
本文介绍如何将Teradata数据和应用迁移到云原生数据仓库AnalyticDB PostgreSQL版。
迁移原则
云原生数据仓库AnalyticDB PostgreSQL版对Teradata语法有着很好的兼容。本指南在将TD数仓应用迁移至AnalyticDB PostgreSQL云化数仓过程中,秉承充分复用旧系统架构、ETL算法、数据结构和工具的原则,需对原加工脚本进行转换,另外,需对历史数据进行迁移,并保证数据的准确性,完整性。
- 对数据仓库基础数据平台的完整迁移。
- 对数据仓库系统上已部署应用的平滑迁移。
- 业务外观透明迁移,保持新旧系统业务操作一致性。
- 充分保证数据仓库迁移后的性能。
- 可接受的系统迁移周期及良好的迁移可操作性。
- 充分复用旧系统架构、ETL算法、数据结构和工具。
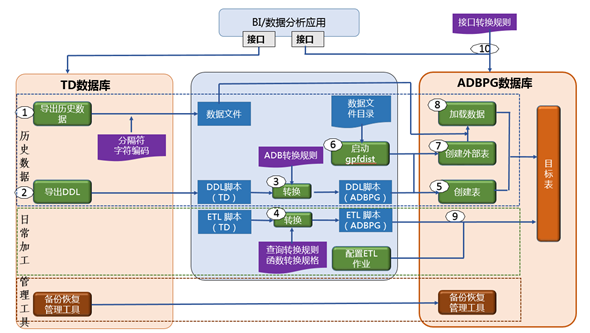
- 历史数据迁移,首先从TD数据库按规定分隔符及字符编码将历史数据导成文本文件,存放于AnalyticDB PostgreSQL数据库网络相通的ECS服务器本地磁盘或云存储OSS上,确保AnalyticDB PostgreSQL数据库通过gpfdist协议的外部表后AnalyticDB PostgreSQL的OSS外部表能读取数据文件。之后从TD导出DDL脚本,按AnalyticDB PostgreSQL语法批量修改脚本,确保在AnalyticDB PostgreSQL能成功创建所有用户表。
- 日常加工流程迁移:对ETL查询加工语句按AnalyticDB PostgreSQL的DML语法进行转换(AnalyticDB PostgreSQL构建了相关基于脚本的自动化转化工具,可以对语法进行自动mapping转换),并根据TD与AnalyticDB PostgreSQL函数对照表替换相关函数,转换ETL连接数据库方式。重新配置加工作业,历史数据迁移成功后,启动日常ETL作业。
- 应用接口迁移:AnalyticDB PostgreSQL数据库支持ODBC/JDBC,BI前端展现等工具可通过ODBC或JDBC标准访问DW,改动网络连接IP等即可。
- 管理工具迁移:部署AnalyticDB PostgreSQL备份及恢复工具,定期备份数据及定期进行恢复演练。
云原生数据仓库PostgreSQL版和Teradata的核心数据类型是互相兼容的,仅部分数据类型需要进行修改,通过AnalyticDB PostgreSQL的自动化转化工具,可以批量进行TD建表DDL语句的转换。详情请参见下表:
| Teradata | AnalyticDB PostgreSQL |
|---|---|
| char | char |
| varchar | varchar |
| long varchar | varchar(64000) |
| varbyte(size) | bytea |
| byteint | 无,可用bytea替代 |
| smallint | smallint |
| integer | integer |
| decimal(size,dec) | decimal(size,dec) |
| numeric(precision,dec) | numeric(precision,dec) |
| float | float |
| real | real |
| double precision | double precision |
| date | date |
| time | time |
| timestamp | timestamp |
建表语句
我们通过一个建表语句的例子来比较云原生数据仓库PostgreSQL版和Teradata。
Teradata建表SQL语句如下:
CREATE MULTISET TABLE test_table,NO FALLBACK ,
NO BEFORE JOURNAL,
NO AFTER JOURNAL,
CHECKSUM = DEFAULT,
DEFAULT MERGEBLOCKRATIO
(
first_column DATE FORMAT 'YYYYMMDD' TITLE '第一列' NOT NULL,
second_column INTEGER TITLE '第二列' NOT NULL ,
third_column CHAR(6) CHARACTER SET LATIN CASESPECIFIC TITLE '第三列' NOT NULL ,
fourth_column CHAR(20) CHARACTER SET LATIN CASESPECIFIC TITLE '第四列' NOT NULL,
fifth_column CHAR(1) CHARACTER SET LATIN CASESPECIFIC TITLE '第五列' NOT NULL,
sixth_column CHAR(24) CHARACTER SET LATIN CASESPECIFIC TITLE '第六列' NOT NULL,
seventh_column VARCHAR(18) CHARACTER SET LATIN CASESPECIFIC TITLE '第七列' NOT NULL,
eighth_column DECIMAL(18,0) TITLE '第八列' NOT NULL ,
nineth_column DECIMAL(18,6) TITLE '第九列' NOT NULL )
PRIMARY INDEX ( first_column ,fourth_column )
PARTITION BY RANGE_N(first_column BETWEEN DATE '1999-01-01' AND DATE '2050-12-31' EACH INTERVAL '1' DAY );
CREATE INDEX test_index (first_column, fourth_column) ON test_table;云原生数据仓库PostgreSQL版的建表语句如下:
CREATE TABLE test_table
(
first_column DATE NOT NULL,
second_column INTEGER NOT NULL ,
third_column CHAR(6) NOT NULL ,
fourth_column CHAR(20) NOT NULL,
fifth_column CHAR(1) NOT NULL,
sixth_column CHAR(24) NOT NULL,
seventh_column VARCHAR(18) NOT NULL,
eighth_column DECIMAL(18,0) NOT NULL ,
nineth_column DECIMAL(18,6) NOT NULL )
DISTRIBUTED BY ( first_column ,fourth_column )
PARTITION BY RANGE(first_column)
(START (DATE '1999-01-01') INCLUSIVE
END (DATE '2050-12-31') INCLUSIVE
EVERY (INTERVAL '1 DAY' ) );
create index test_index on test_table(first_column, fourth_column);通过以上例子,我们可以清晰地发现云原生数据仓库PostgreSQL版和Teradata建表语句的异同:
- 核心数据类型互相兼容,数据类型无需修改。
- 均支持分布列,但语法不同,Teradata使用的是primary index,云原生数据仓库PostgreSQL版使用的是distributed by。
- 均支持PARTITION BY二级分区,语义相同但语法不同。
- 均支持对表创建索引,但语法不同。
- 云原生数据仓库PostgreSQL版不支持TITLE关键字,但是支持单独对列添加注释COMMENT,语法为
COMMENT ON COLUMN table_name.column_name IS 'XXX'; - 云原生数据仓库PostgreSQL版不支持在定义char/varchar时声明编码类型,可以在连接数据库时,通过执行
SET client_encoding = latin1;来声明编码类型。
导入导出数据格式
云原生数据仓库PostgreSQL版和Teradata均支持txt、csv格式的数据导入导出,与Teradata的区别在于数据文件的分隔符。
- Teradata支持双分隔符。
- 云原生数据仓库PostgreSQL版支持单分隔符。
SQL语句
云原生数据仓库PostgreSQL版和Teradata的大部分SQL语法都是兼容的,仅有部分Teradata语法需要进行修改。需要修改的语法如下所示:
- cast
Teradata支持如下的cast语法:
cast(XXX as int format '999999') cast(XXX as date format 'YYYYMMDD')而云原生数据仓库PostgreSQL版支持如下cast语法:
cast(XXX as int) cast(XXX as date)云原生数据仓库PostgreSQL版不支持在cast中声明format。
- 对于
cast(XXX as int format '999999'),需要编写函数来实现相同功能。 - 对于
cast(XXX as date format 'YYYYMMDD'),云原生数据仓库PostgreSQL版支持date的显示格式为'YYYY-MM-DD',不影响正常使用。
- 对于
- qualify
Teradata的qualify关键字,用与根据用户的条件,进一步过滤前序排序计算函数得到的结果。
例如,Teradata的qualify关键字如下所示:
SELECT itemid, sumprice, RANK() OVER (ORDER BY sumprice DESC) FROM (SELECT a1.item_id, SUM(a1.sale) FROM sales AS a1 GROUP BY a1.itemID) AS t1 (itemid, sumprice) QUALIFY RANK() OVER (ORDER BY sum_price DESC) <=100;而云原生数据仓库PostgreSQL版不支持qualify关键字,需要将带qualify的SQL语句,修改为嵌套子查询:
SELECT itemid, sumprice, rank from (SELECT itemid, sumprice, RANK() OVER (ORDER BY sumprice DESC) as rank FROM (SELECT a1.item_id, SUM(a1.sale) FROM sales AS a1 GROUP BY a1.itemID) AS t1 (itemid,sumprice) ) AS a where rank <=100; - macro
Teradata通过macro来执行一组SQL语句,如下所示:
CREATE MACRO Get_Emp_Salary(EmployeeNo INTEGER) AS ( SELECT EmployeeNo, NetPay FROM Salary WHERE EmployeeNo = :EmployeeNo; );云原生数据仓库PostgreSQL版不支持macro,但是可以使用function语句来完成Teradata的macro功能:
CREATE OR REPLACE FUNCTION Get_Emp_Salary( EmployeeNo INTEGER, OUT EmployeeNo INTEGER, OUT NetPay FLOAT ) returns setof record AS $$ SELECT EmployeeNo,NetPay FROM Salary WHERE EmployeeNo = $1 $$ LANGUAGE SQL;
函数转化
TD与AnalyticDB PostgreSQL函数转换对照表
| TD函数 | 函数 | 说明 |
|---|---|---|
| Zeroifnull | Coalesce | 对数据作累计处理时,将空值作零处理 |
| NULLIFZERO | Coalesce | 对数据作累计处理时,忽略零值 |
| Index | Position | 字符串定位函数 |
| Add_months | To_date | 从某日期增加或减少指定月份的日期 |
| format | To_char/to_date | 函数定义数据格式 |
| csum | 可通过子查询方式实现 | 计算一列的连续的累计的值 |
| MAVG | 可通过子查询方式实现 | 基于预定的行数(查询宽度)计算一列的移动平均值 |
| MSUM | 可通过子查询方式实现 | 基于预定的查询宽度计算一列的移动汇总值 |
| MDIFF | 可通过子查询方式实现 | 基于预定的查询宽度计算一列的移动差分值 |
| qualify | 可通过子查询方式实现 | QUALIFY子句限制排队输出的最终结果 |
| Char/characters | length | 字符个数 |