
本文为您介绍在Hologres中标签、画像分析场景的最佳实践。
行业背景与痛点
画像分析是指基于沉淀用户的自然属性、行为属性、偏好属性等属性挖掘用户兴趣点、分析群体特征的过程。用户画像是刻画出用户个体或者用户群体全方位特征的重要手段,能为运营分析人员提供用户的偏好、行为等信息进而优化运营策略,为产品提供准确的用户角色信息以便进行针对性的产品设计。画像系统通常集用户特征加工、画像分析功能于一身;经过离线特征加工、维度标签映射、载入即席分析数据等过程,提供实时人群分析、圈选能力。
画像分析方法论已经广泛应用于各个行业,是赋能经营策略优化、精细化运营、精准营销的重要手段。例如以下典型场景。
广告行业:通过人群画像洞察,实现精准广告定向投放。
游戏行业:分析高流失率客户群,调整策略增加用户粘性。
教育行业:分析课程质量,达到增加续保率的目标。
画像分析的工程场景往往由于数据复杂度、数据量级和查询模式等因素导致系统可稳定性、运维性、可扩展性面临重重困难。
运维人员需要维护多套数据链路用于实时离线处理,陷入繁重链路维护工作;传统OLAP(On-Line Analysis Processing)引擎存储计算耦合,计算存储不成比例场景浪费资源,系统扩容迁移成本高。
运营人员需要灵活的圈选能力,单用户描述维度多可能多达数千维度,涵盖属性、行为等数据模式,MOLAP(Multidimensional OLAP)产品可以毫秒响应但缺乏灵活性,ROLAP(Relational OLAP)产品灵活性好但响应时间较长,无法兼顾性能和灵活性。
Hologres解决方案
针对上述两方面问题,基于新一代实时数仓产品Hologres的系统能力,通过配置数据链路、选择插件库、根据系统规模选择方案步骤快速构建高性能、可扩展的系统方案。
数据链路
依托Hologres通常只需要维护一套数据链路即可实现实时、离线的数据处理,避免常见的数据不同步、数据孤岛等问题,如下图所示。
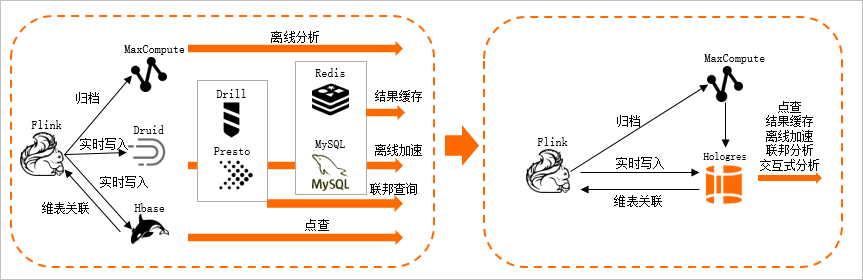 Hologres 数据集成能力方面的主要优势如下。
Hologres 数据集成能力方面的主要优势如下。无缝集成DataWorks产品,通过接入配置即可解决复杂数据依赖问题,构建稳定离线数据处理加载流程。
为实时写入场景提供了基于LSM(Log-Structured Merge)结构的行存储,与Flink进行深度融合,能够为实时标签、实时特征处理等场景提供稳定的性能支撑。
具有联邦查询能力,通过外部表方式直接访问MaxCompute、OSS、其他Hologres实例等外部数据存储。
画像计算
Hologres兼容PostgreSQL生态,内置函数丰富;同时,经过阿里内部及云上客户实践,逐步沉淀了诸多高效的画像计算插件,如下所示。
精确去重运算:RoaringBitmap函数
Hologres原生支持了Roaring Bitmap类型,通过高效率的Bitmap压缩算法,支持集合的交叉并等运算,支持Bitmap聚合,适合计算超高维度、基数的表,常用于去重(UV计算)、标签筛选、近实时用户画像等计算中。
行为数据圈人:明细圈人函数
在行为类数据的圈人场景中,我们经常碰到这样的情况:行为数据按照天或者小时记录在行为表中,当需要找到一段时间内出现某些行为的用户时,因为数据记录成多行而没办法直接过滤,所以就需要使用行为表多次JOIN自己来实现过滤。例如如下场景,在记录用户行为明细表中找出
时间在[20210216~20210218之间 & [click购物车] & [view收藏页]的用户。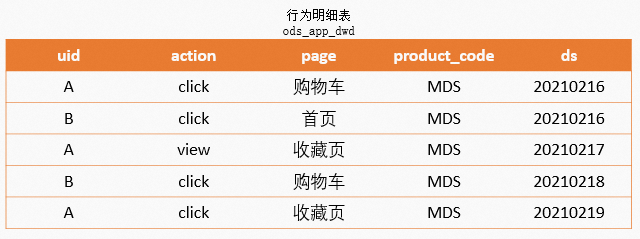
Hologres提供了
bit_construct、bit_orbit_match函数,能够规避JOIN的性能负担,简化SQL的复杂度。函数的主要思路是通过一遍数据过滤,将uid满足条件的集合以位数组形式存放,通过bit_match函数在位数组进行与运算实现数据过滤,示例如下。WITH tbl as ( SELECT uid, bit_or(bit_construct( a := (action='click' and page='购物车'), b := (action='view' and page='收藏页'))) as uid_mask FROM ods_app_dwd WHERE ds < '20210218' AND ds > '20210216' GROUP BY uid ) SELECT uid from tbl where bit_match('a&b', uid_mask);bit_construct函数:用于对表达求值并存储在响应位数组中,比如对SQL中的a、b两个条件,计算结果分别是[1,0], [0,0], [0,1]...。bit_or函数:用于将两个位数组按位进行或运算,用来聚合uid上满足的条件集合。bit_match:用于判断位数组是否符合某个表达式,比如计算a&b表达式[1,1]结果为True,[1,0]为False。
漏斗留存分析:漏斗函数
漏斗分析是常见的转化分析方法,它用于反映用户各个阶段行为的转化率,广泛应用于用户行为分析和App数据分析的流量分析、产品目标转化等数据运营与数据分析。
窗口漏斗函数(WindowFunnel)可以搜索滑动时间窗口中的事件列表,并计算条件匹配的事件列表的最大长度。留存分析是最常见的典型用户增长分析场景,用户经常需要绘制数据可视化图形,分析用户的留存情况。通过漏斗函数、留存函数的使用,可以快速计算出用户留存效果以及对应的转化率,减少复杂Join开销,提高性能。
向量检索:Proxima向量计算
Proxima是一款来自于阿里达摩院的实现向量近邻搜索的高性能软件库,相比于Fassi等开源的同类产品,Proxima在稳定性、性能等方面更为出色,能够提供业内高性能和效果显著的基础方法模块,支持图像、视频、人脸等各种应用场景。Hologres向量查询功能与Proxima深度整合,提供高性能的向量查询服务。支持快速的RNN(Radius Nearest Neighbor)搜索、KNN(K-Nearest Neighbor)搜索、dot_product向量化点积计算组件。
工程方案
在画像系统发展的不同阶段,往往对工程方案有不同的成本和性能诉求。根据实践经验,综合系统数据规模、实现成本、查询性能等三因素,总结两种典型的工程方案如下。
标签宽表方案
宽表标签方案适合标签较少(通常小于1000个),数据更新不频繁的场景。主体思路是在离线阶段把相对稳定的属性表离线聚合成宽表,将多张表的关联操作转化一张宽表的运算,新的标签列的场景通过增加列的方式实现,以表的方式提供非常灵活的标签计算,详情请参见画像分析 - 标签宽表。
RoaringBitmap优化方案
基于RoaringBitmap的超大规模画像分析场景,适合数据量大,标签规模多,需要去重处理的场景。通过结合RoaringBitmap结构化存储,实现天然去重,避免Join开销,降低运算复杂度,快速出结果。详情请参见画像分析 - RoaringBitmap优化方案。
Bit-sliced Index优化方案
基于BSI(Bit-sliced Index)的超大规模画像分析,适合用户属性标签(性别、省份)与用户行为标签(PV、订单金额等)关联分析的场景,对高基数(去重值数量大)的行为标签计算有显著优化作用。通过BSI和Roaring Bitmap,将标签去重、UNION、JOIN等复杂计算全部转化为BSI二进制运算与Roaring Bitmap交并差运算,降低运算复杂度,快速得出行为标签分析结果。详情请参见画像分析 - BSI优化方案(Beta)。
小结
Hologres通过丰富的画像分析插件支持,和自身优异的性能,被阿里集团内部多个核心业务广泛应用于标签计算、画像分析的场景,例如阿里妈妈、搜索、高德以及众多公共云用户使用。服务扩展能力和稳定性历经生产考验,这也证明Hologres是构建低开发运维成本,高稳定性扩展性画像分析平台的不二之选。