
IDP-SDK是阿里云docmind服务提供的一种文档智能解析服务包装的Python SDK,能够将文档转换为结构化的对象格式,并通过SDK快速操作清理需要的数据内容,方便对接包括langchain、llamaindex等框架场景。
IDP-SDK 介绍
什么是IDP-SDK
IDP-SDK是阿里云docmind服务提供的一种文档智能解析服务包装的Python SDK,能够将文档转换为结构化的对象格式,并通过SDK快速操作清理需要的数据内容,方便对接包括langchain、llamaindex等框架场景。
IDP-SDK功能特点
提供DocMind文档结构化输出的doc-json结果反序列化对象,以及辅助功能函数SDK。
使用场景
文档智能解析调用
版本号 | 说明 |
1.0.0 | 提供文档智能解析、电子解析、文档解析(大模型)版本接口调用统一封装的python版本 |
环境选择
云上调用参考文档《服务入口》配置环境变量:
ALIBABA_CLOUD_ACCESS_KEY_ID=YOUR_ALIBABA_CLOUD_ACCESS_KEY_ID
ALIBABA_CLOUD_ACCESS_KEY_SECRET=YOUR_ALIBABA_CLOUD_ACCESS_KEY_SECRET
集成方式
Python 3.9以上环境
pip install https://docmind-api-cn-hangzhou.oss-cn-hangzhou.aliyuncs.com/sdk/doc_json_sdk-1.0.2-py3-none-any.whl使用说明
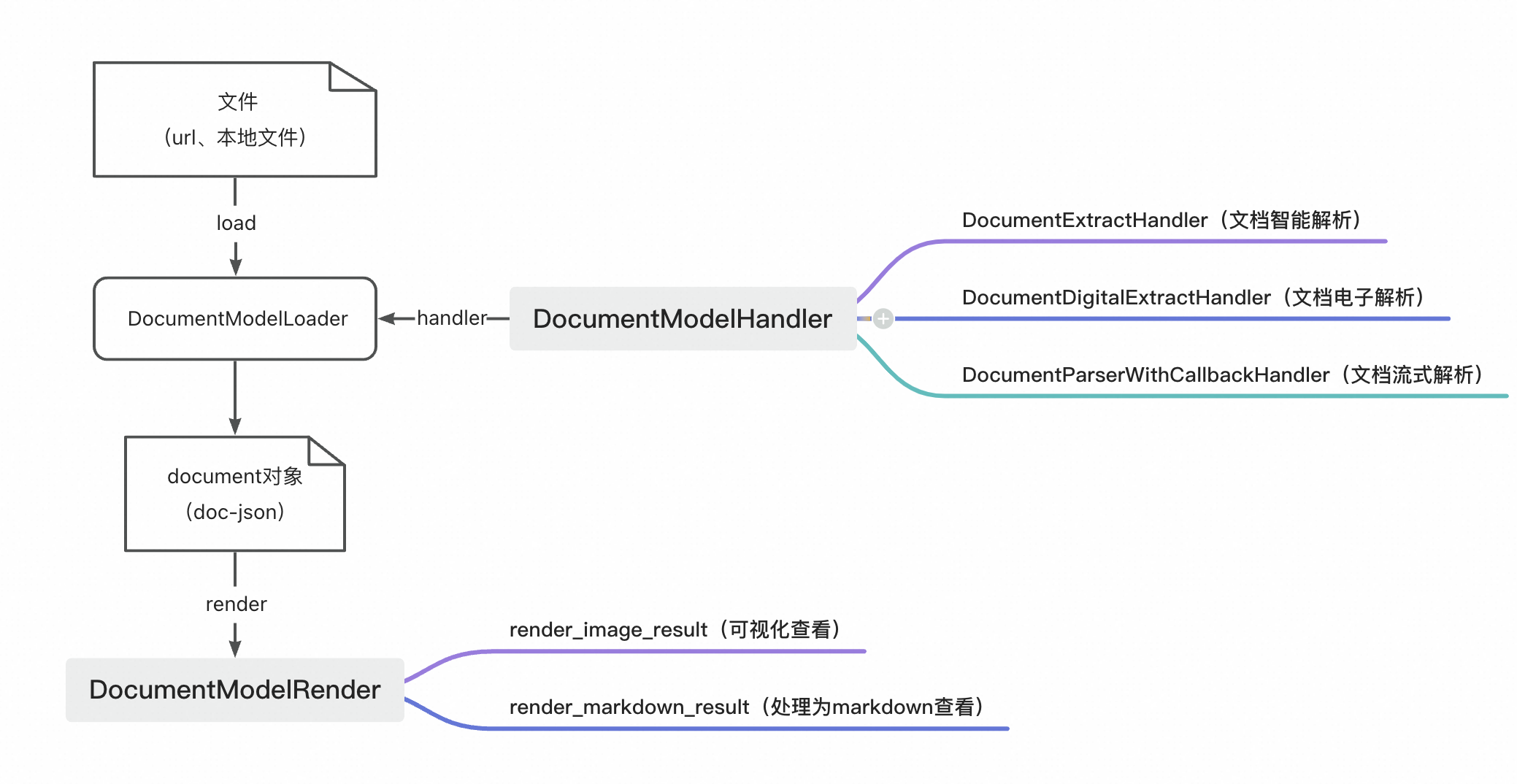
SDK使用中主要使用流程为load文件,通过不同的handler方法处理文件,处理为document对象,包含对于layout版面、text/markdown文本信息、图片/表格信息、文字样式信息、doctree层级信息等,通过render可将解析处理的结果单独输出为markdown信息。
公有云环境调用
公有云环境调用
(配置ALIBABA_CLOUD_ACCESS_KEY_ID,ALIBABA_CLOUD_ACCESS_KEY_SECRET)环境变量
from doc_json_sdk.loader.document_model_loader import DocumentModelLoader
from doc_json_sdk.handler.document_handler import DocumentExtractHandler, DocumentDigitalExtractHandler
def test_document_hander():
file_path = "" # your local file
file_url = None
# DocumentExtractHandler:文档智能解析
# DocumentDigitalExtractHandler:文档电子解析
loader = DocumentModelLoader(handler=DocumentExtractHandler())
document = loader.load(file_path=file_path, file_url=file_url)
公有云环境增加公式调用
from doc_json_sdk.loader.document_model_loader import DocumentModelLoader
from doc_json_sdk.handler.document_handler import DocumentExtractHandler
def test_render_formula_markdown():
file_path = "" # your local file
file_url = None
handler = DocumentExtractHandler()
loader = DocumentModelLoader(handler=handler)
document = loader.load(file_path=file_path,file_url=file_url,
formula_enhancement=True,
reveal_markdown=True,
save_json_path="docmind_result.json")doc-json字符串对象加载
from doc_json_sdk.loader.document_model_loader import DocumentModelLoader
def test_local_json_document():
file_path = "" # your local file
loader = DocumentModelLoader()
document = loader.load(doc_json_fp=open(file_path, "r"))处理文件为Markdown字符串
from doc_json_sdk.loader.document_model_loader import DocumentModelLoader
from doc_json_sdk.handler.document_handler import DocumentExtractHandler,DocumentDigitalExtractHandler
from doc_json_sdk.render.document_model_render import DocumentModelRender
def test_render_markdown():
file_path = "" # your local file
file_url = None
loader = DocumentModelLoader(handler=DocumentExtractHandler())
document = loader.load(file_path=file_path, file_url=file_url, reveal_markdown=True)
render = DocumentModelRender(document_model=document)
with open("docmind_result.md", "w") as f:
f.write(render.render_reveal_markdown())根据layout版面对象过滤处理
from doc_json_sdk.model.enums.layout_type_enum import LayoutTypeEnum
for layout in document:
type_enum = layout.get_layout_type_enum()
if (type_enum == LayoutTypeEnum.Elements.FOOTER or
type_enum == LayoutTypeEnum.Elements.HEADER or
type_enum == LayoutTypeEnum.Elements.NOTE):
# header and footer notes
pass
elif type_enum == LayoutTypeEnum.Elements.IMAGE:
# image with head_line or split_line
if layout.type.find("_line")!=-1:
continue
elif type_enum == LayoutTypeEnum.Elements.TABLE:
#table
pass
else:
# paragraph or note(table or figure)
pass该文章对您有帮助吗?