
本文档提供了实例和计算组的监控方法、云监控关键指标、告警配置方案以及运维示例,旨在帮助您有效监测和诊断系统性能。
监控实践
实例监控
该页面主要展示实例的整体运行情况,主要包括 Query、FE、资源组、物化视图、库表信息等监控信息。
请根据以下要点对实例进行监控和观察:
定期关注概况区域信息,以便迅速掌握运行状态。
各分组图表可根据需要进行查阅。
支持查看单个前端(FE)的监控情况。
通过快速选择时间范围,发现问题,然后缩小时间范围以查看异常指标。
计算组监控
该页面主要展示BE或CN的监控图表,主要包括Compaction、BE或CN、Cache、存储等监控信息。
请根据以下要点对实例进行监控和观察:
定期关注概况区域信息,以便迅速掌握运行状态。
重点关注CPU、MEM和磁盘水位,必要时进行资源升级或扩容。
其他监控分组可根据需求查阅。
支持查看单个BE或CN的监控情况。
通过快速选择时间范围,发现问题,然后缩小时间范围以查看异常指标。
告警实践
云监控指标
云监控页面提供了丰富的StarRocks监控指标,推荐优先使用以下指标。
指标类别 | 指标名称 | 监控指标 | 描述 |
指标类别 | 指标名称 | 监控指标 | 描述 |
可用性 | FE节点状态探测 | serverless_starrocks_fe_up | 请求节点HTTP接口的结果,1表示请求成功,0表示请求失败,可用于探测FE节点状态。 |
BE/CN节点状态探测 | serverless_starrocks_be_up | 请求节点HTTP接口的结果,1表示请求成功,0表示请求失败,可用于探测BE或CN节点状态。 | |
性能 | CPU使用率 | serverless_starrocks_cpu_util | CPU使用率,计算方式为排除idle、wait、steal后的占比。 |
内存使用率 | serverless_starrocks_mem_util | 内存使用率。 | |
磁盘使用率 | serverless_starrocks_be_disks_utilization | 磁盘已使用大小。单位:Byte。 | |
网络 | 网络接收字节数 | serverless_starrocks_be_network_receive_bytes | 网络接收的字节数。 |
网络发送字节数 | serverless_starrocks_be_network_send_bytes | 网络发送的字节数。 | |
总连接数量 | serverless_starrocks_fe_connection_total | FE的总连接数量。 | |
查询 | 每分钟查询失败数 | serverless_starrocks_fe_query_err_increase | 每分钟查询失败的数量。 |
查询耗时统计 | serverless_starrocks_fe_query_latency_ms_p75 serverless_starrocks_fe_query_latency_ms_p95 serverless_starrocks_fe_query_latency_ms_p99 | 查询百分位统计延迟。单位:ms。 云监控百分位(例如0.75、0.95等)通过quantile标签进行区分。 | |
慢查询数 | serverless_starrocks_fe_slow_query_increase | 每分钟增长的慢查询数量。 | |
资源组查询耗时统计 | serverless_starrocks_fe_query_resource_group_latency | 资源组维度的查询耗时指标。 | |
集群状态 | 最大Compaction Score | serverless_starrocks_fe_tablet_max_compaction_score | 通常,Compaction Score大于1000时就会报错,StarRocks会报错 “Too many versions”。建议调低导入并发和导入频率。 |
物化视图 | 物化视图状态 | serverless_starrocks_fe_mv_inactive_state | 物化视图的状态。有效值:
|
物化视图作业刷新失败数量 | serverless_starrocks_fe_mv_refresh_total_failed_jobs | 执行失败的物化视图刷新作业的数量。 | |
物化视图等待作业数量 | serverless_starrocks_fe_mv_refresh_pending_jobs | 当前等待执行的物化视图刷新作业数量。 |
告警配置方案
场景 | 告警配置方案 |
场景 | 告警配置方案 |
场景一:查询量较大,业务场景单一 |
|
场景二:查询场景复杂,Query Err数量和Query延迟不能有效反映集群状态,仅需关注实例状态 |
|
场景三:其他场景 | 按需配置,根据具体业务需求进行灵活调整。 |
运维示例
1、配置告警
进入告警设置页面。
在左侧导航栏,选择。
在实例列表页面,单击目标实例ID。
单击监控告警。
单击左侧的告警设置。
在告警设置页面,单击报警规则设置。

跳转到云监控页面,可以对当前的报警规则执行修改、删除和禁用等操作,详情请参见管理报警规则。
创建报警规则。
在报警规则页面,单击创建报警规则。
在创建报警规则面板,配置以下信息,单击确认。
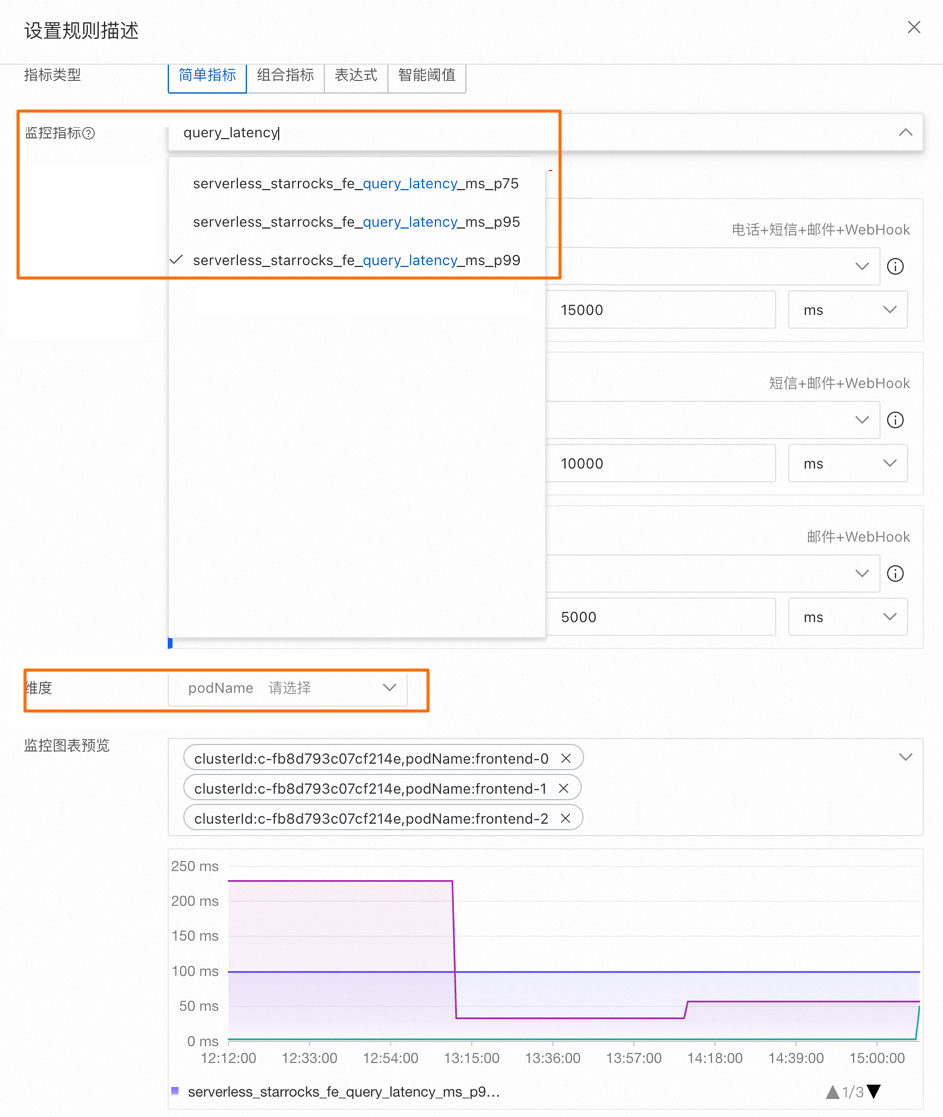
参数
说明
参数
说明
产品
选择E-MapReduce(全托管starrocks)。
资源范围
选择实例。
关联资源
单击添加实例,选择已有的StarRocks实例。
规则描述
选择,设置规则名称,选择监控指标和维度,配置阈值规则,然后单击确定。
2、接收告警
在收到查询耗时超阈值的监控告警后,请登录控制台排查问题。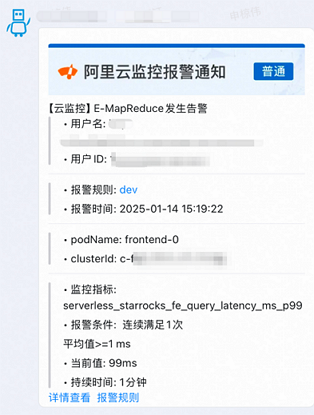
3、监控排查
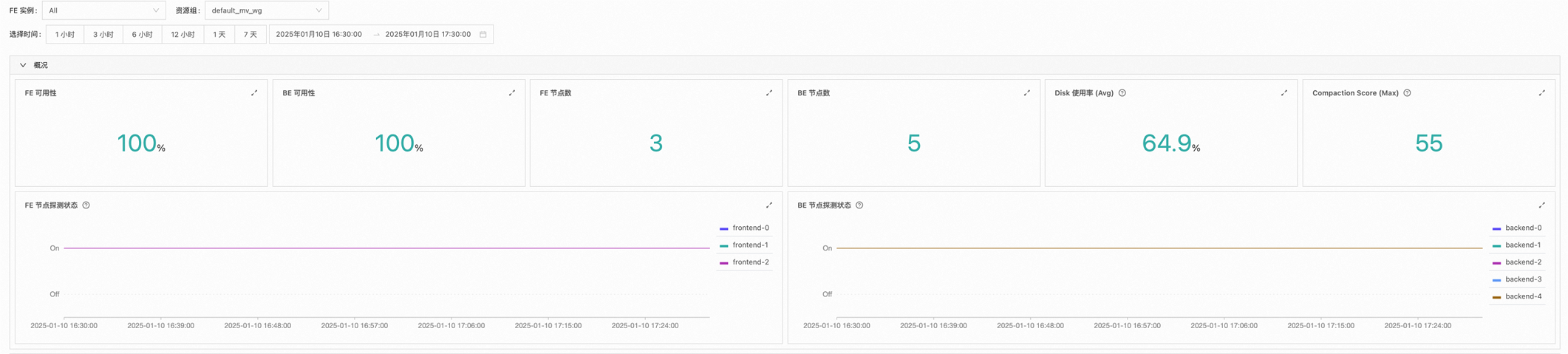
在监控告警的实例页面,查看概况区域,以确认是否存在问题。
查看Query区域,发现查询耗时异常增长。
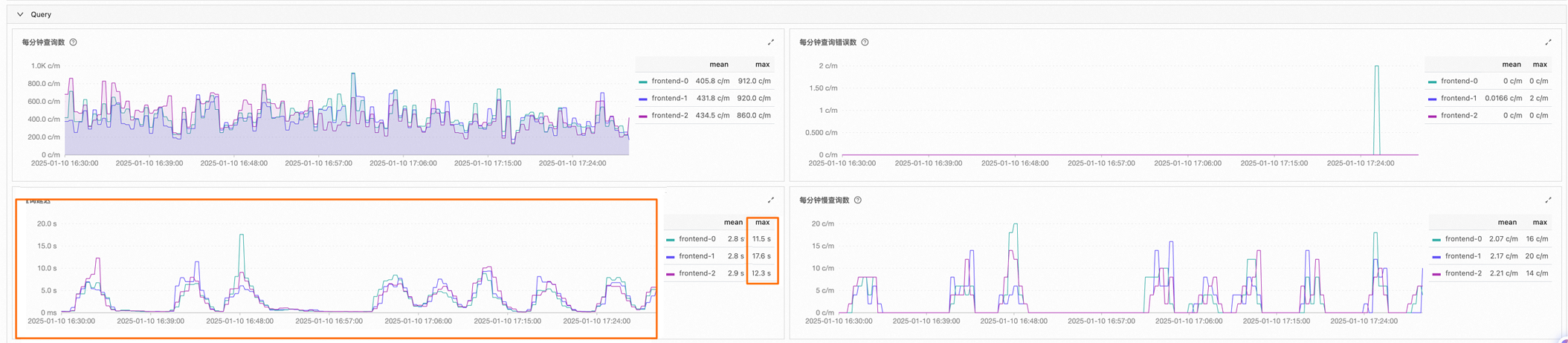
在监控告警的计算组页面,查看BE监控图标。
查看BE CPU,发现负载处于正常范围内。

查看BE Mem状态,发现各项内存指标基本正常,无明显波动。
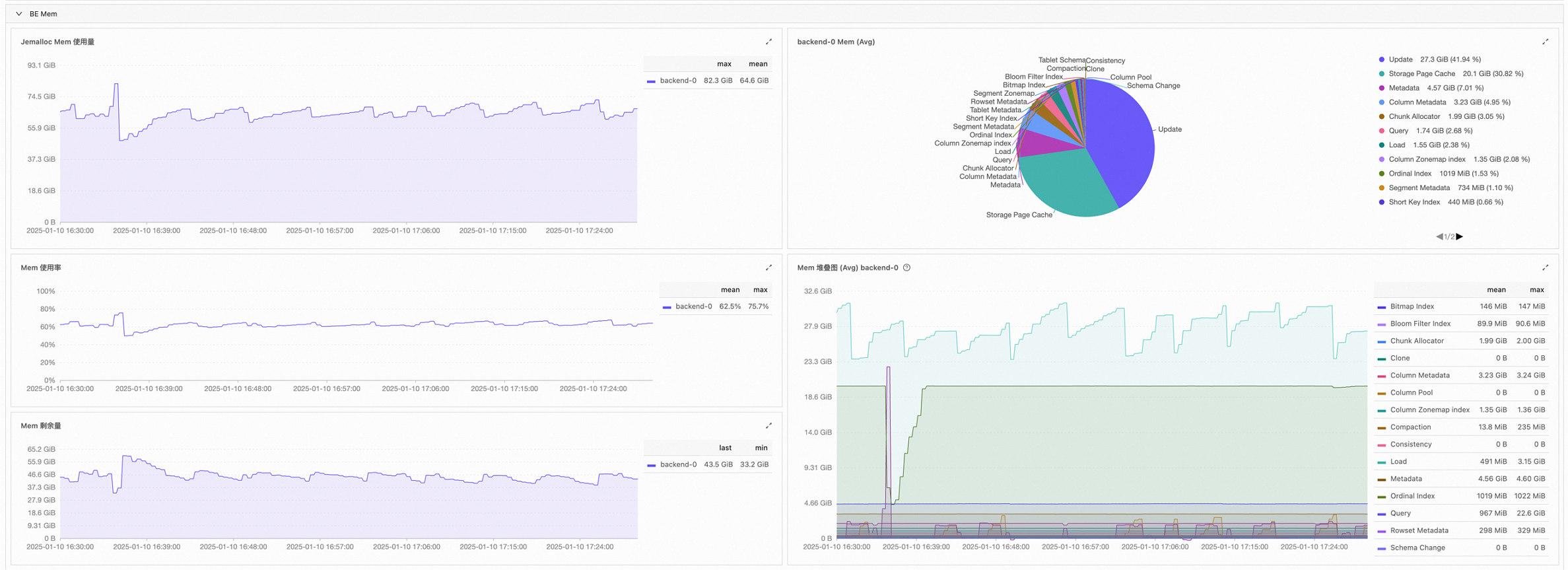
查看BE Disk IO,发现吞吐量已达到瓶颈,并与问题曲线呈现相似趋势,推测查询耗时增加的直接原因是存在大查询。

4、实时诊断与问题定位
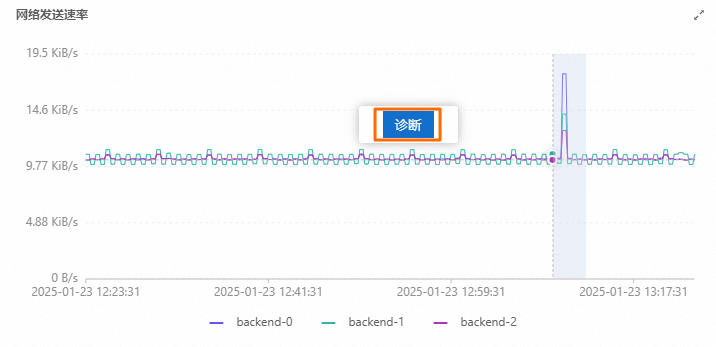
在健康诊断页面的实时诊断页签,使用鼠标拖动选择异常时间区间,然后单击诊断。
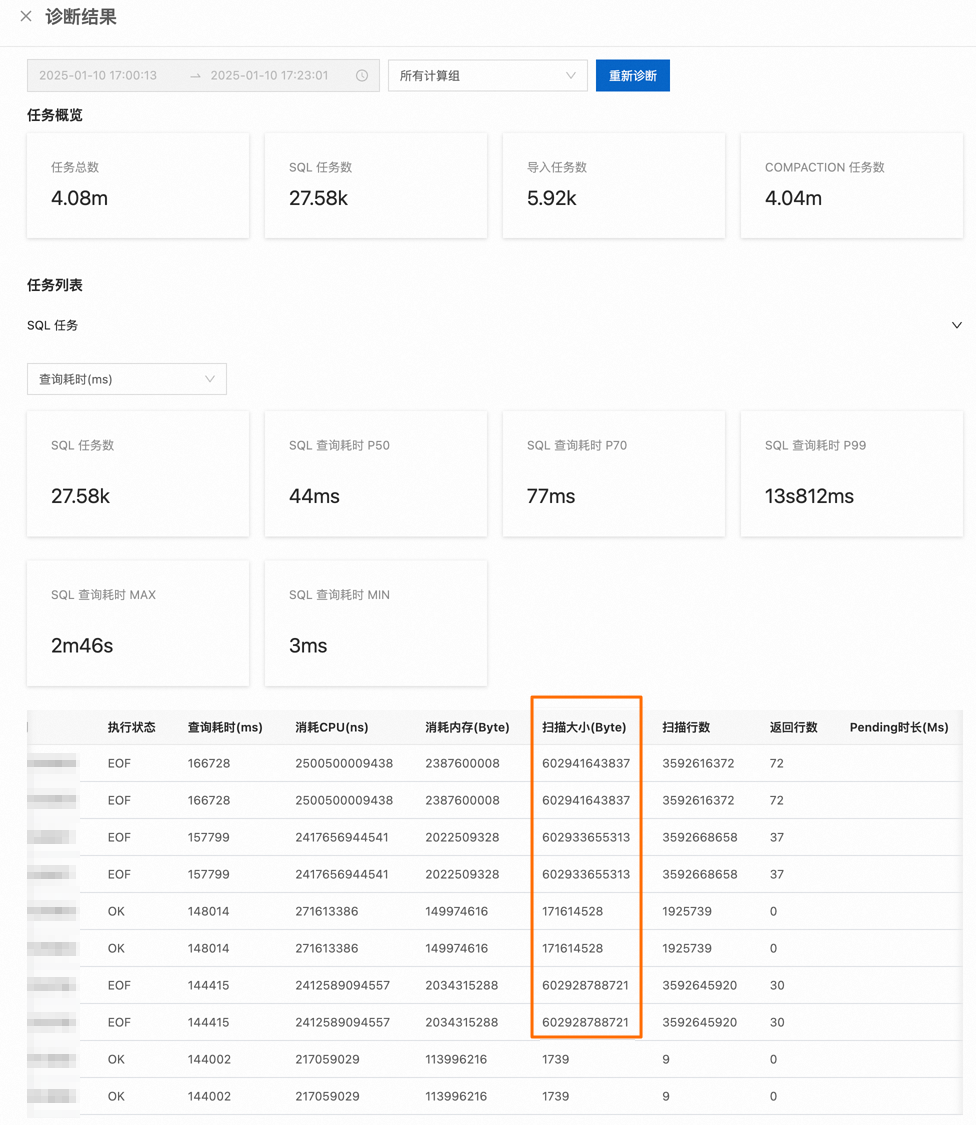
获取实时诊断结果,定位到具体的大查询任务。
- 本页导读 (1)
- 监控实践
- 实例监控
- 计算组监控
- 告警实践
- 云监控指标
- 告警配置方案
- 运维示例
- 1、配置告警
- 2、接收告警
- 3、监控排查
- 4、实时诊断与问题定位