模型文件。关于如何创建存储空间,详情请参见控制台快速入门。
准备指令数据
数据准备策略
为了提升模型蒸馏的有效性和稳定性,您可以参考以下策略准备数据:
您需要准备至少数百条数据,准备的数据多有助于提升模型的效果。
准备的种子数据集的分布应该尽可能广泛且均衡。例如:任务场景分布广泛;数据输入输出长度应该包含较短和较长场景;如果数据不止一种语言,例如有中文和英文,应当确保语言分布较为均衡。
处理异常数据。即使是少量的异常数据也会对微调效果造成很大的影响。您应当先使用基于规则的方式清洗数据,过滤掉数据集中的异常数据。
数据格式要求
训练数据集格式要求为:JSON格式的文件,包含instruction一个字段,为输入的指令。相应的指令数据示例如下:
[
{
"instruction": "在2008年金融危机期间,各国政府采取了哪些主要措施来稳定金融市场?"
},
{
"instruction": "在气候变化加剧的背景下,各国政府采取了哪些重要行动来推动可持续发展?"
},
{
"instruction": "在2001年科技泡沫破裂期间,各国政府采取了哪些主要措施来支持经济复苏?"
}
](可选)使用指令增广模型进行指令增广
指令增广是大语言模型提示工程(Prompt Engineering)的一种常见应用,用于自动增广用户提供的指令数据集,以实现数据增强的作用。
例如给定如下输入:
如何做鱼香肉丝? 如何准备GRE考试? 如果被朋友误会了怎么办?模型输出类似如下结果:
教我如何做麻婆豆腐? 提供一个关于如何准备托福考试的详细指南? 如果你在工作中遇到了挫折,你会如何调整心态?
由于指令的多样性直接影响了大语言模型的学习泛化性,进行指令增广能有效提升最终产生的学生模型的效果。基于Qwen2基座模型,PAI提供了两款自主研发的指令增广模型,分别为Qwen2-1.5B-Instruct-Exp和Qwen2-7B-Instruct-Exp。您可以在PAI-Model Gallery中一键部署模型服务,具体操作步骤如下:
部署模型服务
您可以按照以下操作步骤,将指令增广模型部署为EAS在线服务:
进入Model Gallery页面。
登录PAI控制台。
在顶部左上角根据实际情况选择地域。
在左侧导航栏选择工作空间列表,单击指定工作空间名称,进入对应工作空间内。
在左侧导航栏选择。
在Model Gallery页面右侧的模型列表中,搜索Qwen2-1.5B-Instruct-Exp或Qwen2-7B-Instruct-Exp,并在相应卡片中单击部署。
在部署配置面板中,系统已默认配置了模型服务信息和资源部署信息,您也可以根据需要进行修改。参数配置完成后单击部署按钮。
在计费提醒对话框中,单击确定。
系统自动跳转到部署任务页面,当状态为运行中时,表示服务部署成功。
调用模型服务
服务部署成功后,您可以使用API进行模型推理。具体使用方法参考LLM大语言模型部署。以下提供一个示例,展示如何通过客户端发起Request调用:
获取服务访问地址和Token。
在服务详情页面,单击基本信息区域的查看调用信息。
在调用信息对话框中,查询服务访问地址和Token,并保存到本地。
在终端中,创建并执行如下Python代码文件来调用服务。
import argparse import json import requests from typing import List def post_http_request(prompt: str, system_prompt: str, host: str, authorization: str, max_new_tokens: int, temperature: float, top_k: int, top_p: float) -> requests.Response: headers = { "User-Agent": "Test Client", "Authorization": f"{authorization}" } pload = { "prompt": prompt, "system_prompt": system_prompt, "top_k": top_k, "top_p": top_p, "temperature": temperature, "max_new_tokens": max_new_tokens, "do_sample": True, "eos_token_id": 151645 } response = requests.post(host, headers=headers, json=pload) return response def get_response(response: requests.Response) -> List[str]: data = json.loads(response.content) output = data["response"] return output if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("--top-k", type=int, default=50) parser.add_argument("--top-p", type=float, default=0.95) parser.add_argument("--max-new-tokens", type=int, default=2048) parser.add_argument("--temperature", type=float, default=1) parser.add_argument("--prompt", type=str, default="给我唱首歌。") args = parser.parse_args() prompt = args.prompt top_k = args.top_k top_p = args.top_p temperature = args.temperature max_new_tokens = args.max_new_tokens host = "EAS HOST" authorization = "EAS TOKEN" print(f" --- input: {prompt}\n", flush=True) system_prompt = "我希望你扮演一个指令创建者的角色。 你的目标是从【给定指令】中获取灵感,创建一个全新的指令。" response = post_http_request( prompt, system_prompt, host, authorization, max_new_tokens, temperature, top_k, top_p) output = get_response(response) print(f" --- output: {output}\n", flush=True)其中:
host:配置为已获取的服务访问地址。
authorization:配置为已获取的服务Token。
批量实现指令增广
您可以使用上述EAS在线服务进行批量调用,实现批量指令增广。以下代码示例展示了如何读取自定义的JSON格式数据集,批量调用上面的模型接口进行指令增广。您需要在终端中,创建并执行如下Python代码文件来批量调用模型服务。
import requests
import json
import random
from tqdm import tqdm
from typing import List
input_file_path = "input.json" # 输入文件名
with open(input_file_path) as fp:
data = json.load(fp)
total_size = 10 # 期望的扩展后的总数据量
pbar = tqdm(total=total_size)
while len(data) < total_size:
prompt = random.sample(data, 1)[0]["instruction"]
system_prompt = "我希望你扮演一个指令创建者的角色。 你的目标是从【给定指令】中获取灵感,创建一个全新的指令。"
top_k = 50
top_p = 0.95
temperature = 1
max_new_tokens = 2048
host = "EAS HOST"
authorization = "EAS TOKEN"
response = post_http_request(
prompt, system_prompt,
host, authorization,
max_new_tokens, temperature, top_k, top_p)
output = get_response(response)
temp = {
"instruction": output
}
data.append(temp)
pbar.update(1)
pbar.close()
output_file_path = "output.json" # 输出文件名
with open(output_file_path, 'w') as f:
json.dump(data, f, ensure_ascii=False)其中:
host:配置为已获取的服务访问地址。
authorization:配置为已获取的服务Token。
file_path:请替换为数据集文件所在的本地路径。
post_http_request和get_response函数的定义与其在调用模型服务的Python脚本中对应的函数定义保持一致。
您也可以使用PAI-Designer的LLM-指令扩充(DLC)组件零代码实现上述功能。具体操作方法,请参考自定义工作流。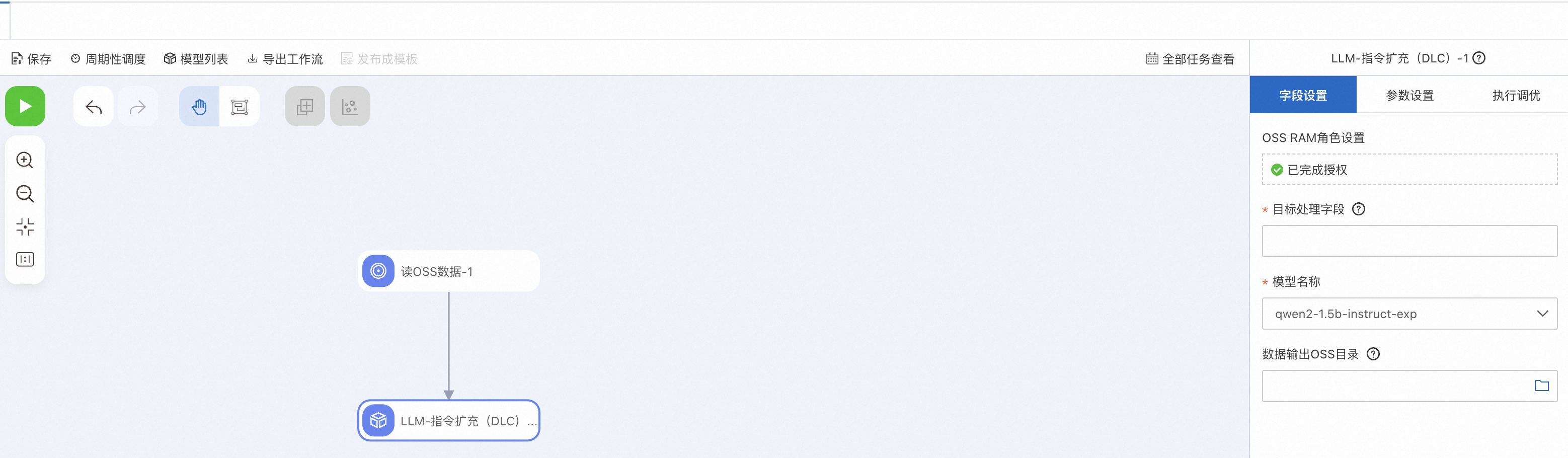
(可选)使用指令优化模型进行指令优化
指令优化是大语言模型提示工程(Prompt Engineering)的另一种常见技术,用于自动优化用户提供的指令数据集,生成更加详细的指令。这些更详细的指令能让大语言模型输出更详细的回复。
例如,在指令优化模型中给定如下输入:
如何做鱼香肉丝? 如何准备GRE考试? 如果被朋友误会了怎么办?模型输出类似如下结果:
请提供一个详细的中国四川风味的鱼香肉丝的食谱。包括所需的具体材料列表(如蔬菜、猪肉和调料),以及详细的步骤说明。如果可能的话,还请推荐适合搭配这道菜的小菜和主食。 请提供一个详细的指导方案,包括GRE考试的报名、所需资料、备考策略和建议的复习资料。同时,如果可以的话,也请推荐一些有效的练习题和模拟考试来帮助我更好地准备考试。 请提供一个详细的指导,教我如何在被朋友误会时保持冷静和理智,并且有效地沟通来解决问题。请包括一些实用的建议,例如如何表达自己的想法和感受,以及如何避免误解加剧,并且建议一些具体的对话场景和情境,以便我能更好地理解和练习。
由于指令的详细性直接影响了大语言模型的输出指令,进行指令优化能有效提升最终产出学生模型的效果。基于Qwen2基座模型,PAI提供了两款自主研发的指令优化模型,分别为Qwen2-1.5B-Instruct-Refine和Qwen2-7B-Instruct-Refine。您可以在PAI-Model Gallery中一键部署模型服务,具体操作步骤如下:
部署模型服务
进入Model Gallery页面。
登录PAI控制台。
在顶部左上角根据实际情况选择地域。
在左侧导航栏选择工作空间列表,单击指定工作空间名称,进入对应工作空间内。
在左侧导航栏选择。
在Model Gallery页面右侧的模型列表中,搜索Qwen2-1.5B-Instruct-Refine或Qwen2-7B-Instruct-Refine,并在相应卡片中单击部署。
在部署配置面板中,系统已默认配置了模型服务信息和资源部署信息,您也可以根据需要进行修改。参数配置完成后单击部署按钮。
在计费提醒对话框中,单击确定。
系统自动跳转到部署任务页面,当状态为运行中时,表示服务部署成功。
调用模型服务
服务部署成功后,您可以使用API进行模型推理。具体使用方法参考LLM大语言模型部署。以下提供一个示例,展示如何通过客户端发起Request调用:
获取服务访问地址和Token。
在服务详情页面,单击基本信息区域的查看调用信息。
在调用信息对话框中,查询服务访问地址和Token,并保存到本地。
在终端中,创建并执行如下Python代码文件来调用服务。
import argparse import json import requests from typing import List def post_http_request(prompt: str, system_prompt: str, host: str, authorization: str, max_new_tokens: int, temperature: float, top_k: int, top_p: float) -> requests.Response: headers = { "User-Agent": "Test Client", "Authorization": f"{authorization}" } pload = { "prompt": prompt, "system_prompt": system_prompt, "top_k": top_k, "top_p": top_p, "temperature": temperature, "max_new_tokens": max_new_tokens, "do_sample": True, "eos_token_id": 151645 } response = requests.post(host, headers=headers, json=pload) return response def get_response(response: requests.Response) -> List[str]: data = json.loads(response.content) output = data["response"] return output if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("--top-k", type=int, default=2) parser.add_argument("--top-p", type=float, default=0.95) parser.add_argument("--max-new-tokens", type=int, default=256) parser.add_argument("--temperature", type=float, default=0.5) parser.add_argument("--prompt", type=str, default="给我唱首歌。") args = parser.parse_args() prompt = args.prompt top_k = args.top_k top_p = args.top_p temperature = args.temperature max_new_tokens = args.max_new_tokens host = "EAS HOST" authorization = "EAS TOKEN" print(f" --- input: {prompt}\n", flush=True) system_prompt = "请优化这个指令,将其修改为一个更详细具体的指令。" response = post_http_request( prompt, system_prompt, host, authorization, max_new_tokens, temperature, top_k, top_p) output = get_response(response) print(f" --- output: {output}\n", flush=True)其中:
host:配置为已获取的服务访问地址。
authorization:配置为已获取的服务Token。
批量实现指令优化
您可以使用上述EAS在线服务进行批量调用,实现批量指令优化。以下代码示例展示了如何读取自定义的JSON格式数据集,批量调用上面的模型接口进行质量优化。您需要在终端中,创建并执行如下Python代码文件来批量调用模型服务。
import requests
import json
import random
from tqdm import tqdm
from typing import List
input_file_path = "input.json" # 输入文件名
with open(input_file_path) as fp:
data = json.load(fp)
pbar = tqdm(total=len(data))
new_data = []
for d in data:
prompt = d["instruction"]
system_prompt = "请优化以下指令。"
top_k = 50
top_p = 0.95
temperature = 1
max_new_tokens = 2048
host = "EAS HOST"
authorization = "EAS TOKEN"
response = post_http_request(
prompt, system_prompt,
host, authorization,
max_new_tokens, temperature, top_k, top_p)
output = get_response(response)
temp = {
"instruction": output
}
new_data.append(temp)
pbar.update(1)
pbar.close()
output_file_path = "output.json" # 输出文件名
with open(output_file_path, 'w') as f:
json.dump(new_data, f, ensure_ascii=False)
其中:
host:配置为已获取的服务访问地址。
authorization:配置为已获取的服务Token。
file_path:请替换为数据集文件所在的本地路径。
post_http_request和get_response函数的定义与其在调用模型服务的Python脚本中对应的函数定义保持一致。
您也可以使用PAI-Designer的LLM-指令优化(DLC)组件零代码实现上述功能。具体操作方法,请参考自定义工作流。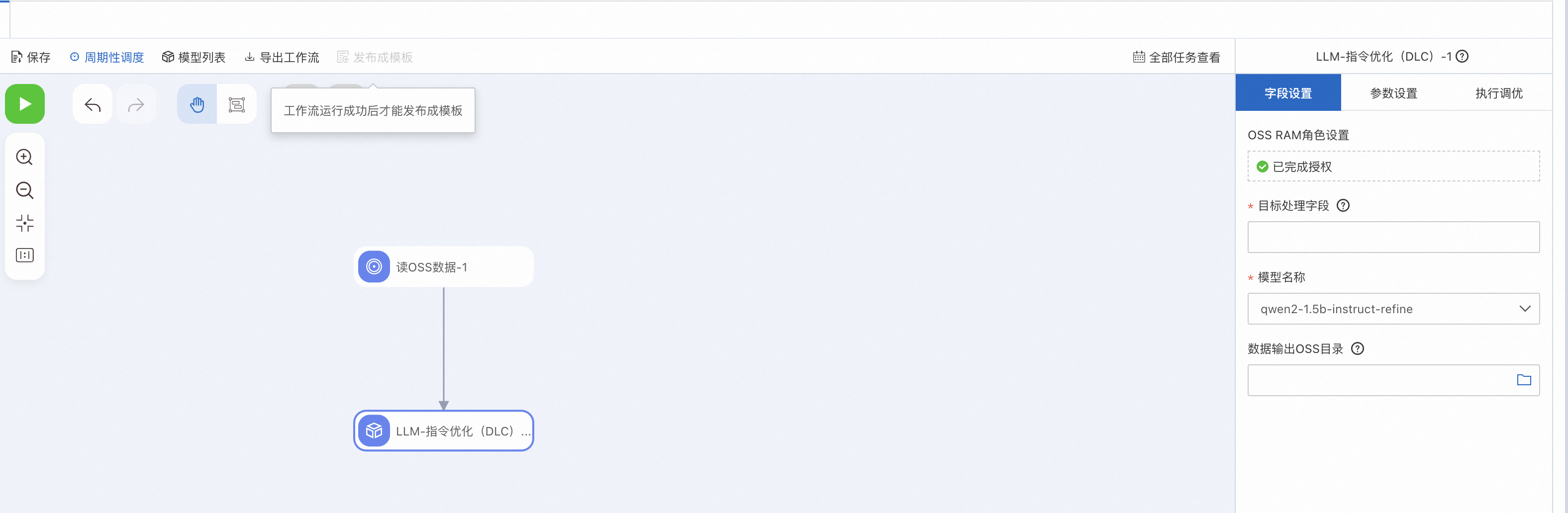
部署教师大语言模型生成对应回复
部署模型服务
在优化好数据集中的指令以后,您可以按照以下操作步骤,部署教师大语言模型生成对应回复。
进入Model Gallery页面。
登录PAI控制台。
在顶部左上角根据实际情况选择地域。
在左侧导航栏选择工作空间列表,单击指定工作空间名称,进入对应工作空间内。
在左侧导航栏选择。
在Model Gallery页面右侧的模型列表中,搜索通义千问2-72B-Instruct,并在相应卡片中单击部署。
在部署配置面板中,系统已默认配置了模型服务信息和资源部署信息,您也可以根据需要进行修改。参数配置完成后单击部署按钮。
在计费提醒对话框中,单击确定。
系统自动跳转到部署任务页面,当状态为运行中时,表示服务部署成功。
调用模型服务
服务部署成功后,您可以使用API进行模型推理。具体使用方法参考LLM大语言模型部署。以下提供一个示例,展示如何通过客户端发起Request调用:
获取服务访问地址和Token。
在服务详情页面,单击基本信息区域的查看调用信息。
在调用信息对话框中,查询服务访问地址和Token,并保存到本地。
在终端中,创建并执行如下Python代码文件来调用服务。
import argparse import json import requests from typing import List def post_http_request(prompt: str, system_prompt: str, host: str, authorization: str, max_new_tokens: int, temperature: float, top_k: int, top_p: float) -> requests.Response: headers = { "User-Agent": "Test Client", "Authorization": f"{authorization}" } pload = { "prompt": prompt, "system_prompt": system_prompt, "top_k": top_k, "top_p": top_p, "temperature": temperature, "max_new_tokens": max_new_tokens, "do_sample": True, } response = requests.post(host, headers=headers, json=pload) return response def get_response(response: requests.Response) -> List[str]: data = json.loads(response.content) output = data["response"] return output if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("--top-k", type=int, default=50) parser.add_argument("--top-p", type=float, default=0.95) parser.add_argument("--max-new-tokens", type=int, default=2048) parser.add_argument("--temperature", type=float, default=0.5) parser.add_argument("--prompt", type=str) parser.add_argument("--system_prompt", type=str) args = parser.parse_args() prompt = args.prompt system_prompt = args.system_prompt top_k = args.top_k top_p = args.top_p temperature = args.temperature max_new_tokens = args.max_new_tokens host = "EAS HOST" authorization = "EAS TOKEN" print(f" --- input: {prompt}\n", flush=True) response = post_http_request( prompt, system_prompt, host, authorization, max_new_tokens, temperature, top_k, top_p) output = get_response(response) print(f" --- output: {output}\n", flush=True)其中:
host:配置为已获取的服务访问地址。
authorization:配置为已获取的服务Token。
批量实现教师模型的指令标注
以下代码示范了如何读取自定义JSON格式数据集,批量调用上述模型接口进行教师模型标注。您需要在终端中,创建并执行如下Python代码文件来批量调用模型服务。
import json
from tqdm import tqdm
import requests
from typing import List
input_file_path = "input.json" # 输入文件名
with open(input_file_path) as fp:
data = json.load(fp)
pbar = tqdm(total=len(data))
new_data = []
for d in data:
system_prompt = "You are a helpful assistant."
prompt = d["instruction"]
print(prompt)
top_k = 50
top_p = 0.95
temperature = 0.5
max_new_tokens = 2048
host = "EAS HOST"
authorization = "EAS TOKEN"
response = post_http_request(
prompt, system_prompt,
host, authorization,
max_new_tokens, temperature, top_k, top_p)
output = get_response(response)
temp = {
"instruction": prompt,
"output": output
}
new_data.append(temp)
pbar.update(1)
pbar.close()
output_file_path = "output.json" # 输出文件名
with open(output_file_path, 'w') as f:
json.dump(new_data, f, ensure_ascii=False)其中:
host:配置为已获取的服务访问地址。
authorization:配置为已获取的服务Token。
file_path:请替换为数据集文件所在的本地路径。
post_http_request和get_response函数的定义与其在调用模型服务脚本中对应的函数定义保持一致。
蒸馏训练较小的学生模型
训练模型
当获得教师模型的回复后,您可以在PAI-Model Gallery中,实现学生模型的训练,无需编写代码,极大简化了模型的开发过程。本方案以Qwen2-7B-Instruct模型为例,为您介绍如何使用已准备好的训练数据,在PAI-Model Gallery中进行模型训练,具体操作步骤如下:
进入Model Gallery页面。
登录PAI控制台。
在顶部左上角根据实际情况选择地域。
在左侧导航栏选择工作空间列表,单击指定工作空间名称,进入对应工作空间内。
在左侧导航栏选择。
在Model Gallery页面右侧的模型列表中,搜索并单击通义千问2-7B-Instruct模型卡片,进入模型详情页面。
在模型详情页面,单击右上角的微调训练。
在微调训练配置面板中,配置以下关键参数,其他参数取默认配置。
参数
描述
默认值
数据集配置
训练数据集
在下拉列表中选择OSS文件或目录,并按照以下步骤选择数据集文件所在的OSS存储路径:
单击
 ,并选择已创建的OSS存储空间。
,并选择已创建的OSS存储空间。单击上传文件,并按控制台操作指引,将从上述步骤获得的数据集文件上传到OSS目录中。
单击确定。
无
训练输出配置
model
单击
 ,选择已创建的OSS存储目录。
,选择已创建的OSS存储目录。无
tensorboard
单击
,选择已创建的OSS存储目录。无
计算资源配置
任务资源
选择资源规格,系统会自动推荐适合的资源规格。
无
超参数配置
learning_rate
模型训练的学习率,Float类型。
5e-5
num_train_epochs
训练轮次,INT类型。
1
per_device_train_batch_size
每张GPU卡在一次训练迭代的数据量,INT类型。
1
seq_length
文本序列长度,INT类型。
128
lora_dim
LoRA维度,INT类型。当lora_dim>0时,使用LoRA/QLoRA轻量化训练。
32
lora_alpha
LoRA权重,INT类型。当lora_dim>0时,使用LoRA/QLoRA轻量化训练,该参数生效。
32
load_in_4bit
模型是否以4比特加载,bool类型。取值如下:
true
false
当lora_dim>0、load_in_4bit为true且load_in_8bit为false时,使用4比特QLoRA轻量化训练。
true
load_in_8bit
模型是否以8比特加载,bool类型。取值如下:
true
false
当lora_dim>0、load_in_4bit为false且load_in_8bit为true时,使用8比特QLoRA轻量化训练。
false
gradient_accumulation_steps
梯度累积步数,INT类型。
8
apply_chat_template
算法是否结合训练数据与默认的Chat Template来优化模型输出,bool类型。取值如下:
true
false
以Qwen2系列模型为例,格式为:
问题:
<|im_end|>\n<|im_start|>user\n + instruction + <|im_end|>\n答案:
<|im_start|>assistant\n + output + <|im_end|>\n
true
system_prompt
模型训练使用的系统提示语,String类型。
You are a helpful assistant
参数配置完成后,单击训练。
在计费提醒对话框中,单击确定。
系统将自动跳转到训练任务页面。
部署模型服务
当模型训练完成后,您可以按照以下操作步骤,将模型部署为EAS在线服务。
在训练任务页面右侧,单击部署。
在部署配置面板中,系统已默认配置了模型服务信息和资源部署信息,您也可以根据需要进行修改。参数配置完成后单击部署按钮。
在计费提醒对话框中,单击确定。
系统自动跳转到部署任务页面,当状态为运行中时,表示服务部署成功。
调用模型服务
服务部署成功后,您可以使用API进行模型推理。具体使用方法参考LLM大语言模型部署。