
数据导入性能优化
云原生数据仓库 AnalyticDB MySQL 版提供的多种数据导入方法,满足不同场景下的数据导入需求。然而数据导入性能依然受各种各样的因素影响,如表的建模不合理导致长尾、导入配置低无法有效利用资源等。本文介绍不同场景下的数据导入调优方法。
通用外表导入数据调优
检查分布键
分布键决定着数据导入的一级分区,每个表在导入时以一级分区为粒度并发导入。当数据分布不均匀时,导入数据较多的一级分区将成为长尾节点,影响整个导入任务的性能,因此要求导入时数据均匀分布。如何选择分布键,请参见选择分布键。
判断分布键合理性:
导入前,根据导入数据所选分布键的业务意义判断是否合理。以表Lineitem为例,当选择l_discount列为分布键,订单折扣值区分度很低,仅有11个不同值,l_discount值相同的数据会分布到同一分区,造成严重倾斜,导入会有长尾,影响性能。选择l_orderkey列则更为合适,订单ID互不相同,数据分布相对较为均匀。
导入后,数据建模诊断中如有分布字段倾斜,则说明选择的分布键不均匀。如何查看分布键诊断信息,请参见存储空间诊断。
检查分区键
INSERT OVERWRITE SELECT导入数据的基本特性为分区覆盖,即导入的二级分区会覆盖原表的同名二级分区。每个一级分区内的数据会再按二级分区定义导入各个二级分区。导入时需要避免一次性导入过多二级分区,多个二级分区同时导入可能引入外排序过程,影响导入性能。如何选择分区键,请参见选择分区键。
判断分区键合理性:
导入前,根据业务数据需求及数据分布判断分区键是否合理。如Lineitem表按l_shipdate列做二级分区,数据范围横跨7年,按年做分区有7个分区,按日做分区有2000多个分区,单分区约3000万条记录,选择按月或者按年做分区则更合适。
导入后,数据建模诊断中如有不合理的二级分区,则选择的分区键不合适。如何查看分区键诊断信息,请参见分区表诊断。
检查索引
AnalyticDB for MySQL建表时默认全列索引,而构建宽表的全列索引会消耗部分资源。导入数据到宽表时,建议使用主键索引。主键索引用于去重,主键列数过多影响去重性能。如何选择主键索引,请参见选择主键。
判断索引合理性:
离线导入场景通常已经通过离线计算进行去重,无需指定主键索引。
在页签,查看表数据量、索引数据量和主键索引数据量。当索引数据量超过表数据量时,需要检查表中是否有较长的字符串列,这种索引列不仅构建耗时,还占用存储空间,可以删除索引,请参见ALTER TABLE。
说明主键索引无法删除。需要重建表。
增加Hint加速导入
在导入任务前增加Hint(direct_batch_load=true)可以加速导入任务。
该Hint仅数仓版弹性模式集群3.1.5版本支持,若使用后导入性能无明显提升,请提交工单。
示例如下:
SUBMIT JOB /*+ direct_batch_load=true*/INSERT OVERWRITE adb_table
SELECT * FROM adb_external_table;使用弹性导入功能加速导入
仅内核版本3.1.10.0及以上的集群支持使用弹性导入功能。
已创建Job型资源组的企业版、基础版及湖仓版集群支持使用弹性导入功能。
弹性导入仅支持导入MaxCompute数据和以CSV、Parquet、ORC格式存储的OSS数据。
使用弹性导入功能加速导入时,需确保Job型资源组中可用资源充足,避免资源不足导致任务长时间等待、耗时长、任务失败等问题。
弹性导入支持同时运行多个弹性导入任务,也支持通过增大单个弹性导入任务使用的资源加速导入。更多信息,请参见数据导入方式介绍。
示例如下:
/*+ elastic_load=true, elastic_load_configs=[adb.load.resource.group.name=resource_group]*/
submit job insert overwrite adb_table select * from adb_external_table;参数说明,请参见Hint参数说明。
通过DataWorks导入数据调优
优化任务配置
优化批量插入条数
表示单次导入的批大小,默认为2048,一般不建议修改。
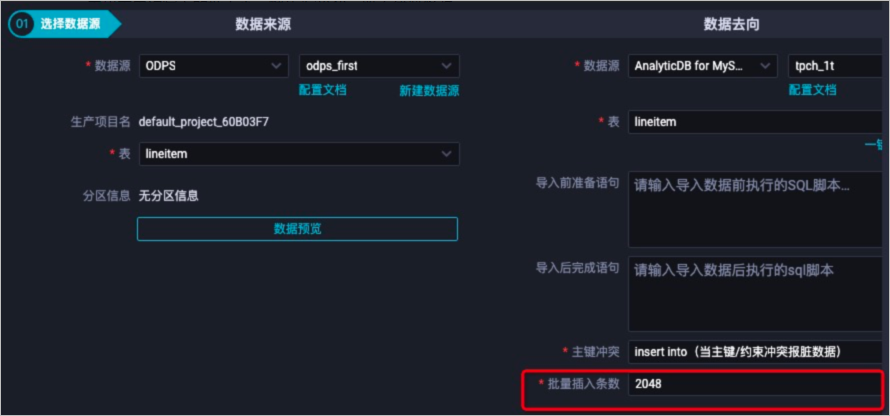
如果单条数据量过大达到数百KB,如高达512 KB,则建议修改此配置为16,保证单次导入量不超过8 MB,防止占用过多前端节点内存。
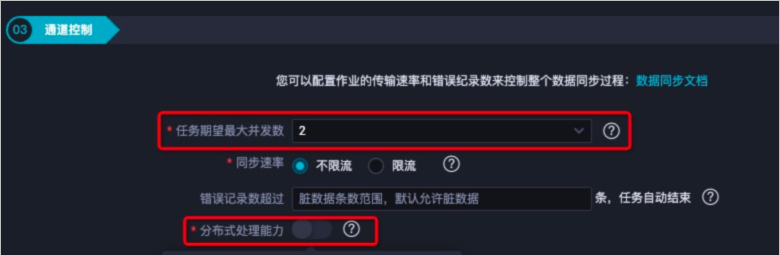
优化通道控制
数据同步性能与任务期望最大并发数配置项大小成正比,建议尽可能增加任务期望最大并发数。
重要任务期望最大并发数越高,占用DataWorks资源会越多,请合理选择。
建议打开分布式处理能力,以取得更好的同步性能。
常见问题及解决方法
当客户端导入压力不足时,会导致集群CPU使用率、磁盘IO使用率及写入响应时间处于较低水位。数据库服务器端虽然能够及时消费客户端发送的数据,但由于总发送量较小,导致写入TPS不满足预期。
解决方法:调大单次导入的批量插入条数及增加任务期望最大并发数,数据导入性能会随着导入压力的增加而线性增加。
当导入的目标表存在数据倾斜时,集群部分节点负载过高,影响导入性能。此时,集群CPU使用率、磁盘IO使用率处于较低水位,但写入响应时间较高,同时您可以在页面的倾斜诊断表中发现目标表。
解决方法:重新设计表结构后再导入数据,详情请参见表结构设计。
通过JDBC使用程序导入数据调优
客户端优化
应用端攒批,多条批量导入
在通过JDBC使用程序导入数据过程中,为减少网络和链路上的开销,建议攒批导入。无特殊要求,请避免单条导入。
批量导入条数建议为2048条。如果单条数据量过大达到数百KB,建议攒批数据大小不超过8 MB,可通过8 MB/单条数据量得到攒批条数。否则单批过大容易占用过多前端节点内存,影响导入性能。
应用端并发配置
应用端导入数据时,建议多个并发同时导入数据。单进程无法完全利用系统资源,且一般客户端需要处理数据、攒批等操作,难以跟上数据库的导入速度,通过多并发导入可以加快导入速度。
导入并发受攒批、数据源、客户端机器负载等影响,没有最合适的数值,建议通过测试逐步计算合适的并发能力。如导入不达预期,请翻倍加大并发,导入速度下降再逐步降低并发,寻找最合适的并发数。
常见问题及解决方法
当通过程序导入数据到AnalyticDB for MySQL性能不佳时,首先排查客户端性能是否存在瓶颈。
保证数据源的数据生产速度足够大,如果数据源来自其他系统或文件,排查客户端是否有输出瓶颈。
保证数据处理速度,排查数据生产消费是否同步,保证有足够的数据等待导入AnalyticDB for MySQL。
保证客户端机器负载,检查CPU使用率或磁盘IO使用率等系统资源是否充足。