
kube-scheduler组件是Kubernetes集群的默认调度器,负责将Pod调度到合适的集群节点上运行。本文介绍kube-scheduler组件的监控指标清单、大盘使用指导以及常见指标异常解析。
使用前须知
操作入口
请参见查看集群控制面组件监控大盘。
指标清单
指标是组件对外透出状态和参数的方式之一,kube-scheduler组件使用的指标清单如下。
指标清单 | 类型 | 说明 |
scheduler_scheduler_cache_size | Gauge | 调度器缓存中节点、Pod和AssumedPod(假定要调度的Pod)的数量。 |
scheduler_pending_pods | Gauge | Pending Pod的数量。队列种类如下:
|
scheduler_pod_scheduling_attempts_bucket | Histogram | 调度器尝试成功调度Pod的次数,Bucket阈值为 |
memory_utilization_byte | Gauge | 内存使用量。单位:字节(Byte)。 |
cpu_utilization_core | Gauge | CPU使用量。单位:核(Core)。 |
resource_utilization_level | Gauge | 资源使用水位。
|
rest_client_requests_total | Counter | 从状态值(Status Code)、方法(Method)和主机(Host)维度分析HTTP请求数。 |
rest_client_request_duration_seconds_bucket | Histogram | 从方法(Verb)和URL维度分析HTTP请求时延。 |
大盘使用指导
大盘基于组件指标和相关PromQL绘制,大盘可观测性展示和功能解析如下。
概览
可观测性展示
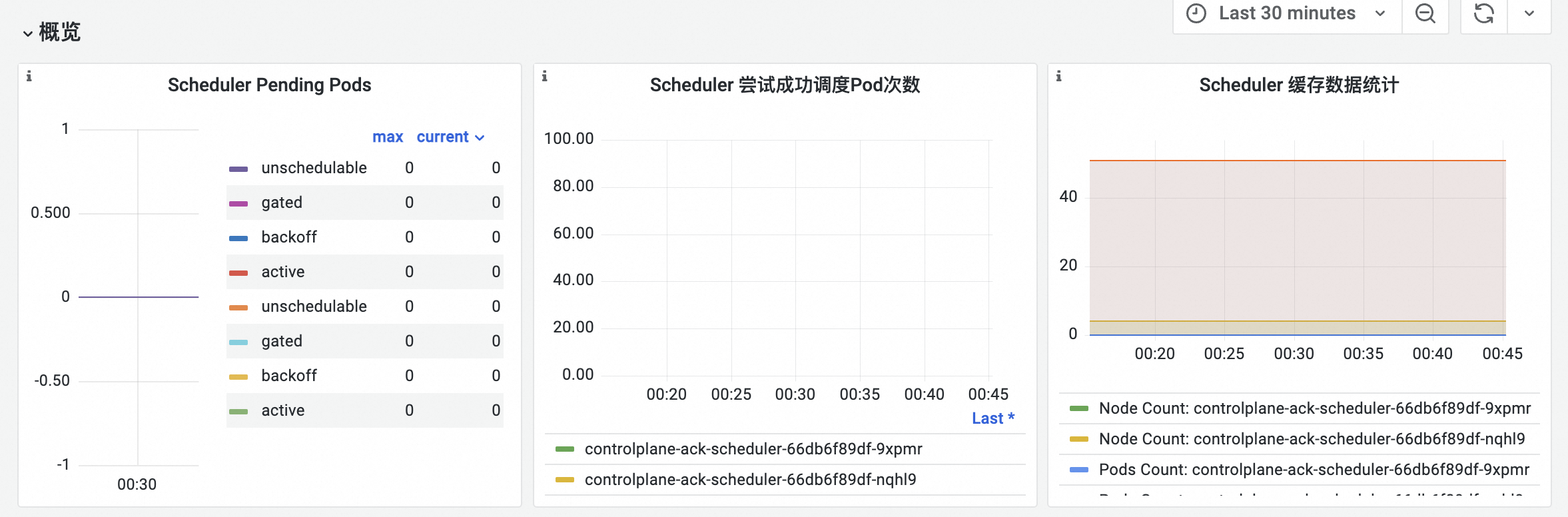
功能解析
指标清单 | PromQL | 说明 |
Scheduler Pending Pods | scheduler_pending_pods{job="ack-scheduler"} | Pending Pod的数量。队列种类如下:
|
Scheduler 尝试成功调度Pod次数 | histogram_quantile($quantile, sum(rate(scheduler_pod_scheduling_attempts_bucket{job="ack-scheduler"}[$interval])) by (pod, le)) | 调度器尝试调度Pod的次数。Bucket阈值为 |
Scheduler 缓存数据统计 |
| 调度器缓存中Node、Pod和AssumedPod的数量。 |
资源
可观测性展示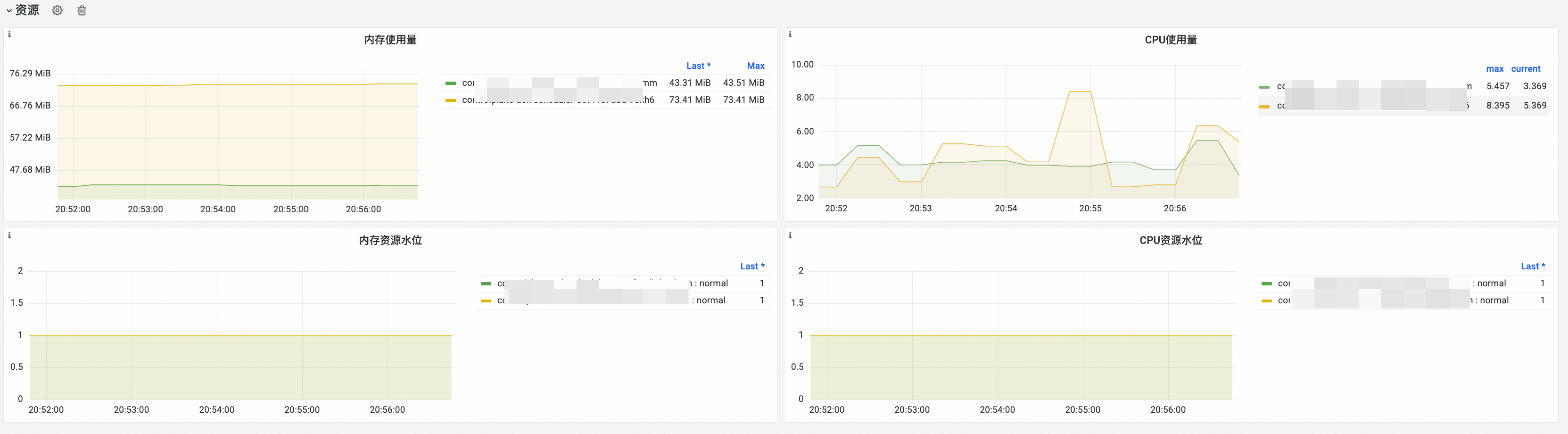
功能解析
指标清单 | PromQL | 说明 |
内存使用量 | memory_utilization_byte{container="kube-scheduler"} | 内存使用量。单位:字节。 |
CPU使用量 | cpu_utilization_core{container="kube-scheduler"}*1000 | CPU使用量。单位:毫核。 |
内存资源水位 |
|
|
CPU资源水位 |
|
Kube API
可观测性展示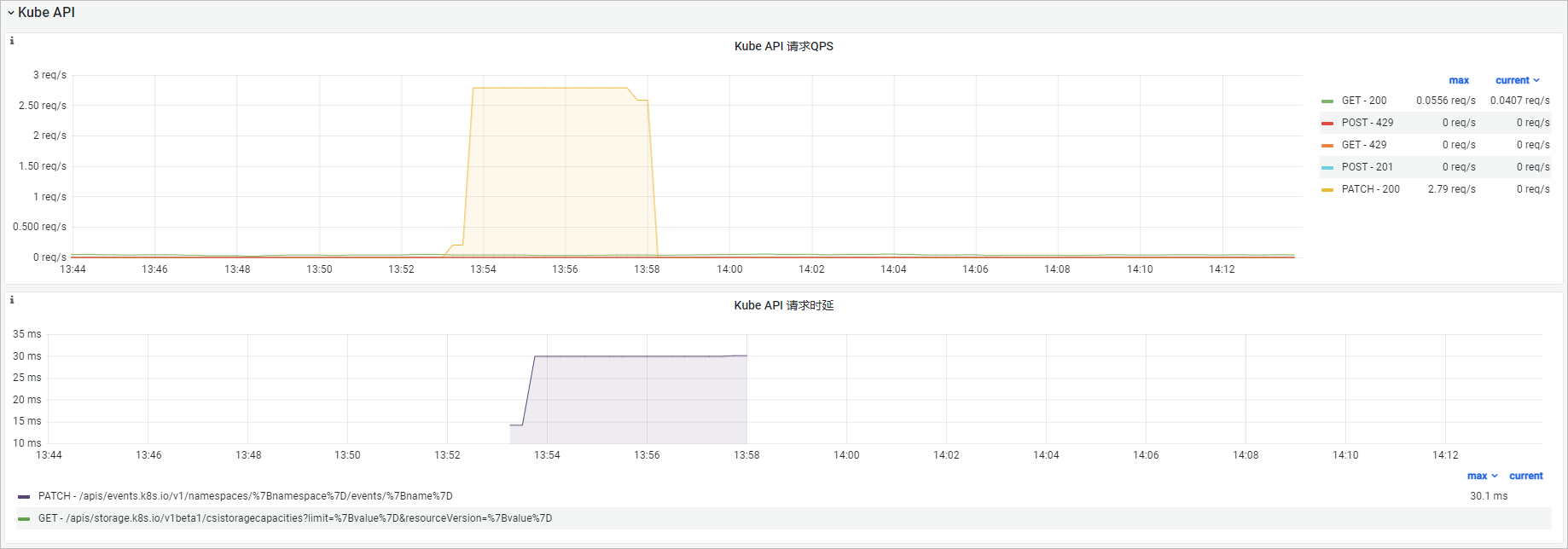
功能解析
指标清单 | PromQL | 说明 |
Kube API 请求QPS |
| kube-scheduler对kube-apiserver组件发起的HTTP请求,从方法(Method)和返回值(Code) 维度分析。 |
Kube API 请求时延 | histogram_quantile($quantile, sum(rate(rest_client_request_duration_seconds_bucket{job="ack-scheduler"}[$interval])) by (verb,url,le)) | kube-scheduler对kube-apiserver组件发起的HTTP请求时延,从方法(Verb)和请求URL维度分析。 |
常见指标异常
如果组件的常见指标异常,请对照下文的情况说明排查是否为预期内情况。
存活调度器Pod数量
正常情况 | 异常情况 | 异常说明 | 建议 |
存活调度器Pod数量大于等于1。 | 存活调度器数量为0。 | 当前集群无可用调度器。 |
|
Pending Pod数量
正常情况 | 异常情况 | 异常说明 | 建议 |
Pod调度速度较稳定,且维持在较低数值。 |
| 当前集群中Pod的资源请求不合理,或节点资源配置不足。 |
|
成功调度一个Pod的尝试次数
正常情况 | 异常情况 | 异常说明 | 建议 |
Pod能够在几次尝试后正常被调度到节点上。 | Pod在多次尝试后依然无法成功调度。 | 当前集群中Pod的资源请求不合理,或节点资源配置不足。 |
|
相关文档
关于其他集群控制面组件监控的指标详情、大盘使用指引和常见指标异常说明,请参见kube-apiserver组件监控指标说明、etcd组件监控指标说明、kube-controller-manager组件监控指标说明、cloud-controller-manager组件监控指标说明。