
将应用数据上报至可观测链路 OpenTelemetry 版后,可观测链路 OpenTelemetry 版即可开始监控应用,可观测链路 OpenTelemetry 版的调用链分析功能是基于已存储的全量链路明细数据,自由组合筛选条件与聚合维度进行实时分析,可以满足不同场景的自定义诊断需求。
前提条件
已将应用数据上报至可观测链路 OpenTelemetry 版,具体操作,请参见接入指南。
筛选调用链
在左侧导航栏单击调用链分析,然后在顶部菜单栏选择目标地域。
在调用链分析页面右上角的时间选择框设置需要查询的时间段。
筛选链路。
在左侧快捷筛选区域,通过状态、耗时、应用名称、接口名称和主机地址维度快速筛选链路。
筛选条件将会显示在页面顶部文本框内。
单击顶部文本框,在下拉弹窗中修改筛选条件或设置其他维度的筛选条件。

在顶部文本框直接输入查询条件。查询语法说明,请参见调用链分析查询用法说明。
说明单击文本框右侧的
 图标可以保存当前筛选条件。
图标可以保存当前筛选条件。单击文本框右侧的已保存视图可以查看已保存的筛选条件,单击目标的筛选条件可以快速查看对应筛选条件下的链路信息。
选择聚合维度,可以将筛选后的数据按照指定维度聚合。
链路列表
筛选设置完成后,调用链分析页面将会显示筛选过滤后的链路查询信息,包括调用次数和HTTP错误数的柱状图,调用耗时的时序曲线,以及调用链列表。
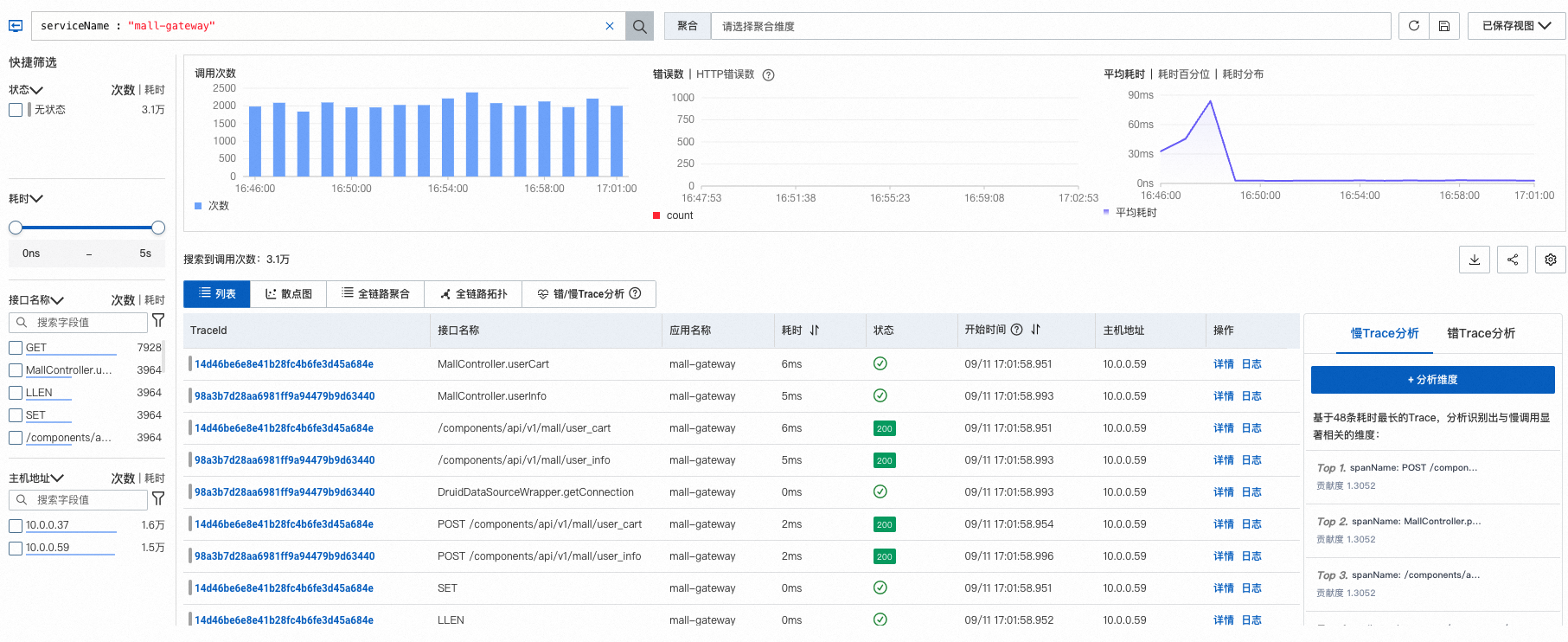
列表状态列各图标说明:
 :Span 状态正常。取自Span的
:Span 状态正常。取自Span的statusCode字段,当statusCode=0或者1时显示,0表示未设置状态码,1表示Span状态正常。 :Span 状态错误。取自Span的
:Span 状态错误。取自Span的statusCode字段,当statusCode=2时显示,表示Span状态错误。 :Span 包含异常。取自Span的
:Span 包含异常。取自Span的attributes.excep.ids字段,当该字段不为空时,表示Span包含异常。2XX(绿色)、3XX(黄色)、4XX(橙色)、5XX(红色):HTTP状态码。取自Span的
attributes.http.status_code或attributes.http.response.status_code字段,当Span包含这两个字段时,优先展示HTTP状态码,不展示正常或错误状态。
TraceId左侧颜色柱说明:
- :表示Span的statusCode=0。
- :表示Span的statusCode=1。
- :表示Span的statusCode=2。
 :表示Span的statusCode=0。
:表示Span的statusCode=0。 :表示Span的statusCode=1。
:表示Span的statusCode=1。 :表示Span的statusCode=2。
:表示Span的statusCode=2。在调用链列表区域,您可以执行以下操作:
 图标,可以将当前参数值添加为筛选条件。
图标,可以将当前参数值添加为筛选条件。
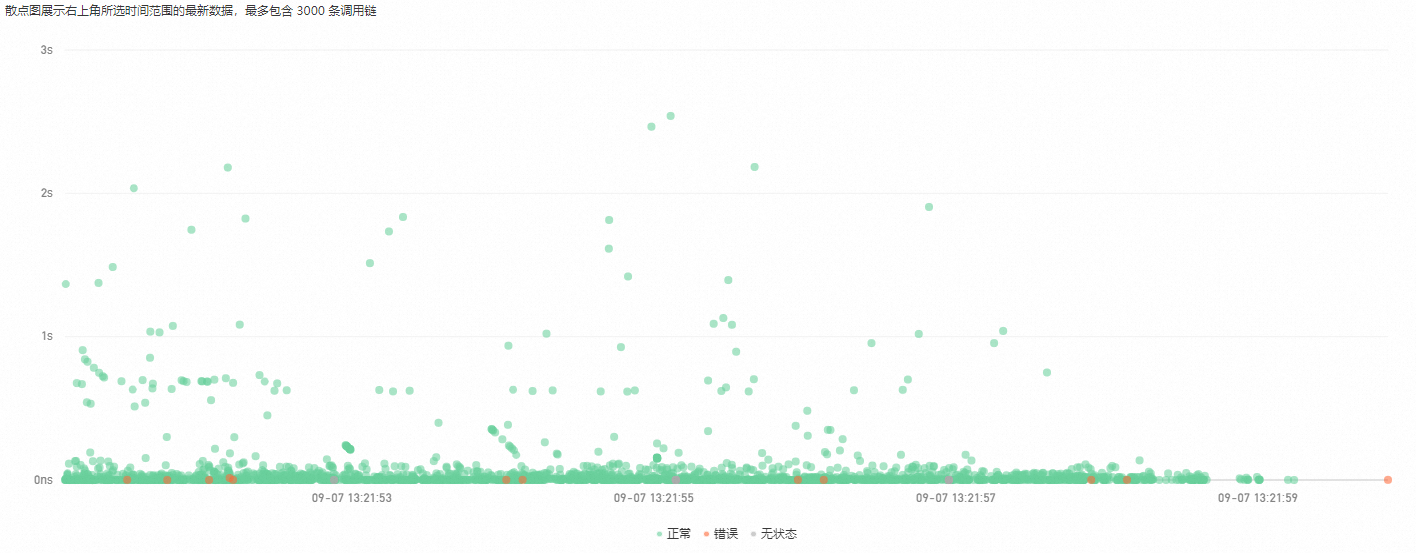
散点图
散点图页面以时间为横轴,耗时指标为纵轴,显示调用链的耗时分布情况。将鼠标悬浮于散点上,可以显示散点对应的调用链的基本信息。单击散点可以查看调用链对应的调用详情。更多信息,请参见Trace详情。
全链路聚合
调用链分析对查询到的Span可以按照各个维度进行分析,但这些分析是针对单个Span,并未在链路级别深度分析。而全链路聚合功能支持通过指定条件查询分布式调用链路的TraceId(最多5000个),然后基于这些TraceId查询对应的Span,并聚合这些Span得出最终结果,整个过程保证聚合的链路完整性。
由于全链路聚合是按照查询条件后聚合计算相应数据的,当您选择的条件比较多时,查询计算存在一定延迟,请耐心等待。
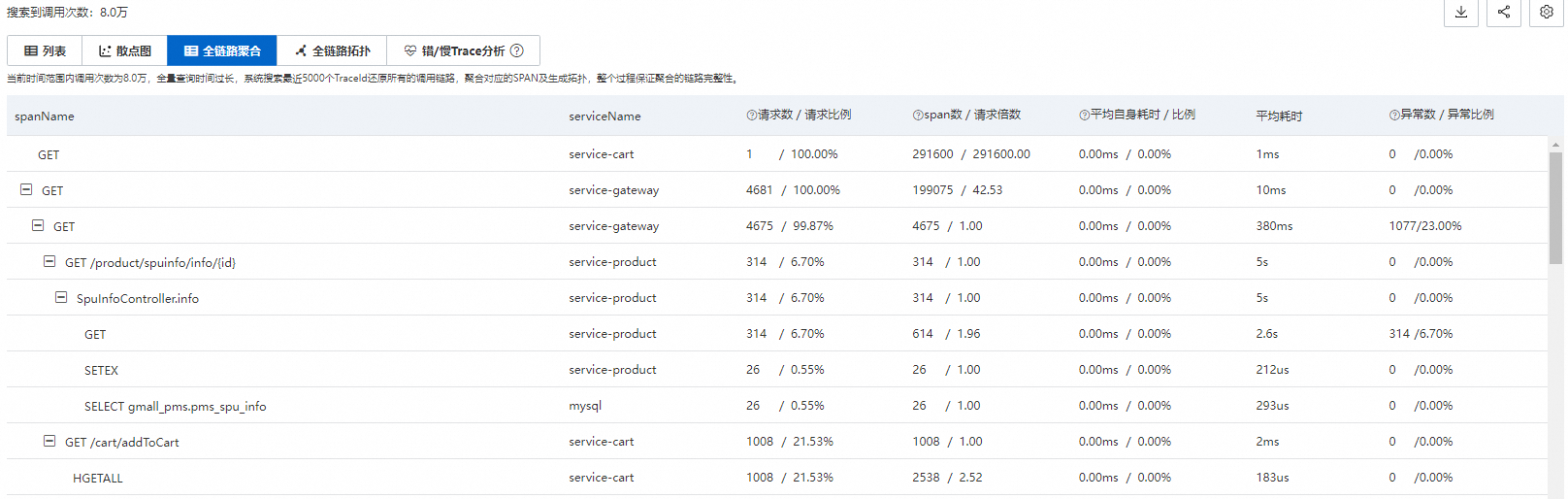
参数 | 说明 |
spanName | Span名称。 |
serviceName | Span对应的应用名。 |
请求数/请求比例 | 请求比例表示调用当前Span节点的请求比例数。 例如10%表示10%的请求会调用当前Span。 计算公式:请求比例=当前Span的请求数/总请求数*100% |
span数/请求倍数 | 请求倍数表示平均每个请求调用当前Span的次数。 例如1.5表示每个请求会调用当前Span 1.5次 。 计算公式:请求倍数=Span数/Span的请求数 |
平均自身耗时/比例 | 平均自身耗时表示不包括子Span的耗时。 例如,对于Span A和其子Span B, 其中A耗时为10 ms, B耗时为8 ms,那么A的自身耗时为2 ms。 计算公式:自身耗时=Span耗时-所有子Span耗时总和 重要 如果是异步调用,自身耗时即Span耗时,无需减去子Span耗时。 |
平均耗时 | 该Span的平均耗时。 |
异常数/异常比例 | 异常比例表示出现异常的请求比例。 例如3%表示有3%的请求出现异常。 计算公式:异常比例=异常请求数/总请求数 重要 异常请求数不等于异常数(Span调用异常的次数),当请求倍数大于1时, 一个异常请求可能对应多个异常数。 |
示例:如下表所示,Span A调用Span B和Span C,各参数含义如下。
spanName | serviceName | 请求数/请求比例 | span数/请求倍数 | 平均自身耗时/比例 | 平均耗时 | 异常数/异常比例 | |
A | - | demo | 10/100.00% | 10/1.00 | 5.00ms/25.00% | 20ms | 2/20.00% |
- | B | demo | 4/40.00% | 8/2.00 | 16.00ms/100.00% | 16ms | 2/50.00% |
- | C | demo | 1/10.00% | 1/1.00 | 4.00ms/100.00% | 4ms | 1/100.00% |
对于入口Span,A的请求数/请求比例表示A的请求总数为10次,比例为100%。B的请求数/请求比例为4/40.00%,表示只有4次请求调用了B,同理只有1次请求调用了C,对应的请求比例分别为40%和10%。其余的请求可能因逻辑判断或者异常而未调用B和C。这里反映了请求的分布比例。
A的span数/请求倍数为10/1.00,表示每次请求只调用了一次A,但是对于B而言,4次请求有8个Span,每次请求调用了2次B。这里反映了一次请求中Span的分布比例。
A的平均自身耗时/比例为5.00ms/25.00%,表示A除了B和C之外的平均耗时为5ms,只占整体平均耗时的25%。而子Span B和C因为没有子Span,所以自身耗时即整体耗时。这里反映了耗时的分布比例。
A的异常数/异常比例为2/20.00%,表示A发生了2次异常,占整体请求的20%。B的异常数/异常比例为2/50.00%,因为每次请求调用了2次B,总的请求数是4,异常比例是50%,那么2次请求发生了异常。所以B的分布可能是:一共有4次请求,其中有2次请求调用的4个Span B都是正常的,剩下2次请求中,首次Span B的调用都发生异常,然后重新调用成功。
如果需要查看具体的调用链详情,可以将鼠标悬浮于蓝色的Span名称上,在悬浮框中可以看到推荐的调用链ID,单击TraceId即可查看。
全链路拓扑
全链路拓扑页签显示调用链聚合后的应用间拓扑。如下图所示,表示两个应用间存在调用关系,同时展示相应的请求数、错误数、响应时间等数据。

错/慢Trace分析
错/慢Trace分析旨在帮助用户分析批量异常调用链的共有维度特征,例如错/慢调用都来自同一个主机、同一个接口,可以分别筛选对应的主机、接口下的Trace,或通过组合维度(例如serviceName="arms-demo" AND ip="192.168.1.1")筛选Trace,快速定位系统异常。错/慢Trace分析也可以用于梳理慢接口,对系统进行定向优化等。
慢Trace分析
ARMS对1000条耗时最长的Trace进行分析,展示与慢Trace显著相关的Top 5维度信息。
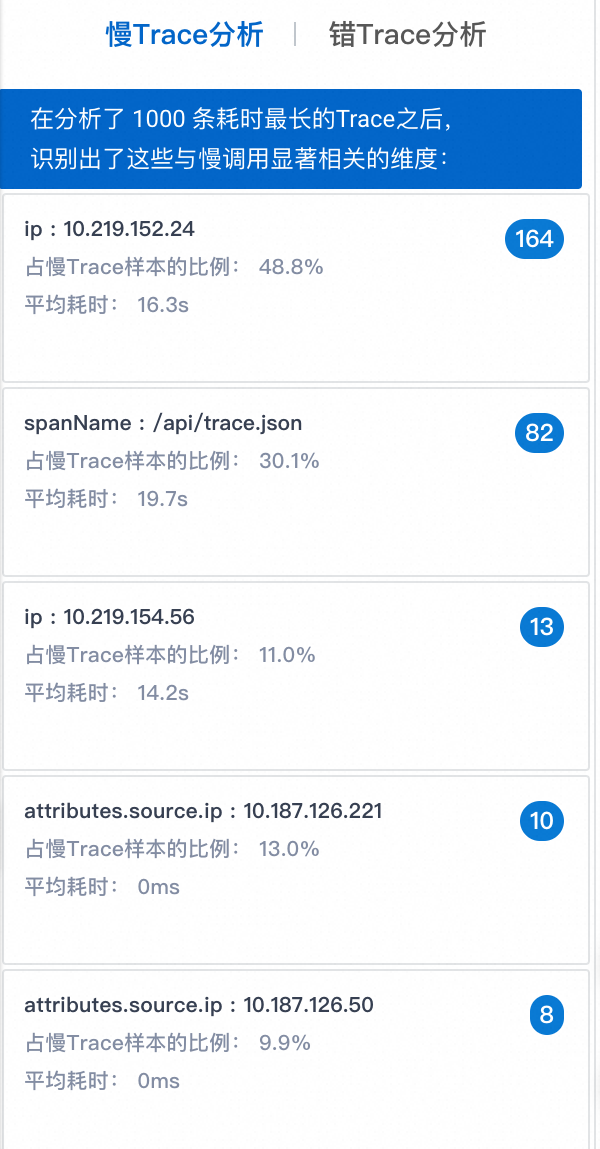
上图的示例表示,在1000条耗时最长的Trace中,有488条Trace的IP为10.219.152.24,且这些Trace的平均耗时为16.3s,说明IP为10.219.152.24的主机可能负载过高,导致响应时间较长。建议进入错/慢Trace分析页签进行深入分析。
右侧的164是该维度的异常分数,分数越高,该维度是慢调用根因的可能性越大。
慢Trace分析详情
在慢Trace分析功能中,ARMS会在当前查询条件下,以耗时大于耗时对比临界值的Trace中耗时最高的1000条Trace作为样本,与随机抽样的耗时小于耗时对比临界值的1000条Trace进行对比,分析并识别出与慢调用显著性相关的Top 3关键特征。
您可以根据需求,自定义耗时对比临界值。例如,如果您想分析耗时超过1分钟的Trace的维度特征,可以修改阈值为60000ms。

上图示例中可以看到,IP为10.219.152.24的Trace在慢Trace样本中占比最高,达到46.8%,并且IP为10.219.152.24的Trace仅占正常Trace的6.8%,说明大量的慢调用经过这个IP,且经过这个IP的调用链耗时都比较高,也许这个IP对应的主机出现了异常,值得深入分析。
同样,经过IP为10.219.154.56的Trace和接口名为/eventCenter的Trace也值得深入分析。
单击柱状图图标,对IP为10.219.152.24的Trace进行下钻分析。

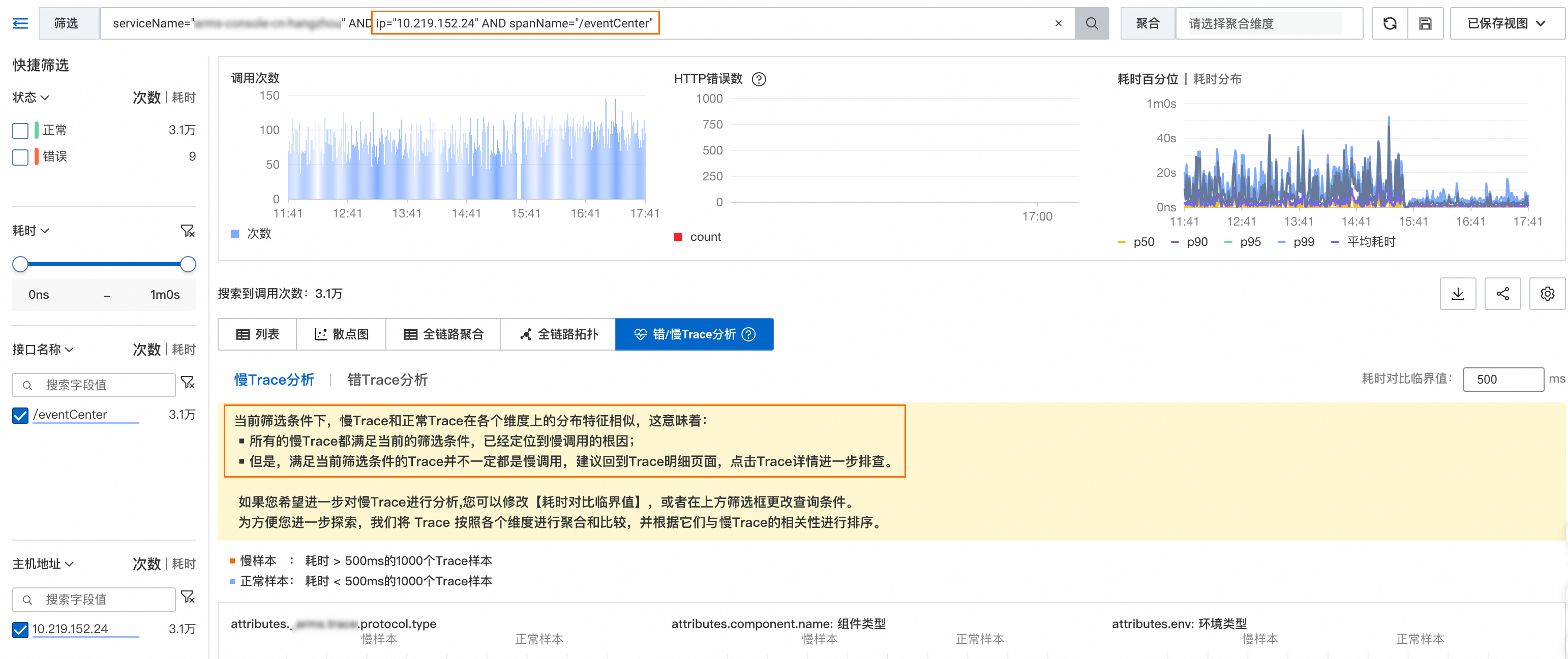
可以发现大量慢调用都来自/eventCenter接口,单击/eventCenter接口的柱状图,继续下钻分析。
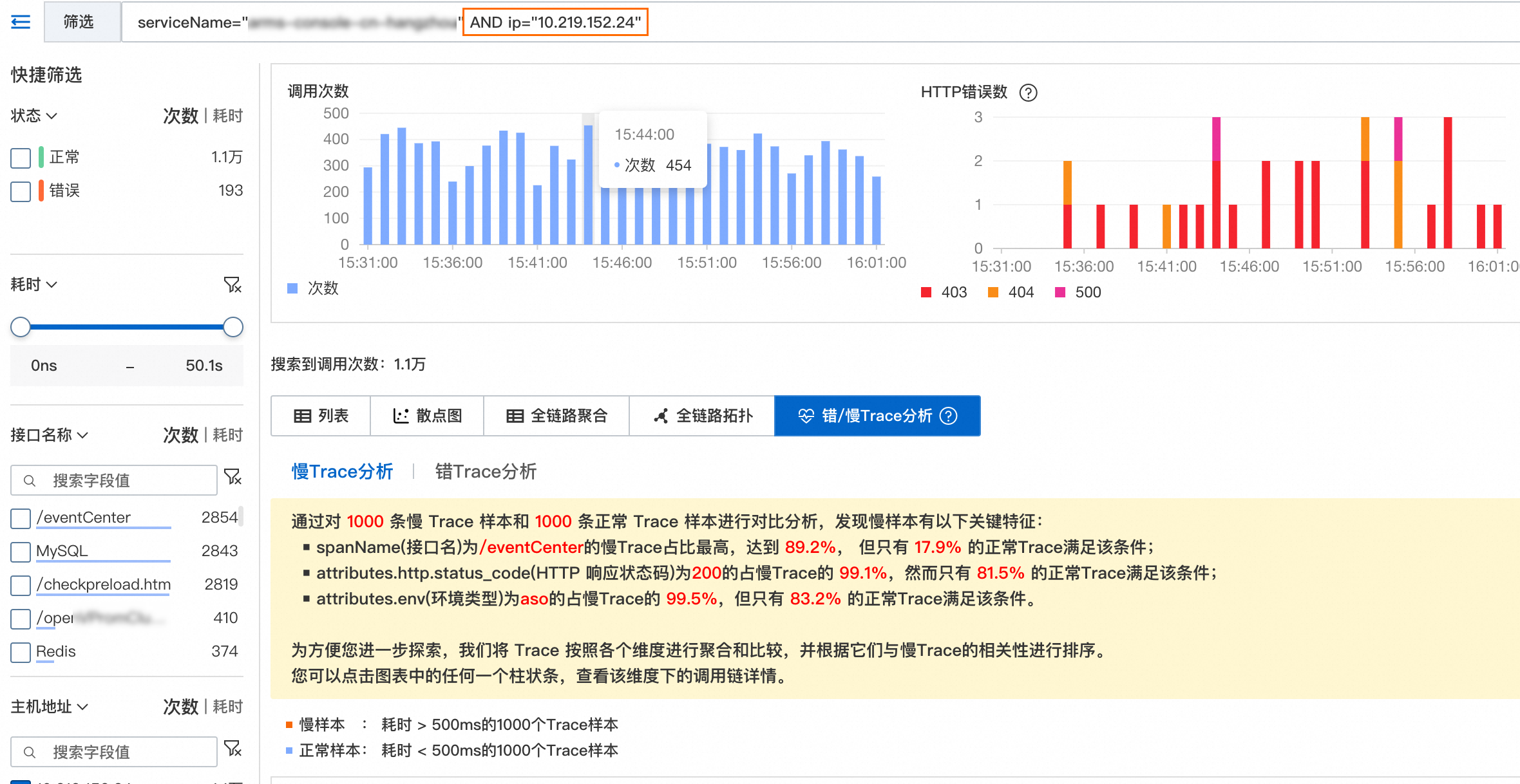
最终可以定位到根因ip="10.219.152.24" AND spanName="/eventCenter"。
您也可以直接在搜索框中填入任意筛选条件,ARMS会对您指定的Trace进行分析。查询语法说明,请参见调用链分析查询用法说明。
错Trace分析
ARMS随机选择1000条错Trace进行分析,展示与错Trace显著相关的Top 5维度信息。
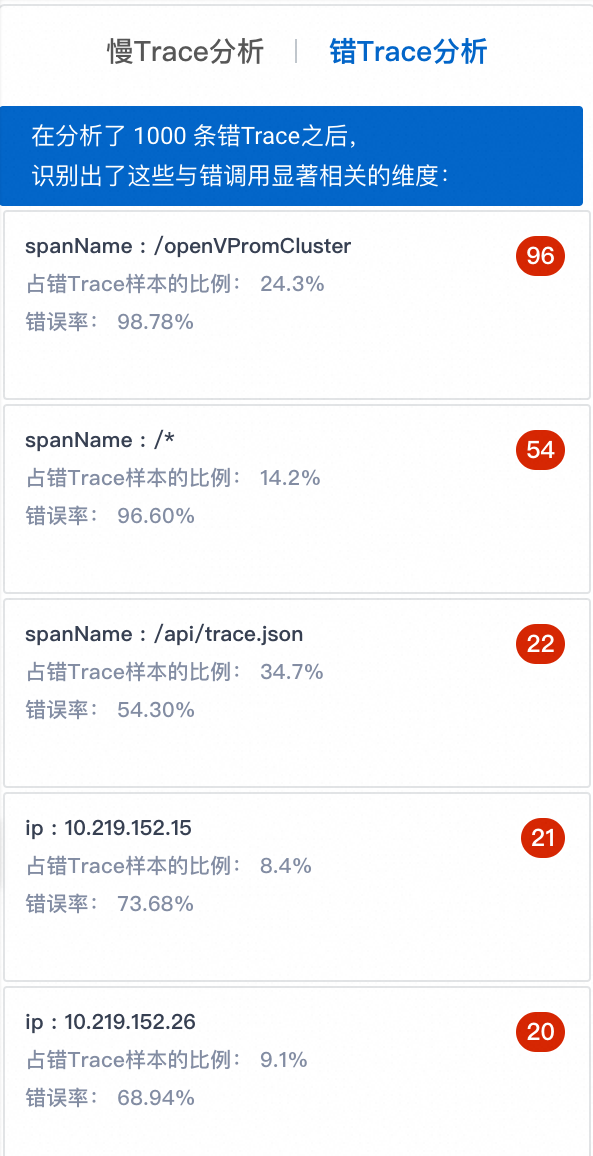
上图的示例表示,在1000条错Trace样本中,来自openVPromCluster接口的Trace占24.3%,并且这些Trace的错误率达到了98.78%,说明openVPromCluster接口很可能出现了异常,导致大量错误调用。建议进入错/慢Trace分析页签进行深入分析。
右侧的92是该维度的异常分数,分数越高,该维度是错调用根因的可能性越大。
错Trace分析详情
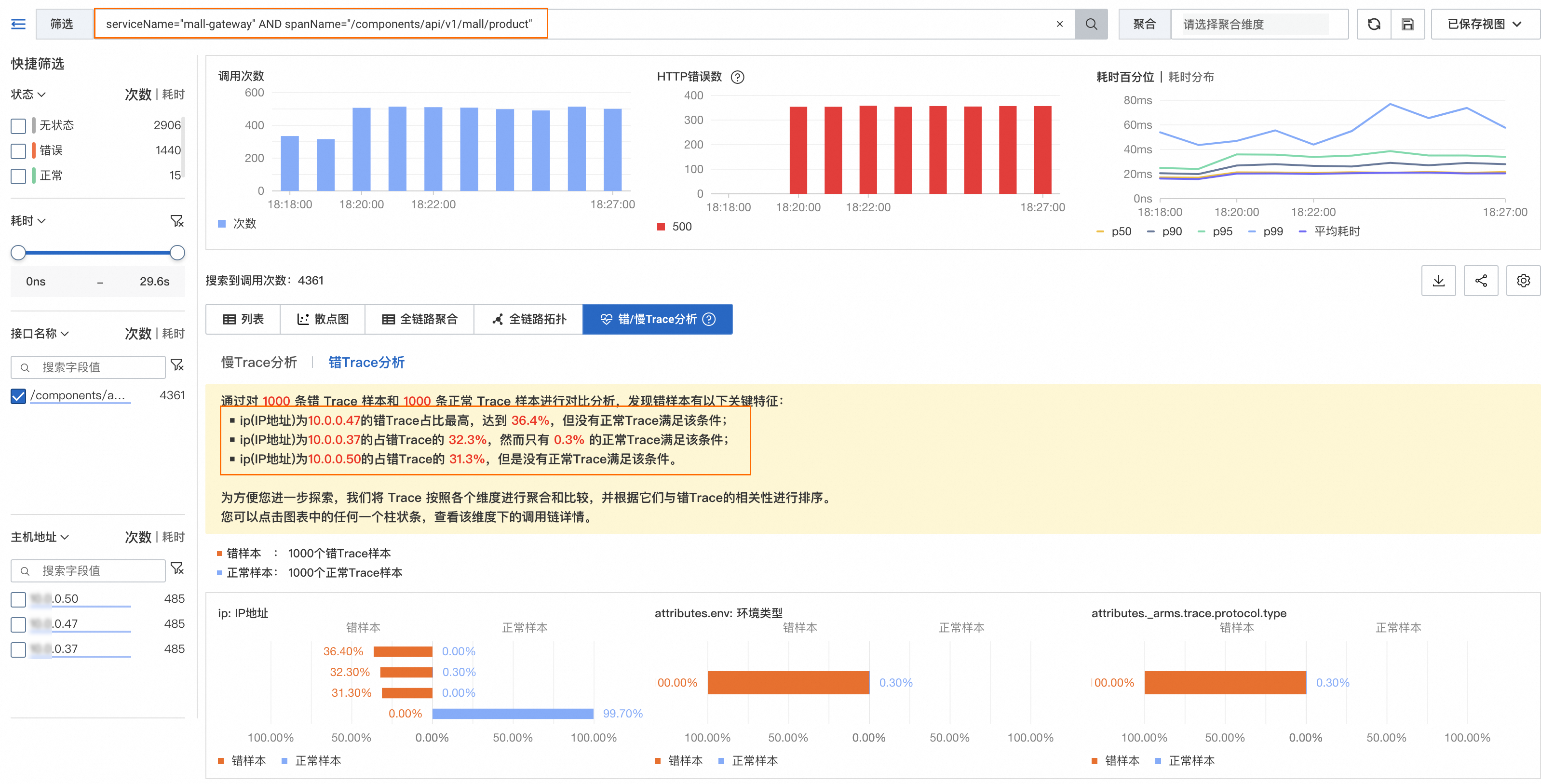
在错Trace分析功能中,ARMS会随机抽样1000条错Trace和1000条正常Trace,分析识别出与错调用显著性相关的Top 3关键特征。

上图示例中可以看到,在1000条错Trace样本中,接口名为/components/api/v1/mall/product的Trace占100%,且仅有9.8%的正常Trace接口名为/components/api/v1/mall/product,这说明所有的错Trace都来自接口/components/api/v1/mall/product,并且经过这个接口的Trace几乎都出错了,该接口很有可能出现了异常,值得深入分析。
同样,经过IP为10.0.0.47和10.0.0.37的Trace大部分调用都出错了,也值得深入分析。
单击spanName = "/components/api/v1/mall/product"的柱状图图标,可以过滤出接口名为/components/api/v1/mall/product的Trace,然后对相关Trace进行下钻分析。

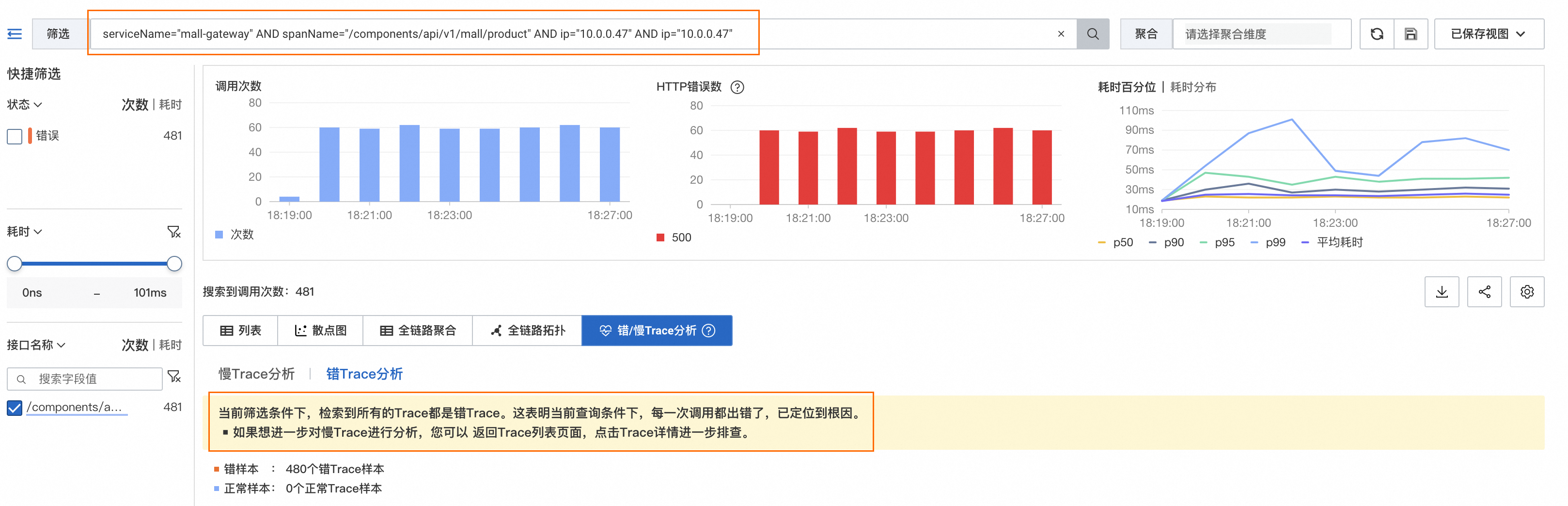
可以发现错误调用集中在10.0.0.47、10.0.0.37和10.0.0.50的IP上,继续下钻。
发现在serviceName="mall-gateway" AND spanName="/components/api/v1/mall/product" AND ip="10.0.0.47"筛选条件下检索的所有Trace都是错Trace,说明在10.0.0.47主机中,mall-gateway应用的/components/api/v1/mall/product接口在该时段出现了异常。
错/慢Trace分析更多使用案例,请参见通过错/慢调用链排查应用产生异常的原因。
Trace详情
组件标签(图示①)
标签中展示了调用类型以及调用链中该类型Span的数量。
调用类型通过Span属性中的component.name来区分(attributes.component.name)。
单击组件标签,可以在调用链中隐藏对应类型的Span,方便您过滤不需要关注的Span。再次单击即可恢复显示。
调用链轨迹图(图示②)
Trace轨迹图用于展示整个跟踪链路及Span数据分布情况。
Trace轨迹图中每个条形均代表一个Span(仅展示耗时占总耗时比例大于1%的Span)。
不同的应用通过不同的颜色进行区分。例如,在上文示例图中,蓝色代表opentelemetry-demo-adservice应用。
轨迹图中的黑线长度代表Span自身耗时,即Span耗时减去Sum(子Span耗时)。例如Span A调用Span B,A耗时为10毫秒,B耗时为8毫秒,那么A的自身耗时为2毫秒。
时间轴表示整条Trace数据的时间跨度。
调用链聚焦与过滤(图示③)
该区域中的每一行代表一条Span数据,并展示父级Span和子级Span之间的层级关系。Span数据前面的标号表示该父级Span所拥有的子级Span数量。在该区域,您可以执行如下操作:
折叠:单击
图标,折叠或展开Span数据。聚焦:选中目标Span数据,单击
图标,系统将只显示该Span以及该Span下游的数据,实现Span数据聚焦。取消聚焦:单击
图标,取消Span数据聚焦。过滤:在搜索框中输入目标Span携带的信息(可以是Span名称、应用名、属性等内容),即可过滤目标Span,展示从入口Span到目标Span的调用路径。如果要取消过滤,删除搜索框中的内容并单击搜索即可。
放大与缩小:单击
图标,将会放大调用链,隐藏Trace轨迹图。单击图标将恢复Trace轨迹图展示。
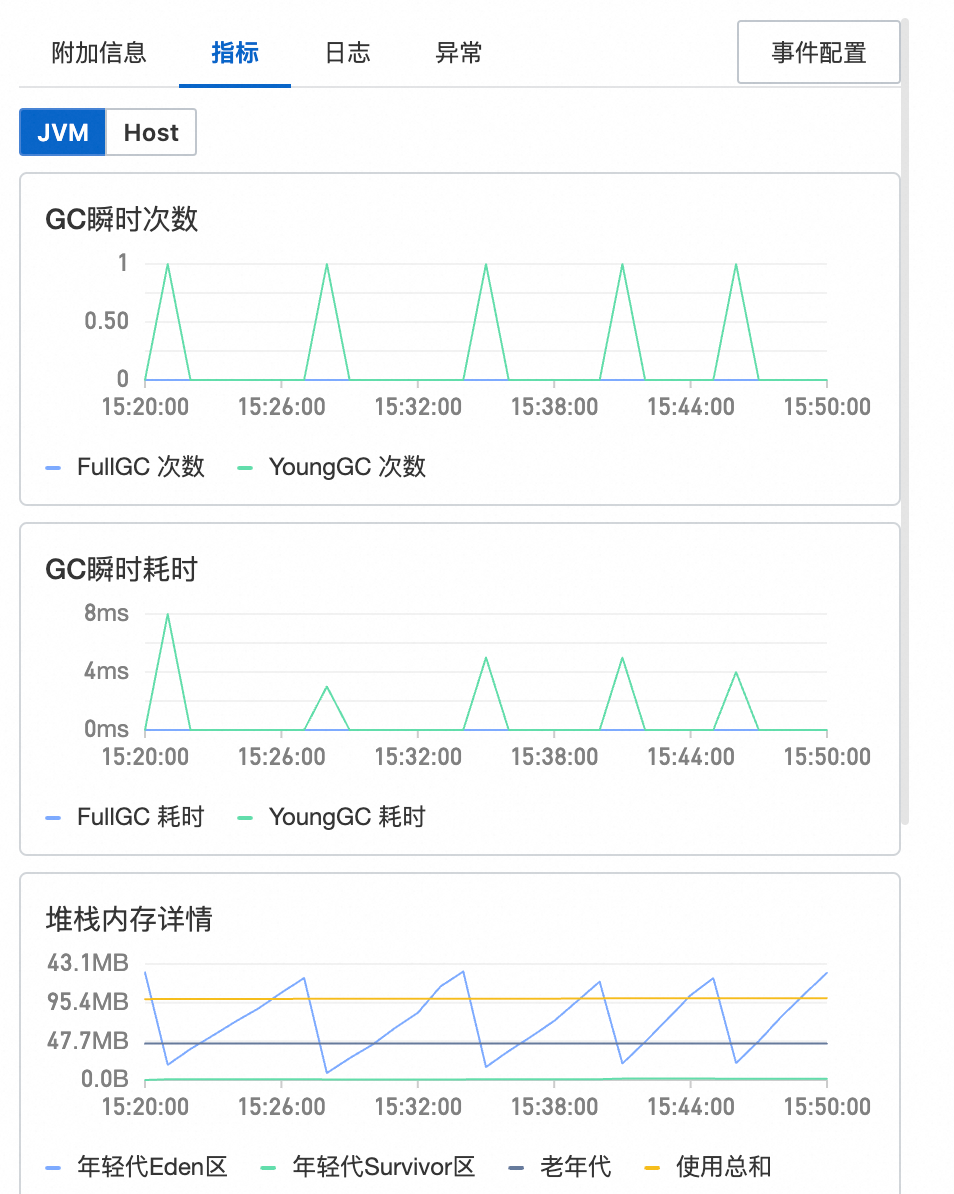
Span详情(图示④)
Span详情区域包含了当前Span的详细信息,以及关联的指标、日志和异常信息,并能管理自定义交互事件和触发交互事件。
附加信息:附加信息包含Span的属性(Attributes)、资源(Resources)、详情(Details)和事件(Events)四种信息,并按照类型进行分组。关于Span详情中的字段说明,请参考调用链分析参数说明。
指标:展示与Span关联的指标。对于ARMS Java应用的调用链,将展示JVM 和主机维度的指标;对于开源探针上报的调用链,将展示RED黄金三指标。
日志关联:如您为应用关联了日志服务日志库,可快速跳转至日志库并查询当前TraceId对应的业务日志。
异常:当Span记录了异常信息时,此页面会展示具体的异常信息。
事件配置:您可以为调用链的一个或多个属性设置交互事件,方便查询更详尽的调用链或查看与调用链关联的日志、指标等信息。自定义交互事件相关的配置说明请参见为调用链配置自定义交互事件。
相关文档
为避免在出现问题后被动诊断错误原因,您还可以使用告警功能针对一个接口或全部接口创建告警,即可在出现问题时向运维团队发送通知。如何创建告警,请参见应用监控告警规则。