
灵骏智算资源为您提供高性能AI训练、高性能计算所需的异构计算算力服务,用于提交DLC训练任务或创建DSW实例。本文为您介绍PAI灵骏智算服务从开通到使用的最佳实践。
前提条件
已开通PAI(DLC、DSW)后付费,详情请参见开通并创建默认工作空间。
已创建VPC、交换机和安全组,详情请参见创建和管理专有网络和创建安全组。
说明如果您有访问公网的需求,需要为该VPC开通公网访问能力,具体操作,请参见使用公网NAT网关SNAT功能访问互联网。
已提交工单,申请添加灵骏智算使用白名单。
如果使用RAM角色提交DLC分布式训练任务,需要完成信任策略配置,配置详情请参见RAM角色登录并使用PAI。
其中为Role配置的权限策略在当前的实现中会影响到PAI DLC的任务运行,您可参考以下权限策略制定您的自定义策略(AliyunPAIDLCDefaultRolePolicy):
使用限制
支持的任务类型
当前灵骏智算资源仅支持TensorFlow、PyTorch、ElasticBatch、MPIJob、Slurm和Ray类型的训练任务。
当前仅智算CPFS类型的数据集暂不支持加速。
准备工作
准备灵骏智算资源
前往AI计算资源>资源池页面,在灵骏智算资源页签购买灵骏智算资源。具体操作,请参见新建资源组并购买灵骏智算资源。
前往AI计算资源>资源配额(Quota)页面,通过创建资源配额来分配灵骏智算资源。具体操作,请参见灵骏智算资源配额。
准备数据集
创建数据集
使用灵骏智算资源提交DLC任务或创建DSW实例时,支持使用OSS、NAS、CPFS类型的数据集,下文以智算CPFS类型的数据集为例为您介绍准备数据集的操作流程。
如果您的训练任务对数据读取有很高的读写速度与性能要求,建议您使用智算CPFS数据集。
购买智算CPFS资源。
前往AI计算资源>资源池页面,单击页面右上方的新建CPFS。
在左侧导航栏选择,然后单击创建文件系统。
在弹出的选择文件系统对话框中单击创建CPFS智算版,选择配置容量后,根据界面提示完成付费、下单。
新建CPFS数据集。
参数配置完成后单击提交,完成数据集创建。
加速数据集
您可以参考以下操作步骤开启数据集加速功能:
目前,智算CPFS类型的数据集不支持开启加速功能。
授权并购买数据集加速实例。具体操作,请参见云产品依赖与授权:DatasetAccelerator和创建及管理数据集加速实例。
为数据集开启加速功能。
开启数据集加速:已有数据集
主要流程如下:
创建一个支持开启数据集加速功能的数据集,例如OSS或CPFS类型的数据集。
在数据集详情页面版本信息区域,单击版本加速,选择上述步骤中创建的数据集加速实例并配置加速挂载点。
说明挂载点类型需选择VPC,如果使用灵骏智算资源提交训练任务,需要选择灵骏智算资源绑定的VPC与交换机。
完成配置后,单击提交。
开启数据集加速:新建数据集
在新建数据集时,您可以直接打开版本加速开关,并配置数据集加速实例。
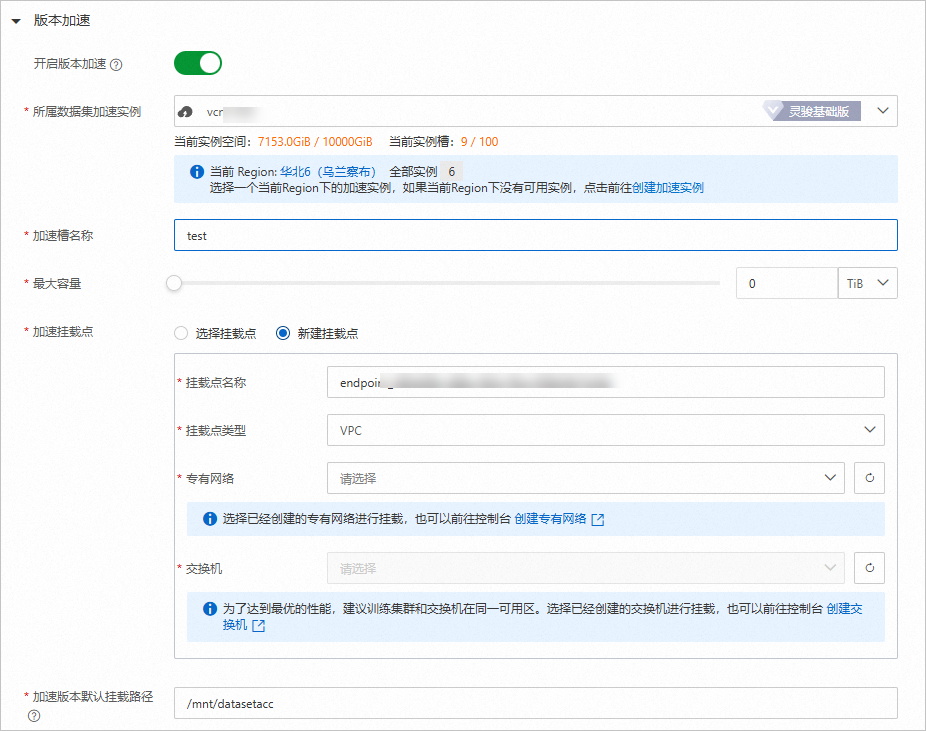
准备自定义镜像环境
您可以使用PAI提供的官方镜像,也可以使用自定义构建的镜像。当使用自定义镜像提交DLC任务时,需要在镜像中安装RDMA库才能使用RDMA。具体使用要求及配置方法如下:
环境要求
CUDA >= 11.2
NCCL >= 2.12.10
Python3
安装RDMA库
使用自定义镜像时,需在Dockerfile中手动安装RDMA库。安装RDMA库的示例代码如下。
RUN apt-get update && \
apt-get install -y --allow-downgrades --allow-change-held-packages --no-install-recommends libnl-3-dev libnl-route-3-dev libnl-3-200 libnl-route-3-200 iproute2 udev dmidecode ethtool && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
RUN cd /tmp/ && \
wget http://pythonrun.oss-cn-zhangjiakou.aliyuncs.com/rdma/nic-libs-mellanox-rdma-5.2-2/nic-lib-rdma-core-installer-ubuntu.tar.gz && \
tar xzvf nic-lib-rdma-core-installer-ubuntu.tar.gz && \
cd nic-lib-rdma-core-installer-ubuntu && \
echo Y | /bin/bash install.sh && \
cd .. && \
rm -rf nic-lib-rdma-core-installer-ubuntu && \
rm -f nic-lib-rdma-core-installer-ubuntu.tar.gz提交DLC分布式作业
支持配置的系统环境变量
公共环境变量
DLC会自动注入以下NCCL相关的环境变量,作业中不需要再进行配置:
NCCL_IB_HCA
NCCL_IB_TC
NCCL_IB_SL
NCCL_IB_GID_INDEX
NCCL_SOCKET_IFNAME
Pytorch环境变量
在PyTorch的分布式训练过程中,Master和Worker是两个不同的角色,它们需要建立连接并通信。而在DLC中,提供了一些环境变量来同步必要的信息,例如将Master的地址和端口号同步给Worker。以下是DLC设置的PyTorch环境变量:
环境变量名 | 描述 |
MASTER_ADDR | Master节点地址。例如: |
MASTER_PORT | Master节点端口。例如:23456。 |
WORLD_SIZE | 分布式作业的节点总数。例如提交了一个包含1个Master、1个Worker的作业,WORLD_SIZE会设置为2。 |
RANK | 节点的Index。例如提交一个包含1个Master、2个Worker的作业,Master上设置的RANK为0,Worker-0设置的RANK为1, Worker-1 设置的RANK为2。 |
TensorFlow环境变量
TensorFlow分布式作业通过TF_CONFIG环境变量来构建分布式的网络拓扑信息,对于TensorFlow,DLC设置了如下环境变量:
环境变量名 | 描述 |
TF_CONFIG | TensorFlow分布式网络拓扑信息,示例如下: { "cluster":{ "worker":[ "dlc1y3madghdduqi-worker-0.t1612285282502324.svc:2222", "dlc1y3madghdduqi-worker-1.t1612285282502324.svc:2222" ] }, "task":{ "type":"worker", "index":0 }, "environment":"cloud" } |
提交分布式作业
登录PAI控制台,选择地域和目标工作空间后,进入分布式训练(DLC)页面。在该页面新建任务,核心参数配置如下,其他参数配置说明请参见创建训练任务。
参数 | 描述 | |
环境信息 | 节点镜像 | 选择PAI预置的官方镜像或自定义镜像。 |
数据集 | 单击自定义数据集,选择已准备的OSS、NAS或智算CPFS数据集。 | |
启动命令 | 根据需要在分布式作业的每个Pod中执行的脚本命令,示例命令如下,实际执行时,您需要根据实际情况进行修改。 | |
资源信息 | 资源类型 | 选择灵骏智算。 |
资源来源 | 选择资源配额。 | |
资源配额 | 选择已创建的灵骏智算资源配额。 | |
任务资源 | 填写节点资源申请量,包括GPU(卡数)、CPU(核数)、内存(GiB)和共享内存(GiB)。 | |
任务提交成功后,您可以随时查看任务详情并进行相应的管理操作。具体操作,请参见查看训练详情和管理训练任务。
创建及管理DSW实例
登录PAI控制台,选择地域和目标工作空间后,进入交互式建模(DSW)页面。在该页面新建实例并配置以下关键参数,其他参数配置详情,请参见创建及管理DSW实例。
参数 | 描述 | |
资源信息 | 资源配额 | 选择已创建的灵骏智算资源配额。 |
资源规格 | 填写资源申请量,包括GPU(卡数)、CPU(核数)、内存(GiB)和共享内存(GiB)。 | |
环境信息 | 镜像 | PAI预置了官方镜像,镜像中预装了常用的软件和机器学习框架,如果这些框架不符合您的需求,您可以使用自定义镜像。 |
数据集挂载 | 单击自定义数据集,选择已创建的数据集。 | |
实例创建成功后,您可以访问或管理您的DSW实例。具体操作,请参见控制台访问DSW实例或管理DSW实例。