
性能监控最佳实践
建设一体化性能监控平台
随着互联网技术的不断发展,企业的业务规模和复杂度也在不断增加。为了保证业务的稳定性和可靠性,企业需要对其系统进行全面的性能监控。而一体化性能监控就是一种集成了多种监控工具和技术的综合性监控方案,可以帮助企业更加全面、高效地监控其系统的性能。
提高监控效率:传统的性能监控方案往往需要使用多个不同的监控工具,例如网络监控、服务器监控、数据库监控等。这些工具往往需要单独配置和管理,而且监控数据也分散在不同的系统中,导致监控效率低下。而一体化性能监控则可以将多个监控工具集成在一起,通过一个统一的监控平台进行管理和监控。这样可以大大提高监控效率,减少监控人员的工作量,同时也可以更加全面地监控系统的性能。
提高监控精度:传统的性能监控方案往往只能监控系统的基本指标,例如CPU使用率、内存利用率等。而一体化性能监控则可以通过集成多种监控工具和技术,监控系统的各个方面,例如网络流量、磁盘IO、数据库响应时间等。这样可以更加全面地了解系统的性能状况,及时发现和解决问题,提高监控精度。
提高故障排查效率:当系统或应用出现故障时,传统的性能监控方案通常需要IT运维人员手动分析监控数据来确定故障原因,这样会浪费大量的时间和精力。而一体化性能监控能够对多种关联的监控数据进行自动分析和处理,帮助IT运维人员快速定位故障原因,从而提高故障排查效率。
提高监控可视化程度:一体化性能监控可以通过统一可视化界面,综合展示不同类型的性能监控数据,使监控数据更加直观、易于理解,帮助监控人员更快地发现和解决问题。同时,一体化性能监控还可以通过报警机制,及时通知监控人员发现问题,提高监控的实时性和响应速度。
因此,一体化性能监控是当今企业信息化建设中不可或缺的一部分。通过将多个性能监控工具整合在一起,形成一个统一的监控平台,可以提高监控效率、监控精度、故障排查效率和可视化程度,从而帮助企业更好地了解其业务系统的运行情况,提高业务系统的稳定性和可靠性。
建设一体化性能监控平台步骤
一体化性能监控平台是指将多个性能监控工具整合在一起,形成一个统一的平台,以便更好地监控和管理系统的性能。建设一体化性能监控平台通常需要以下步骤:
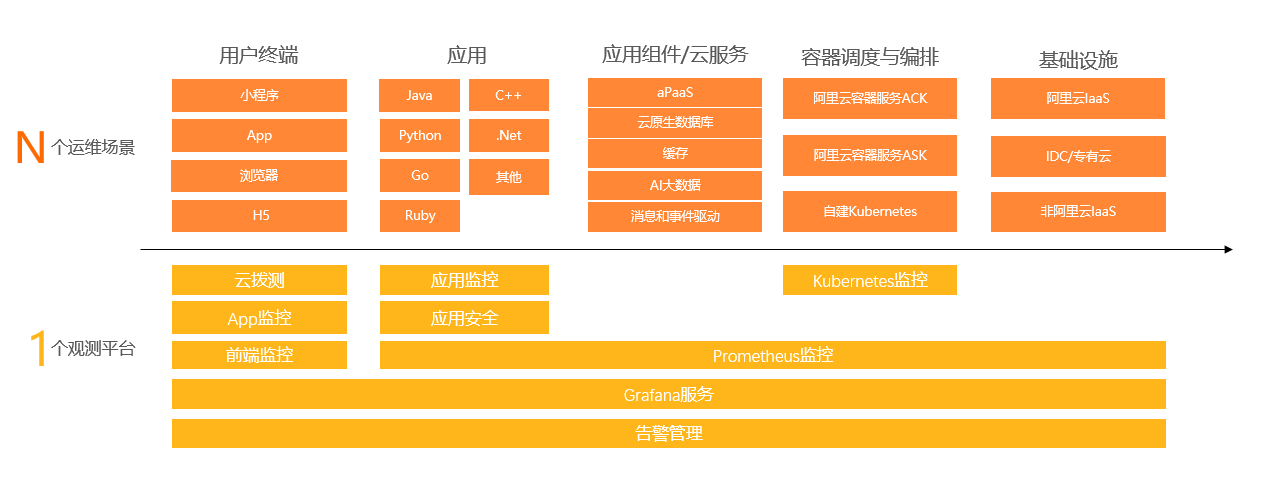
确定监控需求:首先需要明确监控的目标和需求,包括监控的对象、监控的指标、监控的频率等。这些需求将决定后续的监控工具的选择和配置。性能监控的常见对象包括请求耗时、缓存命中率、FullGC 次数、数据库连接数、CPU 使用率等等。几乎覆盖了全栈IT设施,比如用户终端、网关、微服务应用、数据库、容器或物理机等。
选择监控工具:根据监控需求,选择适合的监控工具。常见的监控工具包括Zabbix、Nagios、Grafana等。这些工具可以监控服务器、网络、数据库、应用程序等各个方面的性能指标。
配置监控工具:根据监控需求,对所选的监控工具进行配置。这包括添加监控对象、设置监控指标、调整监控频率等。同时,还需要设置告警规则,以便在系统出现异常时及时通知管理员。
整合监控工具:将多个监控工具整合在一起,形成一个统一的监控平台。这可以通过使用开源的监控集成工具,如Prometheus、Grafana等来实现。这些工具可以将不同的监控数据整合在一起,形成一个统一的监控视图。
数据可视化:将监控数据可视化,以便管理员更直观地了解系统的性能状况。这可以通过使用Grafana等工具来实现。Grafana可以将监控数据以图表、仪表盘等形式展示出来,方便管理员进行分析和决策。
自动化运维:将监控平台与自动化运维工具结合起来,实现自动化运维。这可以通过使用Ansible、SaltStack等工具来实现。这些工具可以根据监控数据自动化地进行故障排除、性能优化等操作,提高系统的稳定性和性能。
建设一体化性能监控平台需要根据监控需求选择合适的监控工具,进行配置和整合,实现数据可视化和自动化运维,以提高系统的稳定性和性能。从 0 到 1 自建一套一体化性能监控平台,需要投入巨大的人力研发、运维和试错成本。阿里云可观测团队面向海量用户场景,通过多年的自研技术沉淀,探索出了一套符合开源标准、稳定可靠、易扩展的一体化性能监控最佳实践。通过应用实时监控服务 ARMS(Application Real-Time Monitoring Service)构建的第四代可观测产品,以应用为中心,向上连接用户体验,向下连接基础设施与云服务,一站式满足企业在业务连续性、架构稳定性乃至业务增长等核心诉求。
实现端到端全链路追踪
链路追踪的价值在于“关联”,终端用户、后端应用、云端组件(数据库、消息等)共同构成了链路追踪的轨迹拓扑大图。这张拓扑覆盖的范围越广,链路追踪能够发挥的价值就越大。而全链路追踪就是覆盖全部关联 IT 系统,能够完整记录用户行为在系统间调用路径与状态的最佳实践方案。
完整的全链路追踪可以为业务带来三大核心价值:端到端问题诊断,系统间依赖梳理,自定义标记透传。
端到端问题诊断:VIP 客户下单失败,内测用户请求超时,许多终端用户的体验问题,追根溯源就是由于后端应用或云端组件异常导致的。而全链路追踪是解决端到端问题的首选方案。
系统间依赖梳理:新业务上线,老业务裁撤,机房搬迁/架构升级,IT 系统间的依赖关系错综复杂,已经超出了人工梳理的能力范畴,基于全链路追踪的拓扑发现,使得上述场景决策更加敏捷、可信。
自定义标记透传:全链路压测,用户级灰度,订单追溯,流量隔离。基于自定义标记的分级处理&数据关联,已经衍生出了一个繁荣的全链路生态。然而,一旦发生数据断链、标记丢失,也将引发不可预知的逻辑灾难。
全链路追踪的挑战
全链路追踪的价值与覆盖的范围成正比,它的挑战也同样如此。为了最大程度地确保链路完整性,无论是前端应用还是云端组件,无论是 Java 语言还是 Go 语言,无论是公有云还是自建机房,都需要遵循同一套链路规范,并实现数据互联互通。多语言协议栈统一、前/后/云(多)端联动、跨云数据融合是实现全链路追踪的三大挑战,如下图所示。
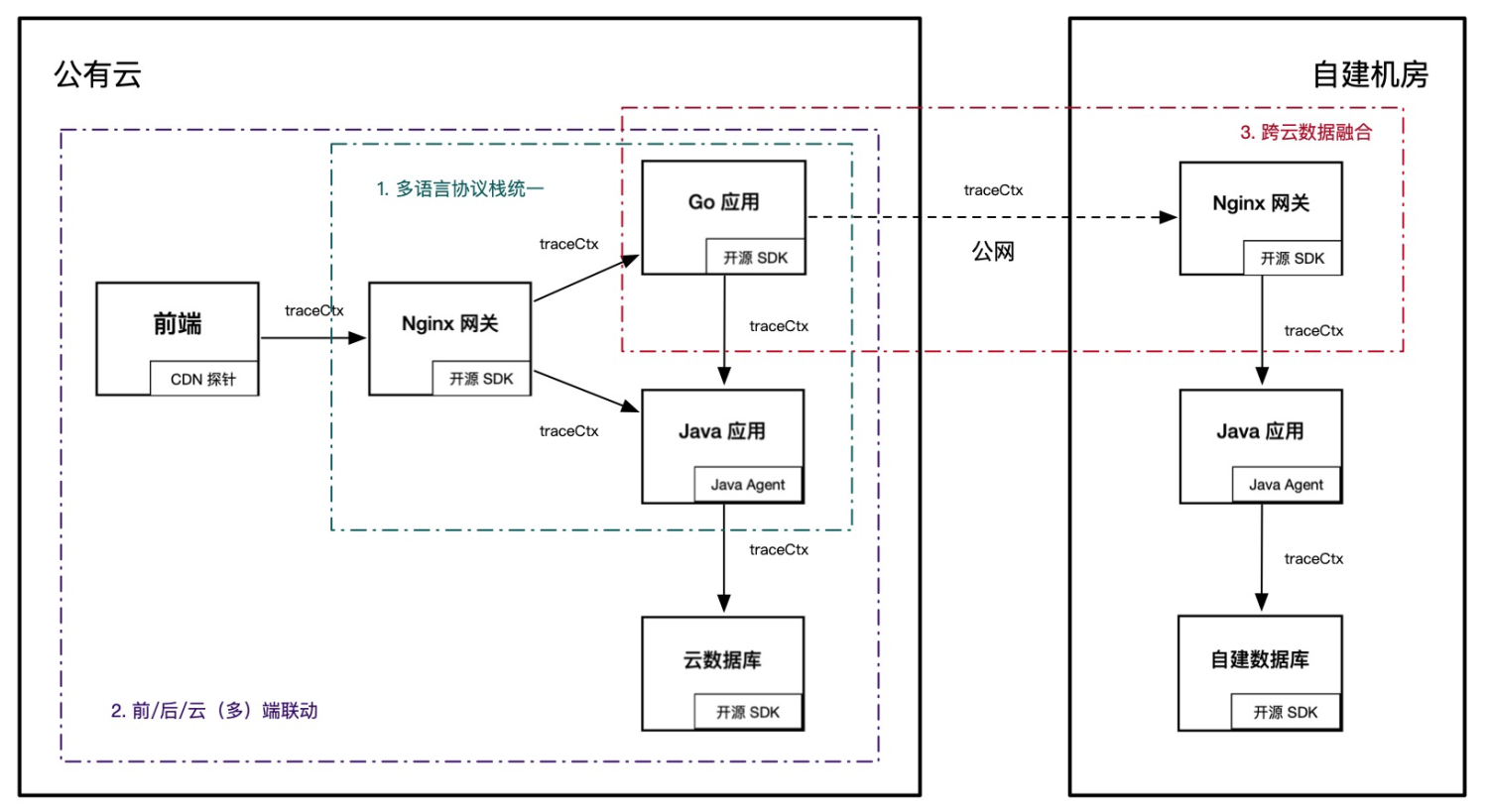
多语言协议栈统一
在云原生时代,多语言应用架构越来越普遍,利用不同语言特性实现最佳的性能和研发体验,已经成为一种趋势。但是,不同语言的成熟度差异,使得全链路追踪无法做到完全的能力一致。目前业界的主流做法是,先保证远程调用协议层格式统一,多语言应用内部自行实现调用拦截与上下文透传,这样可以确保基础的链路数据完整。
但是,绝大部分线上问题无法仅通过链路追踪的基础能力就能够有效定位并解决,线上系统的复杂性决定了一款优秀的 Trace 产品必须提供更加全面、有效的数据诊断能力,比如代码级诊断、内存分析、线程池分析、无损统计等等。充分利用不同语言提供的诊断接口,最大化的释放多语言产品能力是 Trace 能够不断向前发展的基础。
透传协议标准化:全链路所有应用需要遵循同一套协议透传标准,保证链路上下文在不同语言应用间能够完整透传,不会出现断链或上下文缺失的问题。目前主流的开源透传协议包括 W3C、Jaeger、B3、SkyWalking等。
最大化释放多语言产品能力:链路追踪除了最基础的调用链功能外,逐步衍生出了应用/服务监控,方法栈追踪,性能剖析等高阶能力。但是不同语言的成熟度导致产品能力差异较大,比如 Java 探针可以基于 JVMTI 实现很多高阶的边缘侧诊断。优秀的全链路追踪方案会最大化的释放每种语言的差异化技术红利,而不是一味的追求趋同平庸。
前后云(多)端联动
目前开源的链路追踪实现主要集中于后端业务应用层,在用户终端和云端组件(如云数据库)侧缺乏有效的埋点手段。主要原因是后两者通常由云服务商或三方厂商提供服务,依赖于厂商对于开源的兼容适配性是否友好。而业务方很难直接介入开发。
上述情况的直接影响是前端页面响应慢,很难直接定位到后端哪个应用或服务导致的,无法明确给出确定性的根因。同理,云端组件的异常也难以直接与业务应用异常划等号,特别是多个应用共享同一个数据库实例等场景下,需要更加迂回的手段进行验证,排查效率十分低下。
为了解决此类问题,首先需要云服务商更好的支持开源链路标准,添加核心方法埋点,并支持开源协议栈透传与数据回流(如应用实时监控服务的前端监控能力支持 Jaeger 协议透传与方法栈追踪)。
其次,由于不同系统的业务归属等问题,无法完成全链路协议栈统一,为了实现多端联动,需要由 Trace 系统提供异构协议栈的打通方案。
为了实现异构协议栈的打通,Trace 系统需要支持两项能力:
协议栈转换与动态配置,比如前端向下透传了 Jaeger 协议,新接入的下游外部系统使用的则是 ZipKin B3 协议。在两者之间的 Node.js 应用可以接收 Jaeger 协议并向下透传 B3 协议,保证全链路标记透传完整性。
服务端数据格式转换,可以将上报的不同数据格式转换成统一格式进行存储,或者在查询侧进行兼容。前者维护成本相对较小,后者兼容性成本更高,但相对更灵活。
跨云数据融合
很多大型企业,出于稳定性或数据安全等因素考虑,选择了多云部署,这种部署架构下,由于不同环境的网络隔离,以及基础设施的差异性,为运维人员带来了巨大的挑战。
由于云环境间仅能通过公网通信,为了实现多云部署架构下的链路完整性,可以采用链路数据跨云上报、跨云查询等方式。无论哪种方式,目标都是实现多云数据统一可见,通过完整链路数据快速定位或分析问题。
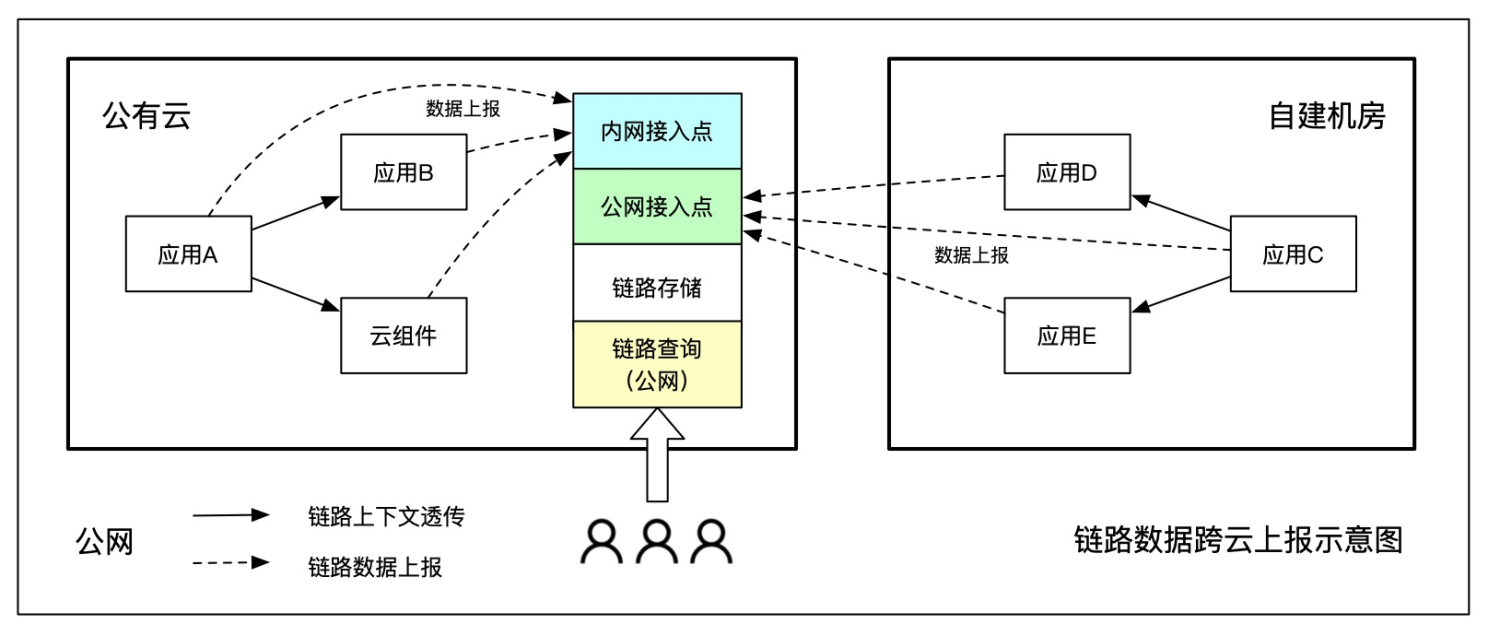
跨云上报
链路数据跨云上报的实现难度相对较低,便于维护管理,是目前云厂商采用的主流做法,比如应用实时监控服务就是通过跨云数据上报实现的多云数据融合。
跨云上报的优点是部署成本低,一套服务端便于维护;缺点是跨云传输会占用公网带宽,公网流量费用和稳定性是重要限制条件。跨云上报比较适合一主多从架构,绝大部分节点部署在一个云环境内,其他云/自建机房仅占少量业务流量,比如某企业 toC 业务部署在阿里云,企业内部应用部署在自建机房,就比较适合跨云上报的方式,如下图所示。
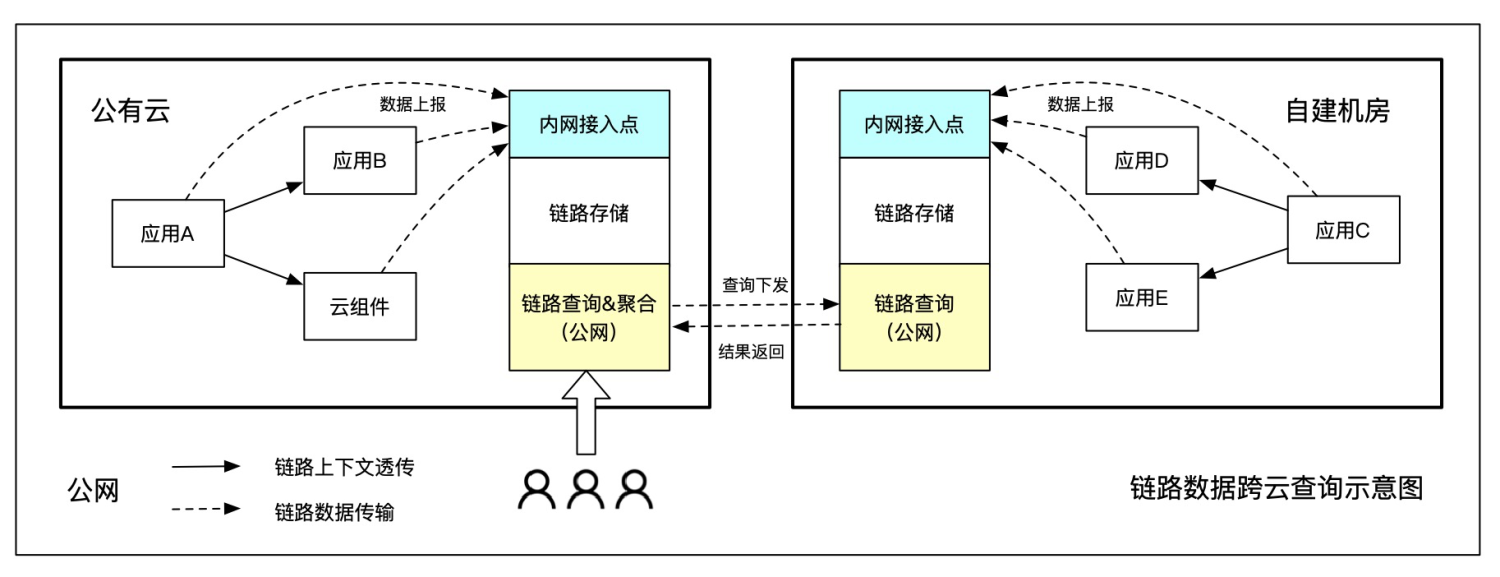
跨云查询
跨云查询是指原始链路数据保存在当前云网络内,将一次用户查询分别下发,再将查询结果聚合进行统一处理,减少公网传输成本。
跨云查询的优点就是跨网传输数据量小,特别是链路数据的实际查询量通常不到原始数据量的万分之一,可以极大地节省公网带宽。缺点是需要部署多个数据处理终端,不支持分位数、全局 TopN 等复杂计算。比较适合多主架构,简单的链路拼接、max/min/avg 统计都可以支持。
跨云查询实现有两种模式,一种是在云网络内部搭建一套集中式的数据处理终端,并通过内网专线打通用户网络,可以同时处理多个用户的数据;另一种是为每个用户单独搭建一套 VPC 内的数据处理终端。前者维护成本低,容量弹性更大;后者数据隔离性更好。
其他方式
除了上述两种方案,在实际应用中还可以采用混合模式或仅透传模式。
混合模式是指将统计数据通过公网统一上报,进行集中处理(数据量小,精度要求高),而链路数据采用跨云查询方式进行检索(数据量大,查询频率低)。
仅透传模式是指每个云环境之间仅保证链路上下文能够完整透传,链路数据的存储与查询独立实现。这种模式的好处就是实现成本极低,每朵云之间仅需要遵循同一套透传协议,具体的实现方案可以完全独立。通过同一个 TraceId 或应用名进行人工串联,比较适合存量系统的快速融合,改造成本最小。
阿里云全链路追踪最佳实践
阿里云环境下,可以基于可观测链路 OpenTelemetry 版,从 0 到 1 快速构建一套贯穿前端、网关、服务端、容器和云组件的全链路追踪体系。
Header 透传格式:全链路统一采用一种透传协议,可以是 W3C TraceContext、B3 或 Jaeger 等格式。
前端接入:可以采用 CDN(Script 注入)或 NPM 两种低代码接入方式,支持 Web/H5、小程序等场景。
后端接入:
Java 应用推荐优先使用 ARMS Agent,无侵入式埋点无需代码改造,支持边缘诊断、无损统计、精准采样等高阶功能。用户自定义方法可以通过 OpenTelemetry SDK 主动埋点。
非 Java 应用推荐接入可观测链路 OpenTelemetry 版,将数据上报至对应接入点,实现多语言应用间的链路透传与展示。
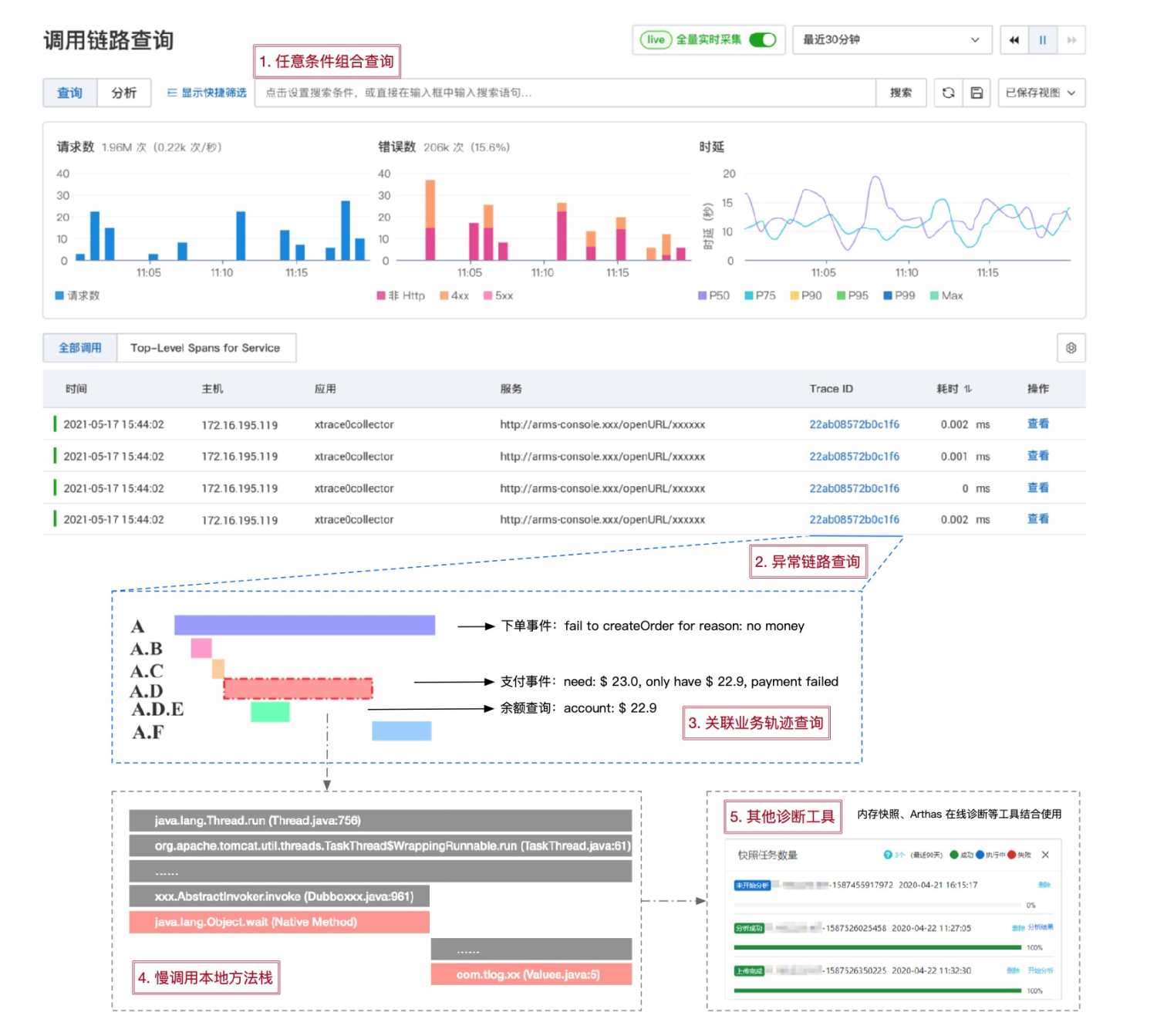
全链路追踪仅仅只是开始,远远不是结束。基于全链路追踪生态,关联更多的指标、日志、事件、Profiling 等数据或工具,提升问题诊断或业务分析效率,才能更好的发挥全链路追踪的价值。
结合阿里云用户实践,一个典型的链路筛选与诊断过程,主要分为以下几步:
根据 TraceId、应用名、接口名、耗时、状态码、自定义标签等任意条件组合过滤出目标调用链。
从满足过滤条件的调用链列表中选中一条链路查询详情。
结合请求调用轨迹,本地方法栈,主动/自动关联数据(如SQL、业务日志)综合分析调用链。
如果上述信息仍无法定位根因,需要结合内存快照、Arthas 在线诊断等工具进行二次分析。