
在Service Mesh中,不同的服务可能需要采集不同的可观测性数据,因此需要支持针对网格代理与网关Pod分别定义采集配置规则,并统一标准化采集配置规则,以便更好地支持云原生应用的可观测性。可观测性在云原生应用中扮演着非常重要的角色,它可以帮助我们实时监控服务的运行情况和性能指标,发现并解决服务故障和瓶颈,从而提高应用的可靠性和性能。阿里云服务网格ASM提供了统一标准化方式,为您提供一种收敛后的可观测数据生成与采集配置模式,以更好地支持云原生应用的可观测性。本文介绍可观测的概念及相关功能。
可观测介绍
随着应用系统的复杂度越来越高,就越来越难保证所有的系统都一直处于稳健状态,有可能某些部分会因问题而处于降级状态。因此不仅需要将应用程序构建得更可靠且更具弹性,还需要通过可观测性工具了解应用服务和基础设施在运行时发生的情况。如果能够了解实际发生的情况,就可以学会检测故障并在观察到某些意外情况时进行深入调试。这将有助于降低平均恢复时间,快速恢复对业务的影响。
可观测性是一个包含各种级别的系统特征,必须结合应用程序的指标采集、网络的指标采集、以及基础设施(例如数据库存储等)来筛选存储大量的数据,以便在发生不可预测的情况时拼凑出一个完整的视图。Service Mesh在可观测性方面可以有效提升应用程序级别的网络指标采集。从实际应用的角度来看,在系统中需要重视其稳定性,需要理解什么时候系统运行良好或出现问题,从而可以更快地识别错误,并实施正确的自动化及手动控制来维护系统的可用性。
Service Mesh的数据平面代理位于服务之间的网络请求路径中,通过捕获代理的可观测性数据可以在运行时了解应用程序网络和网格的运行情况。

在Service Mesh中实现可观测性,涉及了日志、监控指标、链路追踪这些可观测性数据的生成规则配置和采集配置,以及如何将这些可观测数据采集到云托管服务或者自建服务中。同时,还需要考虑如何支持针对网格代理与网关Pod分别定义采集配置,以支持不同的场景诉求。ASM提供了统一标准化方式,为您提供一种收敛后的可观测数据生成与采集配置模式,以更好地支持云原生应用的可观测性。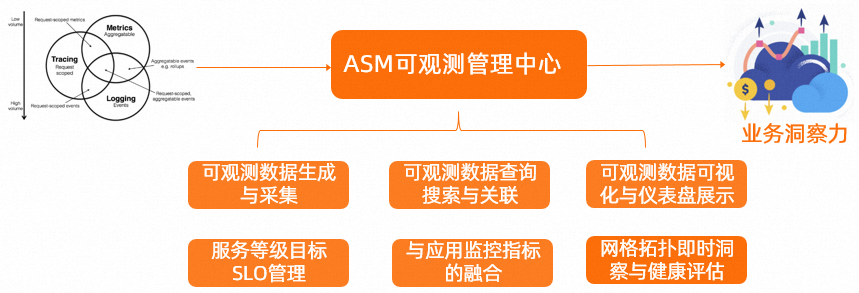
内置最佳实践
Telemetry CRD允许在多个命名空间内创建多个对象,但随意定义可能造成冲突等,导致实际执行的结果与预期不符。基于实际操作得出的最佳实践如下:
在根命名空间istio-system中定义多个网格范围的Telemetry资源对象无效,即只能存在一个Telemetry资源对象。ASM中已经内置了该最佳实践,在istio-system命名空间内只允许存在一个名称为default的Telemetry资源对象。
所有的命名空间下约束只存在一个Telemetry资源对象允许工作负载的选择器selector为空,且名称为default。
可以通过使用工作负载选择器selector在所需命名空间中应用新的Telemetry资源对象来实现特定工作负载的覆盖。
如果存在具有相同的工作负载选择器selector的两个Telemetry资源对象,即这两个Telemetry资源对象选择了相同的工作负载,则不确定这两个Telemetry资源对象中的哪一个会被执行。
当根命名空间istio-system下的全局Telemetry资源对象中,未定位监控指标部分,默认对应不启用生成指标。
日志
在Service Mesh中,日志的采集是实现可观测性的重要手段之一。将所有服务的日志聚合到一处,便于统一管理和检索。为了实现这个目标,需要将每个服务的日志打印到stdout或stderr,并使用日志代理将它们收集到中心日志系统中。ASM提供了日志过滤和日志格式化功能,可以根据需要对日志进行过滤和格式化,以便更好地检索和分析日志。
日志格式规则配置
在实际应用中,不同服务的日志格式可能不同,因此需要设置生成规则来控制日志的生成方式。部署在数据平面(即加入网格的Kubernetes集群)的Envoy Proxy可以输出所有访问日志。ASM支持自定义Envoy Proxy输出的访问日志内容。
基于Telemetry CRD,ASM提供了如下图所示的图形化界面,简化日志数据格式的配置。具体操作,请参见自定义数据面访问日志。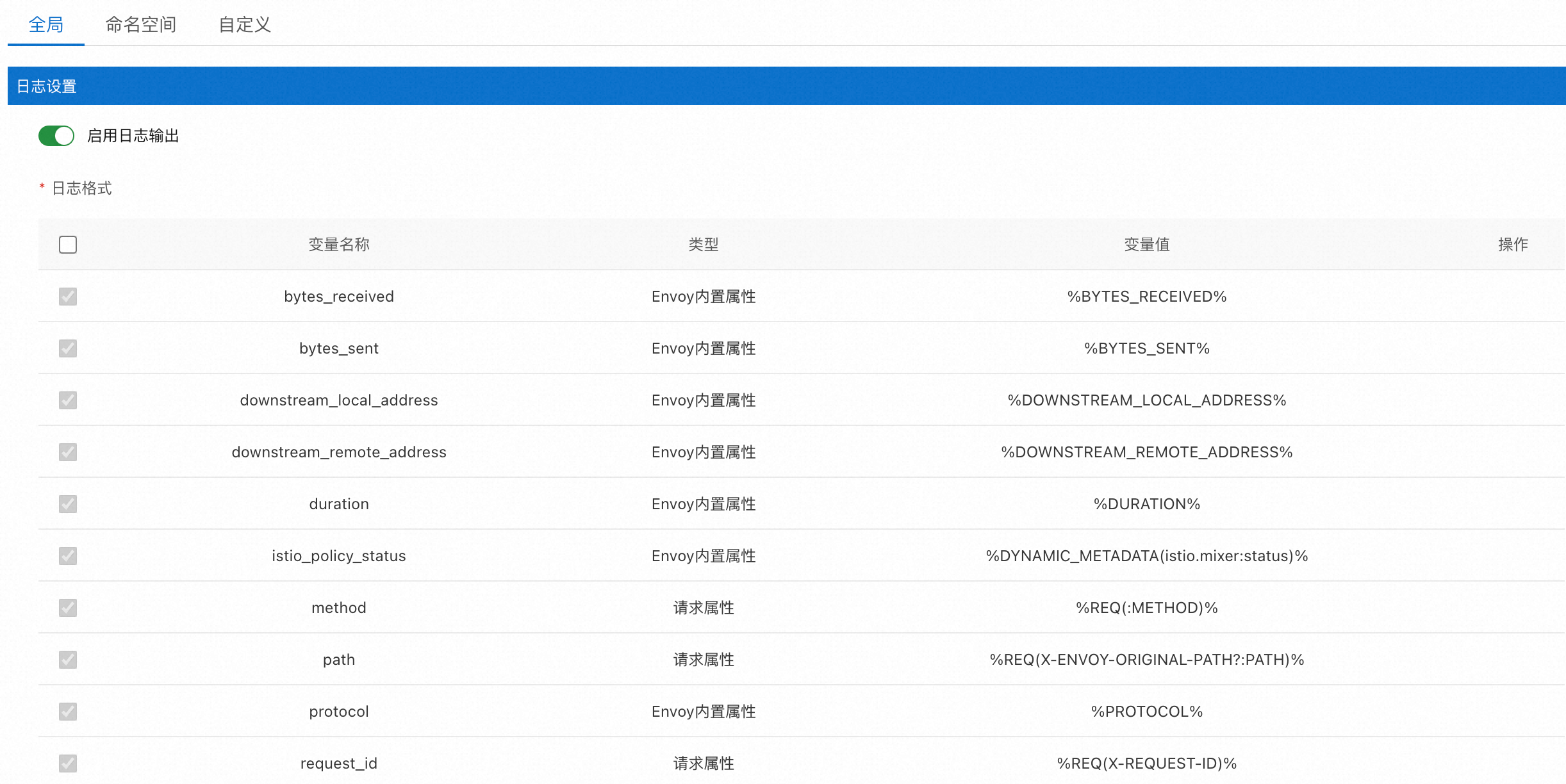
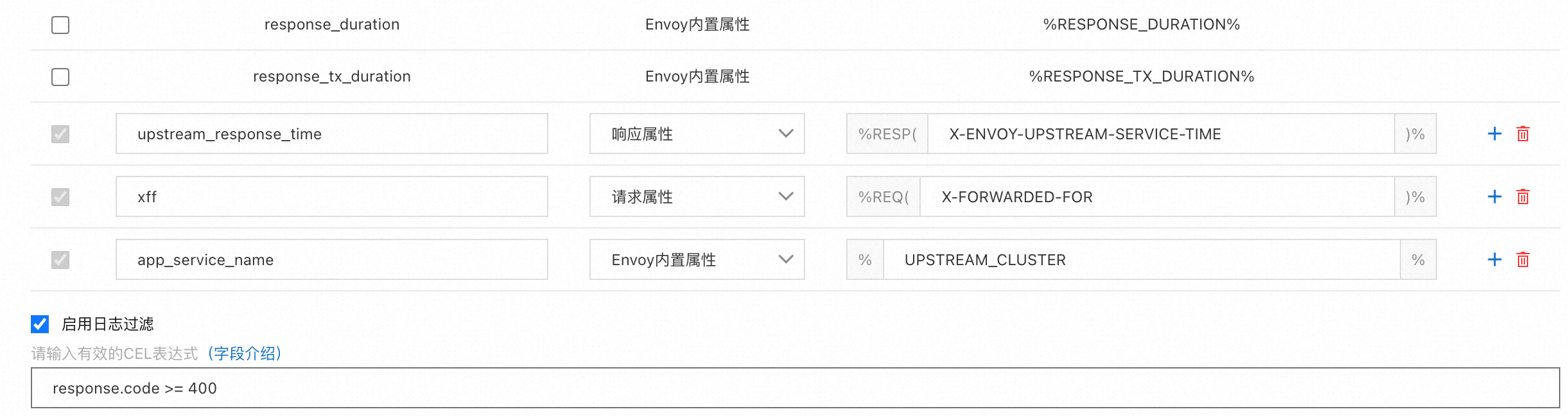
对应生成的定义内容如下:
envoyFileAccessLog:
logFormat:
text: '{"bytes_received":"%BYTES_RECEIVED%","bytes_sent":"%BYTES_SENT%","downstream_local_address":"%DOWNSTREAM_LOCAL_ADDRESS%","downstream_remote_address":"%DOWNSTREAM_REMOTE_ADDRESS%","duration":"%DURATION%","istio_policy_status":"%DYNAMIC_METADATA(istio.mixer:status)%","method":"%REQ(:METHOD)%","path":"%REQ(X-ENVOY-ORIGINAL-PATH?:PATH)%","protocol":"%PROTOCOL%","request_id":"%REQ(X-REQUEST-ID)%","requested_server_name":"%REQUESTED_SERVER_NAME%","response_code":"%RESPONSE_CODE%","response_flags":"%RESPONSE_FLAGS%","route_name":"%ROUTE_NAME%","start_time":"%START_TIME%","trace_id":"%REQ(X-B3-TRACEID)%","upstream_cluster":"%UPSTREAM_CLUSTER%","upstream_host":"%UPSTREAM_HOST%","upstream_local_address":"%UPSTREAM_LOCAL_ADDRESS%","upstream_service_time":"%RESP(X-ENVOY-UPSTREAM-SERVICE-TIME)%","upstream_transport_failure_reason":"%UPSTREAM_TRANSPORT_FAILURE_REASON%","user_agent":"%REQ(USER-AGENT)%","x_forwarded_for":"%REQ(X-FORWARDED-FOR)%","authority_for":"%REQ(:AUTHORITY)%","upstream_response_time":"%RESP(X-ENVOY-UPSTREAM-SERVICE-TIME)%","xff":"%REQ(X-FORWARDED-FOR)%","app_service_name":"%UPSTREAM_CLUSTER%"}'
path: /dev/stdout对应的过滤条件内容如下:
accessLogging:
- disabled: false
filter:
expression: response.code >= 400
providers:
- name: envoy数据面日志采集设置
将数据平面日志采集到阿里云日志服务SLS时,需要设置采集规则来控制日志的采集方式和储存有效期。容器服务ACK集成了日志服务功能,可对服务网格数据平面集群的AccessLog进行采集。具体操作,请参见使用日志服务采集数据面集群AccessLog。
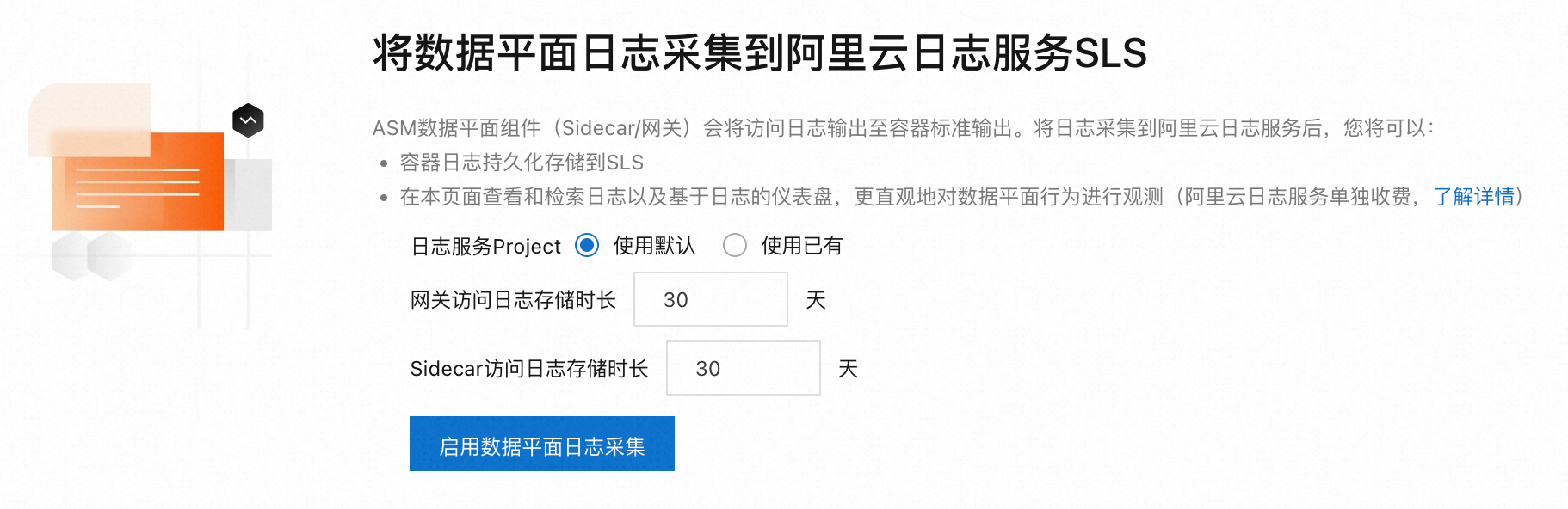
采集控制平面日志及设置告警
ASM支持采集控制平面日志和日志告警,例如采集ASM控制平面向数据平面Sidecar推送配置的相关日志。ASM控制面组件的主要功能之一是推送网格的规则配置到数据面的Sidecar代理或者网关中。如果您配置的网格规则内容存在一些冲突导致推送失败,Sidecar代理或者网关将接收不到最新的配置内容。虽然Sidecar代理或网关在不重启的情况下,可以使用已经接收到的配置继续运行,但是一旦这些Pod重启,很有可能导致Sidecar代理或网关启动失败。在很多实际场景中,经常出现用户误配置引发的网关或代理不可用的问题,因此启用控制面的日志告警,及时发现并解决问题十分必要。具体操作,请参见启用控制平面日志采集和日志告警(旧版)或启用控制平面日志采集和日志告警(新版)。
监控指标
监控指标是Service Mesh中的另一个重要可观测性维度,用于描述请求的处理情况、服务之间的通信状况等。Istio采用Prometheus进行监控指标的采集和存储,每个服务的代理(Envoy)会生成大量的监控指标。这些指标可以用于实时监控服务的运行情况和性能指标,还可以用于异常检测和自动伸缩等场景。
指标数据生成规则配置
启用服务网格数据平面监控指标可以使服务网格数据平面(网关和Sidecar代理)生成与其运行状态相关的指标数据。您可以通过将指标采集到阿里云ARMS Prometheus来直接查看监控报表(采集指标可能产生费用),或是自建Prometheus并从ASM数据平面抓取监控指标。
基于Telemetry CRD,ASM提供了如下图所示的图形化界面,简化自定义指标配置。具体操作,请参见在ASM中自定义监控指标。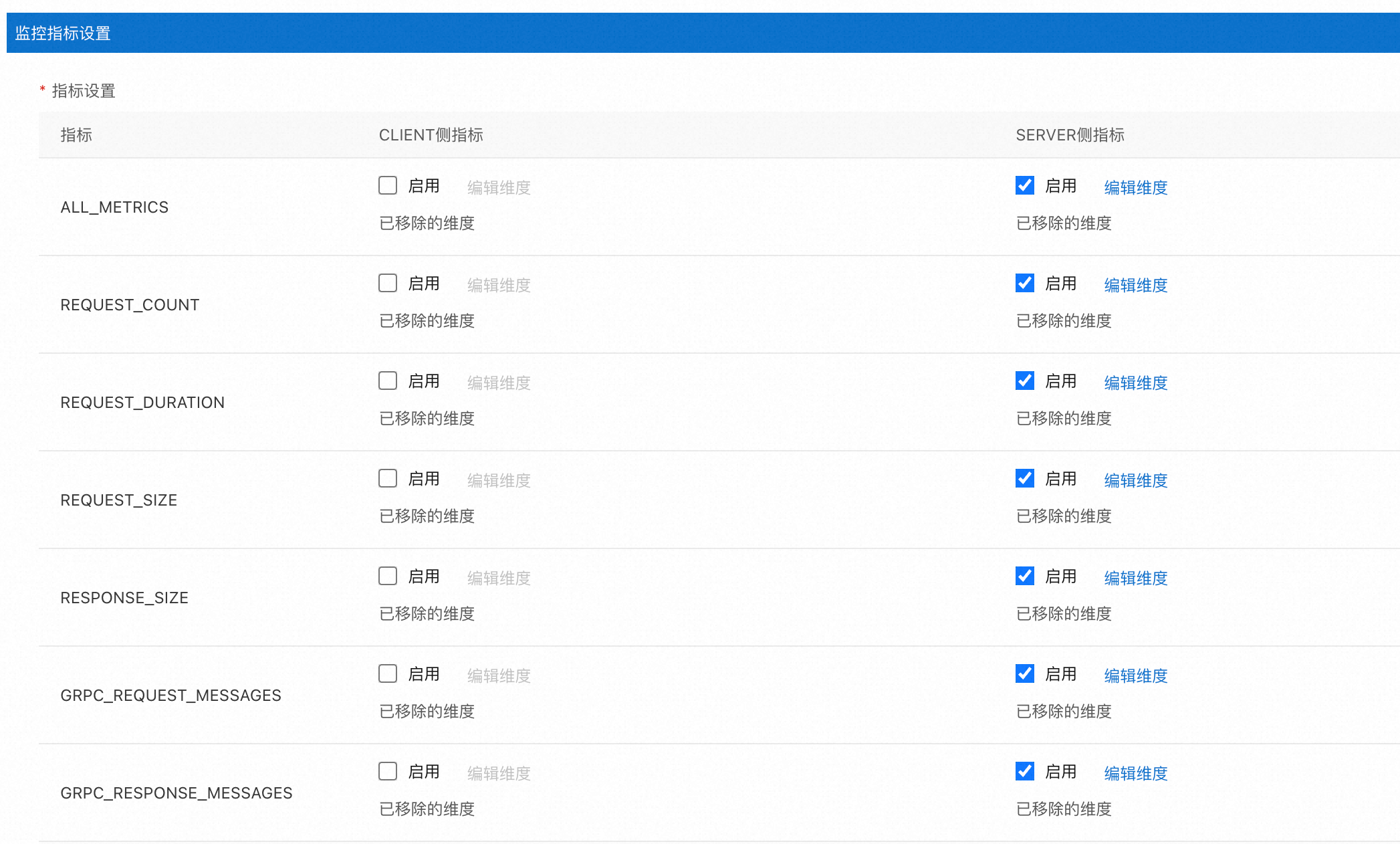
对应生成的定义内容如下:
监控指标注意事项
第一次开启:阿里云可观测监控Prometheus版是收费服务,请您根据实际情况自行决定指标生成范围,以免指标量过大,产生过高费用。例如,若需要针对网关进行监控,则需要开启CLIENT侧指标。对于已开启过的指标,重新开启之后的指标设置将保留使用上一次的设置规则。
ASM网格拓扑功能相关的指标设置:ASM网格拓扑功能依赖于Sidecar上报的监控指标,若您开启了网格拓扑,关闭部分监控指标会对网格拓扑功能造成影响甚至不可用。
如果不启用REQUEST_COUNT的SERVER侧指标,将无法生成HTTP或gRPC服务的拓扑图。
如果不启用TCP_SENT_BYTES的SERVER侧指标,将无法生成TCP服务的拓扑图。
关闭REQUEST_SIZE和REQUEST_DURATION的SERVER侧,REQUEST_SIZE的CLIENT侧指标会导致部分拓扑图节点的监控信息无法展示。
指标采集配置
开启Prometheus的统计数据收集功能,将采集到的监控指标发送到Prometheus中,以便进行存储和分析。ASM集成了ARMS Prometheus功能,可以实现对服务网格的监控。具体操作,请参见集成可观测监控Prometheus版实现网格监控。
Prometheus采集间隔会对指标收集开销产生重大影响。间隔越长,抓取的数据点就越少,从而可以减少处理、存储和计算开销。当前的默认配置为15秒,对于生产场景来说可能过于频繁。请根据实际需要在Prometheus侧进行调整。如果使用的是ARMS Prometheus,请通过ARMS控制台进行相关配置。具体操作,请参见配置采集规则。
直方图关联的指标(包括istio_request_duration_milliseconds_bucket、istio_request_bytes_bucket、istio_response_bytes_bucket)通常比较密集,开销较大。为了避免这些自定义指标持续产生费用,您可以废弃这些自定义指标。如果使用的是ARMS Prometheus,请通过ARMS控制台进行配置。具体操作,请参见配置废弃指标。
ASM集成自建Prometheus实现网格监控。具体操作,请参见集成自建Prometheus实现网格监控。
如下图所示,您可以通过Grafana查看对应的仪表盘。
合并Istio与应用的监控指标
已有Prometheus监控端点的应用服务,通过启用合并Istio与应用的监控指标功能,可以借助网格代理输出原有业务指标。启用合并Istio与应用的监控指标功能后,ASM会将应用程序指标合并到Istio指标中,相对应的prometheus.io注解会被加入到所有数据面Pod上,以启用Prometheus的指标抓取能力。如果这些注解已经存在,就会被覆盖。网格代理将应用指标和Istio指标进行合并,Prometheus可以从:15020/stats/prometheus端点拉取合并后的指标。具体操作,请参见合并Istio与应用的监控指标。
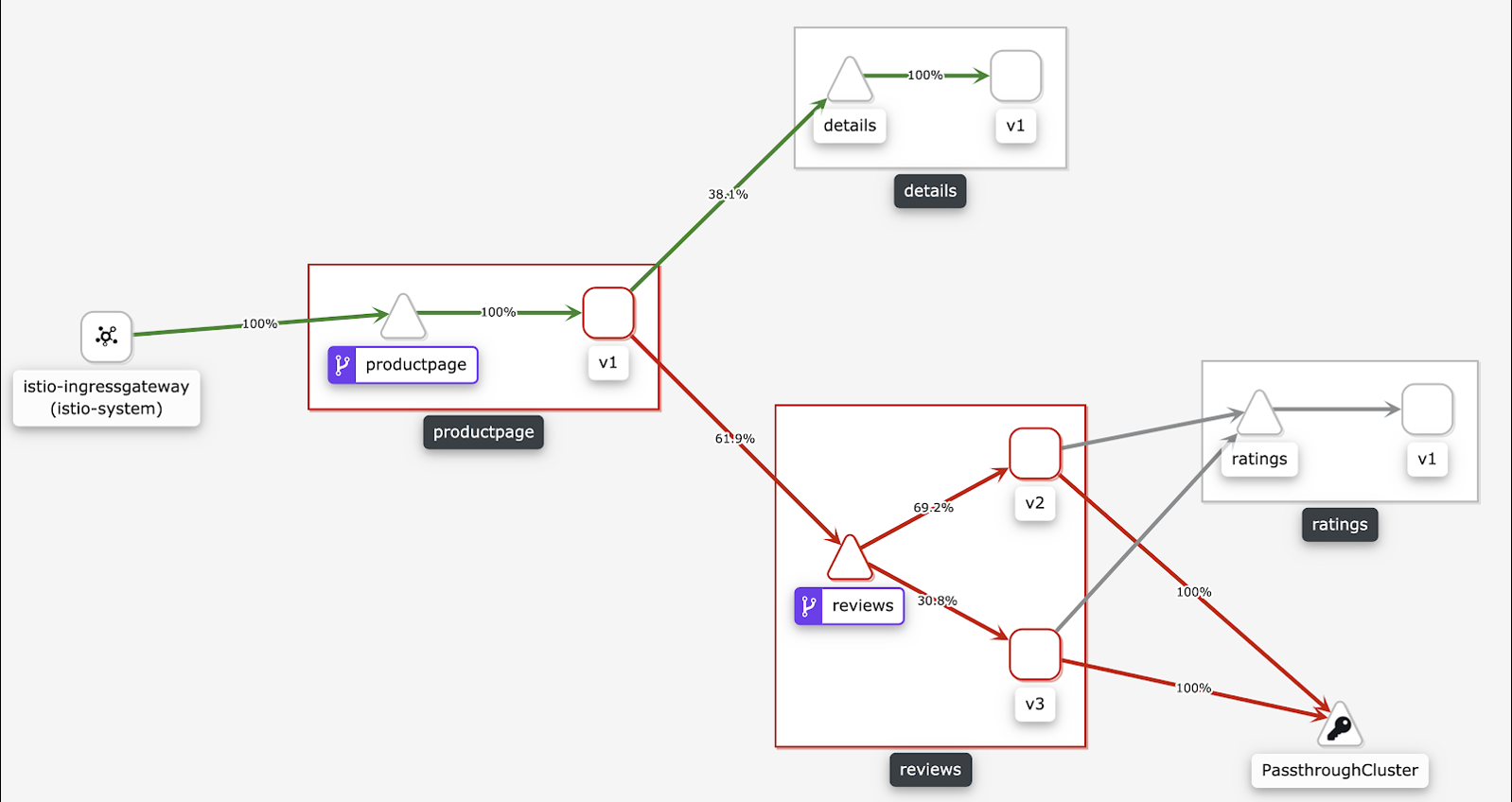
网格拓扑展示
网格拓扑是一个服务网格可观测性工具,提供查看相关服务与配置的可视化界面。如下图所示,ASM支持内置网格拓扑。具体操作,请参见开启网格拓扑提高可观测性。
服务等级目标SLO
服务等级指标SLI(Service Level Indicator)是衡量服务健康状况的指标。SLO是指服务等级的目标值或范围值,由一个或多个服务等级指标SLI组成。
SLO提供了一种形式化的方式来描述、衡量和监控微服务应用程序的性能、质量和可靠性。SLO为应用开发和平台团队、运维团队提供了一个共享的质量基准,可作为衡量服务水平质量以及持续改进的参考。使用SLI组合定义的SLO能够帮助团队以更精确的方式描述服务健康状况。
SLO示例如下:
每分钟平均QPS > 100,000/s
99%访问延迟 < 500ms
99%每分钟带宽 > 200 MB/s
ASM提供了开箱即用的基于服务等级目标SLO(Service Level Objectives)的监控和告警能力,能够监控应用服务之间调用的延迟和错误率特征等。
ASM支持的SLI类型如下:
服务可用性:服务成功响应的时间比例,对应的SLI插件类型为availability。HTTP响应码为429或以5XX(以5开头的状态码)会被判断为不可用。
延迟时间:服务返回请求的响应所需的时间(单位为毫秒),对应的SLI插件类型为lantency。您可自定义延迟上限,高于上限的响应会被判断为不合格。
ASM提供了定义SLO配置的UI界面如下。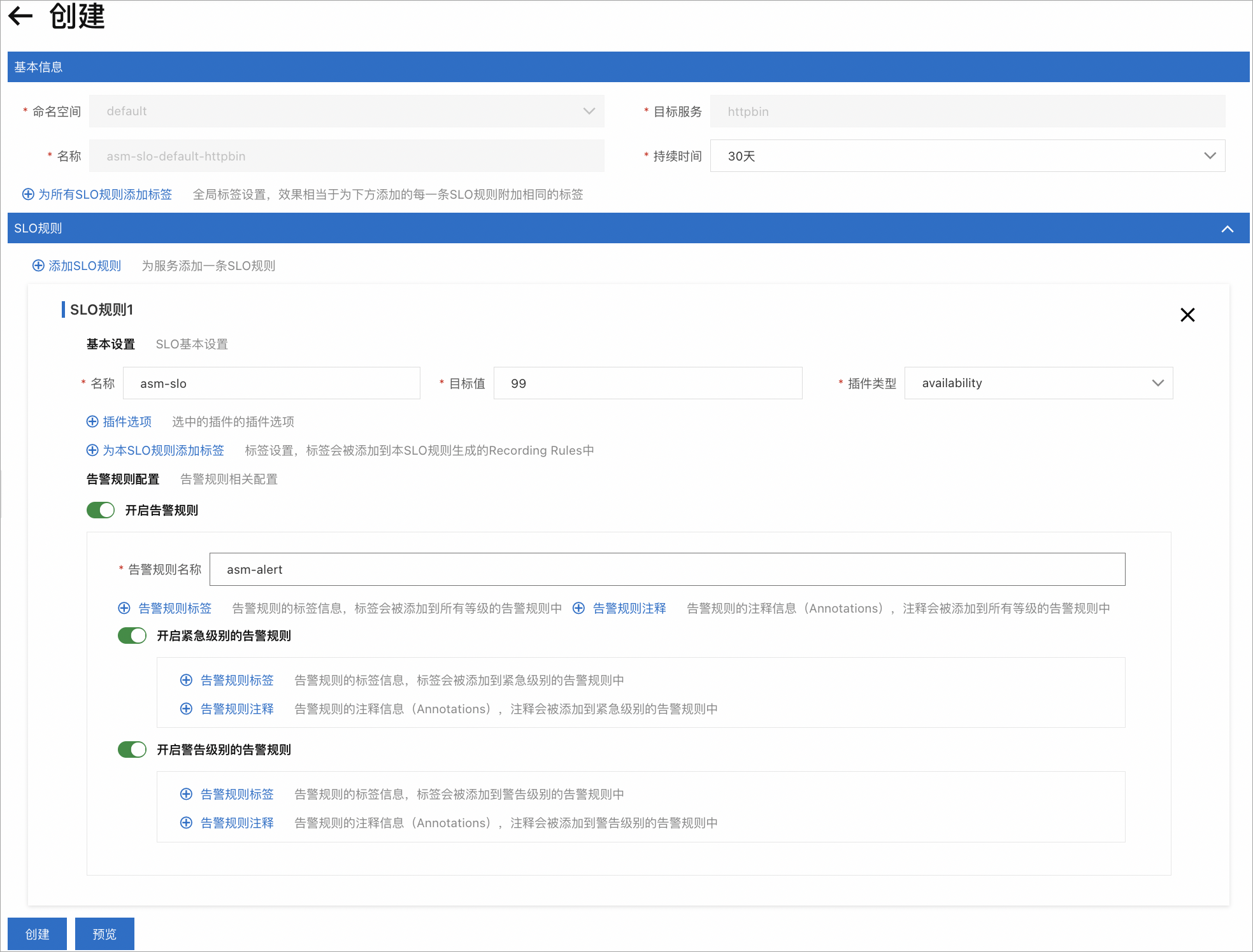
使用ASM定义应用服务级SLO,可以自动生成Prometheus规则。将生成的规则导入Prometheus中之后可以执行SLO。在Prometheus框架中,由AlertManager组件负责收集Prometheus Server产生的告警信息,并根据您的配置发送给各个接收者。如下图所示,当触发告警时,您可以在Alertmanager页面看到自定义告警信息采集成功。关于SLO的更多信息,请参见SLO管理。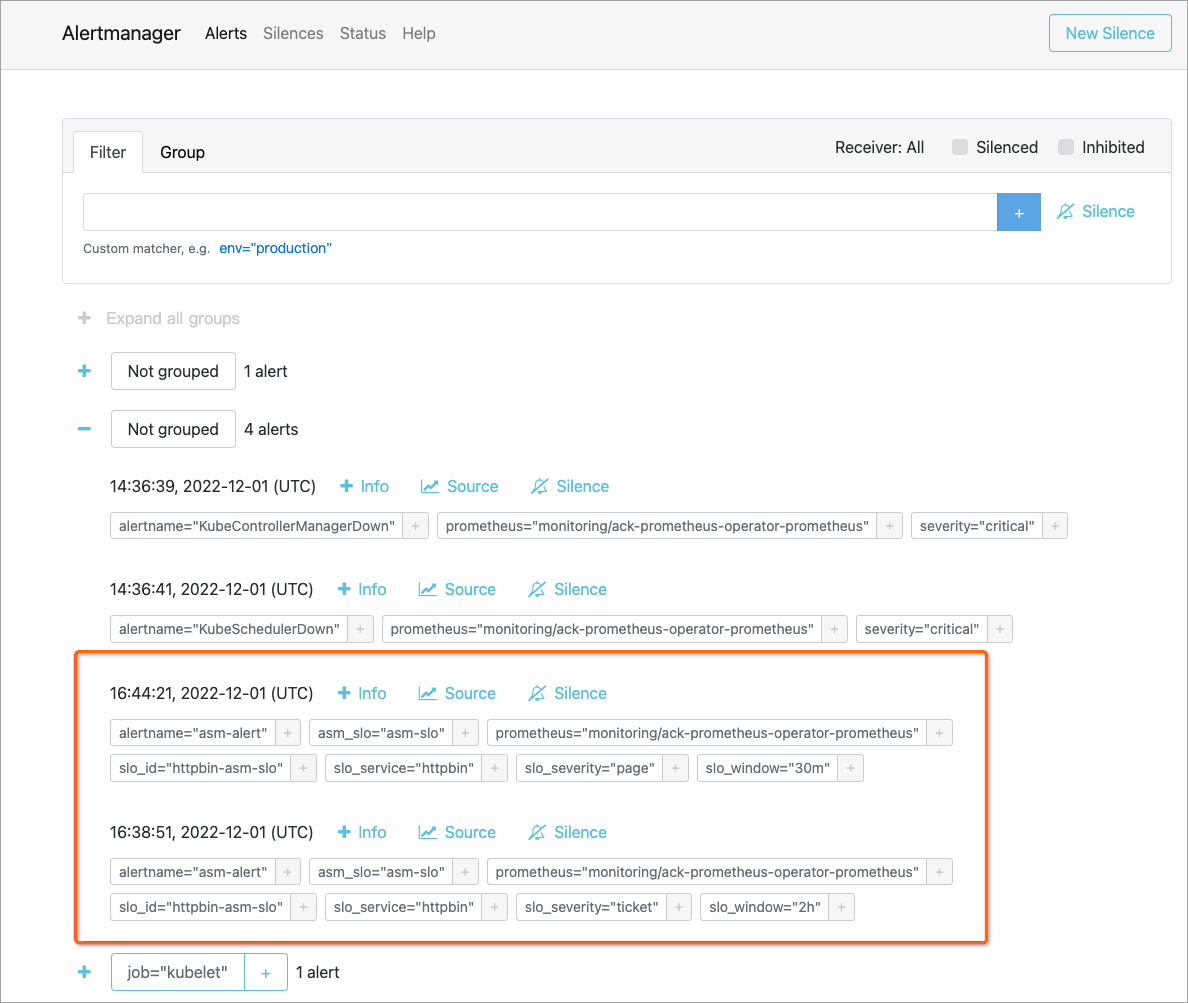
分布式追踪
分布式追踪是Service Mesh中实现可观测性的重要组成部分之一,是一种用于对应用程序进行概要分析和监视的方法,尤其是针对使用微服务架构构建的应用程序。在微服务架构中,服务之间的通信通过网络进行,因此需要采用分布式追踪技术来对服务之间的调用关系进行跟踪和监控。在Istio中,可以使用Jaeger、Zipkin等分布式追踪工具来实现这个功能。在分布式追踪里,存在Trace和Span两个重要概念。
Span:分布式追踪的基本组成单元,表示一个分布式系统中的单独的工作单元,每一个Span可以包含其它Span的引用。多个Span在一起构成了Trace。
Trace:微服务中记录的完整的请求执行过程,一个完整的Trace由一个或多个Span组成。
虽然Istio代理能够自动发送Span信息,但是应用程序仍然需要传播适当的HTTP标头,以便在代理发送Span时,可以将Span正确地关联到单个跟踪中。因此,应用程序需要收集以下标头并将其从传入请求传播到任何传出请求:
x-request-id
x-b3-traceid
x-b3-spanid
x-b3-parentspanid
x-b3-sampled
x-b3-flags
x-ot-span-context
追踪数据生成规则配置
基于Telemetry CRD,ASM提供了如下图所示的图形化界面,简化定义分布式链路追踪数据的生成规则配置。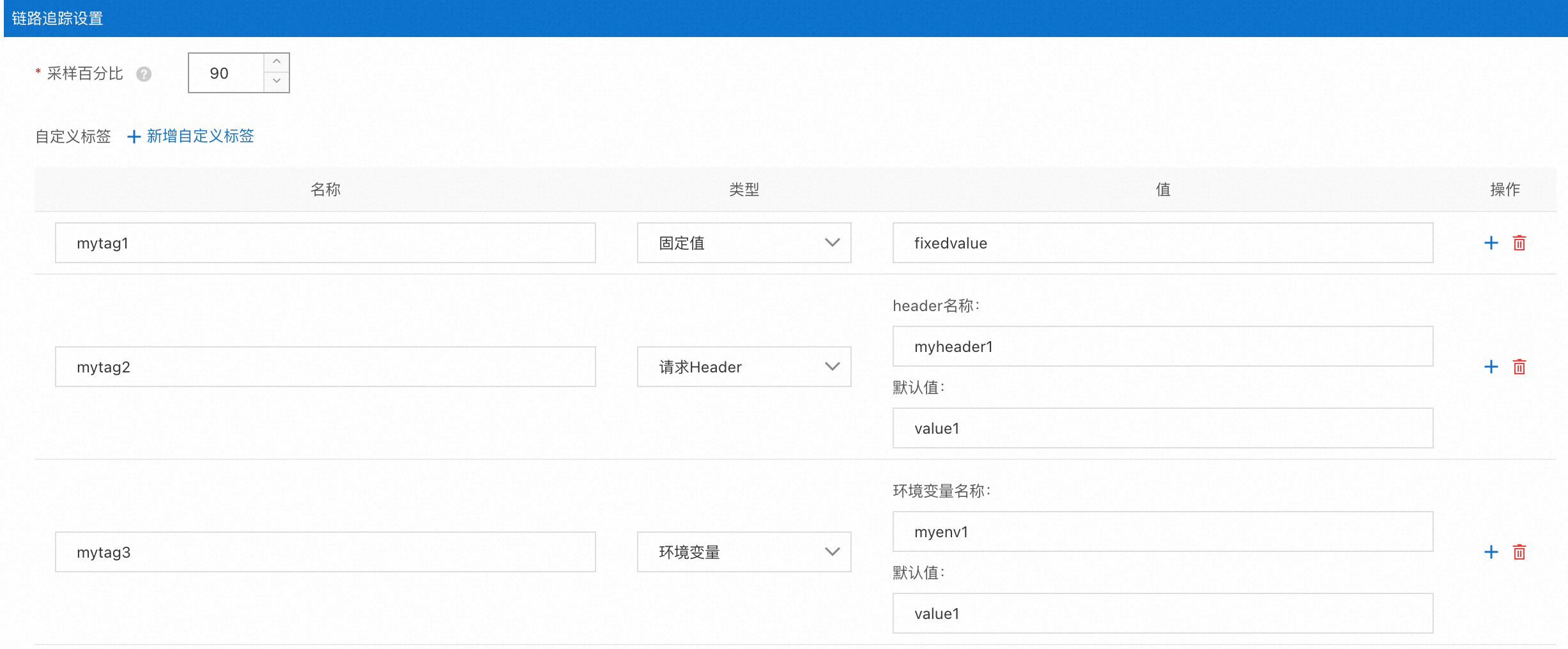
对应生成的定义内容如下:
tracing:
- customTags:
mytag1:
literal:
value: fixedvalue
mytag2:
header:
defaultValue: value1
name: myheader1
mytag3:
environment:
defaultValue: value1
name: myenv1
providers:
- name: zipkin
randomSamplingPercentage: 90追踪采集配置
若您需要将采集到的数据发送到云托管服务或者自建服务中,可以使用以下方式:
在云托管服务中,可以使用云原生应用管理服务来实现数据的收集和分析。具体操作,请参见在ASM中实现分布式跟踪。
在自建服务中,可以使用开源的数据收集和分析工具(例如Zipkin、Jaeger等)来实现数据的收集和分析。具体操作,请参见向自建系统导出ASM链路追踪数据。