阿里云人工智能平台PAI是NVIDIA授权的中国NIM合作伙伴。
NIM是英伟达推出的一套易于使用的预构建容器工具,目的是帮助企业客户在云、数据中心和工作站上安全、可靠的部署高性能的Al模型推理。NIM模型是通过NIM优化工具加工的性能优化后模型,相比原始开源模型有显著的推理性能提升。
在PAI-Model Gallery中提供了多个NIM模型(可通过在模型广场的左侧筛选栏选择“模型来源”为“NIM”来获取),支持2种使用方式:
支持的NIM模型列表
当前在人工智能平台PAI-Model Gallery中可直接部署的NIM模型如下:
模型名称 | Model Gallery模型页面 | NIM推理优化支持的机型 |
qwen2.5-7b-instruct-NIM | ecs.gn7e系列 ecs.gn8is系列 | |
MolMIM | 通用GPU机型 | |
Earth-2 FourCastNet | 通用GPU机型 | |
NVIDIA Retrieval QA Mistral 7B Embedding v2 | ecs.gn7e系列 | |
Eye Contact | 通用GPU机型 | |
NV-CLIP | ecs.gn7e系列 ecs.gn7i系列 | |
AlphaFold2-Multimer | 通用GPU机型 | |
Snowflake Arctic Embed Large Embedding | ecs.gn7e系列 ecs.gn7i系列 | |
NVIDIA Retrieval QA Mistral 4B Reranking v3 | ecs.gn7e系列 ecs.gn7i系列 | |
NVIDIA Retrieval QA E5 Embedding v5 | ecs.gn7e系列 ecs.gn7i系列 | |
Parakeet CTC Riva 1.1b | 通用GPU机型 | |
FastPitch HifiGAN Riva | 通用GPU机型 | |
VISTA-3D | 通用GPU机型 | |
AlphaFold2 | 通用GPU机型 | |
ProteinMPNN | 通用GPU机型 | |
megatron-1b-nmt | 通用GPU机型 |
在PAI-Model Gallery中一键部署使用
在模型广场的左侧筛选栏选择“模型来源”为“NIM”,找到NIM模型

选择NIM模型进入模型详情页,点击右上角部署按钮即可进入部署页面。请注意,在PAI中部署NIM模型需要您已经是 NVIDIA AI Enterprise 用户或 NVIDIA Developer Program 用户。

配置运行资源等信息后,点击部署按钮即可拉起NIM模型在线服务。调用方式请参考模型介绍。

本地部署使用
NIM模型允许用户下载镜像和模型,在本地部署使用。(需要您已经是 NVIDIA AI Enterprise 用户或 NVIDIA Developer Program 用户)
配置环境。详情请参见Getting Started。
在NIM模型的模型详情页点击「下载地址」,确认NIM下载条款许可声明,获取镜像和模型地址。
通过以下命令拉取镜像(请替换 ${镜像地址} 为实际的镜像地址)
docker pull ${镜像地址}使用阿里云ossutil工具下载模型文件。
使用命令启动容器(以模型文件保存在您本地的/local/model/目录下为例;请替换 ${模型挂载路径} 和 ${镜像地址} 为实际的模型挂载路径和镜像地址)
docker run --rm \ --runtime=nvidia \ --gpus all \ -u $(id -u) \ -v /local/model/:${模型挂载路径} ${镜像地址}
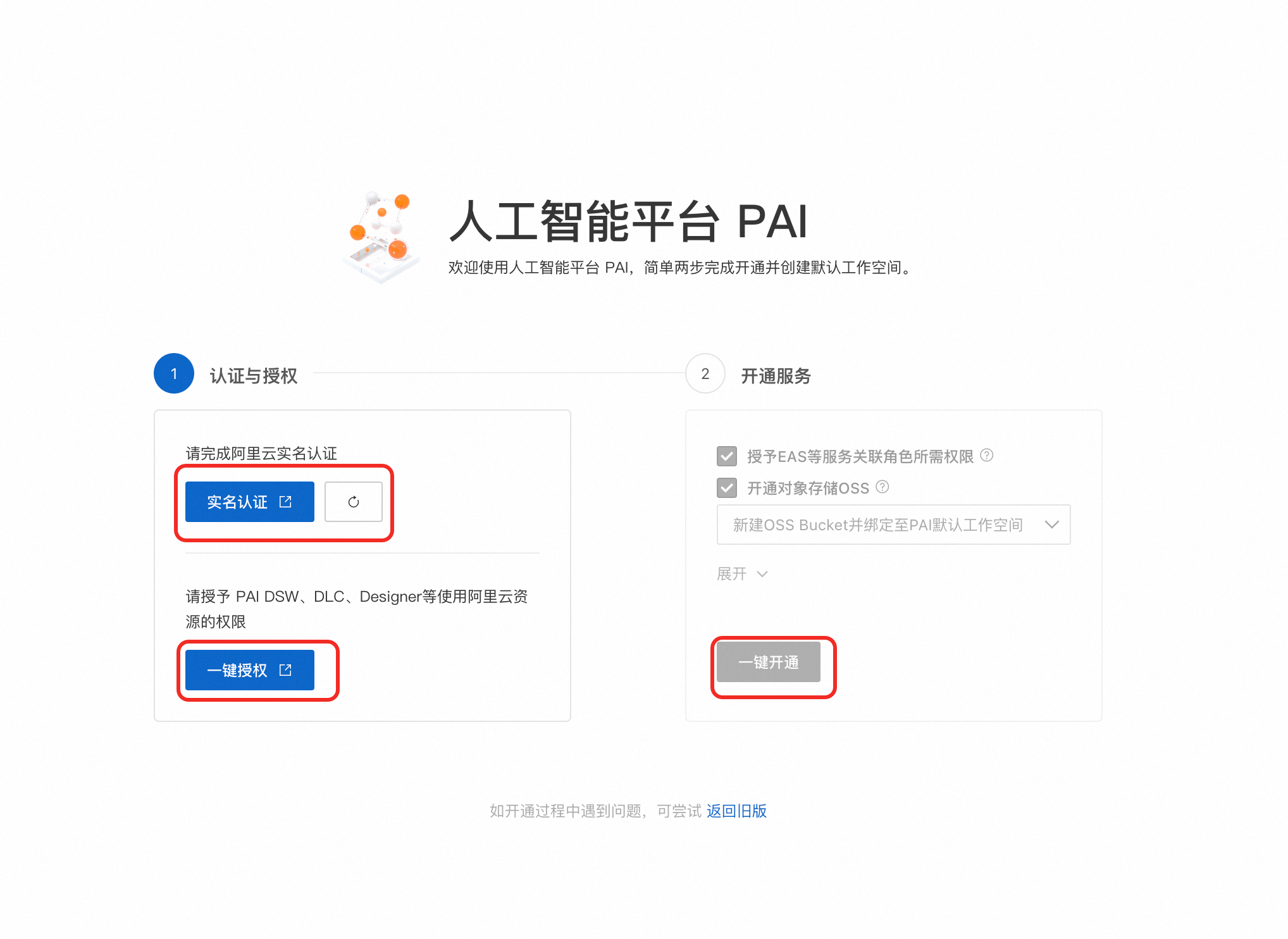
附录:首次使用PAI平台开通流程
对于未注册/未登录阿里云的用户,首次使用PAI-Model Gallery可参考以下流程: