
LLM的普及推动了对AI训练与推理的精细化性能检测与调优需求,众多在GPU节点上运行的业务,期望对GPU容器进行在线性能分析。在Kubernetes容器场景中,AI Profiling作为基于eBPF和动态进程注入的无侵入式性能分析工具,支持对运行GPU任务的容器进程进行在线检测,涵盖Python进程、CPU调用、系统调用、CUDA库和CUDA核函数五个方面的数据采集能力。通过对采集数据进行分析,可以更好地定位容器应用运行的性能瓶颈并掌握对资源的利用程度,进而对应用进行优化。而对线上业务来说,可动态挂卸载的Profiling工具可以实时地对在线业务进行较为细致的分析,且无需对业务代码进行修改。本文将为您介绍如何通过命令行使用AI Profiling。
准备工作
当前版本的AI Profiling中Python Profiling能力依赖于Python解释器的USDT功能。若要启用Python Profiling,请在业务容器中使用以下命令确认业务Pod是否已开启USDT。
python -c "import sysconfig; print(sysconfig.get_config_var('WITH_DTRACE'))"如果输出为1,则表示可以启用Python Profiling,若为0,则无法开启。
说明Profiling任务目前仅支持在ACK集群中ECS及灵骏节点上运行。
如果希望使用本功能,请提交工单联系容器服务团队获取最新版本的kubectl-plugin下载链接及最新版本的Profiling镜像地址。
操作步骤
步骤一:部署kubectl插件
AI Profiling的部署采用kubectl-plugin的方式,具体步骤如下:
执行以下命令安装该插件,本文以Linux_amd64为例。
wget https://xxxxxxxxxxxxxxxxx.aliyuncs.com/kubectl_prof_linux_amd64 mv kubectl_prof_linux_amd64 /usr/local/bin/kubectl-prof chmod +x /usr/local/bin/kubectl-prof执行以下命令,查看插件是否安装成功。
kubectl prof deploy -h预期输出:
其中参数
--region-id为非必填。如需使用SysOM分析,需设置该参数为您执行Profiling所在环境的Region-id:deploy the profiling tool pod Usage: kubectl-profile deploy [flags] Aliases: deploy, run Flags: --container string Specify the target container name -d, --duration uint Specify the profiling duration in seconds (default 60) -h, --help help for deploy --image string Specify the profiling tool image --kubeconfig string Specify the kubeconfig file --memory-limit string Specify the memory limit (default "1Gi") --memory-request string Specify the memory request (default "128Mi") --namespace string Specify the target pod namespace (default "default") --node string Specify the node name --pod string Specify the target pod name --region-id string Specify the region-id --ttl uint Specify the ttl (default 60)
步骤二:选取目标业务容器并创建Profiling任务
选定业务Pod,获取其Namespace、Name和Node参数,本文以一个Pytorch训练任务为例。
NAME READY STATUS RESTARTS AGE IP NODE pytorch-train-worker-sample 1/1 Running 0 82s 172.23.224.197 cn-beijing.10.0.17.XXX使用获取的参数执行以下命令提交Profiling Job。指定需要进行Profiling的业务Pod和容器,Profiling Job将在业务Pod的目标容器所在节点创建Profiling Pod。
kubectl prof deploy \ --image xxxxxxxxxx \ # 请替换为阿里云提供的Profiling镜像地址 --duration 100000 \ # Profiling Pod环境持续的时间 --namespace default \ # 业务Pod的Namespace --region-id cn-beijing \ # 环境所在的阿里云Region ID --pod pytorch-train-worker-sample \ # 业务Pod的Name --container pytorch \ # 业务Pod的Container Name --memory-limit 10G \ # Profiling Pod的内存限制 --memory-request 1G # Profiling Pod的内存申请
步骤三:触发开启Profiling
执行如下命令,查看Profiling Pod相关信息。
kubectl get pod预期输出:
NAME READY STATUS RESTARTS AGE ai-profiler-89bf5b305acf2ec-xxxxx 2/2 Running 0 1m执行如下命令,进入Profiling Pod。
kubectl exec -ti ai-profiler-89bf5b305acf2ec-xxxxx -c debugger -- bash执行以下命令,列出所有的GPU进程,并生成Profiling命令模板。
llmtracker generateCommand预期输出:
I0314 11:42:42.389890 2948136 generate.go:51] GPU PIDs in container: I0314 11:42:42.389997 2948136 generate.go:53] PID: xxxxx, Name: {"pid":xxxxx} I0314 11:42:42.390008 2948136 generate.go:69] The profiling command is: llmtracker profile\ -p <ProcessID-To-Profiling>\ -t <Profiling-Type(python,cuda,syscall,cpu or all)>\ -o /tmp/data.json\ -v 5\ --cpu-buffer-size <CPU-Buffer-Size, recommand to 20>\ --probe-file <Enable-CUDA-Lib-Profile-File>\ -d <Duration-To-Profiling>\ --delay <Delay-Time>\ --enable-cuda-kernel <Enable-CUDA-Kenrel-Profile(true or none)> I0314 14:37:12.436071 3083714 generate.go:86] Profiling Python Path is: /usr/bin/python3.10. If you want to profiling Python, please ser the environment variable: export EBPF_USDT_PYTHON_PATH=/usr/bin/python3.10说明若您需要开启Python层面的Profiling,需要在执行Profiling环境中先设置输出中的环境变量。
参数及说明如下所示:
参数
说明
-p指定需要进行Profiling的PID。可多次使用以支持多个PID。
-t指定Profiling类型,可选项为python、cuda、syscall、cpu。如需全部开启,请填
all。-o指定Profiling结果的输出文件路径和名称,默认为
/tmp/data.json。-v指定日志输出的等级。
--cpu-buffer-size指定eBPF数据采集的CPU缓冲区大小,默认值为20。
--probe-file指定CUDA Lib Profiling所需的模板文件,请参见编写规范,也可直接使用默认模板。
-d设置Profiling任务的持续时间,单位为秒。由于长时间开启Profiling会抓取大量数据, 导致内存和磁盘压力增大,不建议超过60s。
--delay设置Profiling启动的延迟时间,单位为秒,若您开启CUDA Kernel部分的Profiling,该参数建议设置为2以上。
--enable-cuda-kernel指定是否开启CUDA Kernel部分的Profiling,设置为true为开启。
其中,
-t cuda与--enable-cuda-kernel的区别如下:-t cuda使用eBPF采集CUDA库Symbol的调用,包括每个API函数的调用时间和调用参数,进而具体分析过程中实际的调用情况。--enable-cuda-kernel:通过进程注入技术来采集CUDA Kernel函数的具体执行信息,从而详细的查看GPU端的任务流转状态。
更多全量参数,可执行
llmtracker profile -h命令查看。使用如下示例内容执行Profiling,根据需求修改生成的Profiling命令。
说明本示例为开启了全部Profiling项(包含CUDA Kernel Profiling),CUDA Lib配置为
probe.json,输出文件路径为/tmp/data.json,且添加--delay 3 -d 5表明延迟3s开始并持续5s的Profiling。export EBPF_USDT_PYTHON_PATH=/usr/bin/python3.10 llmtracker profile -p xxxxx -t all -o /tmp/data.json -v 5 --enable-cuda-kernel true --cpu-buffer-size 20 --probe-file probe.json --delay 3 -d 5执行如下命令,格式化结果文件并导出。
说明本步骤将结果文件转换为规范格式,以便于在TimeLine中展示和在SysOM中分析。
如果结果文件包含CUDA Kernel的Profiling数据,则需要添加参数
--cupti-dir,并将其固定为路径/tmp。若需使用SysOM的分析和展示功能,结果文件必须输出到目录
/output。
llmtracker export -i /tmp/data.json -o /output/out.json --cupti-dir /tmp
步骤四:Profiling结果展示
使用SysOM展示分析(推荐)
阿里云提供基于SysOM的自动化存储、可视化展示与分析能力。
执行以下命令触发SysOM的分析。在命令中填写阿里云账号的AccessKey ID和AccessKey Secret,同时确保该账号具备访问SysOM资源的权限。--endpoint参数是SysOM OpenAPI的访问端点,详情请参见SysOM API文档。
llmtracker analysis -a xxx -s xxx --endpoint sysom.cn-hangzhou.aliyuncs.com -p xxxxx -o out.json预期输出:
I0314 11:45:11.505791 2950230 analysis.go:46] Start to upload profiling result file
I0314 11:45:11.934619 2950230 analysis.go:51] Stdout: thread ongpu started.
I0314 11:45:11.934637 2950230 analysis.go:68] 95e84fed-f2a6-4a35-87ca-8521087d010c
I0314 11:45:11.934643 2950230 analysis.go:69] Analysis result link: https://alinux.console.aliyun.com/system-observation/ai-infra-observation/result/?analysisId=xxx命令最后返回SysOM的分析展示链接,直接访问即可查看分析结果。
使用Tensorboard展示分析
若您使用OSS、NAS等存储,您可以参见查看TensorBoard查看结果数据的方式,在集群中启动一个挂载了包含Profiling结果数据的PVC的TensorBoard Pod,打开TensorBoard查看相关数据。
使用Chrome Tracing展示分析
若您使用本地存储,需要将生成的profiling结果文件拷贝到本地,然后通过Chrome Tracing(Perfetto)打开文件进行查看。
效果展示
SysOM展示
如果使用SysOM分析能力,可以看到包括GPU CUDA核函数的细节分析、数据总览、详细的TimeLine展示。更多详情,请参见通过控制台使用AI Profiling。
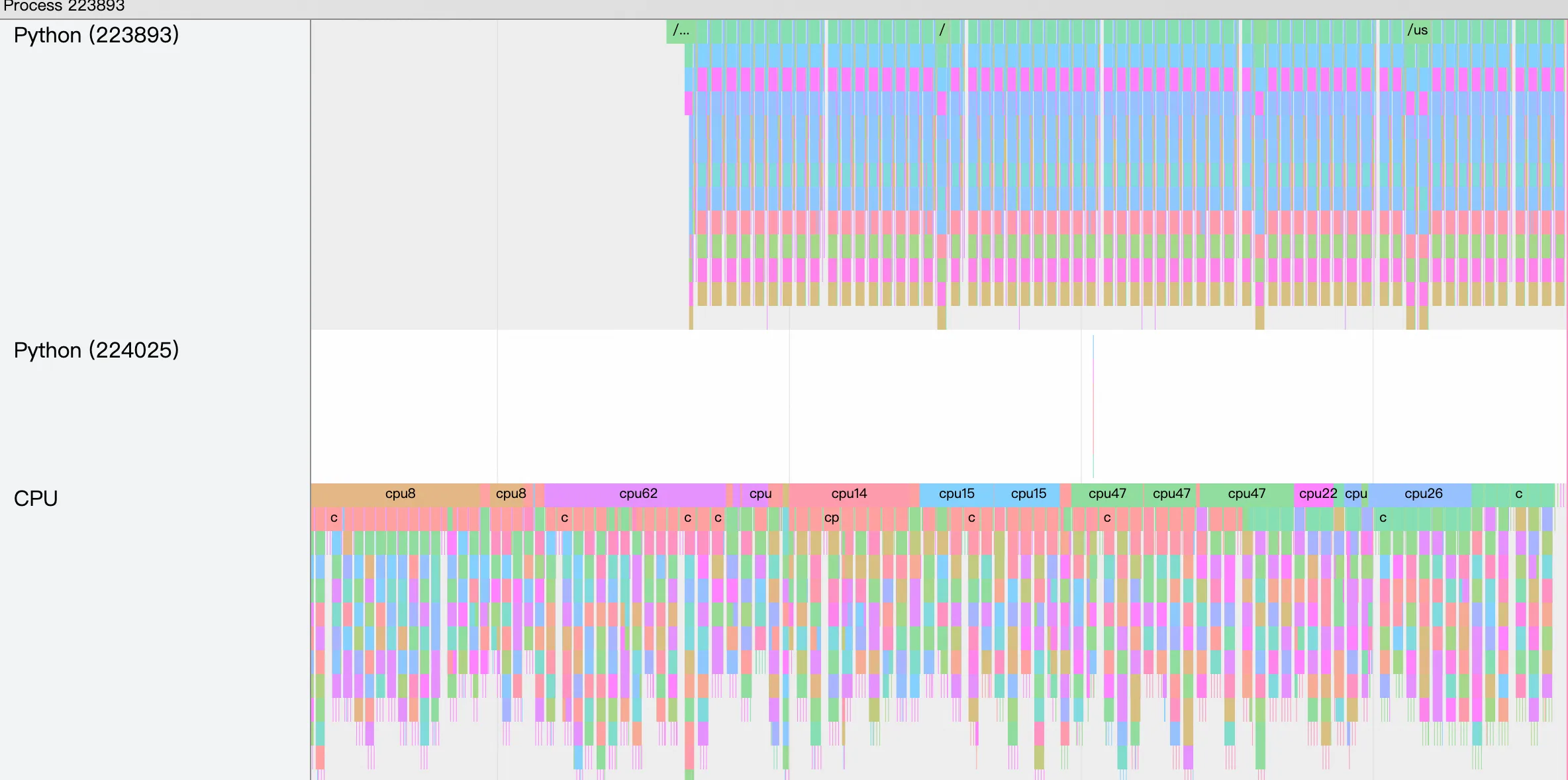
Tensorboard展示
使用TensorBoard展示的TimeLine效果如下:
Chrome Tracing展示
本地使用Chrome Tracing展示的TimeLine效果如下:
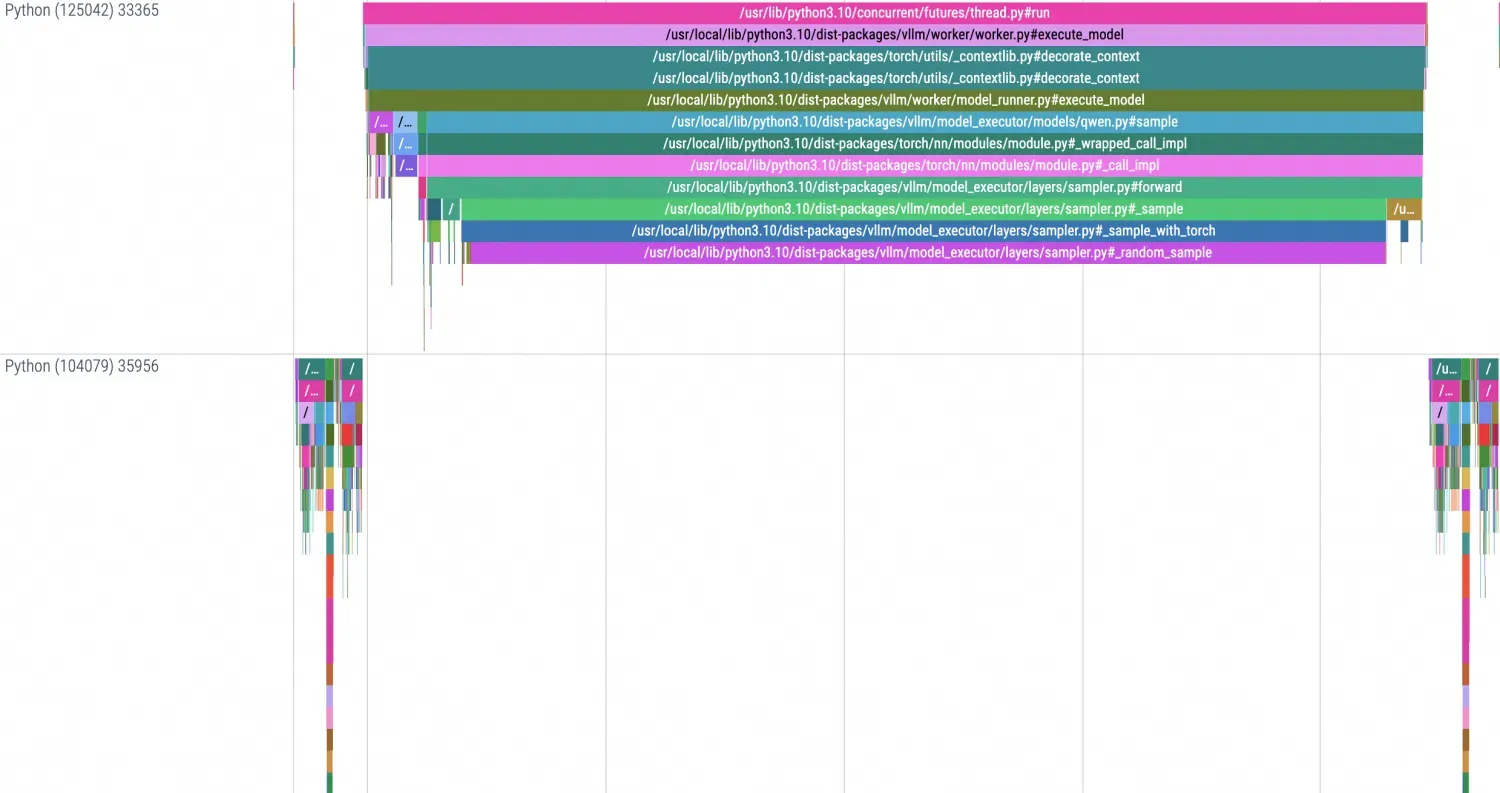
AI Profiling附录
CUDA Lib配置文件
获取目标库的递归依赖并进一步筛选库文件。在筛选出或确认自己期望追踪的库文件后,可以通过
ldd命令来获取目标抓取库文件的链接依赖,从而确定可以抓取有效数据的库文件范围。
确定了目标库文件后,需要确认该库中的模板符号。本步骤以libnccl.so为例,执行如下命令,获取该库中所有的符号信息。
readelf -Ws libnccl.so.2 | grep pnccl预期输出:
... 223: 00000000000557d0 650 FUNC GLOBAL DEFAULT 11 pncclGroupStart 224: 0000000000050200 243 FUNC GLOBAL DEFAULT 11 pncclRedOpDestroy 225: 0000000000062081 656 FUNC GLOBAL DEFAULT 11 pncclCommAbort 227: 000000000006320c 721 FUNC GLOBAL DEFAULT 11 pncclCommUserRank 228: 0000000000064ee0 20 FUNC GLOBAL DEFAULT 11 pncclGetVersion 231: 0000000000045f60 1778 FUNC GLOBAL DEFAULT 11 pncclAllGather 232: 00000000000604f8 1578 FUNC GLOBAL DEFAULT 11 pncclCommInitAll 233: 000000000004ff20 728 FUNC GLOBAL DEFAULT 11 pncclRedOpCreatePreMulSum 238: 0000000000074520 653 FUNC GLOBAL DEFAULT 11 pncclCommDeregister 240: 00000000000474b0 30 FUNC GLOBAL DEFAULT 11 pncclBcast 243: 000000000006173d 789 FUNC GLOBAL DEFAULT 11 pncclCommFinalize 244: 00000000000483d0 2019 FUNC GLOBAL DEFAULT 11 pncclSend ...组装Profiling所需的JSON配置文件,需要构建一个类似于以下格式的JSON文件。该配置文件应定义Probe所需要的信息,包括UProbe中目标库文件在容器中的相对路径、库文件中期望监控方法的Symbol、KProbe中期望监控系统方法的Symbol,默认参考模板如下。