
存算分离模式下计算和存储资源解耦,数据默认存储在阿里云OSS中,显著提升了资源利用效率并降低了成本。为优化查询性能,存算分离通过本地缓存技术将热数据存储在计算节点的本地磁盘中,当查询命中缓存时,数据可以直接从本地读取,从而使查询性能与存算一体集群相当。
前提条件
已创建并连接Serverless StarRocks实例,详情请参见快速使用存算分离版实例。
操作流程
步骤一:创建存算分离数据库及数据表
创建数据库
cloud_db和数据表detail_demo。CREATE DATABASE cloud_db; USE cloud_db; CREATE TABLE IF NOT EXISTS detail_demo ( recruit_date DATE NOT NULL COMMENT "YYYY-MM-DD", region_num TINYINT COMMENT "range [-128, 127]", num_plate SMALLINT COMMENT "range [-32768, 32767] ", tel INT COMMENT "range [-2147483648, 2147483647]", id BIGINT COMMENT "range [-2^63 + 1 ~ 2^63 - 1]", password LARGEINT COMMENT "range [-2^127 + 1 ~ 2^127 - 1]", name CHAR(20) NOT NULL COMMENT "range char(m),m in (1-255) ", profile VARCHAR(500) NOT NULL COMMENT "upper limit value 65533 bytes", ispass BOOLEAN COMMENT "true/false") DUPLICATE KEY(recruit_date, region_num) DISTRIBUTED BY HASH(recruit_date, region_num) PROPERTIES ( "replication_num" = "1" );查看数据库的
DbId。SHOW PROC '/dbs';返回信息如下所示。

查看表的详细信息。
SHOW PROC '/dbs/10313';示例代码中的
10313为前一步骤中获取到的DbId,返回信息如下所示。
返回信息中的
Type字段标识出在存算分离模式下的数据表类型为CLOUD_NATIVE,StoragePath字段为表在OSS中的路径,通过该路径可以定位到存算分离表的数据存储位置。
步骤二:存算分离Cache特性演示
本步骤通过创建两个测试表(分别开启和关闭本地缓存),验证StarRocks存算分离模式下本地缓存(datacache.enable)对性能的影响。
创建测试表。
catalog_sales:开启本地缓存的表。
catalog_sales_nocache:关闭本地缓存的表。
USE cloud_db; --创建catalog_sales表。 CREATE TABLE IF NOT EXISTS catalog_sales( cs_order_number bigint, cs_item_sk bigint, cs_sold_date_sk bigint, cs_sold_time_sk bigint, cs_ship_date_sk bigint, cs_bill_customer_sk bigint, cs_bill_cdemo_sk bigint, cs_bill_hdemo_sk bigint, cs_bill_addr_sk bigint, cs_ship_customer_sk bigint, cs_ship_cdemo_sk bigint, cs_ship_hdemo_sk bigint, cs_ship_addr_sk bigint, cs_call_center_sk bigint, cs_catalog_page_sk bigint, cs_ship_mode_sk bigint, cs_warehouse_sk bigint, cs_promo_sk bigint, cs_quantity int, cs_wholesale_cost decimal(7,2), cs_list_price decimal(7,2), cs_sales_price decimal(7,2), cs_ext_discount_amt decimal(7,2), cs_ext_sales_price decimal(7,2), cs_ext_wholesale_cost decimal(7,2), cs_ext_list_price decimal(7,2), cs_ext_tax decimal(7,2), cs_coupon_amt decimal(7,2), cs_ext_ship_cost decimal(7,2), cs_net_paid decimal(7,2), cs_net_paid_inc_tax decimal(7,2), cs_net_paid_inc_ship decimal(7,2), cs_net_paid_inc_ship_tax decimal(7,2), cs_net_profit decimal(7,2) ) DUPLICATE KEY (cs_order_number, cs_item_sk) DISTRIBUTED BY HASH(cs_order_number, cs_item_sk) BUCKETS 90 PROPERTIES( "replication_num"="1", "datacache.enable" = "true" ); --创建catalog_sales_nocache表。 CREATE TABLE IF NOT EXISTS catalog_sales_nocache( cs_order_number bigint, cs_item_sk bigint, cs_sold_date_sk bigint, cs_sold_time_sk bigint, cs_ship_date_sk bigint, cs_bill_customer_sk bigint, cs_bill_cdemo_sk bigint, cs_bill_hdemo_sk bigint, cs_bill_addr_sk bigint, cs_ship_customer_sk bigint, cs_ship_cdemo_sk bigint, cs_ship_hdemo_sk bigint, cs_ship_addr_sk bigint, cs_call_center_sk bigint, cs_catalog_page_sk bigint, cs_ship_mode_sk bigint, cs_warehouse_sk bigint, cs_promo_sk bigint, cs_quantity int, cs_wholesale_cost decimal(7,2), cs_list_price decimal(7,2), cs_sales_price decimal(7,2), cs_ext_discount_amt decimal(7,2), cs_ext_sales_price decimal(7,2), cs_ext_wholesale_cost decimal(7,2), cs_ext_list_price decimal(7,2), cs_ext_tax decimal(7,2), cs_coupon_amt decimal(7,2), cs_ext_ship_cost decimal(7,2), cs_net_paid decimal(7,2), cs_net_paid_inc_tax decimal(7,2), cs_net_paid_inc_ship decimal(7,2), cs_net_paid_inc_ship_tax decimal(7,2), cs_net_profit decimal(7,2) ) DUPLICATE KEY(cs_order_number, cs_item_sk) DISTRIBUTED BY HASH(cs_order_number, cs_item_sk) BUCKETS 90 PROPERTIES( "replication_num"="1", "datacache.enable" = "false" );数据导入测试。
编辑并上传测试数据到OSS。
说明本文示例通过ECS实例执行以下命令,您也可以在本地执行。创建ECS实例的具体操作,请参见通过控制台使用ECS实例(快捷版)。
通过以下命令,编辑
upload.sh脚本。vim upload.sh在
upload.sh中新增以下内容。#!/bin/bash # 日期时间 date_time=`date +%Y-%m-%d-%H-%M-%S` yum install -y wget unzip mkdir -p /data/ curl https://gosspublic.alicdn.com/ossutil/install.sh | sudo bash wget -O catalog_sales.zip "https://starrocks-oss.oss-cn-beijing.aliyuncs.com/public-access/catalog_sales.zip" && unzip -o catalog_sales.zip -d /data/ echo download data finish upload_url=$1 #ossutil cp -r /data/ ${upload_url} endpoint="oss-cn-****-internal.aliyuncs.com" accessKeyId="<yourAccessKeyID>" accessKeySecret="<yourAccessKeySecret>" echo ossutil64 -e ${endpoint} -i ${accessKeyId} -k ${accessKeySecret} cp -r /data/ ${upload_url} ossutil64 -e ${endpoint} -i ${accessKeyId} -k ${accessKeySecret} cp -r -f /data/ ${upload_url} echo success for data upload请根据实际情况替换文件中的
endpoint、accessKeyId和accessKeySecret。参数
说明
endpoint访问OSS的Endpoint。例如,oss-cn-hangzhou-internal.aliyuncs.com。
如果StarRocks与OSS位于同一地域,则使用VPC网络Endpoint,否则使用公网Endpoint。获取方法请参见OSS地域和访问域名。
accessKeyId访问OSS的AccessKey ID。您可以进入AccessKey管理页面获取AccessKey ID。
accessKeySecretAccessKey ID对应的 AccessKey Secret。
执行以下命令,将测试数据上传至指定的OSS路径。
sh upload.sh 'oss://<yourBucketName>/tcp_ds/'说明其中,
oss://<yourBucketName>/tcp_ds/为测试数据上传的路径,您可以根据实际情况修改。数据上传完成后,系统会在目标路径下的tcp_ds/data/目录中生成.parquet文件。
使用Broker Load导入测试数据(约10 GB)。
-- 导入数据到catalog_sales。 LOAD LABEL cloud_db.catalog_sales_0001 ( DATA INFILE("<file_path>") INTO TABLE catalog_sales format as "parquet" ) WITH BROKER 'broker' ( "fs.oss.accessKeyId" = "<yourAccessKeyID>", "fs.oss.accessKeySecret" = "<yourAccessKeySecret>", "fs.oss.endpoint" = "<yourBucketEndpoint>" ); -- 导入数据到catalog_sales_nocache。 LOAD LABEL cloud_db.catalog_sales_0003 ( DATA INFILE("<file_path>") INTO TABLE catalog_sales_nocache format as "parquet" ) WITH BROKER 'broker' ( "fs.oss.accessKeyId" = "<yourAccessKeyID>", "fs.oss.accessKeySecret" = "<yourAccessKeySecret>", "fs.oss.endpoint" = "<yourBucketEndpoint>" );请根据实际情况替换以下参数。
参数
说明
<file_path>为测试数据的路径,请根据实际情况修改。例如,oss://<yourBucketName>/tcp_ds/data/*.parquet。
fs.oss.accessKeyId
访问OSS的AccessKey ID。您可以进入AccessKey管理页面获取AccessKey ID。
fs.oss.accessKeySecret
AccessKey ID对应的 AccessKey Secret。
fs.oss.endpoint
访问OSS的Endpoint。例如,oss-cn-hangzhou-internal.aliyuncs.com。
如果StarRocks与OSS位于同一地域,则使用VPC网络Endpoint,否则使用公网Endpoint。获取方法请参见OSS地域和访问域名。
在导入任务页面,可以查看测试结果。
测试结果如下表所示。
表名称
本地缓存
表类型
导入用时
catalog_sales
开启
明细表
1分21秒
catalog_sales_nocache
关闭
明细表
1分20秒
测试结果表明,存算分离模式下,启用本地缓存对数据导入性能的影响极低。
数据查询测试。
针对开启本地缓存和不开启本地缓存两种场景进行了测试,以评估本地缓存对查询性能的影响。在StarRocks的存算分离模式下,Query执行引擎会在查询执行过程中记录访问缓存和对象存储OSS的指标,并将其记录在Profile中。因此,我们可以使用Profile工具来查看相关指标。
设置最大Query超时时间。
SET GLOBAL query_timeout = 1200;执行查询。
-- 查询catalog_sales(开启本地缓存)。 SELECT cs_item_sk, cs_bill_customer_sk FROM cloud_db.catalog_sales GROUP BY cs_item_sk, cs_bill_customer_sk ORDER BY cs_item_sk DESC LIMIT 100; -- 查询catalog_sales_nocache(关闭本地缓存)。 SELECT cs_item_sk, cs_bill_customer_sk FROM cloud_db.catalog_sales_nocache GROUP BY cs_item_sk, cs_bill_customer_sk ORDER BY cs_item_sk DESC LIMIT 100;查看Profile指标。
在左侧导航栏中选择,找到对应的Query,在执行详情页签可以看到Profile执行树,找到
CONNECTOR_SCAN节点,右侧指标中主要关注CompressedBytesReadLocalDisk(从本地缓存读取)和CompressedBytesReadRemote(从远端OSS对象存储读取)两个指标。本示例中,catalog_sales表开启了本地缓存,指标值
CompressedBytesReadLocalDisk>0,因此可以确定查询全部命中了本地缓存,查询速度显著提升。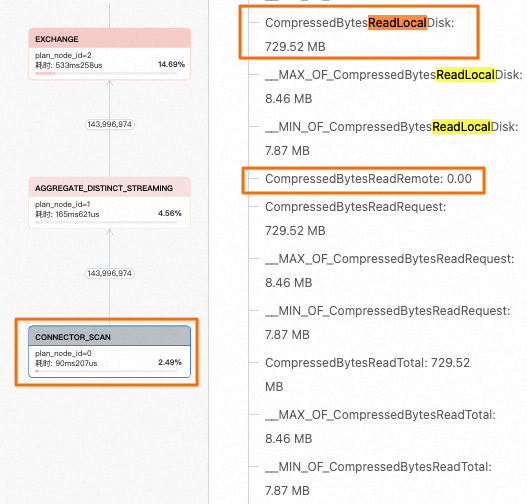
catalog_sales_nocache表没有开启本地缓存,指标值
CompressedBytesReadLocalDisk=0,查询数据未命中本地缓存,数据全部来自远端OSS对象存储。
步骤三:对比存算分离和存算一体的性能
以下内容通过一个测试案例,为您展示了存算分离带本地缓存和存算一体两种模式下的查询性能对比。您可以使用TPC-H测试集进行更详细的性能对比测试,详情请参见测试说明。
准备数据环境。
集群资源配置:1FE(8CU)+3BE(算力:16CU|存储:1000 GB)。
集群参数:使用默认设置,存算分离集群开启本地缓存。
数据量:500 GB(sf=500),经过压缩后约为180 GB。
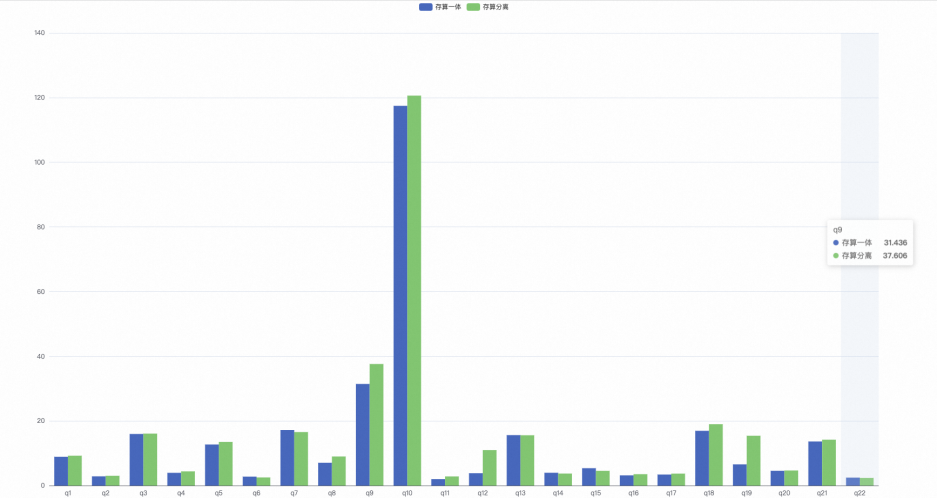
测试结果。
存算一体22条SQL总计用时:302.063秒。
存算分离22条SQL总计用时(第2次执行时开启本地缓存的情况下):333.390秒。
根据TPC-H的结果显示,在开启本地缓存的情况下,存算分离和存算一体的查询性能基本相同。
相关文档
如需了解Query Profile更多信息,请参见Query Profile介绍。
如果您想有效地查看和解读Query Profile以优化StarRocks查询性能,详情请参见Profile性能诊断及优化案例。