
本文介绍数据库自治服务DAS(Database Autonomy Service)的Cost-based SQL诊断引擎。
背景信息
- 应用层面优化:应用代码逻辑优化,以更高效的方式处理数据。
- 实例层面优化:通过环境参数调整,优化实例的运行效率。
- SQL层面优化:通过物理数据库设计、SQL语句改写等优化手段,确保以最佳的方式获取数据。
开发者通常对于前面两个层面的优化比较熟悉,对于第三个即SQL层面的优化会有些生疏,甚至会因由谁(数据库管理员或应用开发者)来负责而产生争论,但SQL优化是整个数据库优化中非常关键的一环,线上SQL性能问题不仅会给业务带来执行效率上的低下,甚至是稳定性上的故障。
按照经验,约80%的数据库性能问题能通过SQL优化手段解决,但SQL优化一直以来都是一个非常复杂的过程,需要多方面的数据库领域专家知识和经验。
例如如何准确地识别执行计划中的瓶颈点,通过优化物理库设计或SQL改写等手段,让数据库优化器执行最佳计划。另外,由于SQL工作负载及其基础数据庞大且不断变化,SQL优化还是一项非常耗时且繁重的任务,这些都决定了SQL优化是一项高门槛、高投入的工作。
面临挑战
- 能力是否靠谱?
- 能力是否全面?
- 如何选择靠谱的优化推荐算法生成靠谱的建议?在SQL诊断优化领域,基于规则和基于代价模型是两种常被选择的优化推荐算法。
- 基于规则在目前许多产品和服务中,基于规则的推荐方式被广泛使用,特别是针对MySQL这种WHAT-IF内核能力缺失的数据库,因为该方式相对来说比较简单,容易实现,但另一面也造成了推荐过于机械化,推荐质量难以保证的问题,例如对如下简单SQL进行索引推荐:
基于规则,通常会首先生成如下四个候选索引:SELECT * FROM t1 WHERE time_created >= '2017-11-25' AND consuming_time > 1000 ORDER BY consuming_time DESC;IX1(time_created) IX2(time_created, consuming_time) IX3(consuming_time) IX4(consuming_time, time_created)但最终推荐给用户的是哪个(或哪几个,考虑index oring/anding的情况)索引呢?基于规则的方式很难给出精确的回答,会出现模棱两可的局面。在这个例子中,SQL只是简单的单表查询,那对于再复杂一点的SQL,例如多个表Join,以及带有复杂的子查询,情况又会如何呢?情况变得更糟糕,更加难以为继。
- 基于代价模型与基于规则不同,DAS中的SQL诊断优化服务采用的是基于代价模型方式实现,即采用和数据库优化器相同的方式去思考优化问题,最终会以执行代价的方式量化评估所有的(或尽可能所有的,因为是最优解求解的NP类问题,因此在一些极端情况下无法做到所有,只是实现次优)可能推荐候选项,最终作出推荐。即便是如此,但对于MySQL这样的开源数据库支持,还将面临其它不一样的挑战:
- WHAT-IF内核能力缺失:无法复用内核的数据库优化器能力来对候选优化方案进行代价量化评估。
- 统计信息缺失:候选优化方案的代价评估,其本质是执行计划的代价计算,统计信息的缺失便是无米之炊。
- 基于规则
- 如何具备足够的SQL兼容性?
SQL诊断优化服务如何做到SQL兼容性,其中包括SQL的解析以及SQL语义的验证,这直接关系到能力的全面性和诊断的成功率,它就像入场券,做不到做不全面都是问题。
- 如何构建具有足够覆盖度的能力测试集?
长期以来,SQL诊断优化能力的构建一直都是颇具挑战性的课题,挑战不仅在于如何融入数据库优化领域专家知识,还包括如何构建一个庞大的测试案例库用于其核心能力验证,它就像一把尺子可以衡量能力,同时又可以以此为驱动,加速能力的构建,因此在整个过程中,拥有足够覆盖度,准确的测试案例库是能力构建过程中至关重要的一环。
但构建足够好的测试案例库是一件非常困难的事情,挑战主要体现在两个方面:- 足够完备性保证:影响SQL优化的因素很多,例如影响索引选择的因素有上百个,加之各因素之间形成组合,这就形成了庞大的案例特征集合,如何让这些特征一一映射到测试案例也是非常庞大的工程。
- 测试案例设计需要专业知识且信息量大,例如对于单一测试案例设计也需要专业知识且测试案例中携带的信息量大,如索引推荐测试案例,它包括:
- schema设计:如表、已有索引、约束等。
- 各类统计信息数据。
- 环境参数等等。
- 如何构建大规模的诊断服务能力?
SQL诊断优化服务需要具备服务于云上百万级数据库实例的能力,其线上服务能力同样面临巨大挑战,例如如何实现复杂的计算服务化拆分,计算服务的横向伸缩,最大化的并行,资源访问分布式环境下的并发控制,不同优先级的有效调度消除隔离,峰值缓冲等等。
解决方案
SQL诊断优化服务是阿里云数据库自治服务DAS中最为核心的服务之一,它以SQL语句作为输入,由DAS完成诊断分析并提供专家优化建议(包括索引建议、语句优化建议以及预期收益等信息),用户不必精通数据库优化领域专家知识,即可获得SQL优化诊断、改写和优化相关的专家建议,最大化SQL执行性能。
另外,依托该能力,DAS的SQL自动优化服务将SQL优化推向了更高的境界,将重人工的被动式优化转变为以智能化为基础的主动式优化,以自优化的自治能力实现SQL优化的无人值守。
能力构建
面对上面提到的众多挑战,本文着重从DAS中的SQL诊断优化引擎核心技术架构以及能力测试集的构建两个维度进一步解读。
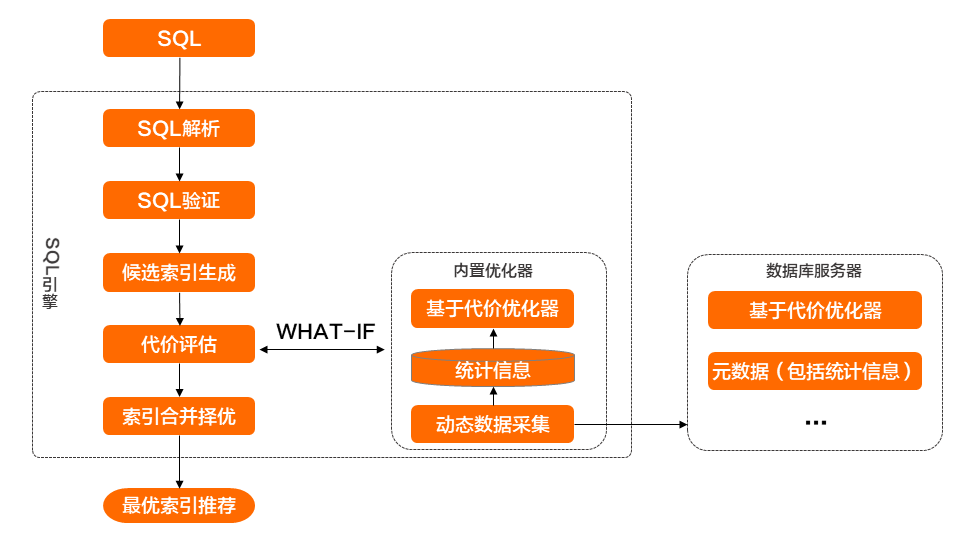
- SQL解析与验证:引擎对查询语句做解析验证,验证输入查询语句是否符合标准,识别查询语句的组成形成语法树,例如:谓词以及谓词类型、排序字段、聚合字段、查询字段等,识别查询语句相关字段的数据类型。验证SQL使用到的表、字段是否符合目标数据库的结构设计。
- 候选索引生成:依据解析验证后的语法树,生成多种候选索引组合。
- 基于代价评估:代价评估基于内置独立于数据库内核的优化器,获取数据库统计信息,在诊断引擎内部作缓存。诊断引擎内置优化器基于统计信息计算代价,评估每个索引的代价以及不同SQL改写方法下的代价评估,从而从代价选择最优索引或SQL改写方法。
- 索引合并与择优:引擎输入可以是一条查询语句,也可以为多个查询语句,或者整个数据库实例所有的查询语句。为多个查询语句做索引推荐,不同的查询语句的索引建议,以及已经存在的物理索引,有可能存在相同索引、前缀相同索引、雷同索引。
构建具有足够覆盖度的能力测试集,并以此为尺,度量能力,驱动能力构建。在这一过程中,如下图所示,DAS构建了以用例系统为中心的开发模式。
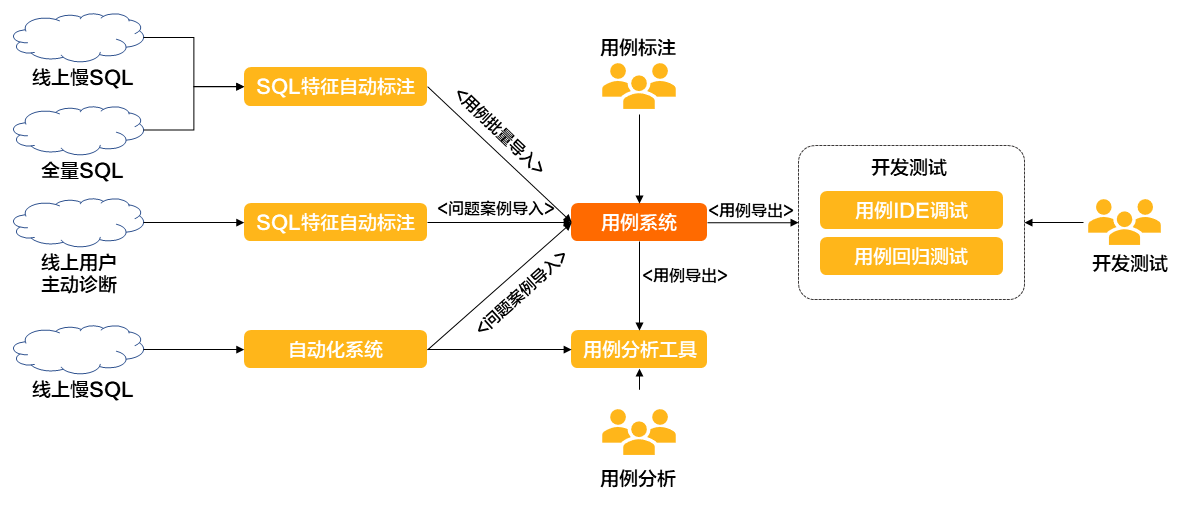
能力测试集构建的基本思想,首先通过特征化实现测试案例基于特征的形式化描述,形成测试案例形式化特征库,并具备足够的完备性。
- 哪些测形式化特征测试用例已被测试用例覆盖,完备度是多少?
- 哪些形式化特征测试用例,当前的诊断优化能力未覆盖?或测试验证失败?
- 在一段时间哪些测形式化特征测试用例出现频繁的回归问题?
- 各能力级的测试用例覆盖率怎样?
优化
- 自助优化:集团用户指定问题SQL,服务完成诊断并提供优化专家建议。
- 自动优化:自动优化服务自动识别业务数据库实例工作负载上的慢查询,主动完成诊断,生成优化建议,评估后编排优化任务,自动完成后续的优化上线操作及性能跟踪,形成全自动的优化闭环,提升数据库性能,持续保持数据库实例运行在最佳优化状态。
更为重要的是,SQL诊断优化服务已经构建了有效的主动式分析,反馈系统,线上诊断失败案例,用户反馈案例,自动优化中的回滚案例会自动回流到案例系统,一刻不停地驱动着诊断服务在快速迭代中成长。
支持的引擎
SQL诊断目前已支持的数据库引擎包括RDS MySQL、PolarDB MySQL版、RDS PostgreSQL和PolarDB PostgreSQL版(兼容Oracle)。