本文为您介绍如何通过提交一个使用DLC计算资源的超参数调优实验,进行LoRA模型训练,以寻找最佳超参数配置。
前提条件
首次使用AutoML功能时,需要完成AutoML相关权限授权。具体操作,请参见云产品依赖与授权:AutoML。
已完成DLC相关权限授权,授权方法详情请参见云产品依赖与授权:DLC。
已创建工作空间并关联了通用计算资源公共资源组。具体操作,请参见创建工作空间。
已开通OSS并创建OSS Bucket存储空间,详情请参见控制台快速入门。
步骤一:创建数据集
创建OSS类型的数据集,通过数据集将OSS存储目录挂载到DLC路径,用于存储超参数调优实验生成的数据文件。其中关键参数说明如下,其他参数使用默认配置,详情请参见创建数据集:从阿里云云产品。
数据集名称:自定义数据集名称。
选择数据存储:选择脚本文件所在的OSS存储目录。
属性:选择文件夹。
步骤二:新建实验
进入新建实验页面,并按照以下操作步骤配置关键参数,其他参数配置详情,请参见新建实验。参数配置完成后,单击提交。
设置执行配置。
参数
描述
任务类型
选择DLC。
资源组
选择公共资源组。
框架
选择Tensorflow。
数据集
选择步骤一中创建的数据集。
节点镜像
选择镜像地址,并在文本框中输入镜像地址
registry.cn-shanghai.aliyuncs.com/mybigpai/nni:diffusers。该镜像中已预先配置了以下数据:
预训练基础模型:模型Stable-Diffusion-V1-5已预先配置在镜像路径
/workspace/diffusers_model_data/model下。LoRa训练数据:pokemon已预先配置在镜像路径
/workspace/diffusers_model_data/data下。训练代码:diffusers已预先配置在镜像路径
/workspace/diffusers下。
机器规格
选择。
节点数量
配置为1。
节点启动命令
cd /workspace/diffusers/examples/text_to_image && accelerate launch --mixed_precision="fp16" train_text_to_image_lora_eval.py \ --pretrained_model_name_or_path="/workspace/diffusers_model_data/model" \ --dataset_name="/workspace/diffusers_model_data/data" \ --caption_column="text" \ --resolution=512 --random_flip \ --train_batch_size=8 \ --val_batch_size=8 \ --num_train_epochs=100 --checkpointing_steps=100 \ --learning_rate=${lr} --lr_scheduler=${lr_scheduler} --lr_warmup_steps=0 \ --rank=${rank} --adam_beta1=${adam_beta1} --adam_beta2=${adam_beta2} --adam_weight_decay=${adam_weight_decay} \ --max_grad_norm=${max_grad_norm} \ --seed=42 \ --output_dir="/mnt/data/diffusers/pokemon/sd-pokemon_${exp_id}_${trial_id}" \ --validation_prompts "a cartoon pikachu pokemon with big eyes and big ears" \ --validation_metrics ImageRewardPatched \ --save_by_metric val_loss超参数
每个超参数对应的约束类型和搜索空间配置如下:
lr:
约束类型:choice。
搜索空间:单击
 ,增加3个枚举值,分别为1e-4、1e-5和2e-5。
,增加3个枚举值,分别为1e-4、1e-5和2e-5。
lr_scheduler:
约束类型:choice。
搜索空间:单击
 ,增加3个枚举值,分别为constant、cosine和polynomial。
,增加3个枚举值,分别为constant、cosine和polynomial。
rank:
约束类型:choice。
搜索空间:单击
 ,增加3个枚举值,分别为4、32和64。
,增加3个枚举值,分别为4、32和64。
adam_beta1:
约束类型:choice。
搜索空间:单击
 ,增加2个枚举值,分别为0.9和0.95。
,增加2个枚举值,分别为0.9和0.95。
adam_beta2:
约束类型:choice。
搜索空间:单击
 ,增加2个枚举值,分别为0.99和0.999。
,增加2个枚举值,分别为0.99和0.999。
adam_weight_decay:
约束类型:choice。
搜索空间:单击
 ,增加2个枚举值,分别为1e-2和1e-3。
,增加2个枚举值,分别为1e-2和1e-3。
max_grad_norm:
约束类型:choice。
搜索空间:单击
 ,增加3个枚举值,分别为1、5和10。
,增加3个枚举值,分别为1、5和10。
使用上述配置可以生成648种超参数组合,后续实验会分别为每种超参数组合创建一个Trial,在每个Trial中使用一组超参数组合来运行脚本。
设置Trial配置。
参数
描述
指标类型
选择stdout。
计算方式
选择best。
指标权重
key:val_loss=([0-9\\.]+)。
Value:1。
指标来源
配置为cmd1。
优化方向
选择越大越好。
设置搜索配置。
参数
描述
搜索算法
选择TPE。
最大搜索次数
配置为5。
最大并发量
配置为2。
开启earlystop
打开开关。
start step
5
步骤三:查看实现详情和运行结果
在实验列表页面,单击实验名称,进入实验详情页面。
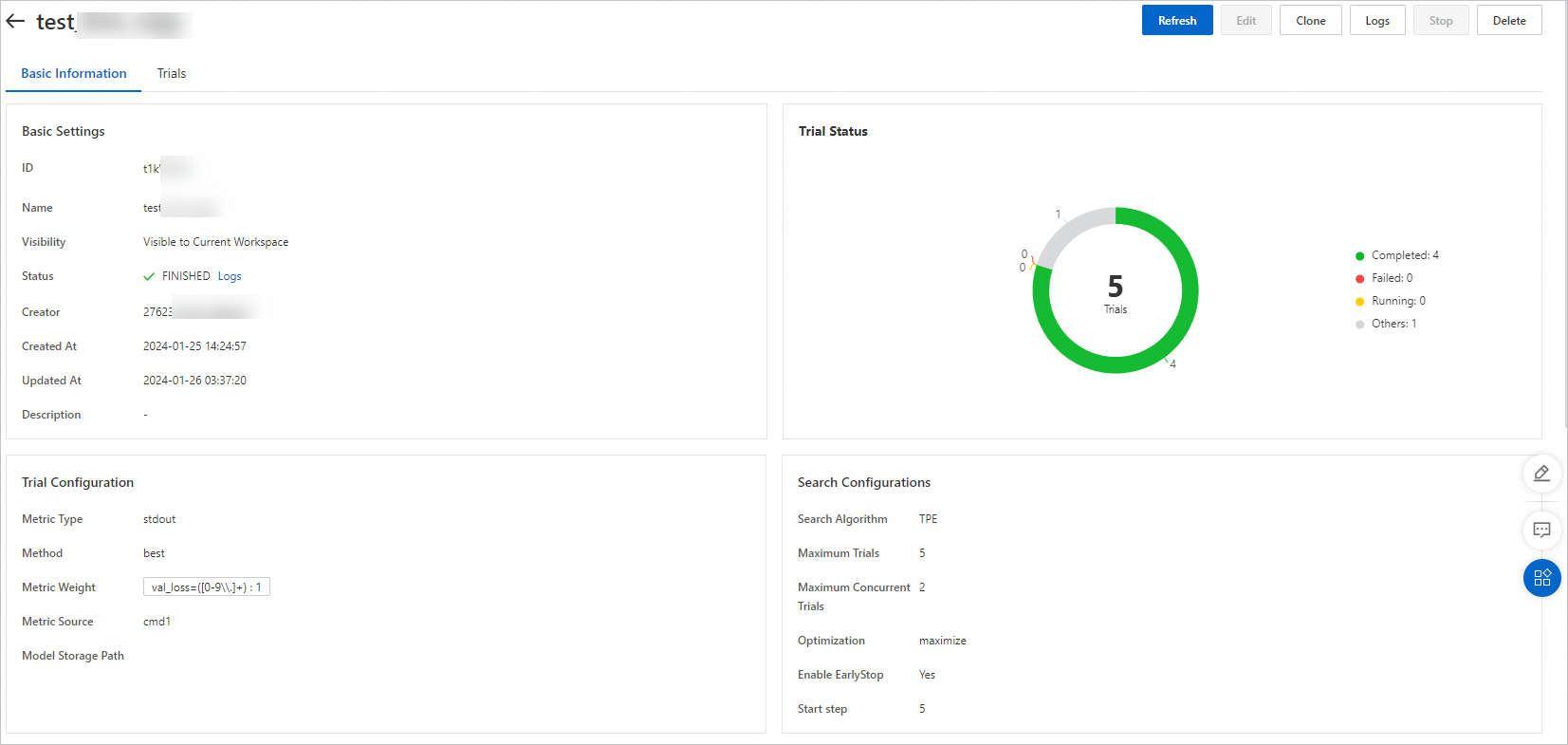
在该页面,您可以查看Trial的执行进度和状态统计。实验根据配置的搜索算法和最大搜索次数自动创建5个Trial。
单击Trial列表,您可以在该页面查看该实验自动生成的所有Trial列表,以及每个Trial的执行状态、最终指标和超参数组合。
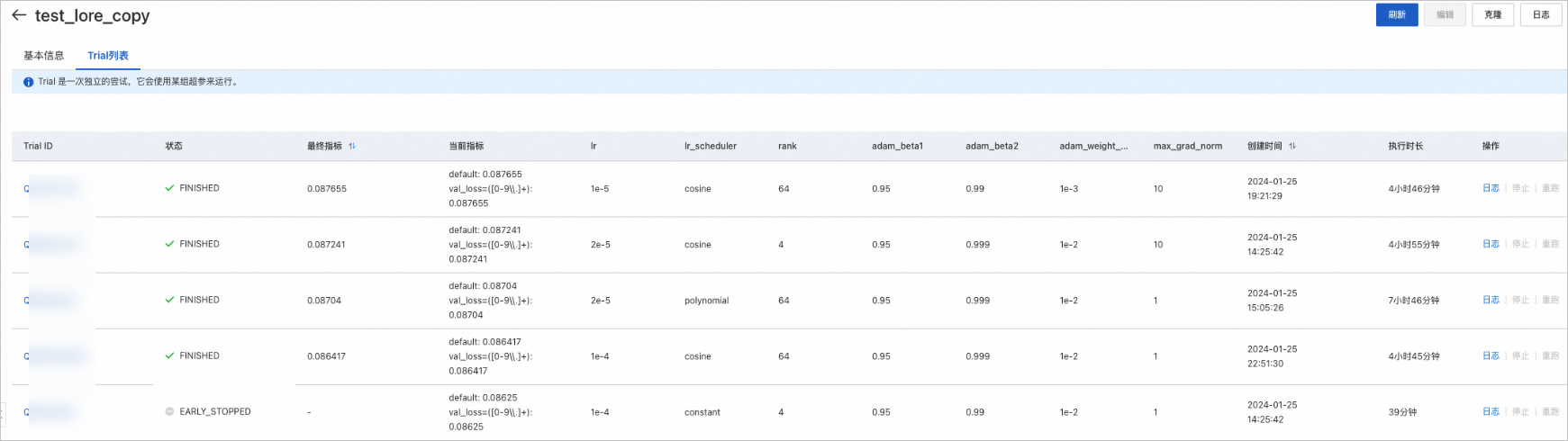
Trial运行时长大约持续5个小时。根据配置的优化方向(越大越好),从上图可以看出,最终指标为0.087655对应的超参数组合较优。
步骤四:部署及推理模型服务
下载LoRA模型,并进行模型文件格式转换。
实验执行成功后,会在启动命令指定的
output_dir目录下生成模型文件。您可以前往该实验配置的数据集挂载的OSS路径的checkpoint-best目录中,查看并下载模型文件。详情请参见控制台快速入门。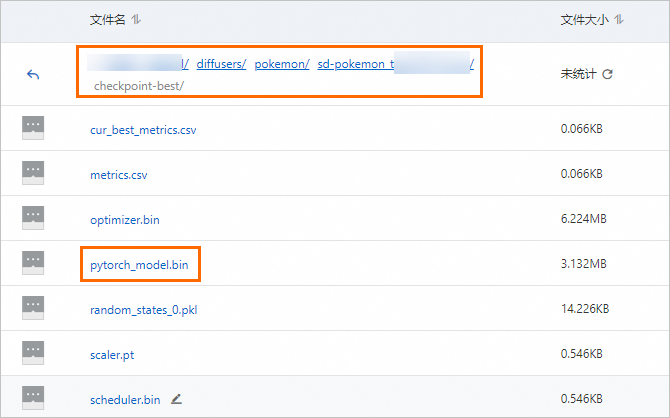
执行以下命令,将pytorch_model.bin转换成pytorch_model_converted.safetensors。
wget http://automl-nni.oss-cn-beijing.aliyuncs.com/aigc/convert.py python convert.py --file pytorch_model.bin
部署Stable Diffusion WebUI服务。
进入模型在线服务(EAS)页面。具体操作,请参见步骤一:进入模型在线服务页面。
在模型在线服务(EAS)页面,单击部署服务,在自定义模型部署区域,单击自定义部署。
在新建服务页面,配置以下关键参数后,单击部署。
参数
描述
服务名称
自定义服务名称。本案例使用的示例值为:sdwebui_demo。
部署方式
选择镜像部署AI-Web应用。
镜像选择
在PAI平台镜像列表中选择stable-diffusion-webui;镜像版本选择4.2-standard。
说明由于版本迭代迅速,部署时镜像版本选择最高版本即可。
模型配置
单击填写模型配置,进行模型配置。
模型配置选择OSS挂载,将OSS路径配置为步骤1中创建的OSS Bucket路径。例如:
oss://bucket-test/data-oss/。挂载路径:将您配置的OSS文件目录挂载到镜像的
/code/stable-diffusion-webui路径下。例如配置为:/code/stable-diffusion-webui/data-oss。是否只读:开关关闭。
运行命令
镜像配置完成后,系统会自动配置运行命令。您需要在运行命令中增加
--data-dir 挂载目录,其中挂载目录需要与模型配置中挂载路径的最后一级目录一致。本方案在运行命令末尾增加--data-dir data-oss。资源配置方法
选择常规资源配置。
资源配置选择
必须选择GPU类型,实例规格推荐使用ml.gu7i.c16m60.1-gu30(性价比最高)。
系统盘配置
将额外系统盘设置为100 GB。
单击部署。
PAI会自动在您配置的OSS空文件目录下创建如下目录结构,并复制必要的数据到该目录下。
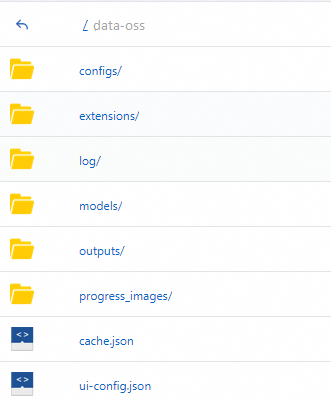
上传模型文件到指定路径下,然后单击目标服务操作列下的
 >重启服务,服务重启成功后,即可生效。
>重启服务,服务重启成功后,即可生效。将上述步骤生成的模型文件pytorch_model_converted.safetensors上传到OSS的
models/lora/目录中。将revAnimated_v122基础模型,上传到OSS的
models/Stable-diffusion/目录中。
单击目标服务的服务方式列下的查看Web应用,在WebUI页面进行模型推理验证。
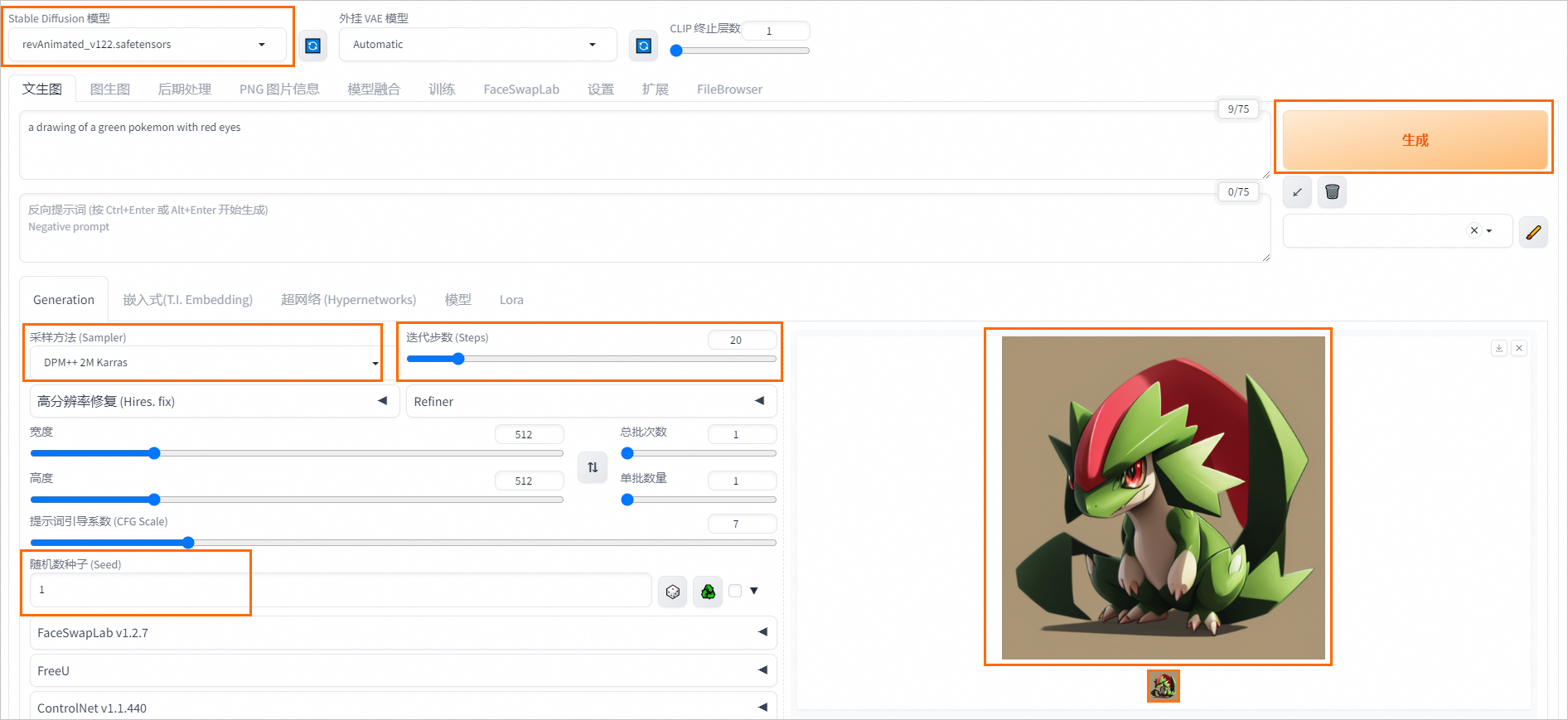
使用Stable Diffusion模型
在WebUI页面配置以下参数:
Stable Diffusion模型:选择revAnimated_v122.safetensors。
正向提示词Prompt:在编辑框中输入请求数据,例如
a drawing of a green pokemon with red eyes。采样方法(Sampler):选择DPM++2M Karras。
迭代部署(Steps):配置为20。
随机数种子(Seed):配置为1。
参数配置完成后,单击生成。输出结果示例如下:
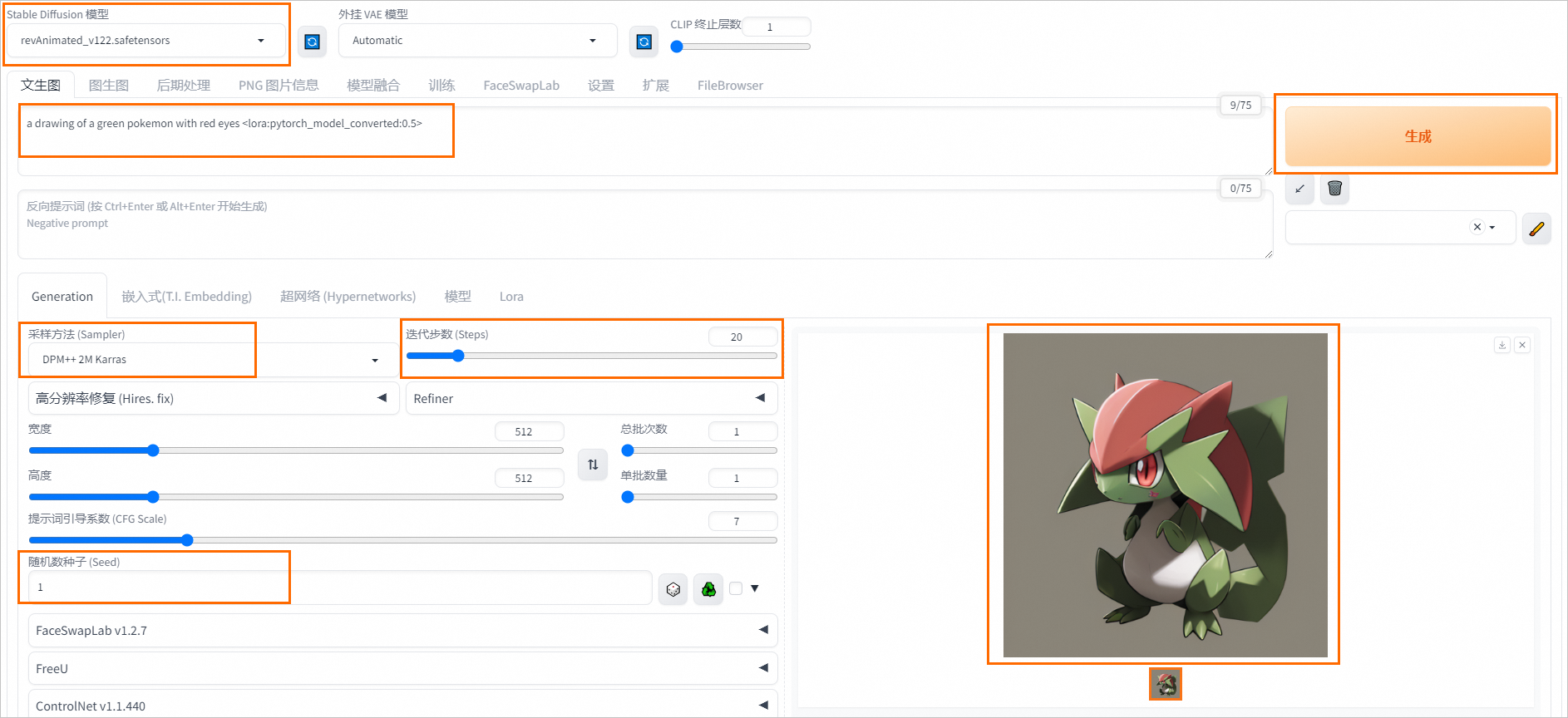
使用Stable diffusion和LoRA模型
在WebUI页面配置以下参数:
Stable Diffusion模型:选择revAnimated_v122.safetensors。
正向提示词Prompt:在编辑框中输入请求数据,并将Lora模型的权重从<lora:pytorch_model_converted:1>调整为<lora:pytorch_model_converted:0.5>。例如
a drawing of a green pokemon with red eyes <lora:pytorch_model_converted:0.5>。单击Lora页签,确认模型pytorch_model_converted.safetensors已成功加载。
采样方法(Sampler):选择DPM++2M Karras。
迭代部署(Steps):配置为20。
随机数种子(Seed):配置为1。
参数配置完成后,单击生成。输出结果示例如下: