
本文为您介绍如何提交Slurm类型的训练任务。
前提条件
已开通DLC后付费,并创建默认工作空间。具体操作,请参见开通PAI并创建默认工作空间。
已创建OSS存储空间(Bucket),详情请参见控制台快速入门。
提交Slurm类型的训练任务
步骤一:准备训练脚本和数据集
分别准备如下训练数据集和训练脚本文件,并上传到已创建的对象存储OSS存储空间中,详情请参见控制台快速入门。
训练数据集:mnist.npz。
训练脚本文件:mnist_train.py。代码示例如下:
import numpy as np import tensorflow as tf from tensorflow.keras import layers, models # 从本地文件加载MNIST数据集 with np.load('/mnt/test/mnist.npz', allow_pickle=True) as data: train_images = data['x_train'] train_labels = data['y_train'] test_images = data['x_test'] test_labels = data['y_test'] # 归一化数据集 train_images, test_images = train_images / 255.0, test_images / 255.0 # 增加一个通道维度 train_images = train_images[..., tf.newaxis] test_images = test_images[..., tf.newaxis] # 构建模型 model = models.Sequential([ layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)), layers.MaxPooling2D((2, 2)), layers.Conv2D(64, (3, 3), activation='relu'), layers.MaxPooling2D((2, 2)), layers.Conv2D(64, (3, 3), activation='relu'), layers.Flatten(), layers.Dense(64, activation='relu'), layers.Dense(10) ]) # 编译模型 model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) # 创建TensorBoard回调 tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="/mnt/test/mnist_logs", histogram_freq=1) # 训练模型 model.fit(train_images, train_labels, epochs=5, validation_data=(test_images, test_labels), callbacks=[tensorboard_callback])
步骤二:提交训练任务
进入新建任务页面。
登录PAI控制台,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击进入DLC。
在分布式训练(DLC)页面,单击新建任务。
在新建任务页面,配置以下关键参数,其他参数配置说明,请参见创建训练任务。
参数
描述
参数
描述
基本信息
任务名称
自定义任务名称,例如mnist_cnn_tb。
环境信息
节点镜像
基于Linux操作系统的镜像,无其他特殊要求。本方案使用的镜像为官方镜像>tensorflow-training:2.11-gpu-py39-cu112-ubuntu20.04。
直接挂载
当脚本文件过大时,您可以选择采用挂载的方式,将脚本文件挂载到容器的指定目录下进行操作。
本任务以对象存储(OSS)挂载为例,为您说明如何进行挂载配置:
单击OSS,并配置以下参数:
OSS:选择脚本文件mnist_train.py所在的对象存储OSS的存储路径。
挂载路径:表示将脚本文件挂载到DLC容器的指定路径。例如
/mnt/test。
启动命令
任务需要执行的命令:
必须以
#!/bin/bash开头。系统允许自定义SBATCH参数配置,但建议避免手动设定资源分配参数,因为平台已自动化该过程,能根据需求动态分配资源。
# 支持。 #SBATCH --job-name=mnist_cnn_tb # 作业名。 #SBATCH --output=/mnt/test/mnist_train_%j.out # 标准输出与错误输出的文件名。 # 不建议使用,不保障正确性。 #SBATCH --cpus-per-task=<N> # 指定每个任务请求的CPU核心数。 #SBATCH --mem=<M> # 指定所需的内存量,单位为MB。 #SBATCH --mem-per-cpu=<M> # 每个CPU核心的内存需求。 #SBATCH --gres=<resource>:<N> # 请求特定类型的资源,例如GPU(如gpu:1)或其他通用资源。 #SBATCH --nodes=<N> # 指定请求的节点数。 #SBATCH --ntasks=<N> # 指定总共要运行的任务数。 #SBATCH --ntasks-per-node=<N> # 每个节点要运行的任务数。 #SBATCH --partition=<partition> # 指定要提交作业的分区。 #SBATCH --time=<time> # 指定作业的最大运行时间。 #SBATCH --account=<account> # 指定要使用的账户。
本任务使用的启动命令如下所示:
#!/bin/bash #SBATCH --job-name=mnist_cnn_tb # 作业名 #SBATCH --output=/mnt/test/mnist_train_%j.out # 标准输出与错误输出的文件名 # 该命令启动训练脚本。 srun /usr/bin/python3 /mnt/test/mnist_train.py资源信息
资源来源
本任务选择公共资源。您也可以根据需要选择其他类型的资源。
框架
选择Slurm。
任务资源
需要分别配置Master和Worker资源如下:
节点数量:配置为1。
资源规格:配置为ecs.g6.xlarge。
保留时长
建议将任务执行完成后的实例保留时长设为1小时,以便在任务执行不成功时能进入容器内部进行问题排查。
开启任务保留会持续占用系统资源。
单击确定。
系统将自动弹出任务预检测对话框。
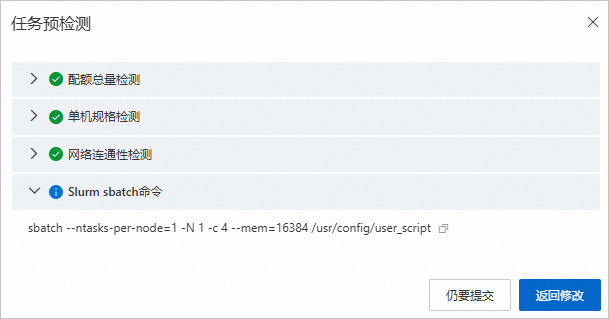
其中Slurm sbatch命令是系统自动生成的用于提交任务的命令。一旦任务被提交,系统将会自动将对应的脚本文件挂载到目录
/usr/config/user_script下,并按所选的资源参数来执行该脚本。单击仍要提交。
页面将自动跳转到分布式训练(DLC)页面,您可以在该页面查看已成功提交的训练任务。
管理训练任务
您可以对已创建的Slurm类型的任务进行以下管理操作,更详细的内容介绍,请参见管理训练任务。
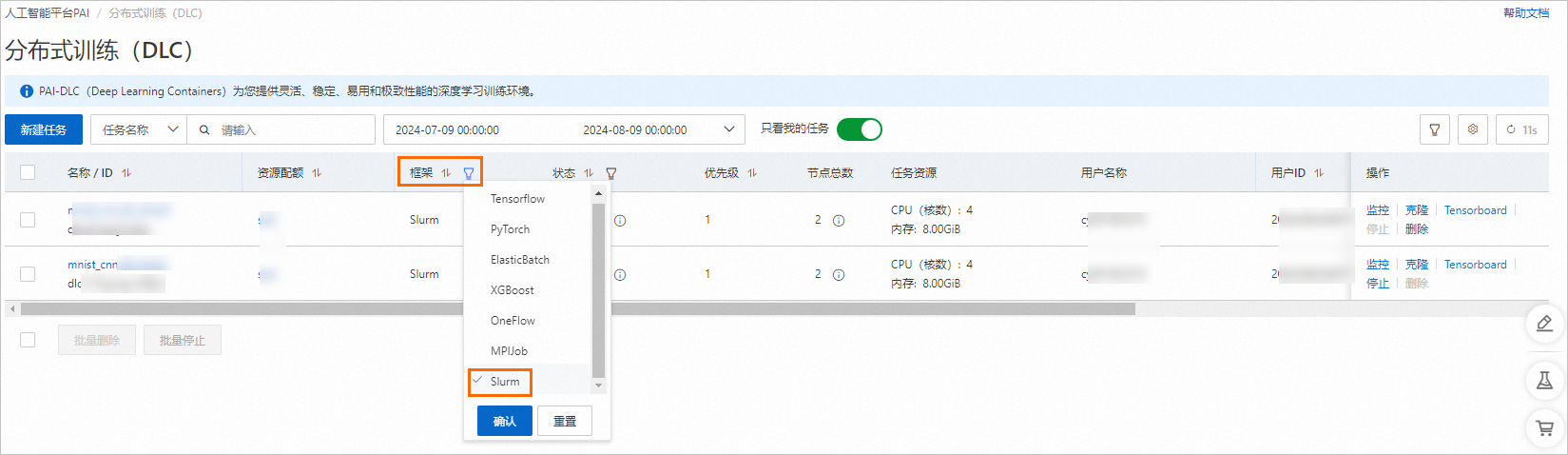
通过过滤框架类型,来筛选Slurm类型的任务。
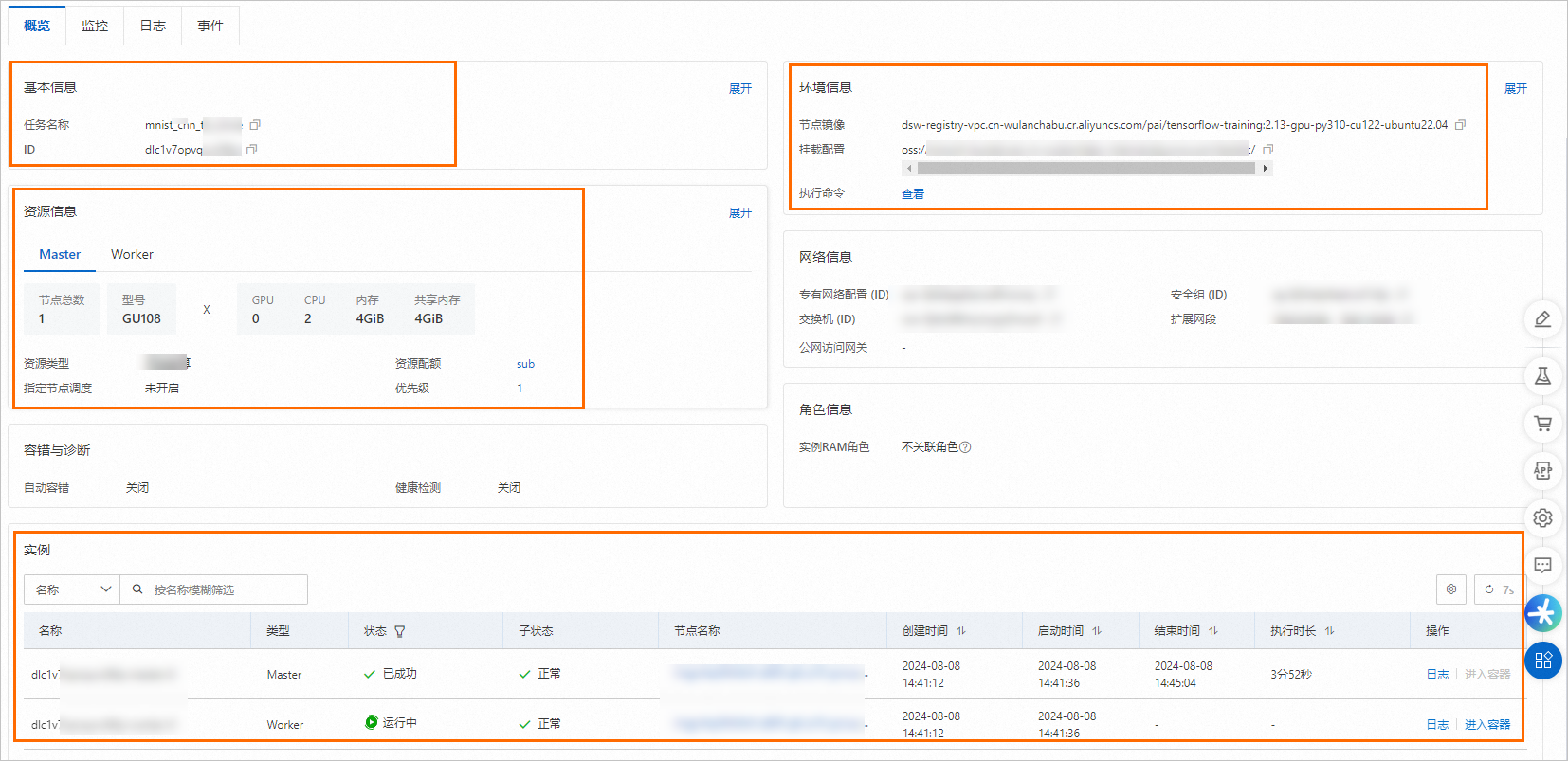
查看任务详情。
在分布式训练(DLC)页面,单击目标任务名称,进入任务概览页面,在该页面查看Surm类型任务的基本信息、资源信息、环境信息以及实例信息等。
定位任务运行失败的原因
本任务在启动命令中配置了错误输出日志路径
/mnt/test/mnist_train_%j.out,如下图所示: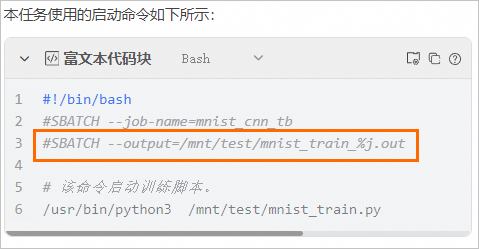 当任务运行失败时,您可以在任务概览页面的实例区域,单击失败实例操作列下的进入容器,在指定目录下查看错误输出日志mnist_train_%j.out。您也可以前往挂载的OSS存储路径中查看。本任务示例如下图所示,您的任务以实际为准。
当任务运行失败时,您可以在任务概览页面的实例区域,单击失败实例操作列下的进入容器,在指定目录下查看错误输出日志mnist_train_%j.out。您也可以前往挂载的OSS存储路径中查看。本任务示例如下图所示,您的任务以实际为准。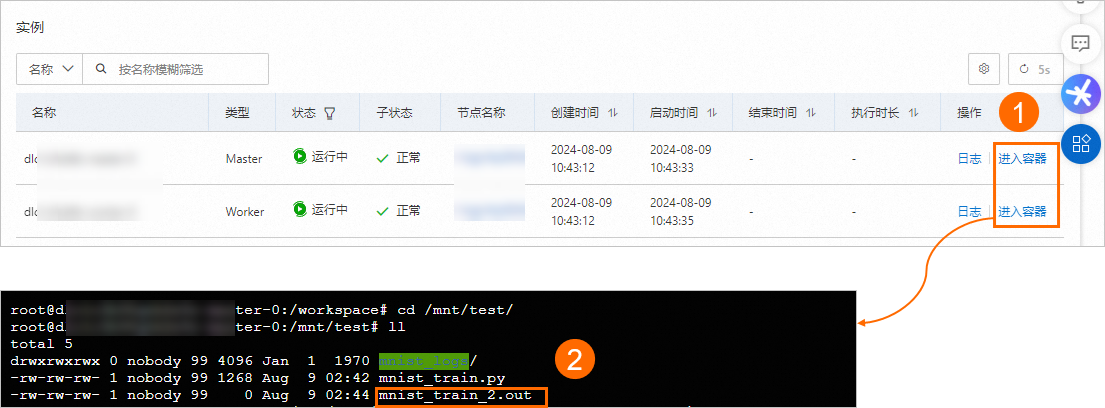
查看任务结果
本任务在训练脚本中预置了如图所示输出路径以保存结果。当任务运行成功后,您可以使用以下两种方法查看任务结果:

在任务概览页面的实例区域,单击目标实例操作列下的进入容器,在指定目录下查看节点运行日志。本任务示例如下图所示,您的任务以实际为准。
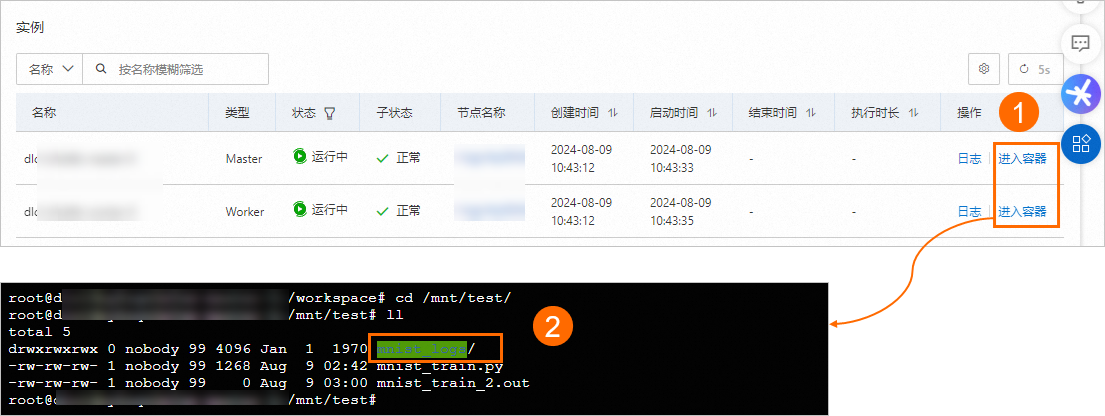
在创建训练任务时已挂载的对象存储OSS的路径中,查看任务结果。
相关文档
分布式训练DLC(Deep Learning Containers)是基于云原生容器服务的深度学习训练平台,为开发者和企业提供灵活、稳定、易用和高性能的机器学习训练环境。您可以使用DLC提交多种类型的训练任务,更多关于DLC的内容介绍,请参见分布式训练(DLC)。
- 本页导读 (1)
- 前提条件
- 提交Slurm类型的训练任务
- 步骤一:准备训练脚本和数据集
- 步骤二:提交训练任务
- 管理训练任务
- 相关文档