
本文介绍如何通过向量检索传统版实例快速实现文本搜索。
该文档仅适用于向量检索传统版实例,即实例引擎版本号以ha3开头,如ha3_3.10.0,目前已停售。

在售实例是向量检索易用版实例,即引擎版本号以vector_service开头,如vector_service_1.4.2,对应文档请参见易用版-文本搜索快速入门。
前置条件
开通阿里云账号并登录控制台时,会提示先创建access key才能继续使用。
创建及使用应用依赖access key参数,主账号下access key参数不能为空。
在为主账号创建access key参数后,还可以再创建RAM子账号access key通过RAM子账号进行访问,RAM子账号赋予对应访问权限,请参考授权访问鉴权规则 。(ps:子账号需要赋予AliyunSearchEngineFullAccess、AliyunSearchEngineReadOnlyAccess访问向量检索版实例的权限)。
需要用户拥有VPC环境,详情可点击此处进行查看。
购买实例
进入OpenSearch控制台,在左上角切换到OpenSearch-向量检索版:

进入向量检索版控制台后,在实例管理界面,点击创建实例。
商品版本选择向量检索版,选择地区,配置“查询节点个数”、“查询节点规格”、“数据节点数量”、“数据节点规格”、“单数据节点总存储空间”,设置“专有网络”和“虚拟交换机”,最后按提示要求设置用户名和用户密码(用于查询时校验权限,非阿里云账号密码),点击“立即购买”:
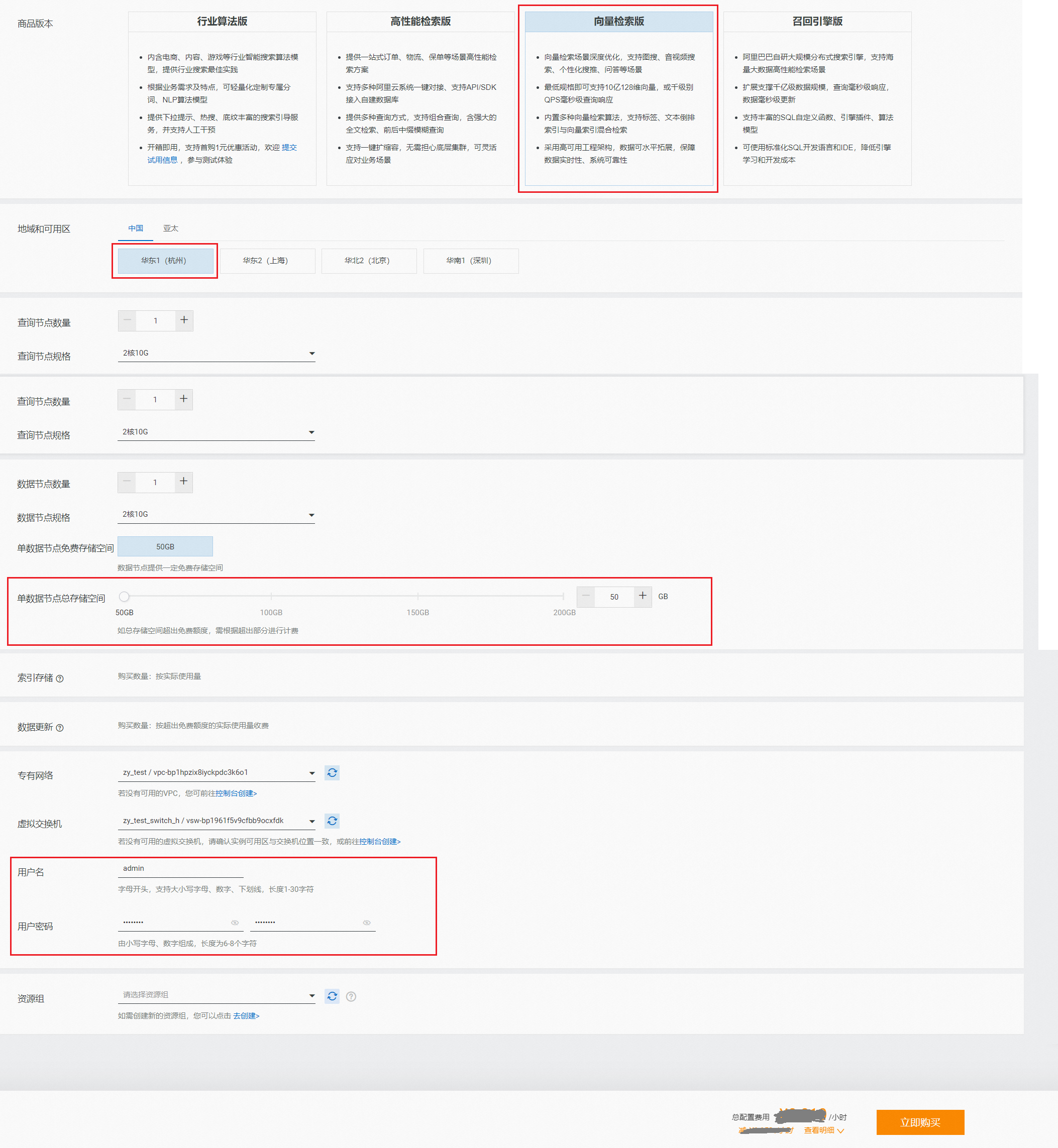
购买的查询节点和数据节点的个数及规格,需根据自身业务进行规划,确定规格后实际费用可在售卖页自动生成。
专有网络和虚拟交换的配置一定要和访问向量检索版实例的ECS机器保持一致。否则在访问向量检索版实例时会报错{'errors':{'code':'403','message':'Forbidden'}}
单数据节点存储空间有免费额度,用户也可申请额外额度,按额外额度部分收费(步长50GB)
在确认订单界面,查看服务协议,确认无误后,点击立即开通:
购买成功后,点击管理控制台,即可在实例管理界面查看已购买的向量检索版实例:
新购的实例会设置一个默认实例名称,可在操作栏下点击管理按钮,进入详情页进行修改:

点击修改图标,按提示框要求修改实例名称最后点击确认:

配置集群
新购买的实例,在其详情页中,实例状态为“待配置”,并且会自动部署一个与购买的查询节点和数据节点的个数及规格一致的空集群,之后需要为该集群配置数据源--->配置索引--->索引重建,之后才可正常搜索。
配置数据源(目前支持的数据源有“MaxCompute数据源”和“API推送数据源”)这里以MaxCompute数据源为例:点击“添加数据源”,数据源类型选择“MaxCompute”,设置project、accesskeyID、accesskeyId、accesskeySecret、Table、分组键partition,可按需选择是否开启“MaxCompute数据源”:
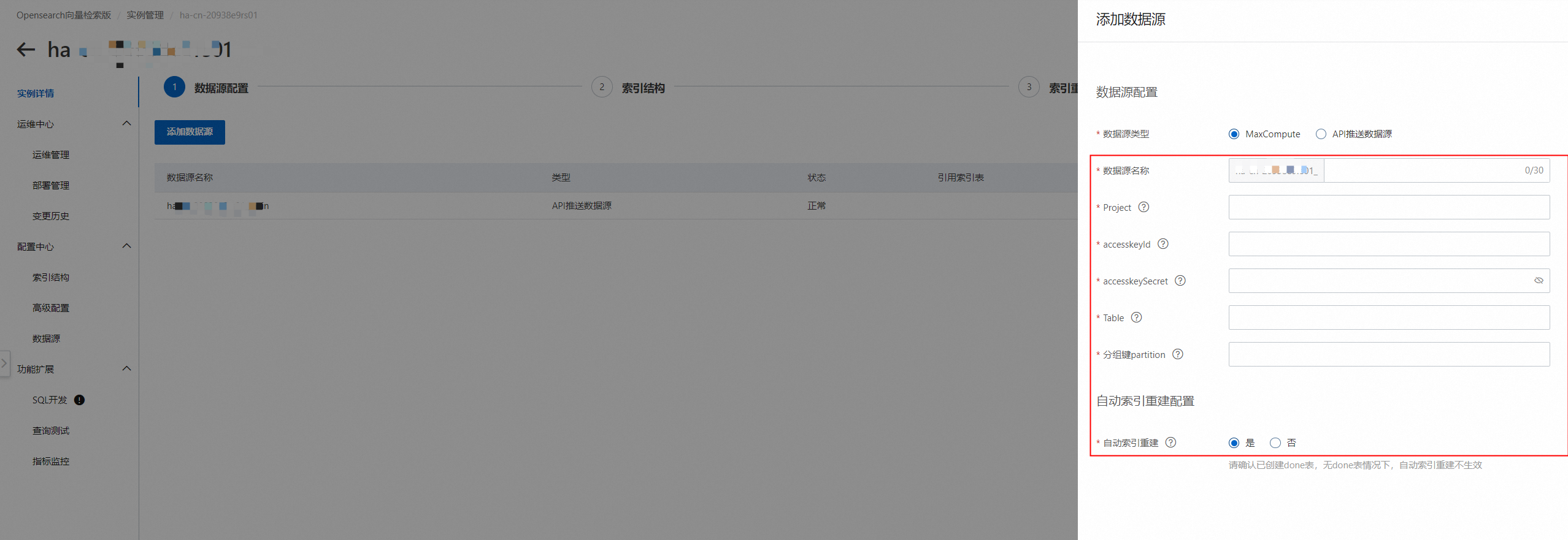
校验成功之后,点击“确定”,完成数据源的添加:
数据源配置成功后,需点击下一步配置索引结构:

2.1. 添加索引表:

2.2. 配置索引表,模板选择“向量:文本语义搜索”模板,数据情况选择“需将原始数据转为向量数据”后:

索引表:可自定义
数据源:选择 1 中配置的数据源
数据分片:根据用户购买的数据节点个数进行配置
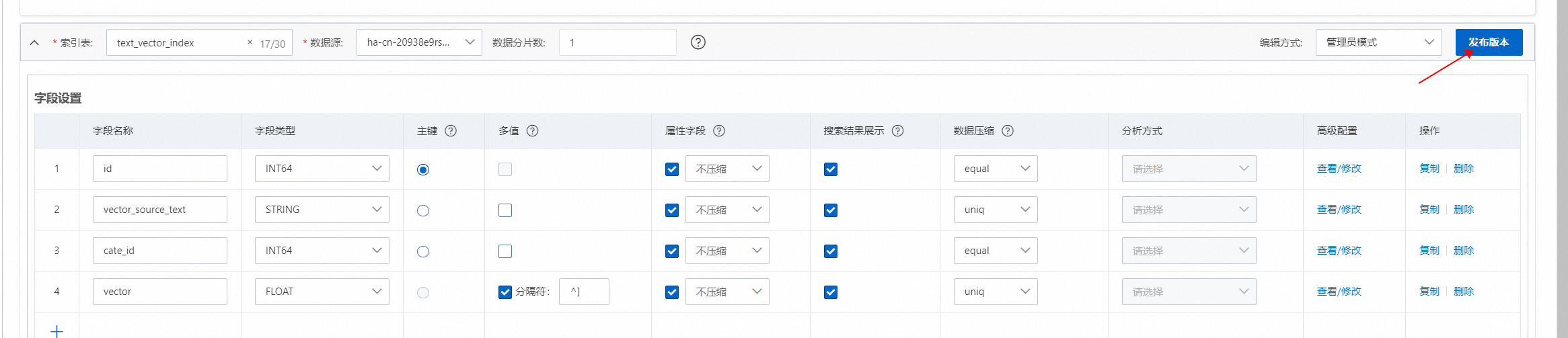
2.3. 设置字段,“向量:文本语义搜索”模板默认生成4个预置字段id(主键)、vector_source_text(向需要文本向量化的文本字段)、cate_id(类目字段)、vector(存储文本向量的字段),用户选择MaxCompute数据源后,从数据源同步的字段,展示在预置字段下方:

vector字段的高级配置:(注:如果选择“已有向量数据”,该字段的配置保持为空即可)
{
"vector_model": "ops-text-embedding-000",
"vector_modal": "text",
"vector_source_field": "vector_source_text"
}vector_model:向量模型,目前支持中英文转化两种模型
ops-text-embedding-000,短文本转向量模型,维度固定为768。
ops-text-embedding-en-000:英文短文本转向量模型,维度固定768。
vector_modal:向量类型,文本向量
vector_source_field:需要文本向量化的字段,本文中为vector_source_text。
属性和字段内容压缩:
属性字段可以选择是否压缩,默认为不压缩,选择file_compressor表示开启压缩
字段内容可以选择是否压缩,默认为不压缩,默认多值和STRING类型选择uniq,单值数值类型是equal
使用向量检索,在定义字段时有位置要求,需要按照主键字段、标签字段(非必要)、向量字段的顺序创建。(如上图所示)
要求vector_source_text的数据,长度不得超过128字节,如果超过会截取前128字节做向量预测。
如果是MaxCompute数据源,从数据源同步字段后,展示在预置字段下方。
主键字段不支持压缩。
字段压缩、属性压缩开启后将节省存储空间,但查询性能可能有所下降,详见说明文档。
支持复制字段操作,复制出的新字段(DUP字段)与原字段内容保持一致(推送不一致内容时,将采用原字段内容覆盖),如期望字段内容不一致,请手动删除DUP字段高级配置中的copy from配置。
设置索引,“向量:文本语义搜索”模板默认生成2个预置索引(主键索引、向量索引),预置索引内容均可手动修改:

索引字段设置压缩:
索引字段可以选择是否压缩,默认为不压缩,选择file_compressor表示开启压缩
主键索引不支持压缩
索引压缩,开启后将节省存储空间,但查询性能可能有所下降,详见说明文档
3.1. 为向量字段添加包含字段:
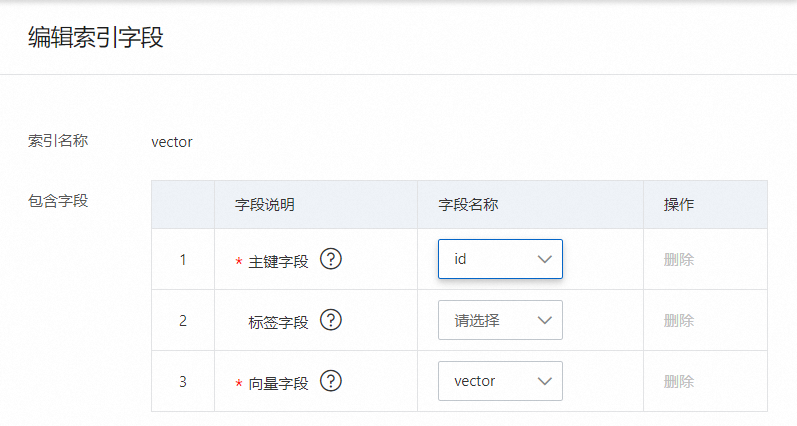
主键字段、向量字段必须填写,标签字段非必填,可以为空。
仅支持选择固定的三个字段,不支持新增。
3.2. 高级配置,向量索引需要单独配置参数,可以参考如下配置,详情可参考向量索引:
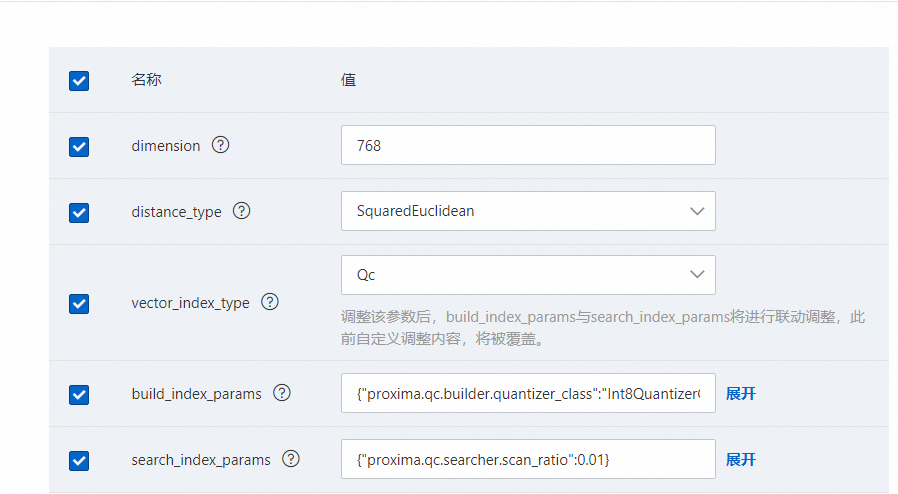
更多参数:
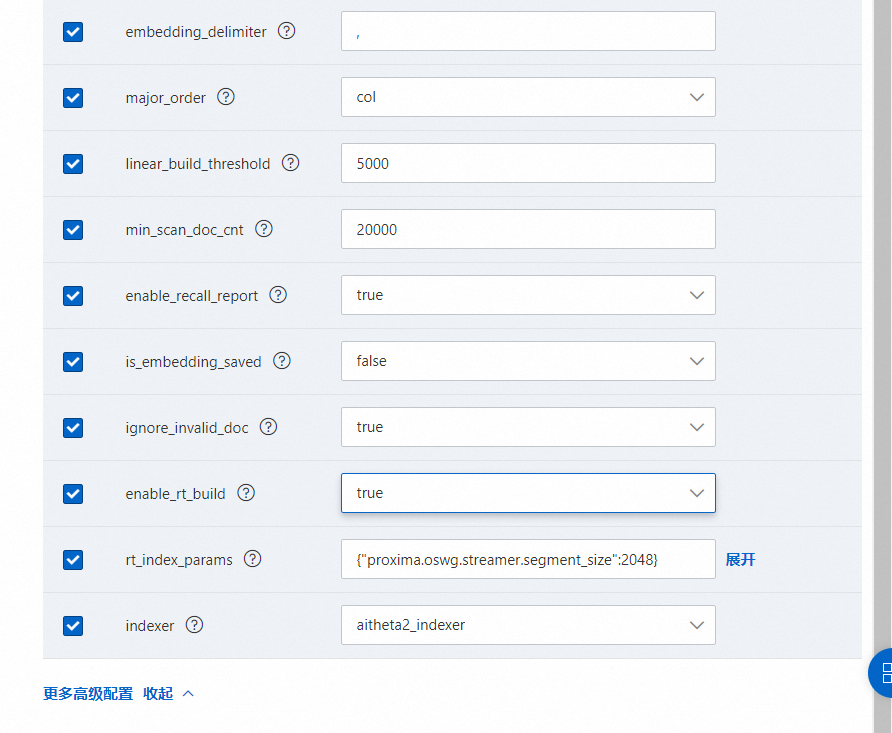
其中build_index_params的配置如下:
{
"proxima.qc.builder.quantizer_class": "Int8QuantizerConverter",
"proxima.qc.builder.quantize_by_centroid": true,
"proxima.qc.builder.optimizer_class": "BruteForceBuilder",
"proxima.qc.builder.thread_count": 10,
"proxima.qc.builder.optimizer_params": {
"proxima.linear.builder.column_major_order": true
},
"proxima.qc.builder.store_original_features": false,
"proxima.qc.builder.train_sample_count": 3000000,
"proxima.qc.builder.train_sample_ratio": 0.5
}search_index_params的配置如下:
{
"proxima.qc.searcher.scan_ratio": 0.01
}配置完成后,点击保存版本,并在弹框后填写备注(可选),点击发布:
等待索引发布完成后,可点击“下一步”进行索引重建:

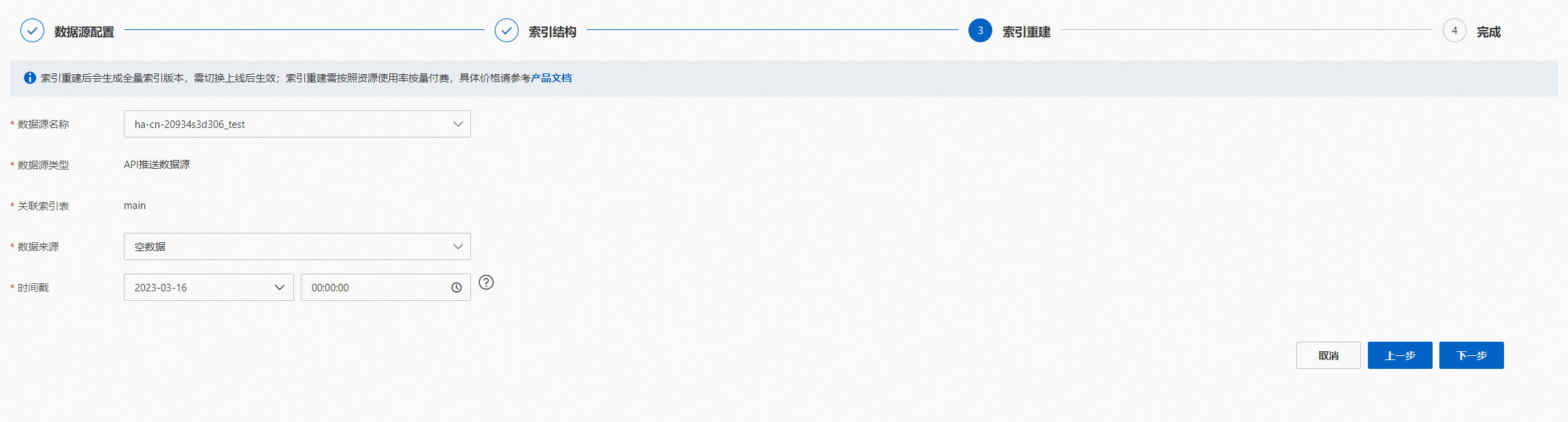
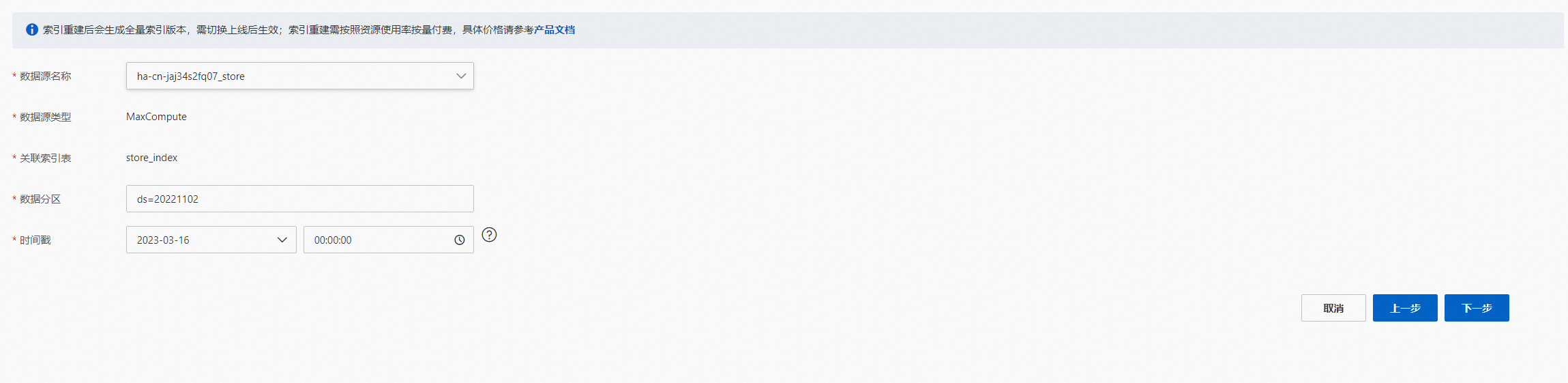
索引重建,选择索引重建需要配置的参数项,点击“下一步”:
API推送数据源:
MaxCompute数据源:
可在运维中心>历史变更>数据源变更查看索引重建进度,进度完成后即可进行查询测试:

页面查询测试:
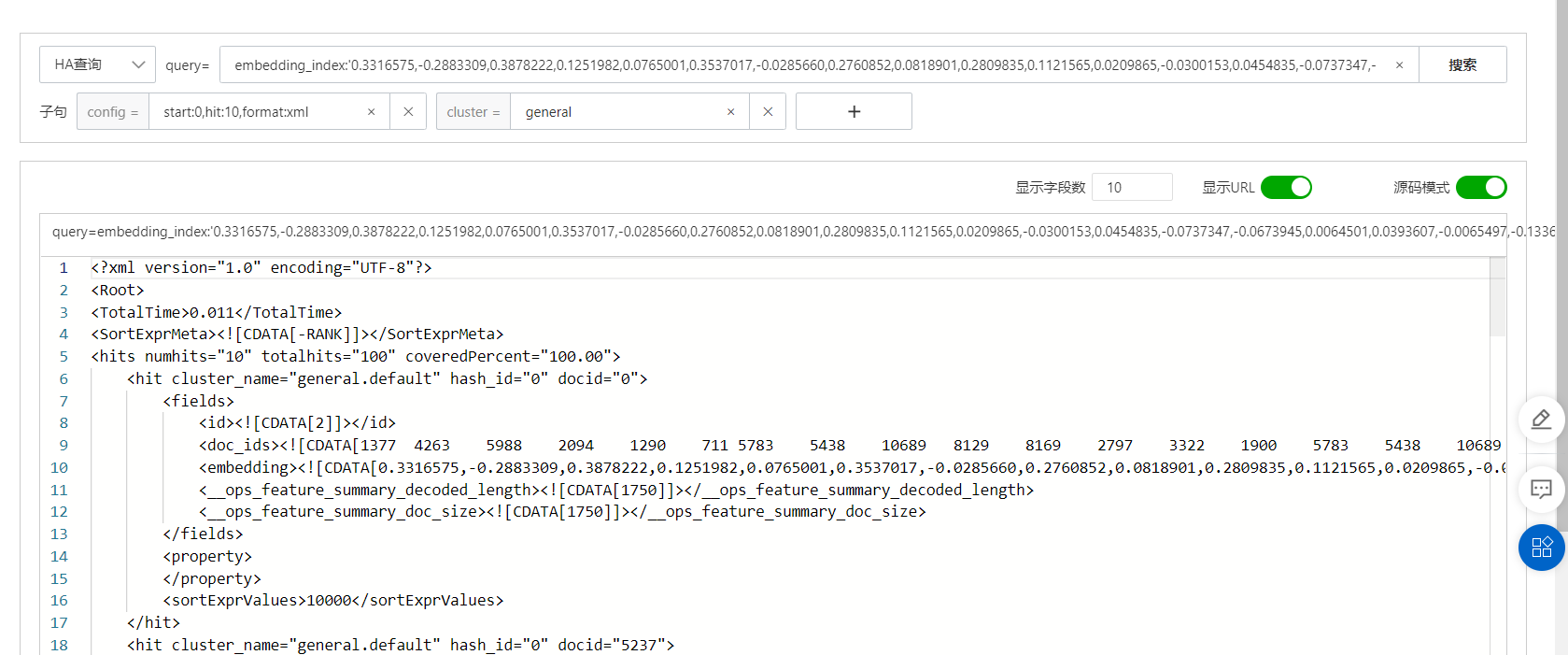
效果测试
语法介绍
query=text_index:'文本内容&modal=text&n=10&search_params={}'modal表示模态类型,modal设置为text
n表示指定向量检索返回的top结果数
文本内容需要经过base64编码
SDK中检索数据
添加依赖:
pip install alibabacloud-ha3engine搜索 demo:
# -*- coding: utf-8 -*-
from alibabacloud_ha3engine import models, client
from alibabacloud_tea_util import models as util_models
from Tea.exceptions import TeaException, RetryError
def search():
Config = models.Config(
endpoint="参考实例详情页>API入口下的API域名",
instance_id="",
protocol="http",
access_user_name="购买实例时设置的用户名",
access_pass_word="购买实例时设置的密码"
)
# 如用户请求时间较长. 可通过此配置增加请求等待时间. 单位 ms
# 此参数可在 search_with_options 方法中使用
runtime = util_models.RuntimeOptions(
connect_timeout=5000,
read_timeout=10000,
autoretry=False,
ignore_ssl=False,
max_idle_conns=50
)
# 初始化 Ha3Engine Client
ha3EngineClient = client.Client(Config)
optionsHeaders = {}
try:
# 示例1: 直接使用 ha 查询串进行搜索.
# =====================================================
query_str = "config=hit:4,format:json,fetch_summary_type:pk,qrs_chain:search&&query=text_index:'文本内容&modal=text&n=10&search_params={}'&&cluster=general"
haSearchQuery = models.SearchQuery(query=query_str)
haSearchRequestModel = models.SearchRequestModel(optionsHeaders, haSearchQuery)
hastrSearchResponseModel = ha3EngineClient.search(haSearchRequestModel)
print(hastrSearchResponseModel)
except TeaException as e:
print(f"send request with TeaException : {e}")
except RetryError as e:
print(f"send request with Connection Exception : {e}")注意事项
向量索引需要设置为CUSTOMIZED类型
该场景支持HA语法、RESTFUL API,不支持SQL