
本文为您介绍EMR Serverless StarRocks的架构。
EMR Serverless StarRocks架构

EMR Serverless StarRocks的产品架构主要由以下三个层次构成:
存储层:
存算一体版:StarRocks内表使用云盘或本地盘作为数据存储的介质,使用StarRocks Table Format存储格式。
存算分离版:StarRocks内表使用对象存储或HDFS等数据湖存储,使用StarRocks Table Format存储格式。
数据湖分析版:通过StarRocks外部表,直接读取数据湖(例如对象存储或HDFS)中的Hive格式或湖格式的数据,采用DataLake Table Format。
StarRocks实例:
全部实例(包括前端FE,后端BE或CN)都在云端托管,实现免运维。
通过计算组(Warehouse)可以进行资源灵活配置及隔离。
通过弹性能力可以确保低成本的资源使用,降低资源成本。
通过缓存机制能显著提升存算分离或数据湖分析的查询速度,同时,产品自带的StarRocks缓存管理功能进一步助力您高效地进行缓存调优。
产品能力:
实例运维:提供无需运维的实例管理功能,包括资源与配置管理、告警、健康报告和自动升级等,提升运维效率与系统稳定性。
数据运维:提供即开即用的数据管理能力,例如可视化SQL编辑器、导入任务、慢查询、数据审计、元数据管理以及权限配置等能力。
基于以上产品能力,您可以更加高效地聚焦于自己的业务应用,例如运营分析、用户画像、自助报表、订单分析以及用户报表生成等方面。
StarRocks系统架构
StarRocks架构的核心只有FE(Frontend)、BE(Backend)或CN(Compute Node)节点,方便部署与维护。节点可以在线水平扩展,元数据和业务数据都有副本机制,确保整个系统无单点。StarRocks提供MySQL协议接口,支持标准的SQL语法,您可以通过MySQL客户端方便地查询和分析StarRocks中的数据。
随着StarRocks产品的发展,系统架构从存算一体(shared-nothing)进化到存算分离(shared-data)。
在3.0版本更新前,StarRocks采用存算一体架构,其中BE节点负担着数据的存储和计算任务,所有数据访问和分析操作都直接在本地节点完成,以确保快速响应的查询性能。
自3.0版本起,StarRocks开始采纳存算分离架构,转变了数据存储的方式。原有的BE节点得到升级改造成为无状态的计算节点(CN),并将数据持久化存储迁移至远端对象存储服务或HDFS。在这一新架构下,CN节点的本地磁盘主要用于缓存经常访问的热数据,进而提高查询处理的速度。存算分离架构的优势在于支持计算节点的动态添加或删除,实现了更灵活高效的扩缩容功能。
如下图所示,是从存算一体向存算分离架构演进的形象展示。
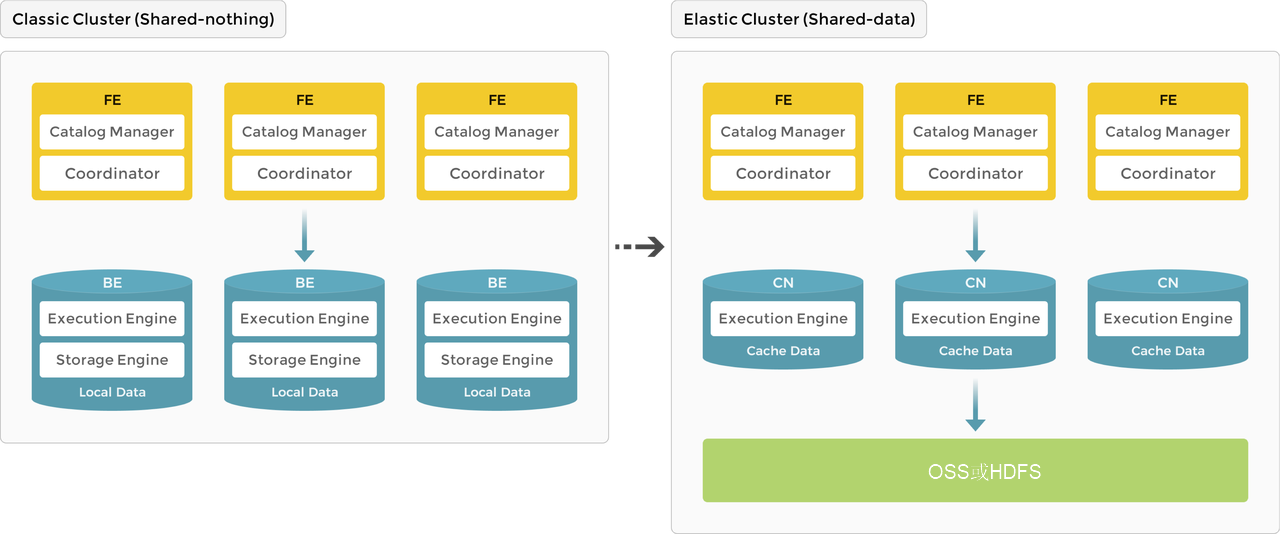
本文部分内容和图片来源于社区StarRocks的系统架构。
存算一体
StarRocks 3.0版之前采用的是存算一体(shared-nothing)架构,这是其作为MPP数据库的显著特点。在这种架构中,BE节点负责数据的存储与计算。在查询时可以直接读取本地数据进行计算,极大地提升了查询的速度,有效避免了数据传输和拷贝的延迟。此外,存算一体支持多副本数据存储,提高了并发查询能力和数据的可靠性,非常适合对查询性能要求极高的场景。
在StarRocks的存算一体架构中,系统主要由前端节点(FE)和后端节点(BE)两种类型的节点构成。
FE
FE负责管理元数据、管理客户端连接、查询规划和调度等工作,并在每个节点的内存中保存一份完整的元数据副本,以确保服务的一致性。
角色 | 元数据读写 | Leader选举 | 说明 |
Leader | 读写 | 自动选举 | Leader FE在对元数据进行读写操作后,通过BDB JE (Berkeley DB Java Edition) 同步变更至Follower和Observer。Leader由Follower节点中选举产生,如果Leader失败,其他Follower将进行新一轮选举。 |
Follower | 只读 | 参与 | Follower只有元数据的读取权限,并通过Leader的元数据日志来异步同步数据。Follower节点也参与Leader的选举,选举过程基于BDB JE协议,并要求超过半数的Follower节点正常运行。 |
Observer | 只读 | 不参与 | Observer节点与Follower具有相同的读取权限,并进行异步数据同步,但不参与Leader选举。Observer的主要目的是增强集群的查询并发能力,并不给集群选举带来额外负担。 |
BE
BE负责SQL计算和数据存储的任务,采用本地存储和多副本机制以提高系统的可用性。
数据存储: BE节点在存储方面完全均等,没有主次之分。数据由前端节点(FE)根据特定政策分配到各个BE节点,其中BE节点负责将接收的数据转换成可存储的格式并创建相应的索引。
SQL计算: 对于SQL查询的处理,BE节点首先将SQL语句按照语义规划成逻辑执行单元,然后再根据数据的分布情况拆分成具体的物理执行单元。这些物理执行单元直接在指定的BE节点上执行,实现了数据计算的本地化,避免了不必要的数据传输和复制,从而极大的提升了查询性能。
尽管存算一体架构在查询性能上具有显著优势,但也存在一些局限性:
成本高:为了确保数据的可靠性,BE节点必须使用多副本,特别是三副本机制,这随着数据量的增加会导致存储资源的持续扩充,可能会造成计算资源的浪费。
架构复杂:多副本的维护要求高一致性,这使得存算一体架构变得更加复杂,提高了管理和维护的难度。
弹性不足:在存算一体模式下,扩缩容往往伴随着数据重新平衡的过程,可能会影响弹性使用体验。
存算分离
StarRocks存算分离架构是在存算一体的基础上将计算和存储进行解耦。在这种模式中,数据持久化存储转移到了成本更优化且可靠性更高的远程对象存储(例如OSS)或HDFS上。计算节点(CN)所在的本地磁盘主要用作缓存,以加速对高频访问数据的查询。当本地缓存得到命中时,存算分离模式能够提供与存算一体相当的查询速度。
存算分离模式下,您可以动态地添加或移除计算节点,实现秒级别的扩缩容,有效降低了数据存储与资源扩展的成本,并促进资源隔离及计算资源的弹性伸缩。此模式类似于存算一体,整个系统依旧由前端(FE)和计算节点(CN)两种服务进程构成,需要您额外配置的仅是后端的对象存储。
在StarRocks存算分离架构中,FE节点的角功能保持不变,而BE节点转变为无状态的CN节点,其仅缓存热数据,负责数据导入、查询计算和缓存数据管理等任务。
存储
StarRocks的存算分离技术目前支持以下后端存储解决方案,您可以根据需求灵活选择:
阿里云OSS对象存储。
HDFS,包括自建Hadoop或阿里云EMR DataLake集群。
在数据格式方面,StarRocks存算分离的数据文件与存算一体保持一致,并支持各种索引技术,其中元数据(例如TabletMeta)经过重新设计以更好地适应对象存储环境。
缓存
为了优化查询性能,StarRocks构建了层级分明的数据缓存体系。热数据存放在内存,确保快速可达;次热数据则存放在本地磁盘;而冷数据则位于远端的对象存储中。数据会根据访问频率在这三个层次中流转。
在查询操作中,通常来说热数据会直接从缓存中获取,冷数据需要从后端对象存储中读取并缓存至本地,以便加快后序访问速度。通过内存、本地磁盘及远程存储的联合,StarRocks构建了多层数据访问体系,您可以自定义数据冷热规则以优化业务需求,实现了高效计算与成本可控的存储。
您在建立表时可以选择是否开启缓存。开启缓存后,数据将在写入过程中同时存放到本地磁盘以及后端对象存储中。在查询时,CN节点会优先读取本地磁盘中的数据,若本地缓存未命中,则从后端对象存储获取原始数据,并将其缓存至本地磁盘,以优化后续的访问速度。对于未缓存的冷数据,StarRocks还针对性地进行了优化,结合应用的访问模式,通过预读技术和并行扫描等策略,降低了对远端对象存储访问的频率,进一步提升了查询效率。