
如果您需要对MaxCompute(ODPS)中的海量数据进行信息检索、多维查询、统计分析等操作,可借助阿里云Elasticsearch实现。本文通过DataWorks的数据集成服务,实现最快分钟级,将海量MaxCompute数据离线同步到阿里云ES中。
背景信息
DataWorks是一个基于大数据引擎,集成数据开发、任务调度、数据管理等功能的全链路大数据开发治理平台。您可以通过DataWorks的同步任务,快速的将各种数据源中的数据同步到阿里云ES。
-
支持同步的数据源包括:
-
阿里云云数据库(MySQL、PostgreSQL、SQL Server、MongoDB、HBase)
-
阿里云PolarDB-X(原DRDS升级版)
-
阿里云MaxCompute
-
阿里云OSS
-
阿里云Tablestore
-
自建HDFS、Oracle、FTP、DB2及以上数据库类型的自建版本
-
-
适用场景:
-
大数据离线同步到阿里云ES的场景,支持同步整个库或同步某个表中的全部数据。更多信息,请参见MySQL整库离线同步至Elasticsearch。
-
大数据在线实时同步到阿里云ES的场景,支持全量、增量一体化同步。更多信息,请参见MySQL整库实时同步至Elasticsearch。
-
前提条件
-
已创建MaxCompute项目。具体操作,请参见创建MaxCompute项目。
-
已创建阿里云ES实例,并开启实例的自动创建索引功能。具体操作,请参见创建阿里云Elasticsearch实例和配置YML参数。
-
已创建DataWorks工作空间。具体操作,请参见创建工作空间。
-
仅支持将数据同步到阿里云ES,不支持自建Elasticsearch。
-
MaxCompute项目、ES实例和DataWorks工作空间所在地域需保持一致。
-
ES实例、MaxCompute和DataWorks工作空间需要创建在同一时区下,否则同步与时间相关的数据时,同步前后的数据可能存在时区差。
费用说明
操作步骤
步骤一:准备源数据
创建MaxCompute表并导入测试数据。具体操作,请参见创建表和导入数据。
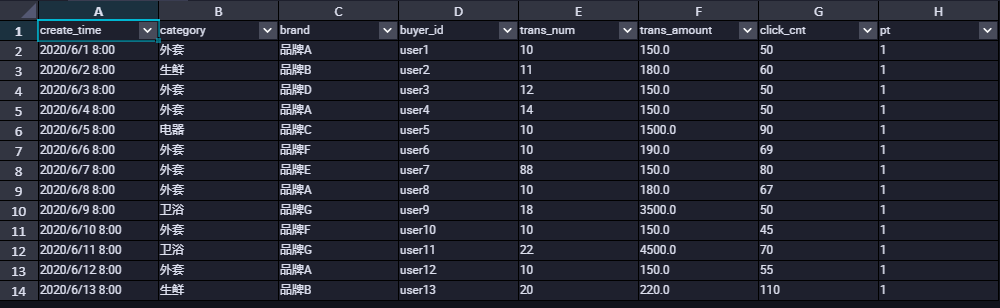
本文使用的表结构和表数据如下所示:
-
表结构
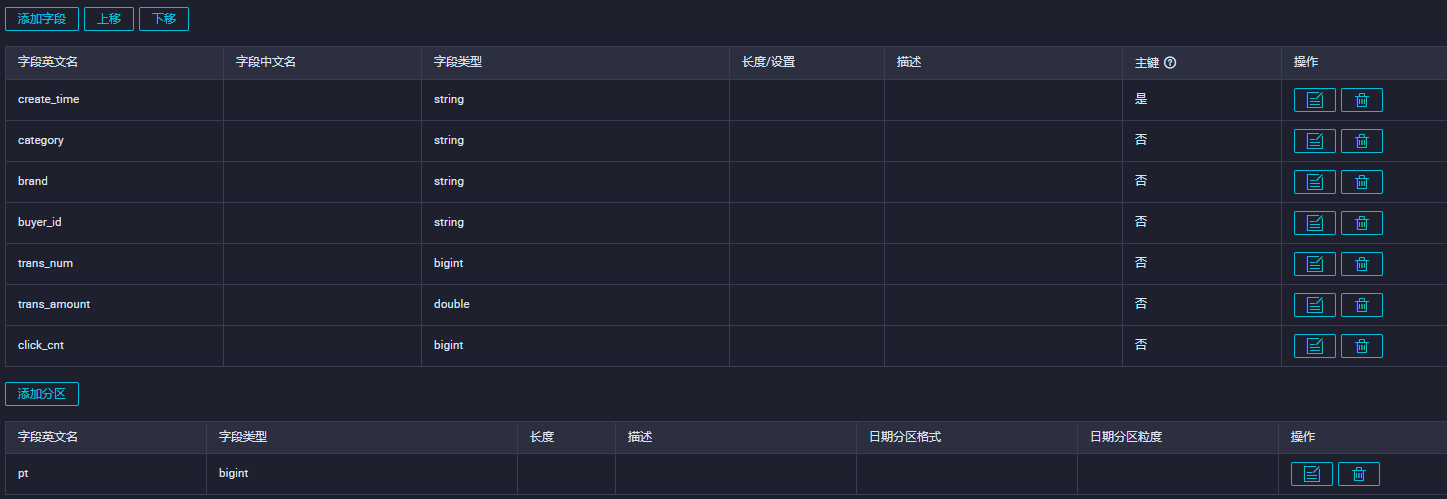
-
部分表数据
步骤二:购买并配置独享资源组
购买一个数据集成独享资源组,并为该资源组绑定专有网络和工作空间。独享资源组可以保证数据快速、稳定地传输。
-
登录DataWorks控制台。
-
在顶部菜单栏选择相应地域后,在左侧导航栏单击资源组。
-
在独享资源组页签下,单击。
-
在DataWorks独享资源(包年包月)购买页面,独享资源类型选择独享数据集成资源,输入资源组名称,单击立即购买,购买独享资源组。
更多配置信息,请参见步骤一:购买资源组。
-
在已创建的独享资源组的操作列,单击网络设置,为该独享资源组绑定专有网络。具体操作,请参见绑定专有网络。
说明本文以独享数据集成资源组通过VPC内网同步数据为例。关于通过公网同步数据,请参见添加白名单。
独享资源需要与Elasticsearch实例的专有网络连通才能同步数据。因此需要绑定Elasticsearch实例所在的专有网络、可用区和交换机。查看Elasticsearch实例所在的专有网络、可用区和交换机,请参见查看Elasticsearch实例的基本信息。
重要绑定专有网络后,您需要将专有网络的交换机网段加入到Elasticsearch实例的VPC私网访问白名单中。具体操作,请参见配置Elastic search实例公网或私网访问白名单。
-
在页面左上角,单击返回图标,返回资源组列表页面。
-
在已创建的独享资源组的操作列,单击绑定工作空间,为该独享资源组绑定目标工作空间。
具体操作,请参见步骤二:绑定归属工作空间。
步骤三:添加数据源
将MaxCompute和Elasticsearch数据源接入DataWorks的数据集成服务中。
-
进入DataWorks的数据集成页面。
-
登录DataWorks控制台。
-
在左侧导航栏,单击工作空间。
-
在目标工作空间的操作列,选择。
-
-
在左侧导航栏,单击数据源。
-
新增MaxCompute数据源。
-
在数据源列表页面,单击新增数据源。
-
在新增数据源页面,搜索并选择MaxCompute数据源。
-
在新增MaxCompute数据源对话框,在基础信息区域配置数据源参数。
配置详情,请参见配置MaxCompute数据源。
-
在连接配置区域,单击测试连通性,连通状态显示为可连通时,表示连通成功。
-
单击完成。
-
-
使用同样的方式添加Elasticsearch数据源。配置详情,请参见配置Elasticsearch数据源。
步骤四:配置并运行数据同步任务
数据同步任务将独享资源组作为一个可以执行任务的资源,独享资源组将获取数据集成服务中数据源的数据,并将数据写入Elasticsearch。
-
有两种方式可以配置离线同步任务,文本以向导模式配置离线同步任务为例。您也可以通过脚本模式配置离线同步任务,详情请参见脚本模式配置和Elasticsearch Writer。
-
本文以旧版数据开发(DataStudio)示例,创建离线同步任务。
-
进入DataWorks的数据开发页面。
-
登录DataWorks控制台。
-
在左侧导航栏,单击工作空间。
-
在目标工作空间的操作列,选择。
-
-
新建一个离线同步任务。
-
在左侧导航栏的数据开发(
 图标)页签,选择,按照界面指引新建一个业务流程。
图标)页签,选择,按照界面指引新建一个业务流程。 -
右键单击新建的业务流程,选择。
-
在新建节点对话框中,输入节点名称,单击确认。
-
-
配置网络与资源
-
在数据来源区域,数据来源选择MaxCompute(ODPS),数据源名称选择待同步的数据源名称。
-
在我的资源组区域,选择独享资源组。
-
在数据去向区域,数据去向选择Elasticsearch,数据源名称选择待同步的数据源名称。
-
-
单击下一步。
-
配置任务。
-
在数据来源区域,选择待同步的表。
-
在数据去向区域,配置数据去向的各参数。
-
在字段映射区域中,设置来源字段与目标字段的映射关系。
-
在通道控制区域,配置通道参数。
详细配置信息,请参见向导模式配置。
-
-
运行任务。
-
(可选)配置任务调度属性。在页面右侧,单击调度配置,按照需求配置相应的调度参数。各配置的详细说明,请参见调度配置。
-
在节点区域的右上角,单击保存图标,保存任务。
-
在节点区域的右上角,单击提交图标,提交任务。
如果您配置了任务调度属性,任务会定期自动执行。您还可以在节点区域的右上角,单击运行图标,立即运行任务。
运行日志中出现
Shell run successfully!表明任务运行成功。部分任务运行日志如下所示:2023-10-31 16:52:35 INFO Exit code of the Shell command 0 2023-10-31 16:52:35 INFO --- Invocation of Shell command completed --- 2023-10-31 16:52:35 INFO Shell run successfully! 2023-10-31 16:52:35 INFO Current task status: FINISH 2023-10-31 16:52:35 INFO Cost time is: 33.106s
-
步骤五:验证数据同步结果
在Kibana控制台中,查看同步成功的数据,并按条件查询数据。
-
登录目标阿里云Elasticsearch实例的Kibana控制台。
具体操作,请参见登录Kibana控制台。
-
单击Kibana页面左上角的
 图标,选择Dev Tools(开发工具)。
图标,选择Dev Tools(开发工具)。 -
在Console(控制台)中,执行如下命令查看同步的数据。
POST /odps_index/_search?pretty { "query": { "match_all": {}} }说明odps_index为您在数据同步脚本中设置的index字段的值。数据同步成功后,返回如下结果。
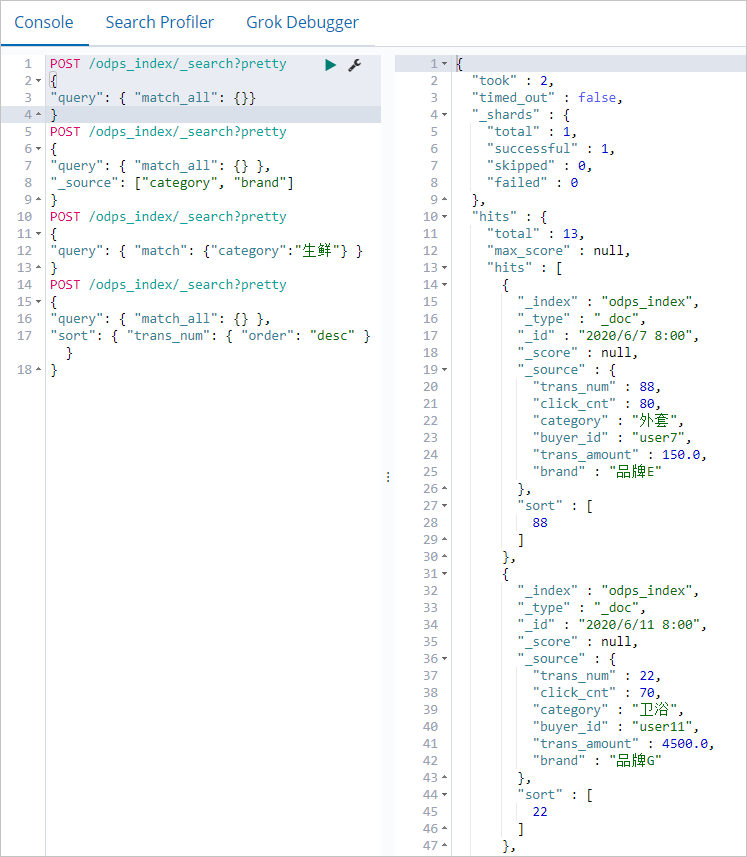
-
执行如下命令,搜索文档中的
category和brand字段。POST /odps_index/_search?pretty { "query": { "match_all": {} }, "_source": ["category", "brand"] } -
执行如下命令,搜索
category为生鲜的文档。POST /odps_index/_search?pretty { "query": { "match": {"category":"生鲜"} } } -
执行如下命令,按照
trans_num字段对文档进行排序。POST /odps_index/_search?pretty { "query": { "match_all": {} }, "sort": { "trans_num": { "order": "desc" } } }更多命令和访问方式,请参见Elastic.co官方帮助中心。