如您需进行文本分析、信息检索、文本挖掘与特征提取、构建搜索引擎、机器翻译、训练语言模型等场景应用,则可通过DataWorks的PyODPS节点使用开源结巴中文分词工具,将中文文本分割为词语,进行相关文本的分析处理。同时,若默认词库无法满足您的业务需要,您还可通过创建自定义词库来增加分词或修改分词结果。
背景信息
DataWorks提供的PyODPS节点支持直接编辑Python代码并使用MaxCompute的Python SDK进行数据开发。PyODPS节点分为PyODPS 2节点和PyODPS 3节点类型,PyODPS 3提供了更简洁易用的API接口,支持通过PIP直接安装,可以更好地利用MaxCompute的资源和特性,建议您使用PyODPS 3节点进行开发操作,详情请参见开发PyODPS 3任务。
PyODPS 3仅支持Python 3.x版本,PyODPS 2同时支持Python 2.x和Python 3.x版本,如您需要使用Python 2.x版本,则仅支持选择PyODPS 2节点。
本文的操作仅作为示例展示功能,不建议用于实际的生产环境。
前提条件
已创建DataWorks工作空间,详情请参见创建工作空间。
已创建MaxCompute计算资源并绑定至数据开发(DataStudio),详情请参见创建MaxCompute数据源并绑定至工作空间。
准备工作:下载开源结巴中文分词包
进入GitHub,按照下图指引下载开源结巴分词中文包。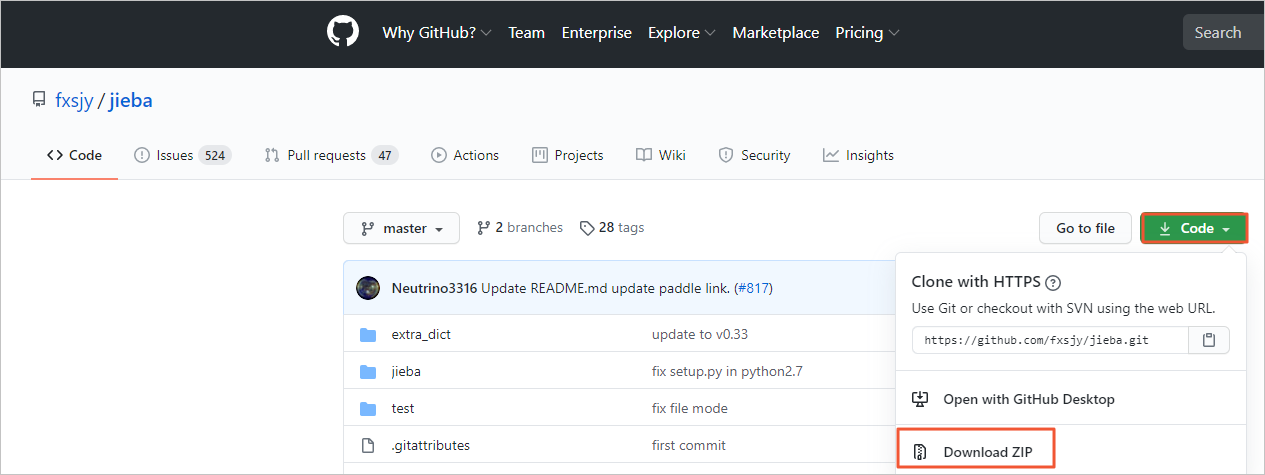
实践一:使用开源词包进行分词
创建业务流程,操作详情请参见创建业务流程。
创建MaxCompute资源并上传jieba-master.zip包。
右键单击创建的业务流程,选择。
在新建资源对话框中,配置各项参数,完成后单击新建。
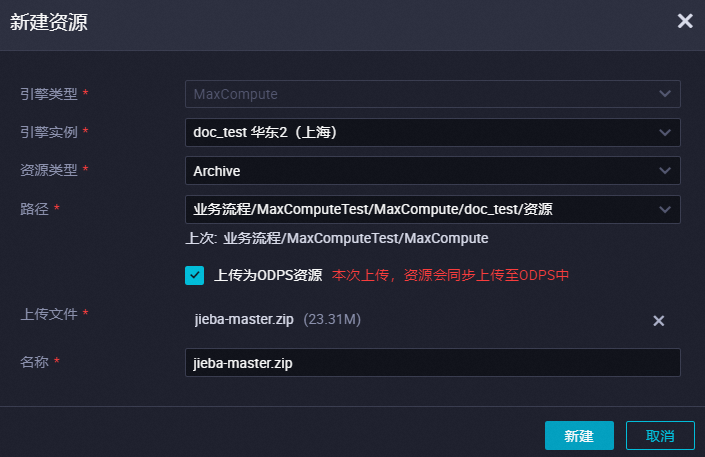 核心参数配置说明如下。
核心参数配置说明如下。参数
描述
上传文件
单击点击上传,根据界面提示选择已下载的jieba-master.zip文件。
名称
资源的名称,无需和上传的文件名保持一致,但需要符合命名规范。您可根据界面提示自定义资源名称,本实践名称示例配置为jieba-master.zip。
单击工具栏中的
 图标,根据界面提示提交新建的资源。
图标,根据界面提示提交新建的资源。
创建测试数据表jieba_test和测试结果表jieba_result。
右键单击创建的业务流程,选择,根据界面提示创建表,并使用DDL模式配置表的字段信息。创建完成后,提交表到开发环境。建表相关操作,详情请参见创建并使用MaxCompute表。
本实践需要创建的两个表的配置要点如下。
表名
DDL语句
作用
jieba_test
CREATE TABLE jieba_test ( `chinese` string, `content` string );用于存储测试的数据。
jieba_result
CREATE TABLE jieba_result ( `chinese` string ) ;用于存储分词测试结果数据。
下载测试数据并导入测试数据表jieba_test。
单击分词测试数据下载测试数据jieba_test.csv至本地。
在数据开发页面,单击
 图标。
图标。在将本地数据导入开发表对话框,输入需要导入数据的测试表jieba_test并选中,单击下一步。
上传您下载至本地的jieba_test.csv文件,配置上传信息并预览数据,单击下一步。
选中按名称匹配,单击导入数据。
创建PyODPS 3节点。
右键单击创建的业务流程,选择。
在新建节点对话框输入名称(示例为word_split),单击确认。
使用开源词包测试运行分词代码。
在PyODPS 3节点中运行下方示例代码,对上传至jieba_test表中的测试数据进行分词,并回显分词结果表的前十行数据。
def test(input_var): import jieba result = jieba.cut(input_var, cut_all=False) return "/ ".join(result) # odps.stage.mapper.split.size 可用于提高执行并行度 hints = { 'odps.isolation.session.enable': True, 'odps.stage.mapper.split.size': 64, } libraries =['jieba-master.zip'] # 引用您的 jieba-master.zip 压缩包 src_df = o.get_table('jieba_test').to_df() # 引用您的 jieba_test 表中的数据 result_df = src_df.chinese.map(test).persist('jieba_result', hints=hints, libraries=libraries) print(result_df.head(10)) # 查看分词结果前10行,更多数据需要在表 jieba_result 中查看说明odps.stage.mapper.split.size可用于提高执行并行度,详情请参见Flag参数列表。
查看运行结果。
运行完成后,您可通过如下方式查看结巴分词程序的运行结果:
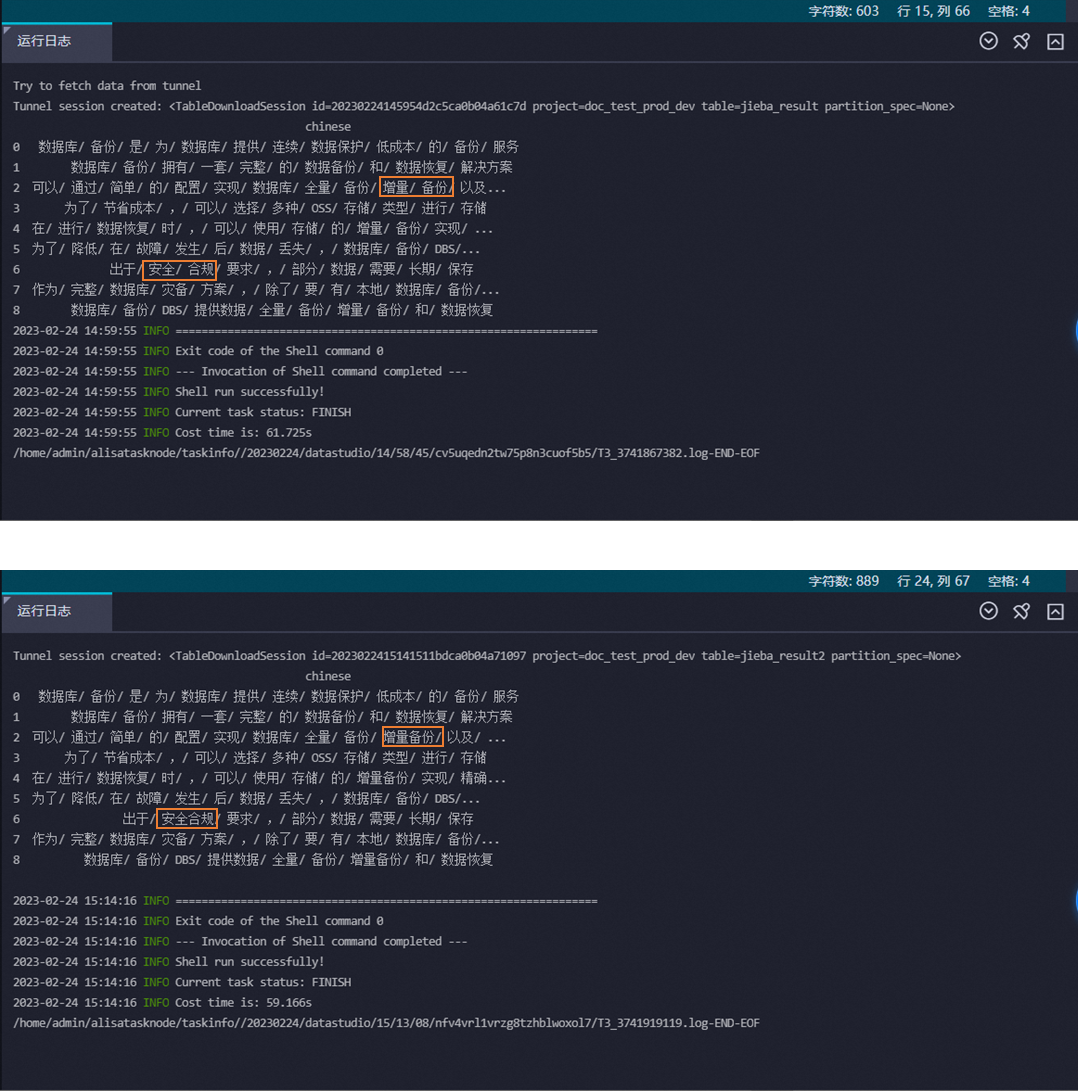
方式一:在页面下方的运行日志区域查看。
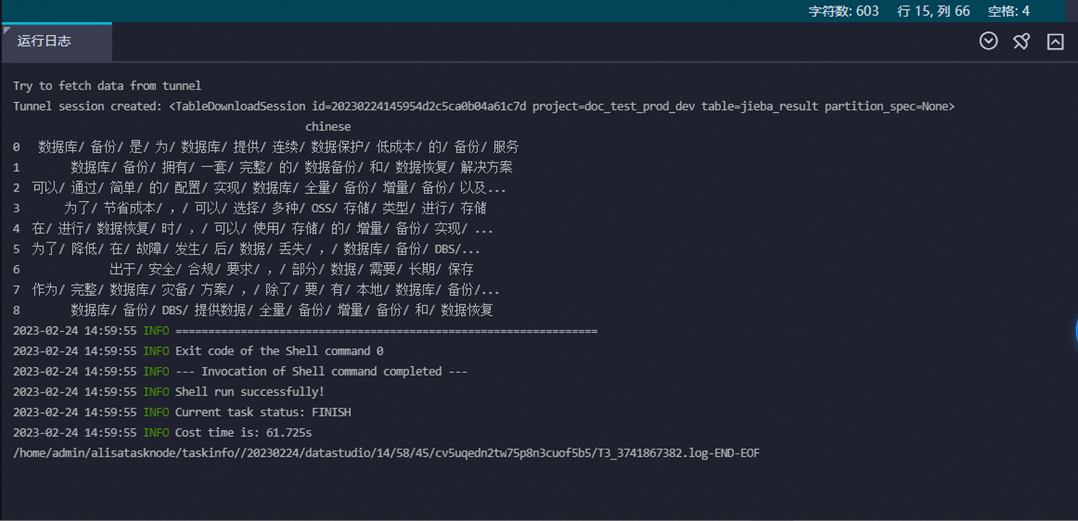
方式二:在页面左侧单击临时查询按钮,创建一个临时查询节点,查看测试结果表jieba_result中的结果数据。
select * from jieba_result;
实践二:使用自定义词库进行分词
如果开源结巴分词的默认词库无法满足您的需求,则您可使用自定义的词库对分词结果进行进一步修正,以下为您示例如何使用自定义词库进行分词。
创建MaxCompute资源。
PyODPS自定义函数可读取上传至MaxCompute的资源(表资源或文件资源),此时,自定义函数需要写为闭包函数或Callable类。
说明您可使用DataWorks的注册MaxCompute函数功能引用复杂的自定义函数,详情请参见创建并使用自定义函数。
本实践以使用闭包函数的方式,引用上传至MaxCompute的资源文件(即自定义词库)key_words.txt。
创建File类型的MaxCompute函数。
右键单击创建的业务流程,选择,输入资源名称key_words.txt后单击新建。
输入自定义词库内容并保存、提交。
以下为自定义词库的示例,您可根据自己的测试需求输入合适的自定义词库。
增量备份 安全合规
使用自定义词库测试运行分词代码。
在PyODPS 3节点中运行下方示例代码,对上传至jieba_test表中的测试数据进行分词,并回显分词结果表的前十行数据。
def test(resources): import jieba fileobj = resources[0] jieba.load_userdict(fileobj) def h(input_var): # 在嵌套函数h()中,执行词典加载和分词 result = jieba.cut(input_var, cut_all=False) return "/ ".join(result) return h # odps.stage.mapper.split.size 可用于提高执行并行度 hints = { 'odps.isolation.session.enable': True, 'odps.stage.mapper.split.size': 64, } libraries =['jieba-master.zip'] # 引用您的 jieba-master.zip 压缩包 src_df = o.get_table('jieba_test').to_df() # 引用您的 jieba_test 表中的数据 file_object = o.get_resource('key_words.txt') # get_resource() 引用 MaxCompute 资源 mapped_df = src_df.chinese.map(test, resources=[file_object]) # map调用函数,并传递 resources 参数 result_df = mapped_df.persist('jieba_result2', hints=hints, libraries=libraries) print(result_df.head(10)) # 查看分词结果前10行,更多数据需要在表 jieba_result2 中查看说明odps.stage.mapper.split.size 可用于提高执行并行度,详情请参见Flag参数列表。
查看运行结果。
运行完成后,您可通过如下方式查看结巴分词程序的运行结果:
方式一:在页面下方的运行日志区域查看。
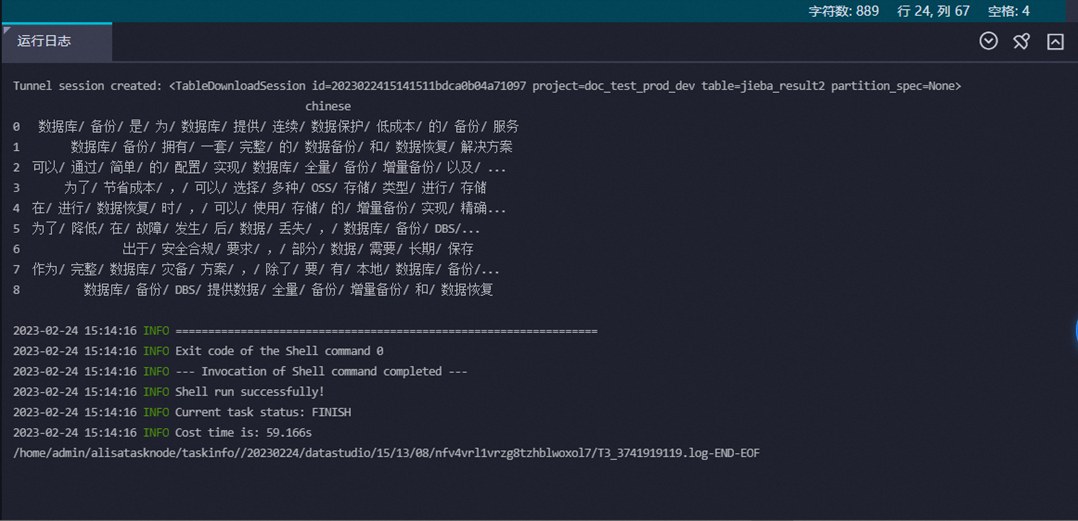
方式二:在页面左侧单击临时查询按钮,创建一个临时查询节点,查看测试结果表jieba_result2中的结果数据。
select * from jieba_result2;
对比自定义词库与开源词包的运行结果。