
DMS分类分级扫描能够对数据库中的敏感数据进行检测,并自动为符合识别规则的字段打上相应的分类分级标签,还可以保护高敏感等级的字段,并将敏感字段直观地展示在识别结果中。本文介绍DMS敏感数据保护分类分级扫描功能的原理。
原理介绍
DMS分类分级扫描由底层识别模型扫描和上层分类分级扫描组成。先使用识别模型扫描表中字段和数据,再使用分类分级扫描表中字段。其中,识别模型扫描可以识别数据信息类型,例如姓名、时间等。分类分级扫描则基于识别模型扫描的结果,通过实例关联的分类分级模板对字段进行业务归类,同时自动设置字段的安全级别和脱敏算法。
分类分级扫描基于识别模型扫描,但两者相互独立,互不干扰。
识别模型扫描
识别模型扫描支持如下两种识别方式:
数据内容识别(正则匹配)
通过识别模型匹配字段内容来对字段进行归类。例如识别模型名称为身份证,若字段数据符合身份证校验算法,则将该字段标记为身份证类型。
在进行数据内容识别时,DMS会随机采样部分数据进行识别,以保证识别效率;当采样数据中符合识别模型要求的数据量大于特定阈值时,系统可以确定该字段为身份证类型。
元数据识别
通过识别模型匹配字段名称,对字段进行归类。例如,当DMS内置的身份证识别模型识别到表中字段名称为id_card时,会将该字段标记为身份证类型。
识别结果
每个字段可对应多个识别结果。例如识别模型手机号与11位数字均可识别手机号内容。对于单个字段,DMS最多保存3个识别结果。
DMS内置部分识别模型,用户也可以自定义识别模型。自定义识别模型仅支持数据内容识别。
识别模型有禁用和启用(默认)两种状态。仅已启用的识别模型,会被系统逐一应用到字段进行识别。
分类分级扫描
分类分级扫描会将待扫描的字段与分类规则进行一一匹配。若字段符合分类规则的定义,则标记为该字段的分类规则。
分级分类原理
首先筛选出分类分级模板中所有已启用的分类规则,再针对单个识别规则,分以下三步进行识别:
根据字段识别模型的扫描结果,判断分类规则中是否包含识别模型。
例如识别模型为识别模型A、识别模型B,分类规则定义的识别模型为识别模型B、识别模型C,则系统会取两者交集识别模型B,并认为该分类规则包含字段的识别模型,继续识别下一个规则。若分类规则中没有命中的识别模型,则认为识别失败,继续识别下一个规则。
根据字段的元数据(库名、表名、字段名及字段备注)进行识别范围判断。
判断该字段的数据是否在识别范围内。若存在,则将该分类暂存至字段的分类结果中,继续选取下一个分类规则对字段进行识别。
标记字段的分类。
当使用所有分类规则对字段进行识别后,仅有一个符合要求的规则,则标记为该字段的分类。若字段符合多种分类规则,则根据规则的安全级别进行排序(由低到高),最终选定安全级别最高的分类。
如下为单个字段的分类分级扫描过程:

识别规则基本信息说明
在分类分级扫描前,您可以自定义分类分级识别规则。如下为部分重要参数说明:
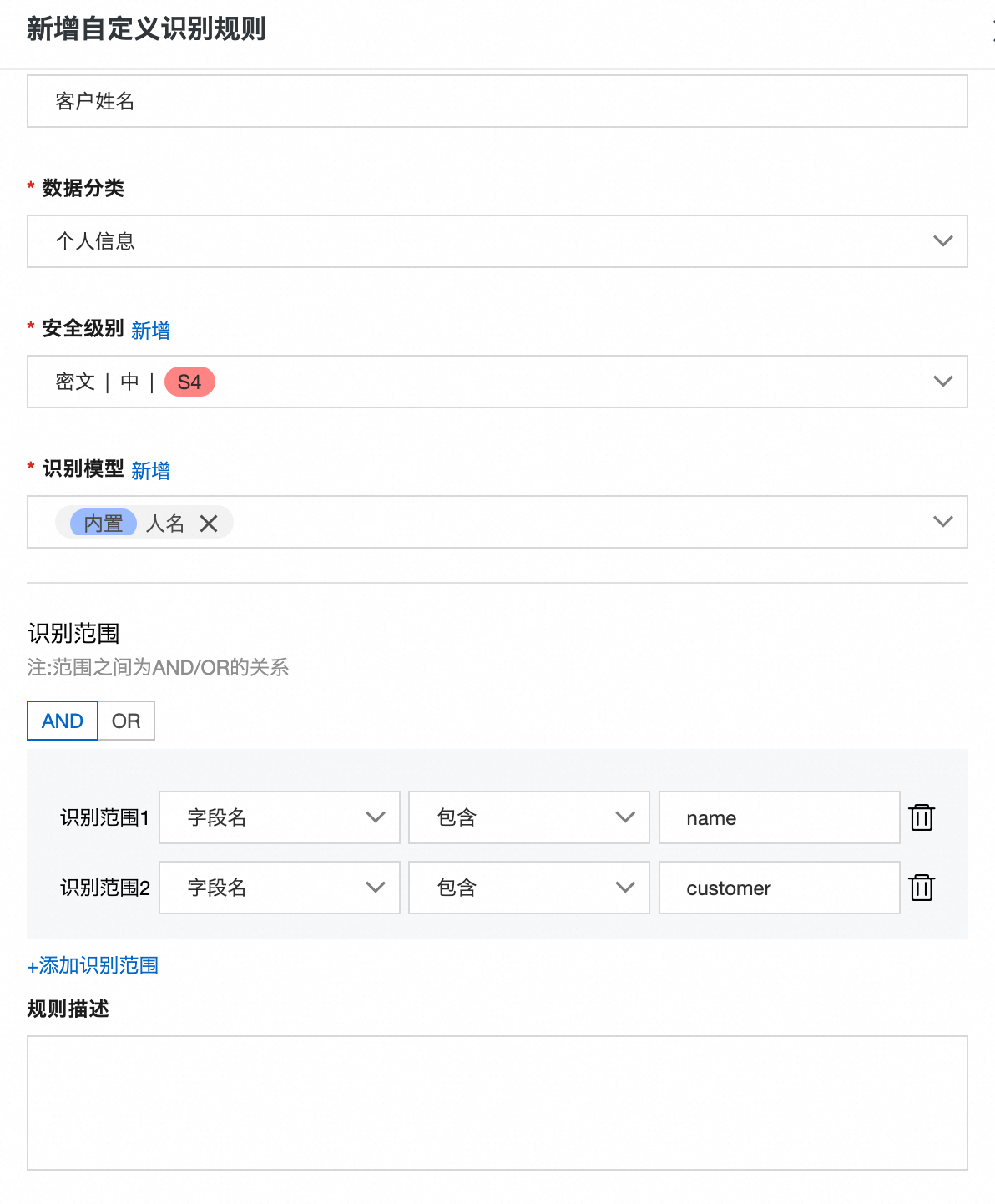
安全级别:用户可自定义字段的安全级别,等级越高表示数据越敏感、越重要。更多信息,请参见字段安全级别。
识别模型:该识别规则对应的底层识别模型,可多选,逻辑关系为OR。例如某一字段命中了多个识别模型,只要该规则的识别模型中包含其中一种即可。
识别范围:筛选元数据。识别范围之间的关系包含AND或OR,若为AND,则字段的元数据必须符合所有的识别范围;若为OR,则字段元数据符合其中一种即可。