CNP(Cloud Native Application Performance Optimizer),一站式云原生应用性能评测、分析和优化的平台型产品,致力于提升云上应用性能,自动化高效评测灵骏集群训练性能,提供性能优化建议。本文为您介绍如何使用CNP进行性能评测。
CNP平台入口
登录灵骏控制台。
在左侧导航栏,点击性能评测 > CNP性能评测平台。
您可以在CNP平台中发起性能评测、查看评测结果。
在页面左下角,点击返回可以快速回到灵骏控制台。
发起评测
第一步:选择集群
在欢迎页单击开始评测或在性能评测页单击发起评测,进入评测流程第一步:选择集群。
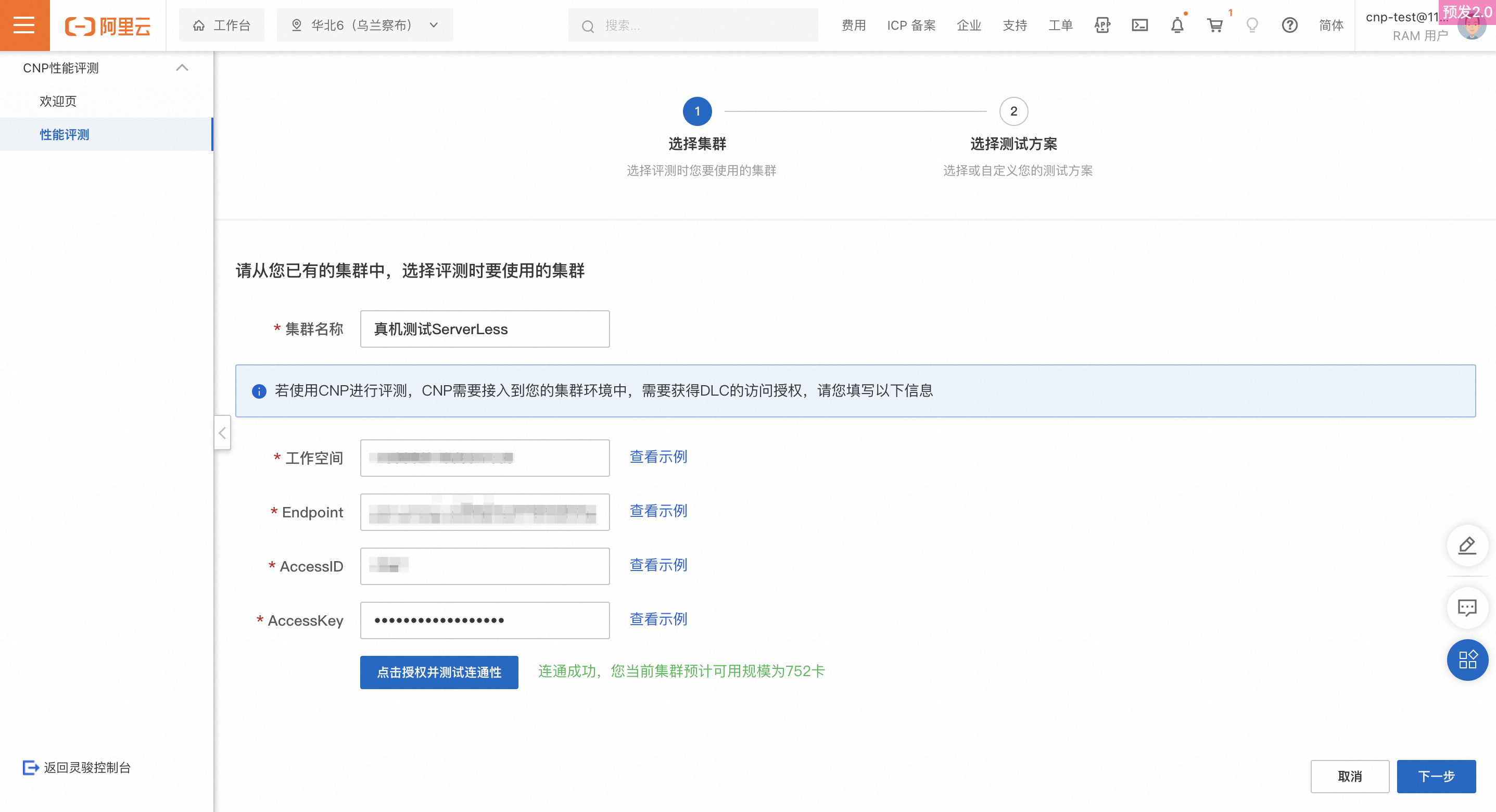
集群名称:从您当前所拥有的集群中,选择执行评测时要使用的一个集群。
授权DLC访问信息:填写完成后,单击下方测试连通性,如果成功访问则会返回连通成功,否则会给出失败原因,常见的失败原因如下所示:
失败原因枚举
建议操作
连接超时
开通访问CNP的白名单后再次尝试
信息填写有误
AccessID、Accesskey、工作空间、Endpoint至少有一个信息填写错误,检查信息后再次尝试
获取STS token失败(D3001)
创建SLR失败(D3002)
创建Arms实例失败(D3003)
检查Arms服务失败(D3004)
开通ARMS服务
获取Arms信息失败(D3005)
无权限创建SLR(D3006)
授权SLR
连通性测试通过后,点击下一步,进入第二步:选择测试方案。
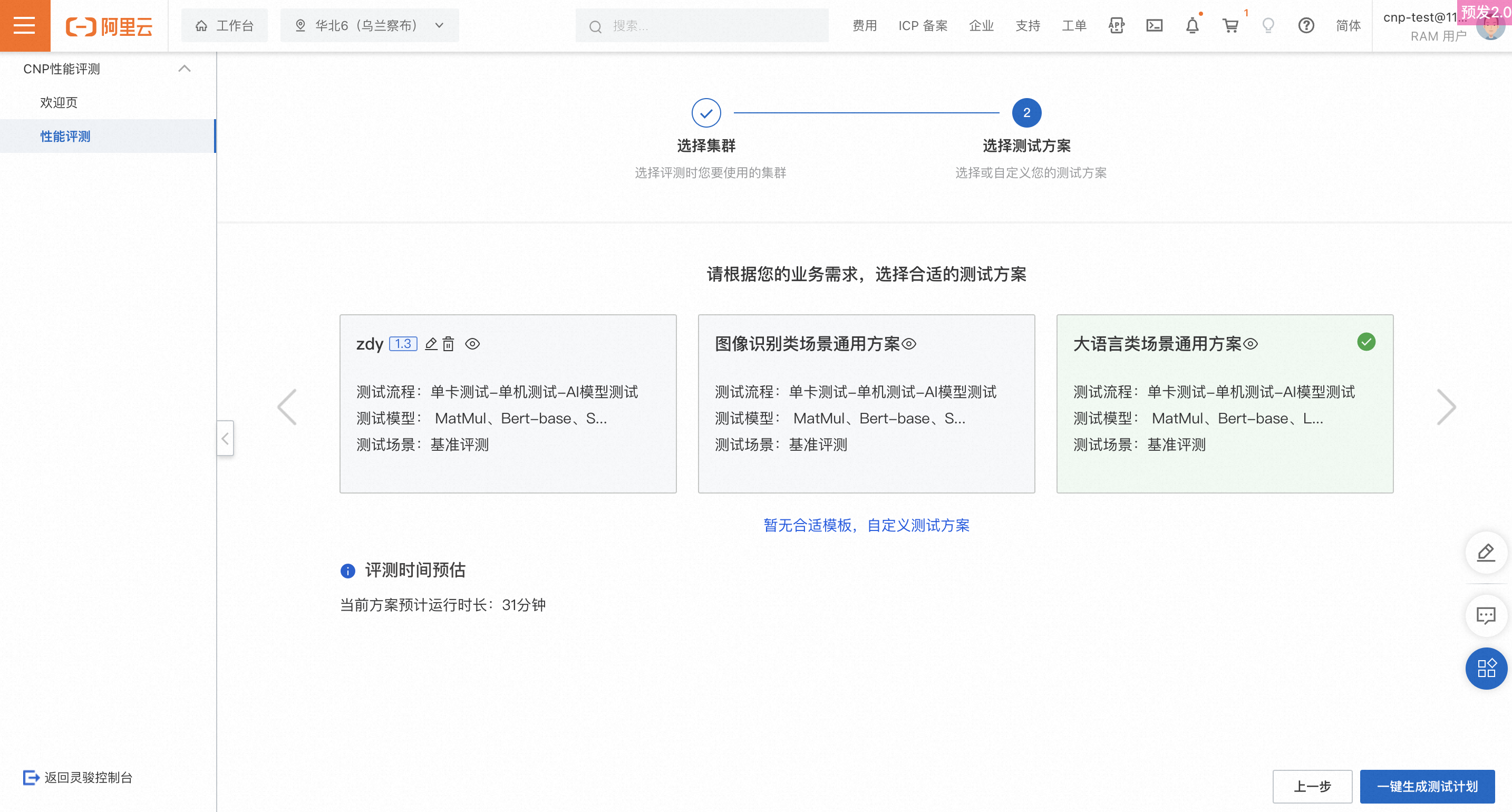
第二步:选择测试方案
使用模板
系统默认提供两套测试方案模板,您可根据实际业务场景选择其中之一。
方案 | 包含的测试内容 | 测试的集群规模 |
方案A:大语言类场景通用方案 |
|
|
方案B:图像识别类场景通用方案 |
|
|
自定义方案
若系统提供的模板均无法满足测试需求,则可以选择自定义测试方案。
单卡测试:节点数支持自定义,测试用例默认MatMul。
单机测试:节点数支持自定义,测试用例默认Bert-base。
AI模型测试:AI模型以及评测的集群卡数支持自定义选择。
当前已支持的模型包括:LLaMA-7B、Stable-Diffusion、Swin-Transformer、Bert-base、UNet。
默认参数配置均采用基准配置,具体配置可在页面中查看。
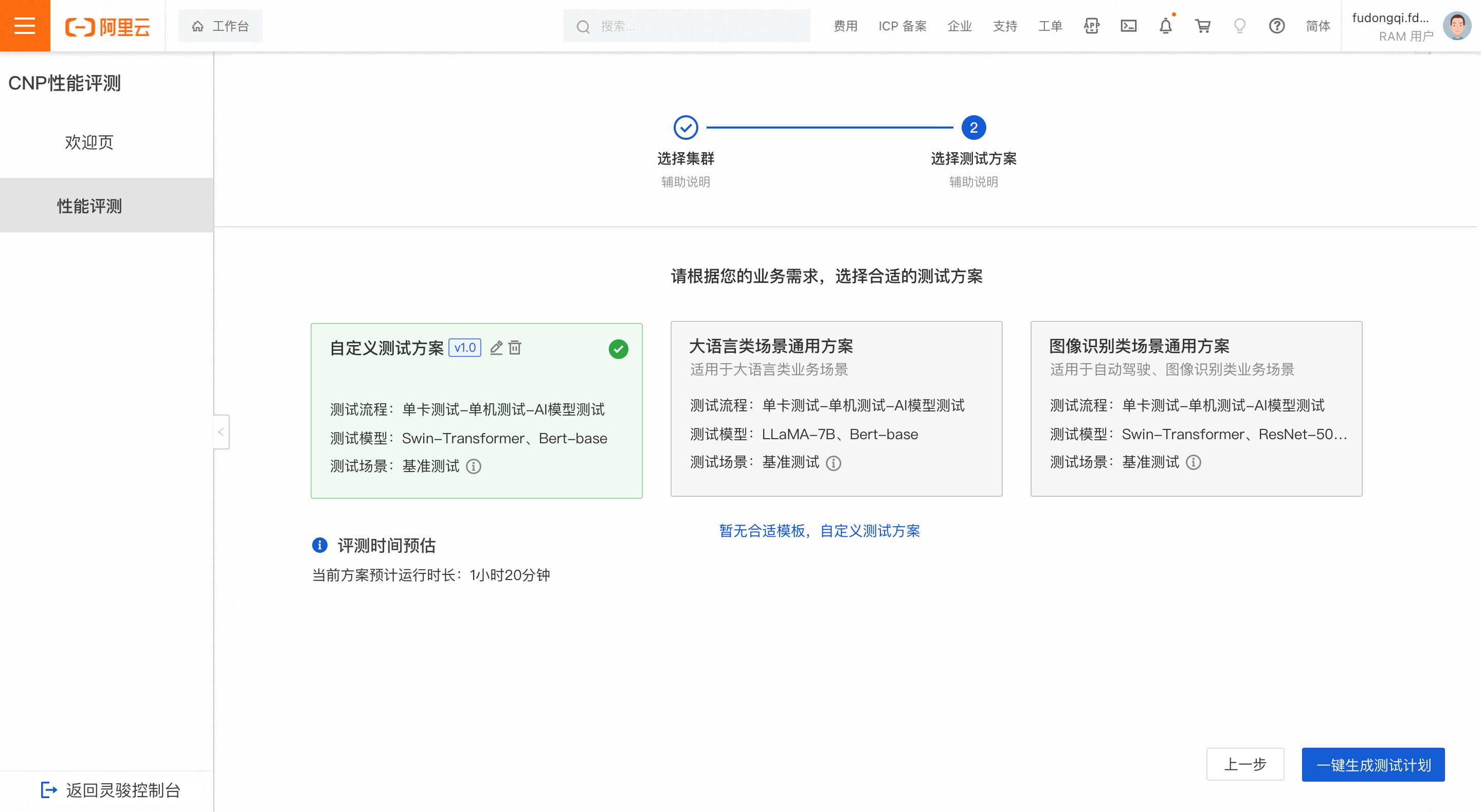
评测时间预估
选择测试方案后,会根据方案中包含的测试内容,自动估算评测预计花费的时间。注意,此时间是根据您第一步所选集群的最大规模进行的估算结果,若您可用集群未达到最大规模,则实际评测时间将比预估时间耗时更长。
一键开始评测
完成第一步和第二步后,点击一键开始评测,即可发起评测,等待评测结果。
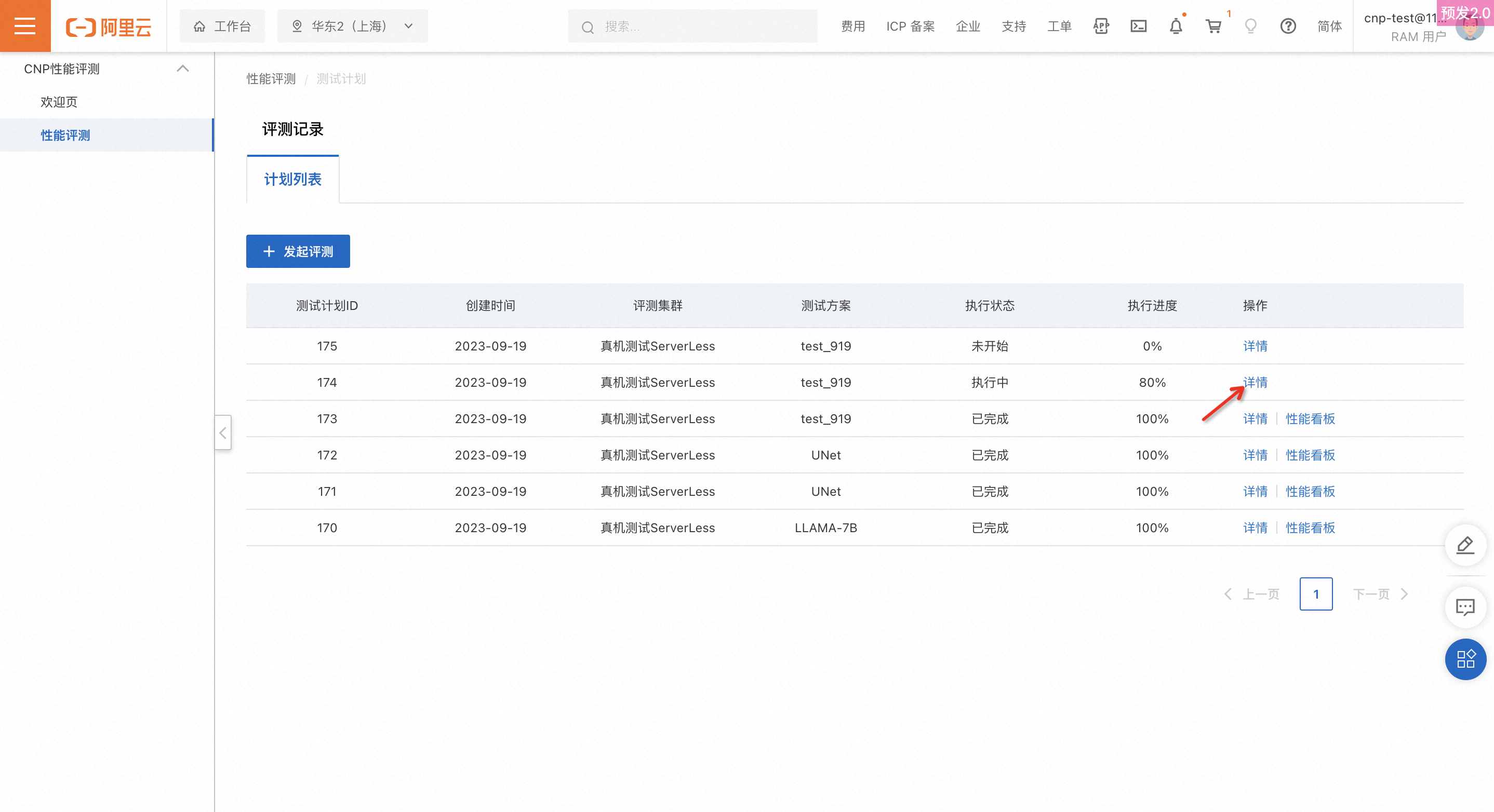
查看评测进度及结果
创建完成测试计划后,在评测计划列表页可实时查看执行状态和执行进度。点击详情,可进入评测计划详情,进一步查看每个环节的评测进度。
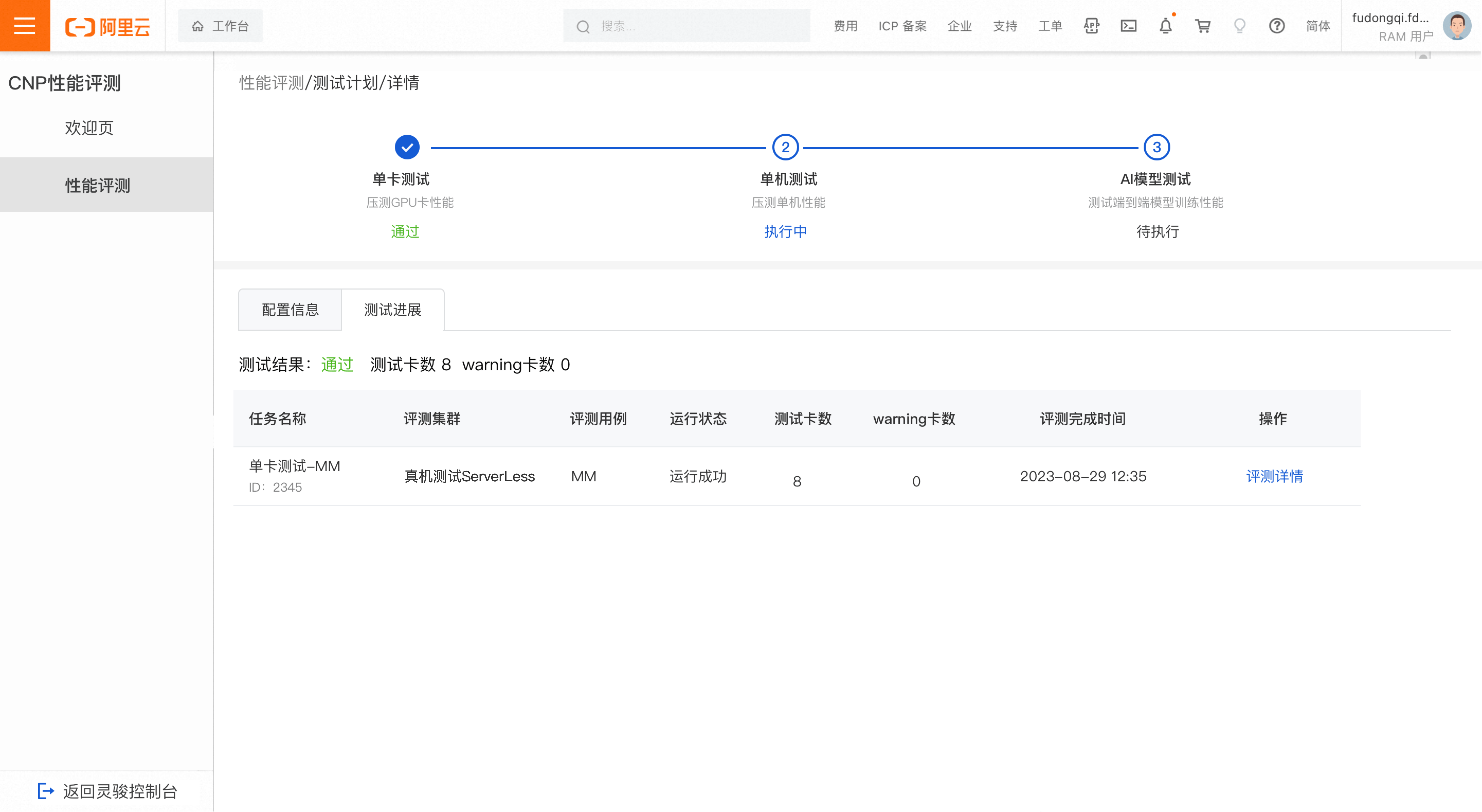
单卡测试
测试通过
当测试的卡未出现疑似问题卡且未出现warning卡时,判定为单卡测试结果通过。
说明疑似问题卡:表示该卡的任务运行失败,卡疑似有问题;
warning卡:表示该卡的TFLOPS变化有超过5%的迭代数在正常阈值范围之外
正常阈值的计算逻辑:取每个迭代所有卡的TFLOPS中位数作为基线,将基线上下3%与4*sigma(4*标准差) 进行比较,取值较大者作为正常阈值范围。

测试结果异常
当测试的卡出现疑似问题卡或出现warning卡时,判定为单卡测试结果异常。
在评测任务列表中,点击加号图标可以展开疑似问题卡或warning卡查看明细,您可将异常节点上报给运维团队进一步排查。点击评测详情,可查看此任务的详细评测结果。
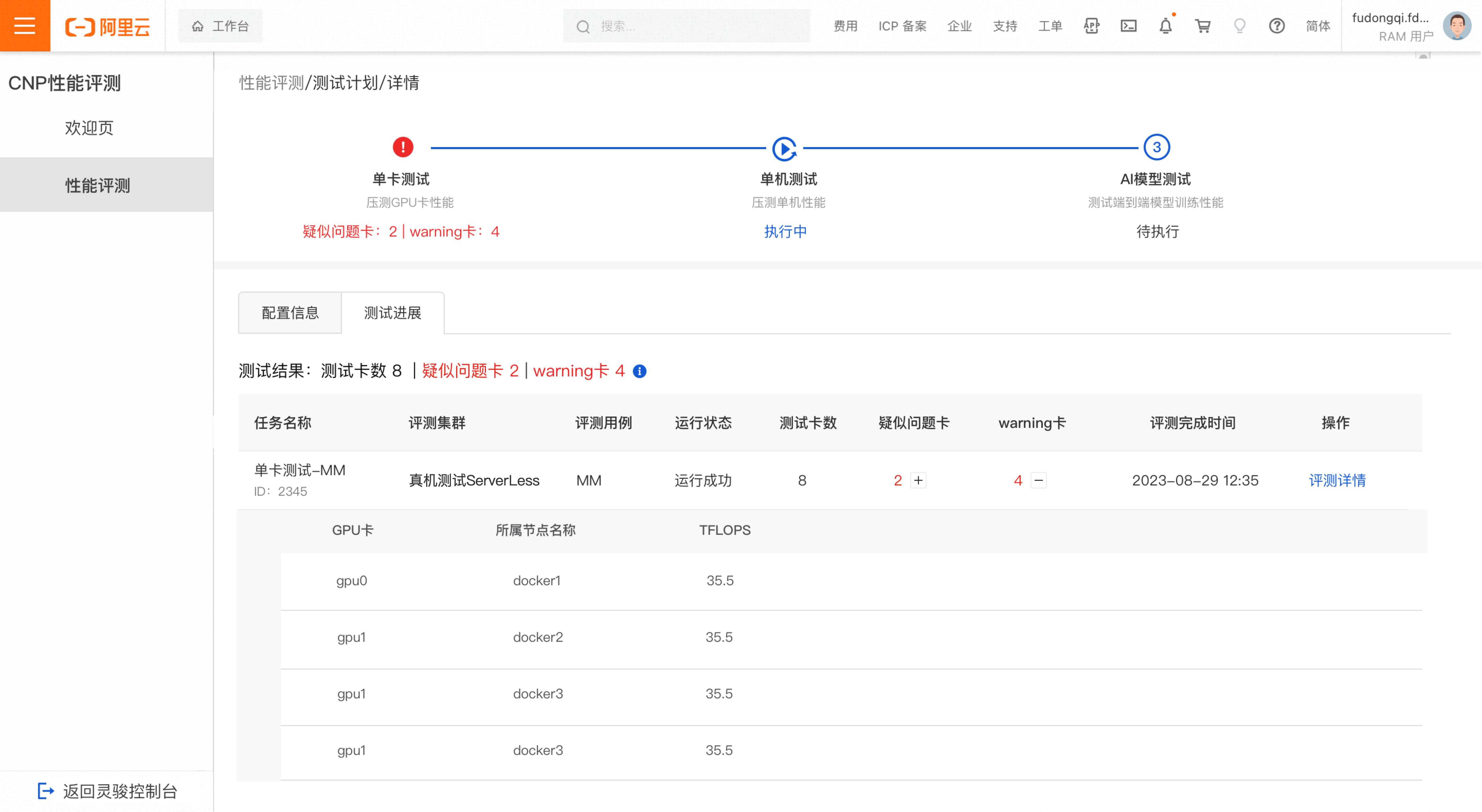
单机测试进度
测试通过
当测试的节点未出现疑似问题节点且未出现warning节点时,判定为单机测试结果通过。
说明疑似问题节点:表示该节点下的DLC任务运行失败,节点疑似有问题;
warning卡:表示该节点的吞吐量变化有超过5%的迭代数在正常阈值范围之外
正常阈值的计算逻辑:取每个迭代所有节点的吞吐中位数作为基线,将基线上下3%与4*sigma(4*标准差) 进行比较,取值较大者作为正常阈值范围。
测试结果异常
当测试的节点出现疑似问题节点或出现warning节点时,判定为单机测试结果异常。
在评测任务列表中,点击加号图标可以展开疑似问题节点或warning节点查看明细,将异常节点上报给运维团队进一步排查。点击评测详情,可查看此任务的详细评测结果。
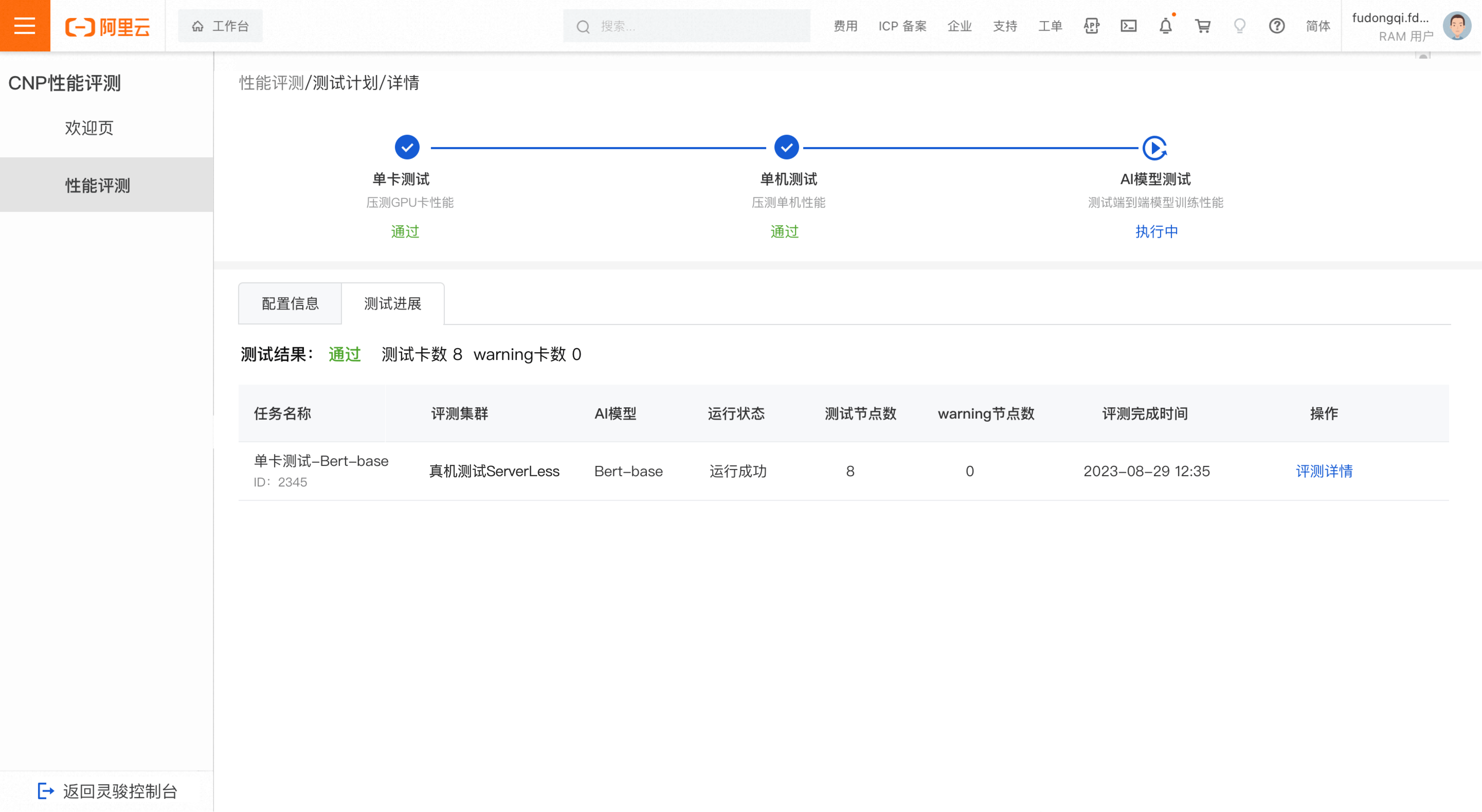
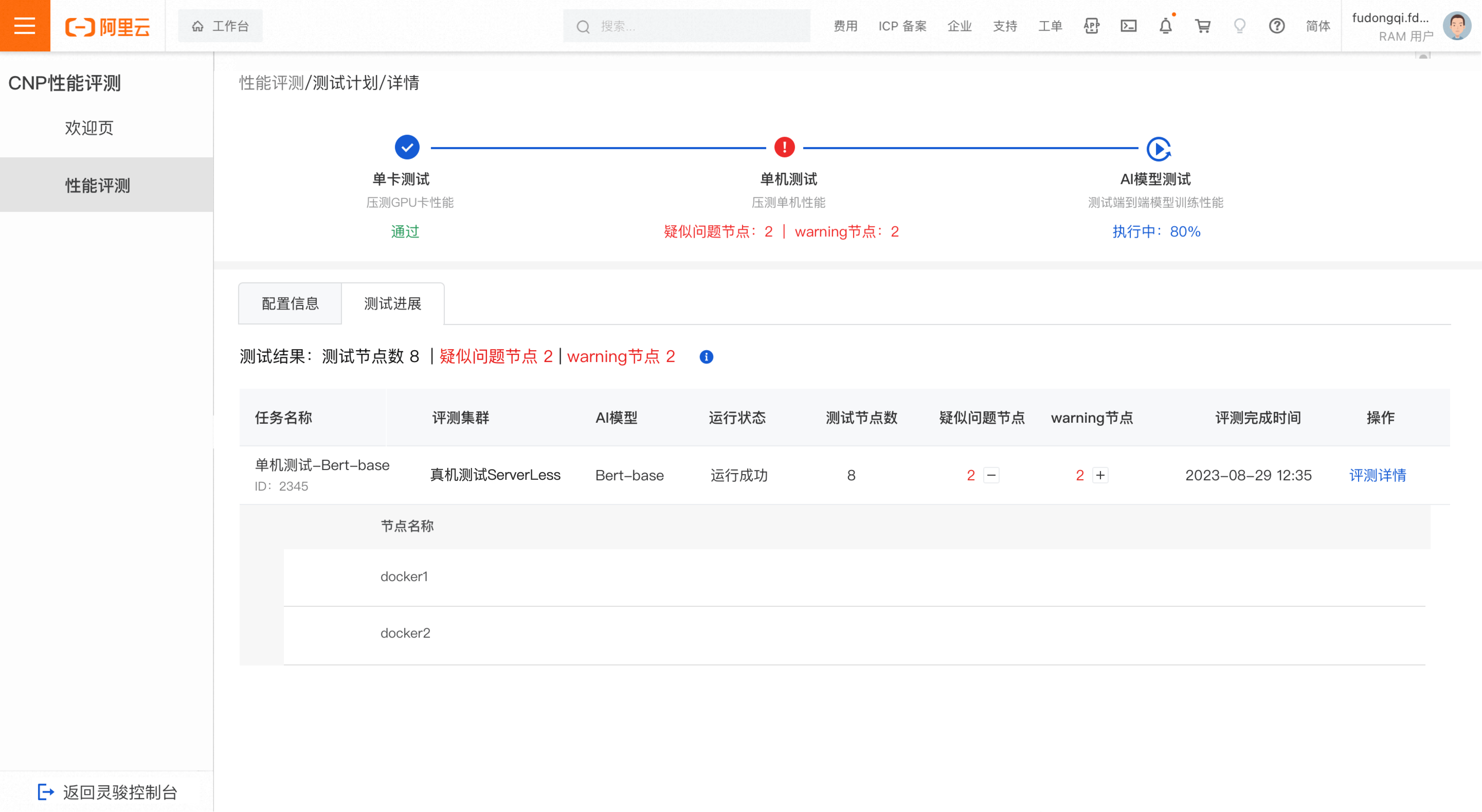
AI模型测试
测试进度
待执行:若所有任务都为待执行状态
已完成:若所有任务均运行成功或运行失败或已停止
已停止:若所有任务均为已停止状态
执行中:部分任务已完成、部分任务待执行或执行中
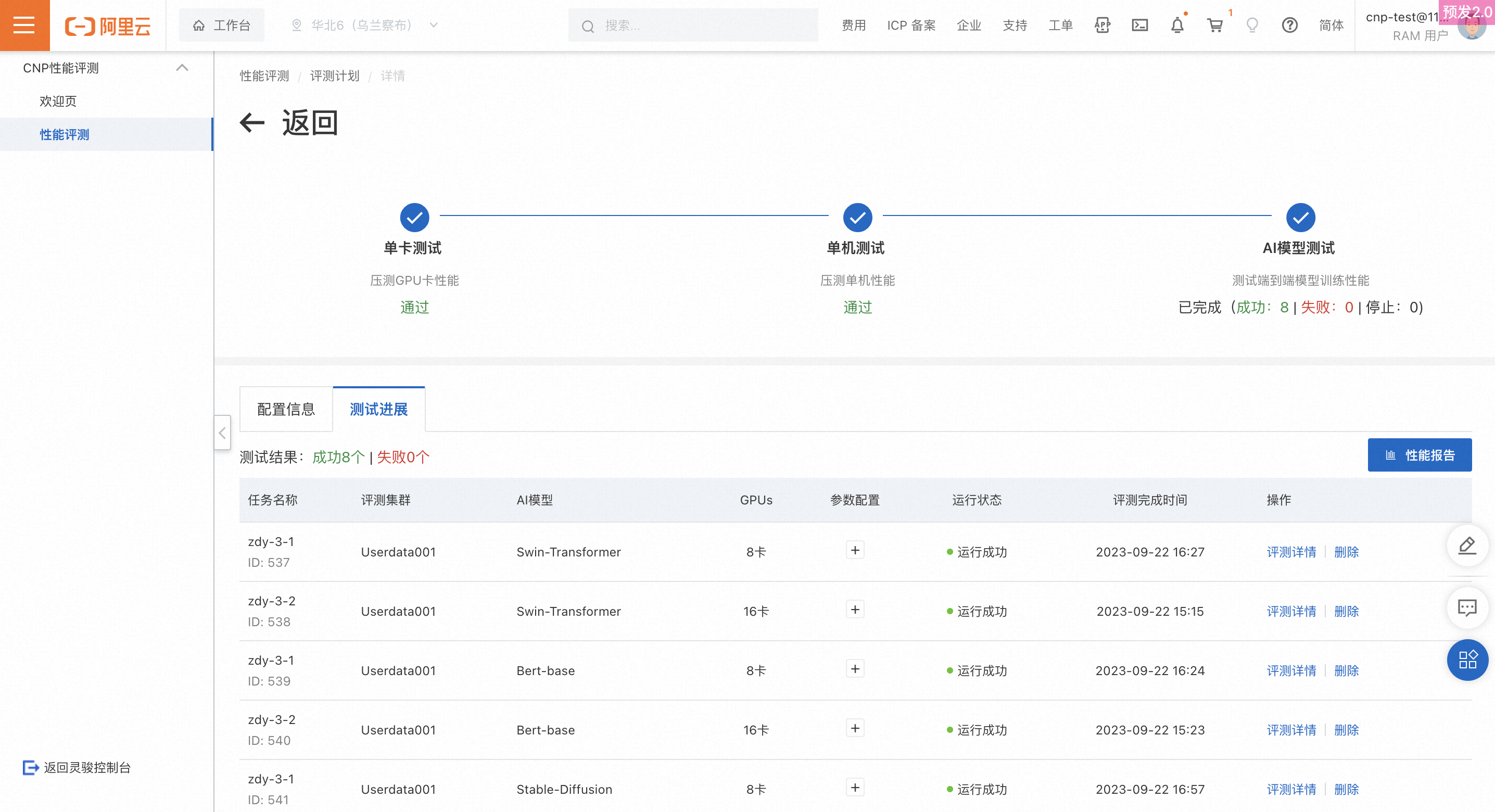
测试任务列表
可查看当前测试计划在AI模型步骤中包含的所有任务,运行中的任务若想终止可以点击停止操作,所有任务均可删除。
警告已删除和运行失败的任务数据不会统计在性能看板dashboard中,请谨慎操作。
查看测试结果性能看板
操作入口
执行状态为已完成的测试计划,可以查看性能看板,性能看板中包含的数据为当前测试计划中-AI模型测试环节运行成功的评测任务。
看板内容
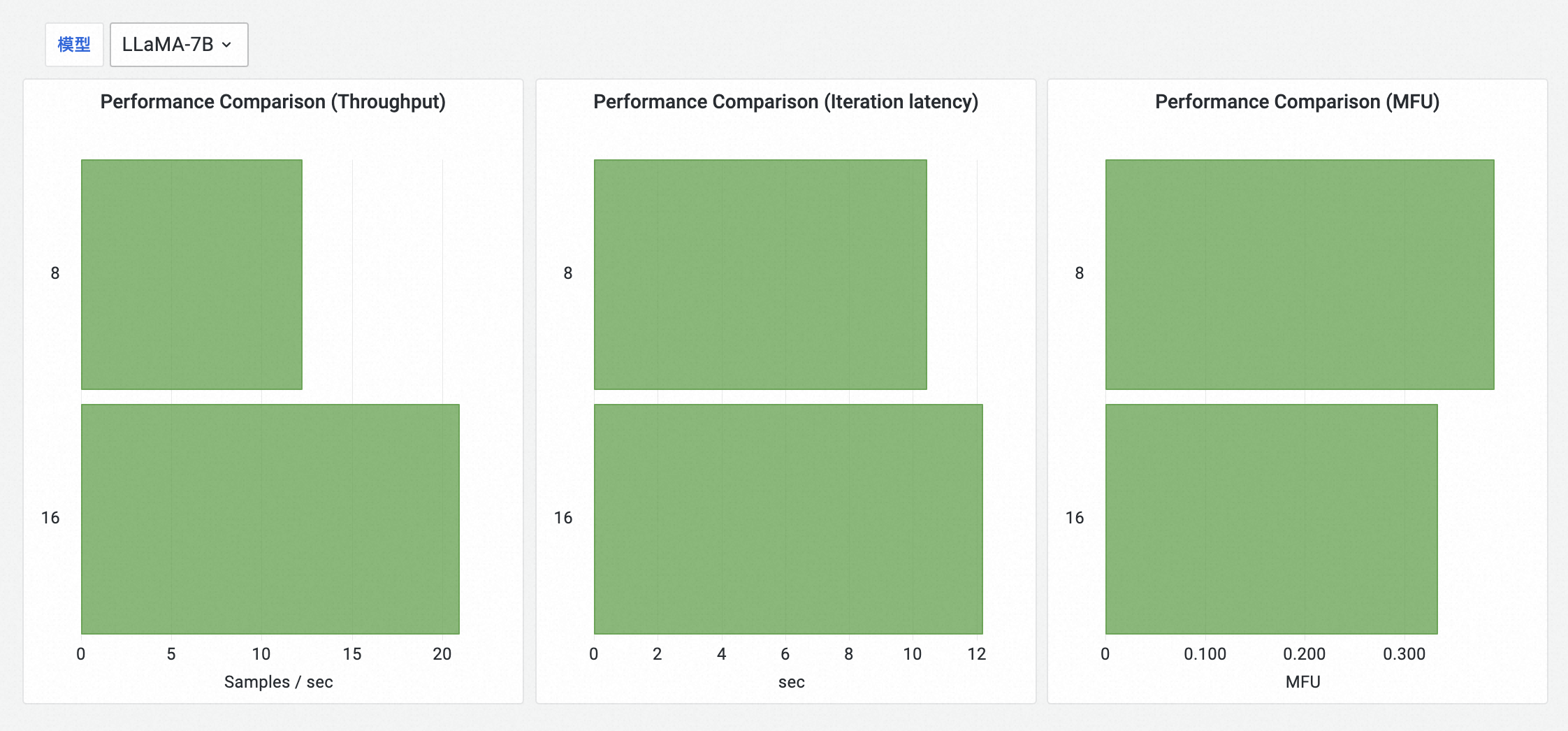
Scalability of Test Model
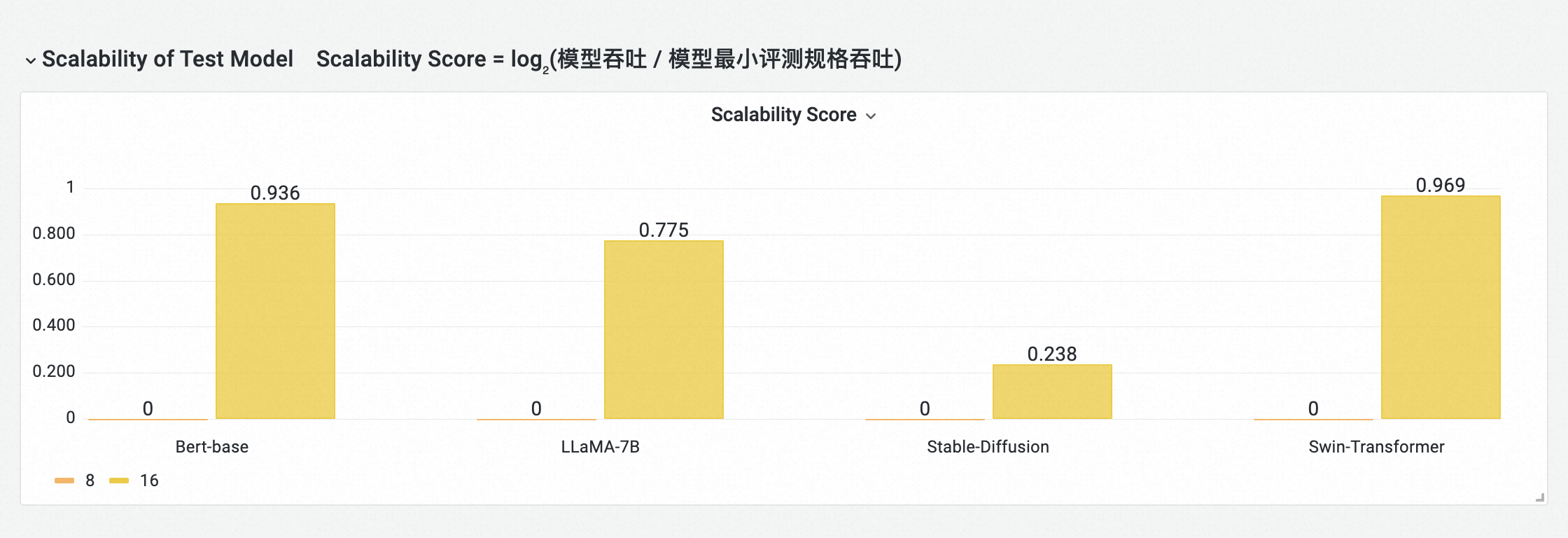
按模型显示每个模型在当前测试计划中所评测的卡数下,吞吐量随卡数的变化趋势,体现模型在集群上的性能扩展性(不同模型间结果不进行对比)。
计算公式:Scalability Score = log₂(模型吞吐 / 模型最小评测规格吞吐)
示例:以GPT3-175B模型为例(MOCK数据、仅用作说明)
GPUs | 吞吐量 | Scalability Score | 理论Scalability Score |
64 | 10 | ||
128 | 18 | log₂(18 / 10) | log₂ 2 |
256 | 35 | log₂(35 / 10) | log₂ 4 |
512 | 69 | log₂(69 / 10) | log₂ 8 |
1024 | 137 | log₂(137 / 10) | log₂ 16 |
注:Scalability Score越接近理论Scalability Score值,性能拓展性越好
评测结果明细
按模型显示每个模型在当前测试计划中所评测的卡数下,throughput指标(吞吐量)、MFU指标和iteration latency指标。纵坐标表示卡数,横坐标表示指标值。