本文介绍作业性能相关的常见问题。
如何拆分算子节点?
在页面,单击目标作业名称,在部署详情页签的运行参数配置区域的其他配置中,添加如下代码后保存生效。
pipeline.operator-chaining: 'false'Group Aggregate优化技巧有哪些?
开启MiniBatch(提升吞吐)
MiniBatch是缓存一定的数据后再触发处理,以减少对State的访问,从而提升吞吐量并减少数据的输出量。
MiniBatch主要基于事件消息来触发微批处理,事件消息会按您指定的时间间隔在源头插入。
适用场景
微批处理通过增加延迟换取高吞吐,如果您有超低延迟的要求,不建议开启微批处理。通常对于聚合场景,微批处理可以显著提升系统性能,建议开启。
开启方式
MiniBatch默认关闭,您需要在目标作业的部署详情页签,运行参数配置区域的其他配置中,填写以下代码。
table.exec.mini-batch.enabled: true table.exec.mini-batch.allow-latency: 5s参数解释如下表所示。
参数
说明
table.exec.mini-batch.enabled
是否开启mini-batch。
table.exec.mini-batch.allow-latency
批量输出数据的时间间隔。
开启LocalGlobal(解决常见数据热点问题)
LocalGlobal机制通过LocalAgg聚合筛选部分倾斜数据,有效减轻GlobalAgg的热点压力,提升整体性能。
LocalGlobal优化将原先的Aggregate分成Local和Global两阶段聚合,即MapReduce模型中的Combine和Reduce两阶段处理模式。第一阶段在上游节点本地攒一批数据进行聚合(localAgg),并输出这次微批的增量值(Accumulator)。第二阶段再将收到的Accumulator合并(Merge),得到最终的结果(GlobalAgg)。
适用场景
提升普通聚合(例如SUM、COUNT、MAX、MIN和AVG)的性能,以及这些场景下的数据热点问题。
使用限制
LocalGlobal是默认开启的,但是有以下限制:
在minibatch开启的前提下才能生效。
需要使用AggregateFunction实现Merge。
判断是否生效
观察最终生成的拓扑图的节点名字中是否包含GlobalGroupAggregate或LocalGroupAggregate。
开启PartialFinal(解决COUNT DISTINCT热点问题)
为了解决COUNT DISTINCT的热点问题,通常需要手动改写为两层聚合(增加按Distinct Key取模的打散层)。目前,实时计算提供了COUNT DISTINCT自动打散,即PartialFinal优化,您无需自行改写为两层聚合。
LocalGlobal优化针对普通聚合(例如SUM、COUNT、MAX、MIN和AVG)有较好的效果,对于COUNT DISTINCT收效不明显,因为COUNT DISTINCT在Local聚合时,对于DISTINCT KEY的去重率不高,导致在Global节点仍然存在热点问题。
适用场景
使用COUNT DISTINCT,但无法满足聚合节点性能要求。
重要不能在包含UDAF的Flink SQL中使用PartialFinal优化方法。
数据量较少的情况,不建议使用PartialFinal优化方法,以免浪费资源。因为PartialFinal优化会自动打散成两层聚合,引入额外的网络Shuffle。
开启方式
默认不开启。如果您需要开启,则需要在目标作业的部署详情页签,运行参数配置区域的其他配置中,填写以下代码。
table.optimizer.distinct-agg.split.enabled: true判断是否生效
观察最终生成的拓扑图,是否由原来一层的聚合变成了两层的聚合。
AGG WITH CASE WHEN改写为AGG WITH FILTER语法(提升大量COUNT DISTINCT场景性能)
统计作业需要计算各种维度的UV,例如全网UV、来自手机客户端的UV、来自PC的UV等等。建议使用标准的AGG WITH FILTER语法来代替CASE WHEN实现多维度统计的功能。实时计算目前的SQL优化器能分析出Filter参数,从而同一个字段上计算不同条件下的COUNT DISTINCT能共享State,减少对State的读写操作。性能测试中,使用AGG WITH FILTER语法来代替CASE WHEN能够使性能提升1倍。
适用场景
对于在同一个字段上计算不同条件下的COUNT DISTINCT结果的场景,性能提升很大。
原始写法
COUNT(distinct visitor_id) as UV1 , COUNT(distinct case when is_wireless='y' then visitor_id else null end) as UV2优化写法
COUNT(distinct visitor_id) as UV1 , COUNT(distinct visitor_id) filter (where is_wireless='y') as UV2
TopN优化技巧有哪些?
TopN算法
当TopN的输入是非更新流(例如SLS数据源),TopN只有1种算法AppendRank。当TopN的输入是更新流时(例如经过了AGG或JOIN计算),TopN有2种算法,性能从高到低分别是:UpdateFastRank和RetractRank。算法名字会显示在拓扑图的节点名字上。
AppendRank:对于非更新流,只支持该算法。
UpdateFastRank:对于更新流,最优算法。
RetractRank:对于更新流,保底算法。性能不佳,在某些业务场景下可优化成UpdateFastRank。
下面介绍RetractRank如何优化成UpdateFastRank。使用UpdateFastRank算法需要具备3个条件:
输入流为更新流。
输入流有Primary Key信息,例如上游做了GROUP BY聚合操作。
排序字段的更新是单调的,且单调方向与排序方向相反。例如,ORDER BY COUNT、COUNT_DISTINCT或SUM(正数)DESC。
如果您要获取到UpdateFastRank的优化Plan,则您需要在使用ORDER BY SUM DESC时,添加SUM为正数的过滤条件,确保total_fee为正数。
insert into print_test SELECT cate_id, seller_id, stat_date, pay_ord_amt --不输出rownum字段,能减小结果表的输出量。 FROM ( SELECT *, ROW_NUMBER () OVER ( PARTITION BY cate_id, stat_date --注意要有时间字段,否则State过期会导致数据错乱。 ORDER BY pay_ord_amt DESC ) as rownum --根据上游sum结果排序。 FROM ( SELECT cate_id, seller_id, stat_date, --重点。声明Sum的参数都是正数,所以Sum的结果是单调递增的,因此TopN能使用优化算法,只获取前100个数据。 sum (total_fee) filter ( where total_fee >= 0 ) as pay_ord_amt FROM random_test WHERE total_fee >= 0 GROUP BY cate_name, seller_id, stat_date, cate_id ) a ) WHERE rownum <= 100;TopN优化方法
无排名优化
TopN的输出结果不需要显示rownum值,仅需在最终前端显示时进行1次排序,极大地减少输入结果表的数据量。无排名优化方法详情请参见Top-N。
增加TopN的Cache大小
TopN为了提升性能有一个State Cache层,Cache层能提升对State的访问效率。TopN的Cache命中率的计算公式如下。
cache_hit = cache_size*parallelism/top_n/partition_key_num例如,Top100配置缓存10000条,并发50,当您的PartitionBy的Key维度较大时,例如10万级别时,Cache命中率只有10000*50/100/100000=5%,命中率会很低,导致大量的请求都会击中State(磁盘),观察state seek metric可能会有很多毛刺。性能会大幅下降。
因此当partitionKey维度特别大时,可以适当加大TopN的cache size,相应的也建议适当加大TopN节点的heap memory,详情请参见配置作业部署信息。
table.exec.rank.topn-cache-size: 200000默认值为10000条,调整TopN cache到200000,那么理论命中率能达到
200000*50/100/100000 = 100%。PartitionBy的字段中要有时间类字段
例如每天的排名,要带上Day字段,否则TopN的最终结果会由于State TTL产生错乱。
有哪些高效去重方案?
实时计算Flink版的源数据在部分场景中存在重复数据,去重成为了用户经常反馈的需求。实时计算有保留第一条(Deduplicate Keep FirstRow)和保留最后一条(Deduplicate Keep LastRow)2种去重方案。
语法
由于SQL上没有直接支持去重的语法,还要灵活地保留第一条或保留最后一条。因此我们使用了SQL的ROW_NUMBER OVER WINDOW功能来实现去重语法。去重本质上是一种特殊的TopN。
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY col1[, col2..] ORDER BY timeAttributeCol [asc|desc]) AS rownum FROM table_name) WHERE rownum = 1参数
说明
ROW_NUMBER()
计算行号的OVER窗口函数。行号从1开始计算。
PARTITION BY col1[, col2..]
可选。指定分区的列,即去重的KEYS。
ORDER BY timeAttributeCol [asc|desc])
指定排序的列,必须是一个时间属性的字段(即Proctime或Rowtime)。可以指定顺序(Keep FirstRow)或者倒序 (Keep LastRow)。
rownum
仅支持
rownum=1或rownum<=1。如上语法所示,去重需要两层Query:
使用
ROW_NUMBER()窗口函数来对数据根据时间属性列进行排序并标上排名。当排序字段是Proctime列时,Flink就会按照系统时间去重,其每次运行的结果是不确定的。
当排序字段是Rowtime列时,Flink就会按照业务时间去重,其每次运行的结果是确定的。
对排名进行过滤,只取第一条,达到了去重的目的。
排序方向可以是按照时间列的顺序,也可以是倒序:
Deduplicate Keep FirstRow:顺序并取第一行数据。
Deduplicate Keep LastRow:倒序并取第一行数据。
Deduplicate Keep FirstRow
保留首行的去重策略:保留KEY下第一条出现的数据,之后出现该KEY下的数据会被丢弃。因为STATE中只存储了KEY数据,所以性能较优,示例如下。
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY b ORDER BY proctime) as rowNum FROM T ) WHERE rowNum = 1以上示例是将T表按照b字段进行去重,并按照系统时间保留第一条数据。proctime在这里是源表T中的一个具有Processing Time属性的字段。如果您按照系统时间去重,也可以将proctime字段简化proctime()函数调用,可以省略proctime字段的声明。
Deduplicate Keep LastRow
保留末行的去重策略:保留KEY下最后一条出现的数据。保留末行的去重策略性能略优于LAST_VALUE函数,示例如下。
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY b, d ORDER BY rowtime DESC) as rowNum FROM T ) WHERE rowNum = 1以上示例是将T表按照b和d字段进行去重,并按照业务时间保留最后一条数据。rowtime在这里是源表T中的一个具有Event Time属性的字段。
在使用内置函数时,需要注意什么?
使用内置函数替换自定义函数
实时计算的内置函数在持续的优化当中,请尽量使用内置函数替换自定义函数。实时计算对内置函数主要进行了如下优化:
优化数据序列化和反序列化的耗时。
新增直接对字节单位进行操作的功能。
KEY VALUE函数使用单字符的分隔符
KEY VALUE的签名:
KEYVALUE(content, keyValueSplit, keySplit, keyName),当keyValueSplit和keySplit是单字符,例如,冒号(:)、逗号(,)时,系统会使用优化算法,在二进制数据上直接寻找所需的keyName值,而不会将整个content进行切分,性能约提升30%。LIKE操作注意事项
如果需要进行StartWith操作,使用
LIKE 'xxx%'。如果需要进行EndWith操作,使用
LIKE '%xxx'。如果需要进行Contains操作,使用
LIKE '%xxx%'。如果需要进行Equals操作,使用
LIKE 'xxx',等价于str = 'xxx'。如果需要匹配下划线(_),请注意要完成转义
LIKE '%seller/_id%' ESCAPE '/'。下划线(_)在SQL中属于单字符通配符,能匹配任何字符。如果声明为LIKE '%seller_id%',则不仅会匹配seller_id,还会匹配seller#id、sellerxid或seller1id等,导致结果错误。
慎用正则函数(REGEXP)
正则表达式是非常耗时的操作,对比加减乘除通常有百倍的性能开销,而且正则表达式在某些极端情况下可能会进入无限循环,导致作业阻塞,具体情况请参见Regex execution is too slow,因此建议使用LIKE。正则函数包括:
全表读取阶段效率低且存在反压,如何解决?
可能是下游节点处理太慢导致了反压。因此您需要先排查下游节点是否存在反压。如果存在,则需要先解决下游节点的反压问题。您可以通过以下方式处理:
增加并发数。
开启minibatch等聚合优化参数(下游聚合节点)。
作业状态总览中vertex subtask的Status Durations颜色标识含义
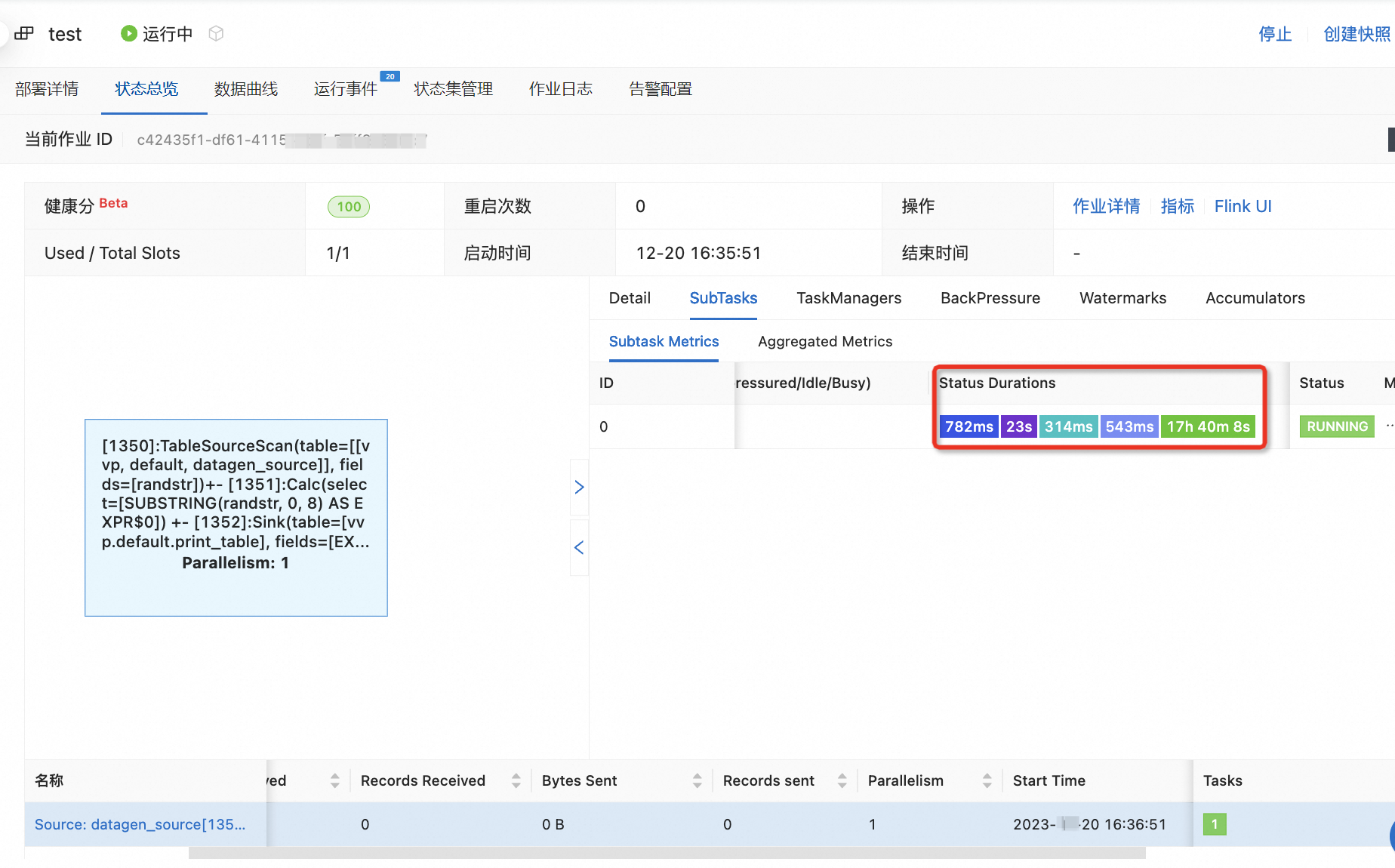
Status Durations表示vertex subtask在各个阶段的耗时,各颜色标识含义如下:
 :CREATED
:CREATED :SCHEDULED
:SCHEDULED :DEPLOYING
:DEPLOYING :INITIALIZING
:INITIALIZING :RUNNING
:RUNNING
RMI TCP Connection是什么线程?为什么占用的CPU比其他线程高这么多?
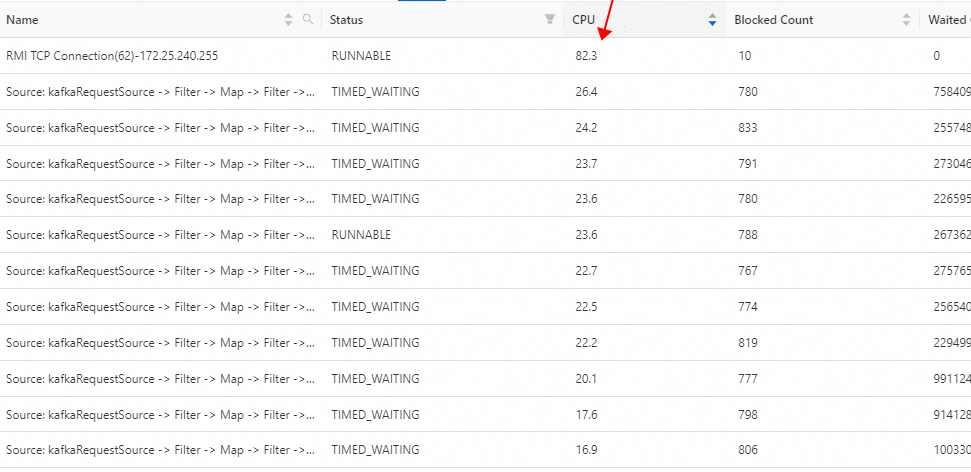
RMI TCP Connection线程是Java自带的RMI(Remote Method Invocation)框架中的线程,负责执行远程方法调用。线程占用CPU是动态实时变化的,短暂的指标波动不能代表CPU整体的负载过高。在一段时间内观察CPU的使用情况,可以通过分析线程的火焰图进行评估,从下图可以看出RMI线程几乎不消耗CPU。

运行拓扑图中显示的Low Watermark、Watermark以及Task InputWatermark指标显示的时间和当前时间有时差?
原因1:声明源表Watermark时使用了
TIMESTAMP_LTZ(TIMESTAMP(p) WITH LOCAL TIME ZONE)类型,导致Watermark和当前时间有时差。下文以具体的示例为您展示使用TIMESTAMP_LTZ类型和TIMESTAMP类型对应的Watermark指标差异。
源表中Watermark声明使用的字段是TIMESTAMP_LTZ类型。
CREATE TEMPORARY TABLE s1 ( a INT, b INT, ts as CURRENT_TIMESTAMP,--使用CURRENT_TIMESTAMP内置函数生成TIMESTAMP_LTZ类型。 WATERMARK FOR ts AS ts - INTERVAL '5' SECOND ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.b.kind'='random','fields.b.min'='0','fields.b.max'='10' ); CREATE TEMPORARY TABLE t1 ( k INT, ts_ltz timestamp_ltz(3), cnt BIGINT ) WITH ('connector' = 'print'); -- 输出计算结果。 INSERT INTO t1 SELECT b, window_start, COUNT(*) FROM TABLE( TUMBLE(TABLE s1, DESCRIPTOR(ts), INTERVAL '5' SECOND)) GROUP BY b, window_start, window_end;说明Legacy Window对应的老语法和
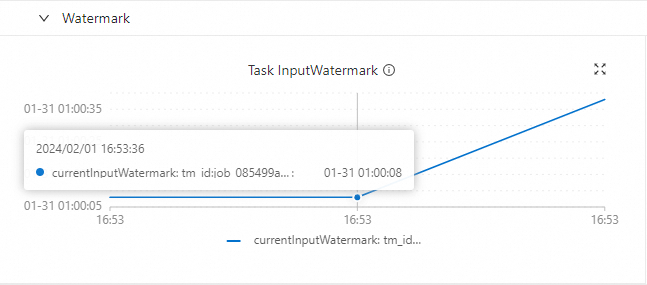
TVF Window(Table-Valued Function)产生的结果是一致的。以下为Legacy Window对应的老语法的示例代码。SELECT b, TUMBLE_END(ts, INTERVAL '5' SECOND), COUNT(*) FROM s1 GROUP BY TUMBLE(ts, INTERVAL '5' SECOND), b;在实时计算开发控制台将作业部署上线运行后,以北京时间为例,可以观察到作业运行拓扑图及监控告警上显示的Watermark和当前时间存在8小时时差。
Watermark&Low Watermark
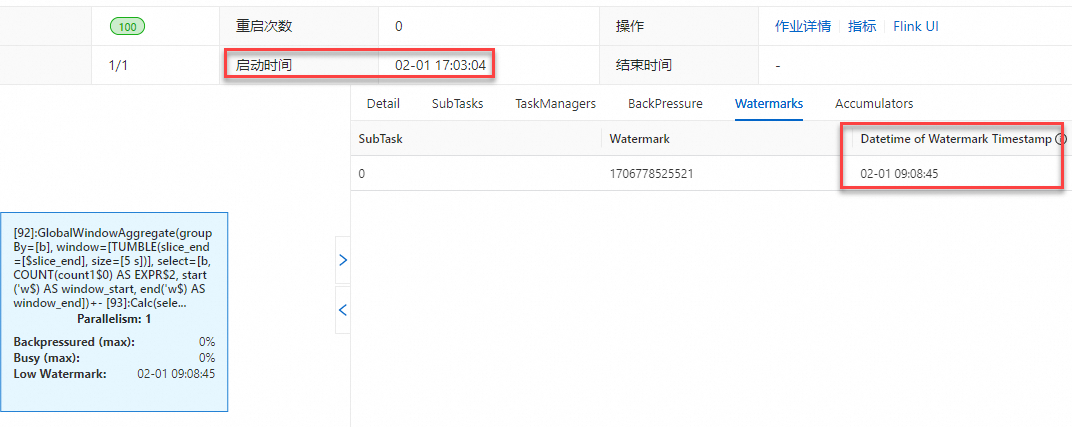
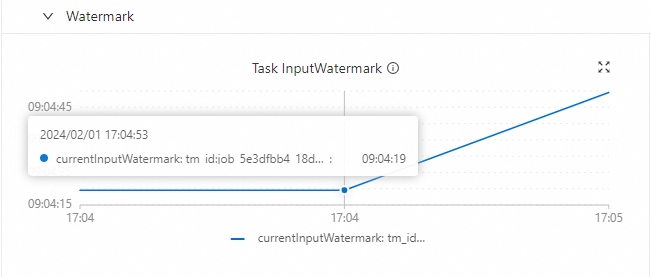
Task InputWatermark
源表中Watermark声明使用的字段是TIMESTAMP(TIMESTAMP(p) WITHOUT TIME ZONE)类型。
CREATE TEMPORARY TABLE s1 ( a INT, b INT, -- 模拟数据源中的TIMESTAMP无时区信息,从2024-01-31 01:00:00开始逐秒累加。 ts as TIMESTAMPADD(SECOND, a, TIMESTAMP '2024-01-31 01:00:00'), WATERMARK FOR ts AS ts - INTERVAL '5' SECOND ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.a.kind'='sequence','fields.a.start'='0','fields.a.end'='100000', 'fields.b.kind'='random','fields.b.min'='0','fields.b.max'='10' ); CREATE TEMPORARY TABLE t1 ( k INT, ts_ltz timestamp_ltz(3), cnt BIGINT ) WITH ('connector' = 'print'); -- 输出计算结果。 INSERT INTO t1 SELECT b, window_start, COUNT(*) FROM TABLE( TUMBLE(TABLE s1, DESCRIPTOR(ts), INTERVAL '5' SECOND)) GROUP BY b, window_start, window_end;在实时计算开发控制台上将作业部署上线运行后,可以观察到作业运行拓扑图及监控告警上显示的Watermark和当前时间是同步的(本示例是与模拟数据的时间同步的),不存在时差现象。
Watermark&Low Watermark
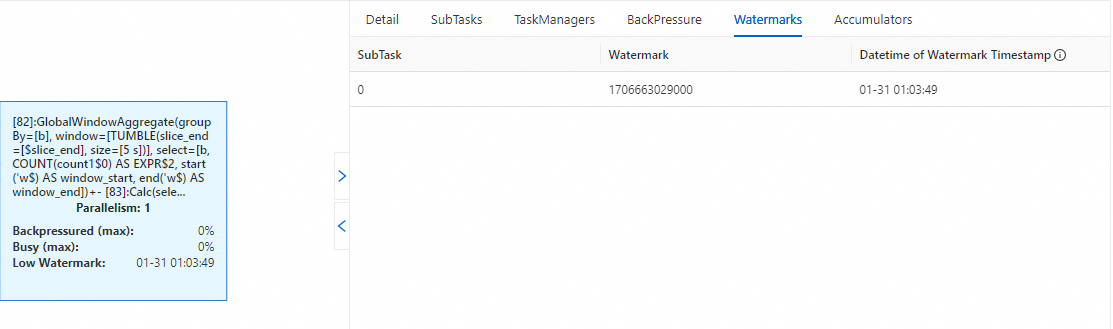
Task InputWatermark
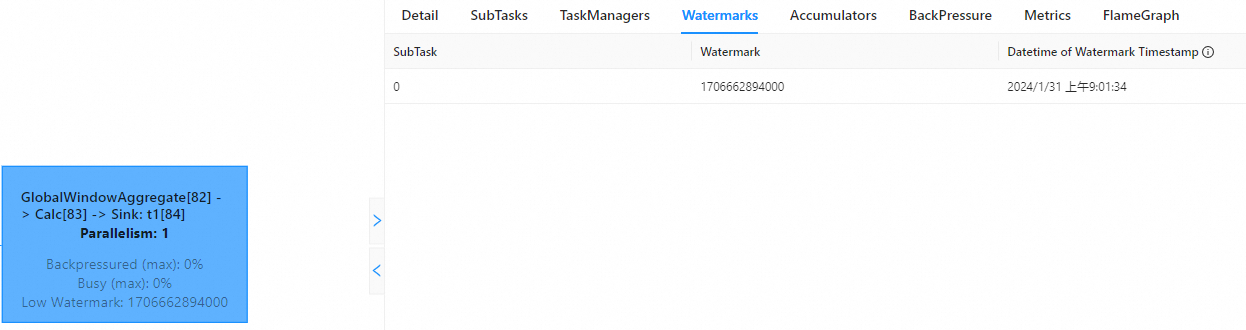
原因2:实时计算开发控制台和Apache Flink UI的展示时间存在时区差异。
实时计算开发控制台UI界面是以UTC+0显示时间,而Apache Flink UI是通过浏览器获取本地时区并进行相应的时间转换后的本地时间。以北京时间为例,为您展示二者显示区别,您会观察到在实时计算开发控制台显示的时间比Apache Flink UI时间慢8小时。
实时计算开发控制台
Apache Flink UI
如何排查作业反压问题?
在作业运维页面,单击目标作业名称,进入状态总览页签。
查看Busy和BackPressure,确定反压位置。
Busy指示灯颜色越红,表示任务负载越重;BackPressure指示灯颜色越深,表示受反压影响越严重。
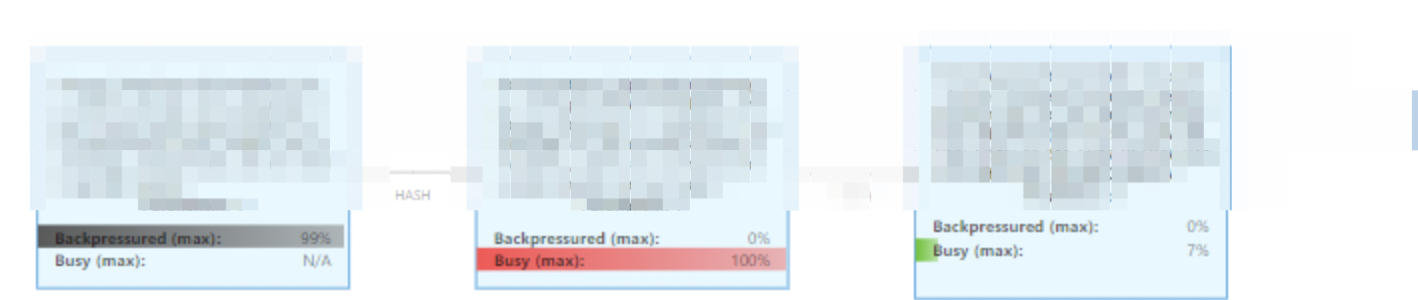
单击发生反压的Operator。
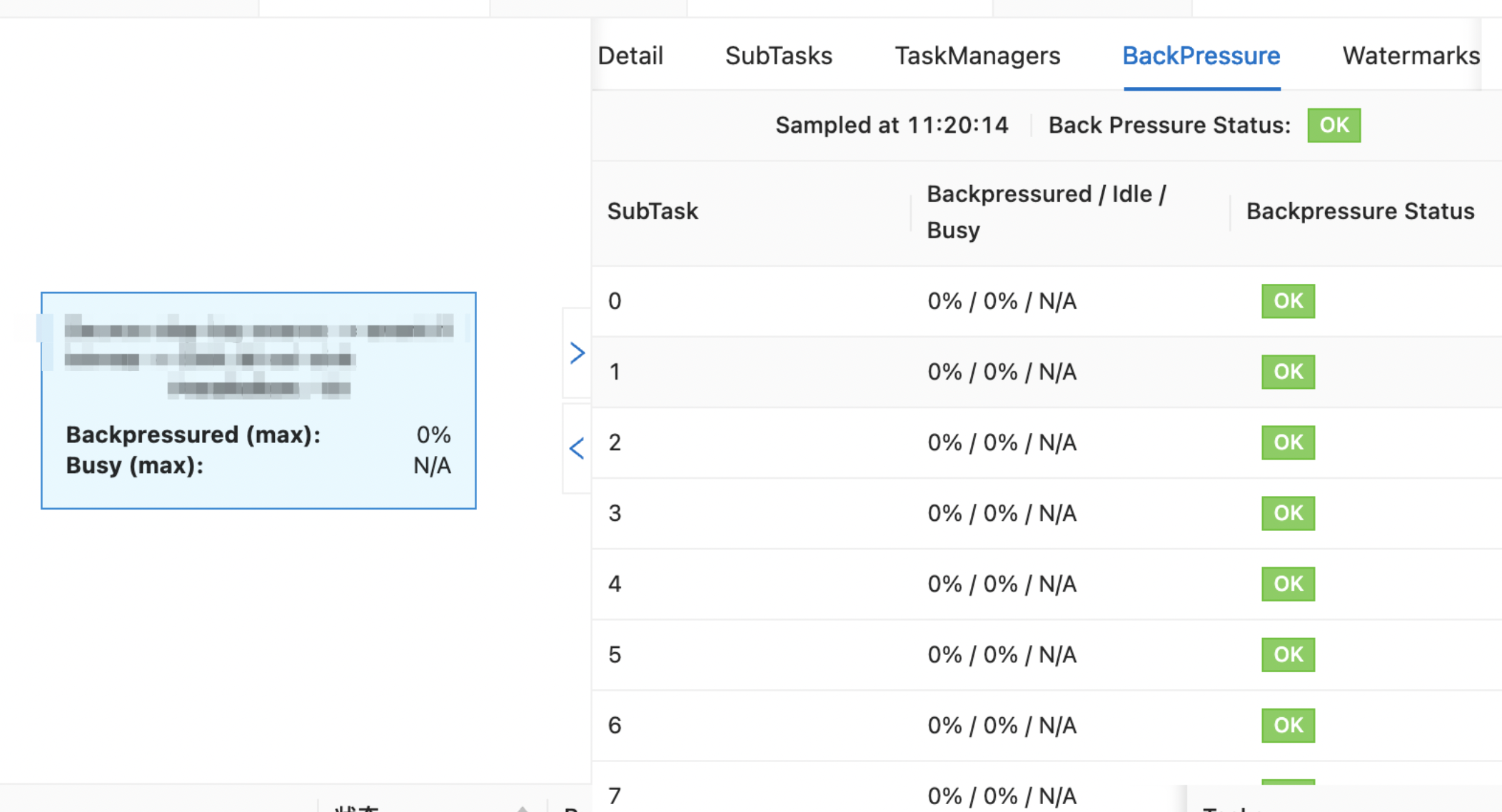
在BackPressure页签,排查SubTask反压情况。
如何排查作业延迟过高的问题?
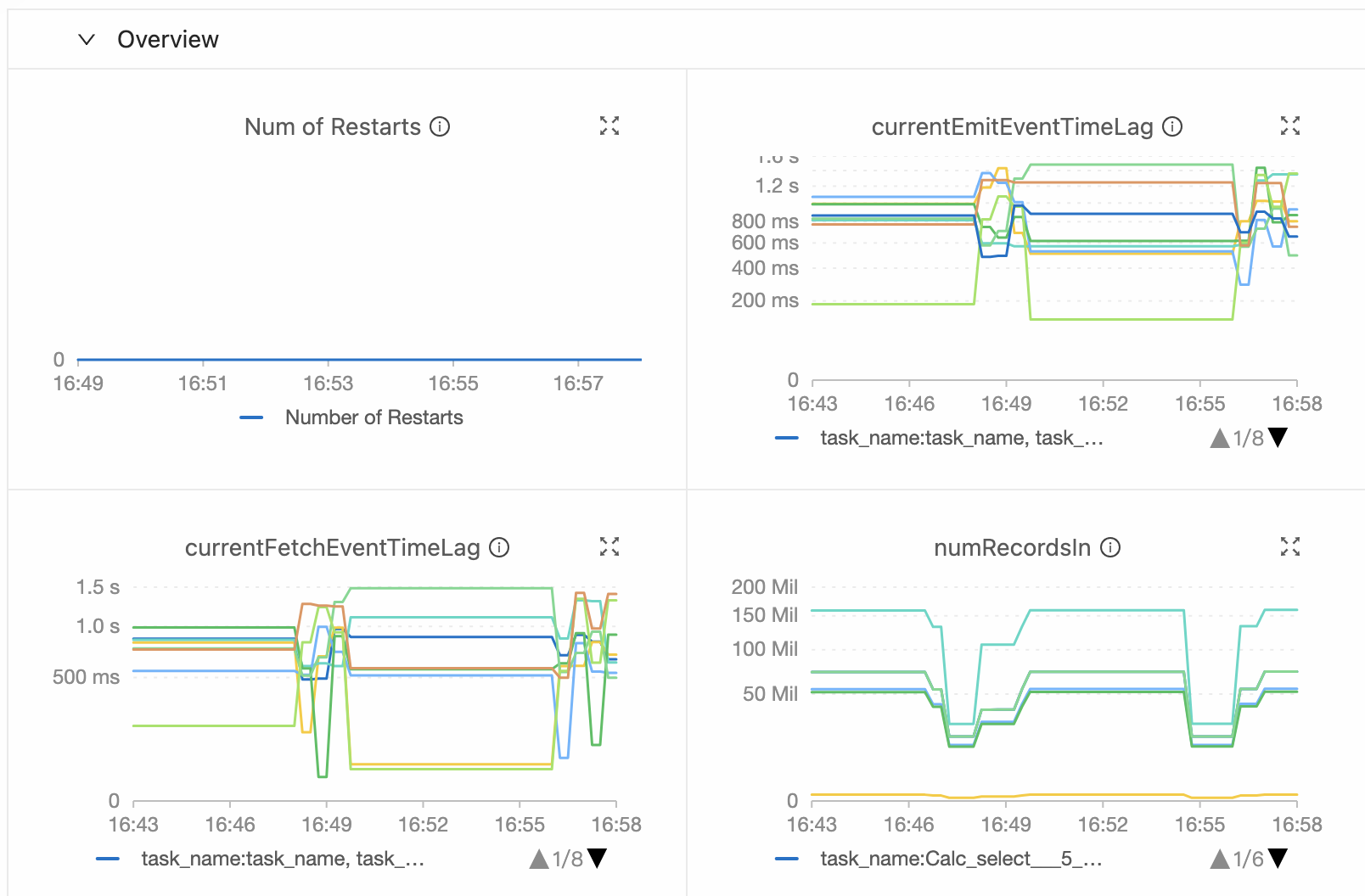
在作业运维页面的监控告警或数据曲线页签下,查看currentEmitEventTimeLag和currentFetchEventTimeLag指标并进行对应的处理。指标说明如下:
若
currentEmitEventTimeLag指标数值偏高,表明作业在拉取数据或处理上存在延迟,需检查算子性能是否达标。若
currentFetchEventTimeLag指标数值偏高,表明作业在拉取数据或上游系统数据处理上存在延迟,需排查网络I/O和上游系统。
当由上游因素导致延迟较高时,两个指标会同时增加。
Flink SQL作业数据热点问题导致反压,该如何优化?
作业存在反压时,经查看Subtask反压情况后,发现是数据热点问题。此时您可以参考以下方式进行优化:
开启LocalGlobal(解决常见数据热点问题)
LocalGlobal机制通过LocalAgg聚合筛选部分倾斜数据,有效减轻GlobalAgg的热点压力,提升整体性能。
LocalGlobal优化将原先的Aggregate分成Local和Global两阶段聚合,即MapReduce模型中的Combine和Reduce两阶段处理模式。第一阶段在上游节点本地攒一批数据进行聚合(localAgg),并输出这次微批的增量值(Accumulator)。第二阶段再将收到的Accumulator合并(Merge),得到最终的结果(GlobalAgg)。
适用场景
提升普通聚合(例如SUM、COUNT、MAX、MIN和AVG)的性能,以及这些场景下的数据热点问题。
使用限制
LocalGlobal是默认开启的,但是有以下限制:
在minibatch开启的前提下才能生效。
需要使用AggregateFunction实现Merge。
判断是否生效
观察最终生成的拓扑图的节点名字中是否包含GlobalGroupAggregate或LocalGroupAggregate。
开启PartialFinal(解决COUNT DISTINCT热点问题)
为了解决COUNT DISTINCT的热点问题,通常需要手动改写为两层聚合(增加按Distinct Key取模的打散层)。目前,实时计算提供了COUNT DISTINCT自动打散,即PartialFinal优化,您无需自行改写为两层聚合。
LocalGlobal优化针对普通聚合(例如SUM、COUNT、MAX、MIN和AVG)有较好的效果,对于COUNT DISTINCT收效不明显,因为COUNT DISTINCT在Local聚合时,对于DISTINCT KEY的去重率不高,导致在Global节点仍然存在热点问题。
适用场景
使用COUNT DISTINCT,但无法满足聚合节点性能要求。
重要不能在包含UDAF的Flink SQL中使用PartialFinal优化方法。
数据量较少的情况,不建议使用PartialFinal优化方法,以免浪费资源。因为PartialFinal优化会自动打散成两层聚合,引入额外的网络Shuffle。
开启方式
默认不开启。如果您需要开启,则需要在目标作业的部署详情页签,运行参数配置区域的其他配置中,填写以下代码。
table.optimizer.distinct-agg.split.enabled: true判断是否生效
观察最终生成的拓扑图,是否由原来一层的聚合变成了两层的聚合。
消费上游数据速度不稳定,该如何排查?
此类问题可能的原因与解决方案如下:
上游生产数据规律与当前数据处理速度不一致。
请分析上游数据生成规律,确保数据生产和处理速度相匹配。
作业存在反压。
请检查作业节点是否存在反压影响消费上游速度。如果当前作业显示只有一个节点,添加
pipeline.operator-chaining: 'false'参数后重启作业,拆开算子链,观察是否有被反压的节点影响消费速率。IO速率异常。
查看Flink对应时间下数据输入曲线和消费速率的规律,以排查是否是由IO引起。
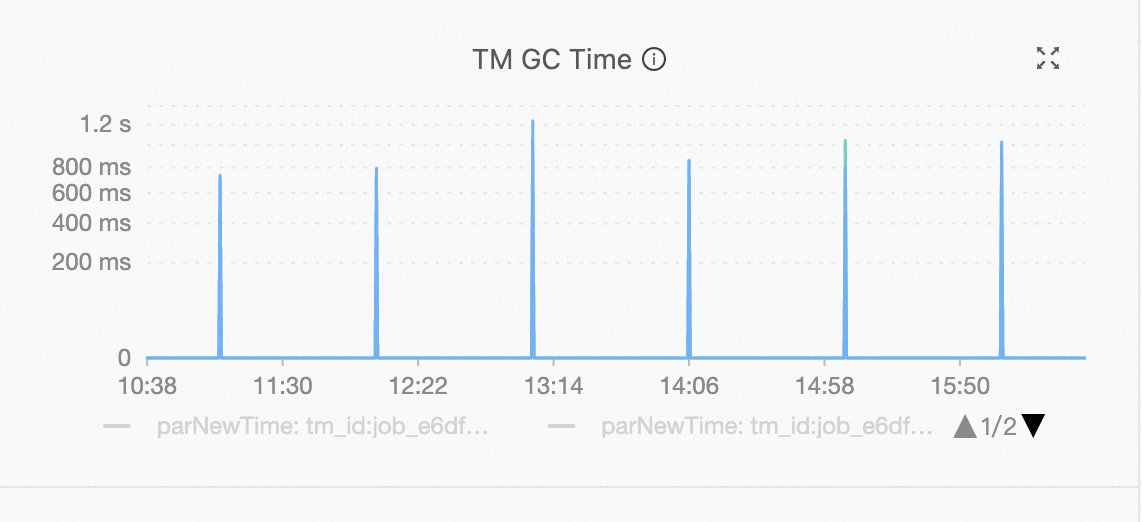
消费速率异常。
请观察消费速度波动规律,是否与Garbage Collection (GC)时间点对应。如果波动与GC时间点对应,请检查对应TM节点的内存情况。