
在PAI子产品(DLC或DSW)中,您可以使用ossfs 2.0客户端或JindoFuse组件(由阿里云EMR提供)将对象存储OSS类型的数据源挂载到容器的指定路径,也可以通过阿里云对象存储OSS提供的OSS Connector for AI/ML和OSS SDK来读取OSS数据。根据不同的应用场景,您可以选择合适的OSS数据读取方法。
背景信息
在AI开发过程中,通常将源数据存储在对象存储OSS中,然后将其从OSS下载至训练环境进行模型开发和训练等。然而,这种方法常伴随着一系列挑战:
-
数据集的下载时间过长造成GPU等待。
-
每次训练任务都需要重复下载数据。
-
为了实现数据的随机采样,不得不在每个训练节点上下载完整数据集。
为了解决上述问题,您可以参考以下建议,选择合适的OSS数据读取方法:
|
OSS数据读取方法 |
描述 |
适用场景 |
|
利用JindoFuse组件将OSS数据集挂载到容器的指定路径,便于直接读写数据。 |
|
|
|
ossfs 2.0是一款专门用于通过挂载方式高性能访问OSS(对象存储)的客户端,它具备出色的顺序读写能力,可充分发挥OSS的高带宽优势。 |
ossfs 2.0适用于对存储访问性能要求较高的场景,比如AI训练、推理、大数据处理、自动驾驶等新型计算密集型负载。这类工作负载主要涉及顺序和随机读取、顺序(仅支持追加)写入操作,并且无需依赖完整的 POSIX 语义。 |
|
|
PAI平台集成了OSS Connector for AI/ML,利用在PyTorch代码中直接流式读取OSS文件实现简易高效的数据读取。具有以下优势:
|
该方式通过非挂载的方式来读写OSS数据。如果您是基于Pytorch进行训练,且需要读取海量(百万级别)小文件,并且对吞吐量有较高要求,可以选择使用OSS Connector for AI/ML的方式来加速数据集的读取。 |
|
|
利用OSS2来实现OSS数据的流式访问。OSS2是一个灵活高效的解决方案,它可以显著减少请求OSS数据的时间,提升训练效率。 |
如果您只需要通过非挂载的方式临时访问OSS数据,或者根据业务逻辑来决定是否访问OSS,可采用OSS Python SDK或OSS Python API的方式。 |
JindoFuse
DLC和DSW支持使用JindoFuse组件将OSS类型的数据集或OSS路径挂载到容器的指定路径,方便您在训练过程中直接读写存储在OSS中的数据。
挂载方式
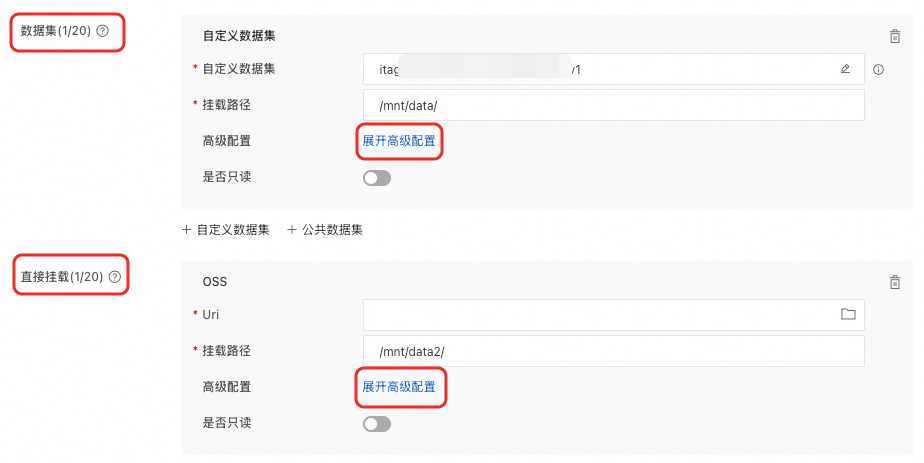
在DLC中挂载OSS
在创建分布式训练(DLC)任务时,挂载OSS数据。支持以下两种挂载类型,具体配置方法,请参见创建训练任务。
|
挂载类型 |
描述 |
|
数据集 |
选择对象存储OSS类型的数据集,并配置挂载路径。当使用公共数据集时,只支持只读挂载模式。 |
|
直接挂载 |
直接挂载OSS Bucket存储路径。 当使用已开启本地缓存的灵骏智算资源配额时,可通过开启使用缓存开关,启用缓存能力。 |
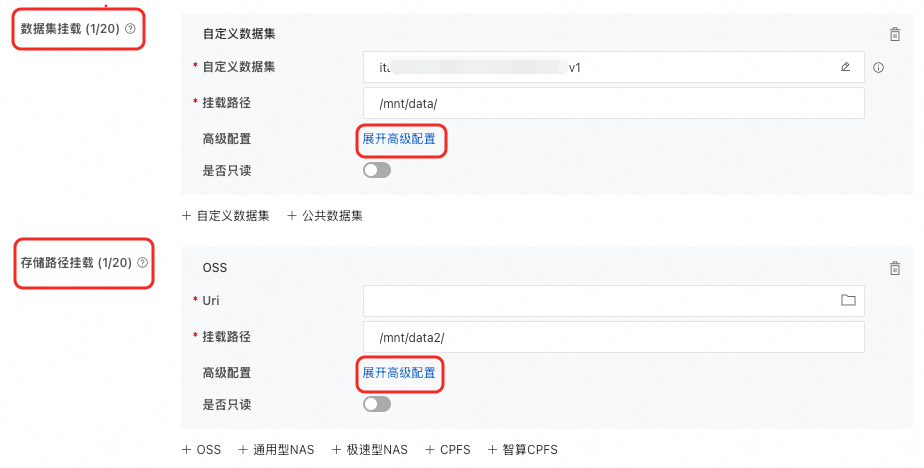
在DSW中挂载OSS
在创建DSW实例时,挂载OSS数据。支持以下两种挂载类型,具体配置方法,请参见创建DSW实例。
|
挂载类型 |
描述 |
|
数据集挂载 |
选择对象存储OSS类型的数据集,并配置挂载路径。当使用公共数据集时,只支持只读挂载模式。 |
|
存储路径挂载 |
直接挂载OSS Bucket存储路径。 |
默认配置限制
当高级配置参数为空时表示使用默认配置,默认配置有如下限制:
-
为了快速读取OSS文件,挂载OSS时会有元数据(目录与文件列表)的缓存。
在分布式任务中,如果有多个节点需要创建同一个目录并检查目录是否存在,元数据的Cache会导致每个节点都尝试进行创建。实际只有一个节点能成功创建目录,其它节点会报错。
-
默认使用OSS的MultiPart API来创建文件,在写文件的过程中,在OSS上看不到该对象。当所有写操作完成后,才能在OSS页面上查看。
-
不支持同时进行文件的写入和读取操作。
-
不支持对文件进行随机写入操作。
常见JindoFuse配置
您也可以根据使用场景,在高级配置中自定义JindoFuse参数。
本文提供部分场景的Jindo配置建议,并未覆盖所有场景下的最优性能。更灵活的配置,请参见JindoFuse使用指南。
快速读写:允许用户读写,读取速度快,但并发读写可能会出现数据不一致的问题,适合挂载训练数据和模型,不适合作为工作目录。
{ "fs.oss.download.thread.concurrency": "cpu核数2倍", "fs.oss.upload.thread.concurrency": "cpu核数2倍", "fs.jindo.args": "-oattr_timeout=3 -oentry_timeout=0 -onegative_timeout=0 -oauto_cache -ono_symlink" }增量读写:在增量写入时能够保证数据一致性,覆盖原有数据会有一致性问题。读取速度略慢,适合保存训练的模型权重文件。
{ "fs.oss.upload.thread.concurrency": "cpu核数2倍", "fs.jindo.args": "-oattr_timeout=3 -oentry_timeout=0 -onegative_timeout=0 -oauto_cache -ono_symlink" }读写一致:在并发读写中能保持数据一致性,适用于对数据一致性要求高,可以容忍读取速度慢的场景,适合保存代码项目。
{ "fs.jindo.args": "-oattr_timeout=0 -oentry_timeout=0 -onegative_timeout=0 -oauto_cache -ono_symlink" }只读:仅允许读取,不允许写入,适合挂载公共数据集。
{ "fs.oss.download.thread.concurrency": "cpu核数2倍", "fs.jindo.args": "-oro -oattr_timeout=7200 -oentry_timeout=7200 -onegative_timeout=7200 -okernel_cache -ono_symlink" }
此外,常见的配置操作有:
-
选择不同的JindoFuse版本:
{ "fs.jindo.fuse.pod.image.tag": "6.7.0" } -
关掉元数据Cache:当执行分布式任务且多个节点同时尝试向同一目录写文件时,Cache可能会引起部分节点的写入操作失败。您可以通过修改JindoFuse的命令行参数,增加
-oattr_timeout=0-oentry_timeout=0-onegative_timeout=0来解决该问题{ "fs.jindo.args": "-oattr_timeout=0-oentry_timeout=0-onegative_timeout=0" } -
调整上传(下载)数据的线程数目:通过配置以下参数来调整线程数据。
{ "fs.oss.upload.thread.concurrency": "32", "fs.oss.download.thread.concurrency": "32", "fs.oss.read.readahead.buffer.count": "64", "fs.oss.read.readahead.buffer.size": "4194304" } -
使用AppendObject方式挂载OSS文件:所有在本地OSS创建的文件,都会调用OSS的AppendObject接口来创建Object(文件)。通过AppendObject方式最后生成的Object大小不得超过5 GB,关于AppendObject的更多使用限制,请参见AppendObject。示例配置如下:
{ "fs.jindo.args": "-oattr_timeout=0 -oentry_timeout=0 -onegative_timeout=0", "fs.oss.append.enable": "true", "fs.oss.flush.interval.millisecond": "1000", "fs.oss.read.readahead.buffer.size": "4194304", "fs.oss.write.buffer.size": "262144" } -
挂载OSS-HDFS:如何开通OSS-HDFS,请参见什么是OSS-HDFS服务。在分布式训练的场景下建议增加以下参数:
{ "fs.jindo.args": "-oattr_timeout=0 -oentry_timeout=0 -onegative_timeout=0 -ono_symlink -ono_xattr -ono_flock -odirect_io", "fs.oss.flush.interval.millisecond": "10000", "fs.oss.randomwrite.sync.interval.millisecond": "10000" } -
配置内存资源:可通过配置
fs.jindo.fuse.pod.mem.limit参数来调整内存资源,示例如下:{ "fs.jindo.fuse.pod.mem.limit": "10Gi" }
ossfs 2.0
在挂载OSS数据源时,您可以在高级配置中设置{"mountType":"ossfs"},以使用ossfs方式进行挂载。
挂载方式
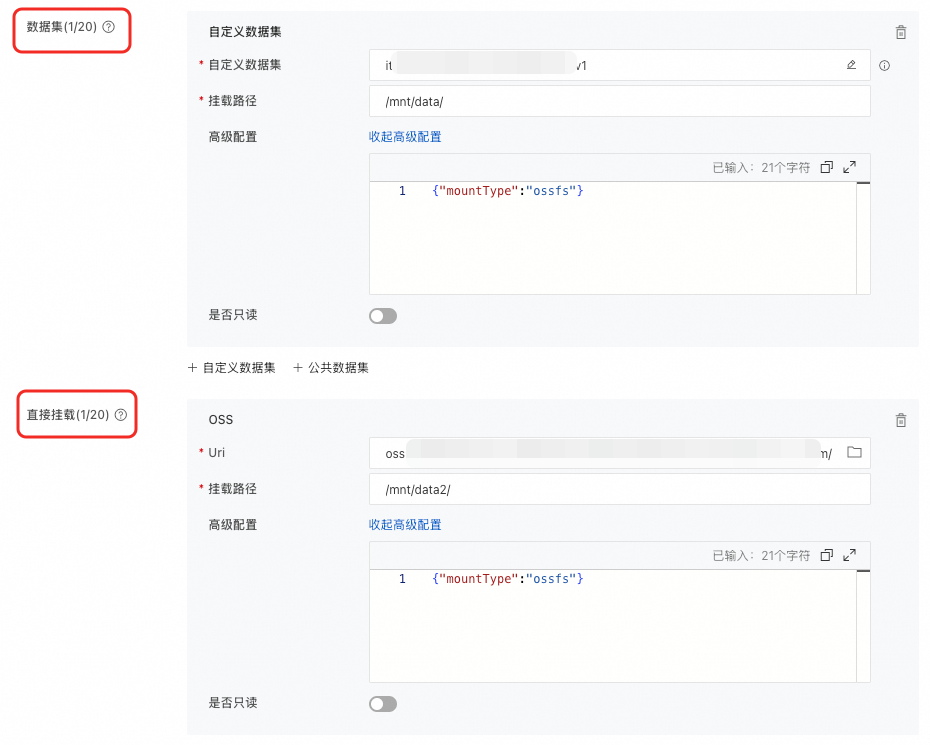
在DLC中挂载OSS
在创建分布式训练(DLC)任务时,挂载OSS数据。支持以下两种挂载类型,具体配置方法,请参见创建训练任务。
|
挂载类型 |
描述 |
|
数据集 |
选择对象存储OSS类型的数据集,并配置挂载路径。当使用公共数据集时,只支持只读挂载模式。 |
|
直接挂载 |
直接挂载OSS Bucket存储路径。 当使用已开启本地缓存的灵骏智算资源配额时,可通过开启使用缓存开关,启用缓存能力。 |
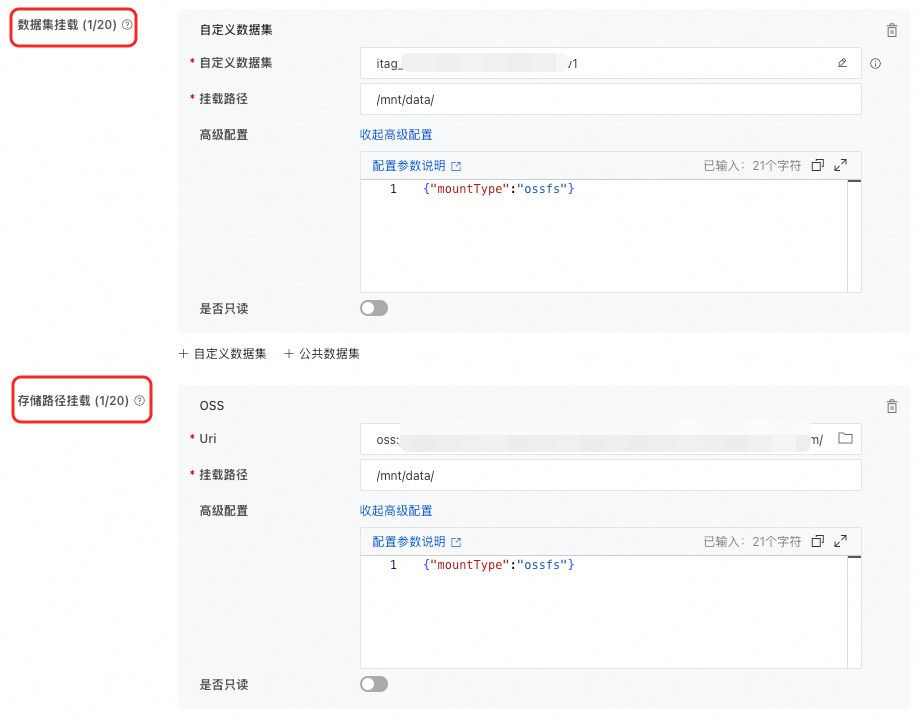
在DSW中挂载OSS
在创建DSW实例时,挂载OSS数据。支持以下两种挂载类型,具体配置方法,请参见创建DSW实例。
|
挂载类型 |
描述 |
|
数据集挂载 |
选择对象存储OSS类型的数据集,并配置挂载路径。当使用公共数据集时,只支持只读挂载模式。 |
|
存储路径挂载 |
直接挂载OSS Bucket存储路径。 |
常见ossfs配置
在高级配置中,您可以通过fs.ossfs.args设置高级参数,多个参数之间使用半角逗号,分隔。有关高级参数的使用说明,请参见ossfs 2.0。以下是几个常见的场景示例:
-
任务过程中数据源不变:如果要读取的所有文件在读取过程中均不会被修改,可以配置较大的缓存时间,从而减少元数据请求次数。典型场景例如:读取一批已有的旧文件,并在处理后生成一批新文件。
{ "mountType":"ossfs", "fs.ossfs.args": "-oattr_timeout=7200" } -
快速读写:使用较小的元数据缓存时间,可以平衡缓存效率和文件数据的及时性。
{ "mountType":"ossfs", "fs.ossfs.args": "-oattr_timeout=3, -onegative_timeout=0" } -
分布式任务读写一致:ossfs默认基于元数据缓存进行文件的数据更新。通过以下配置实现多节点同步视图。
{ "mountType":"ossfs", "fs.ossfs.args": "-onegative_timeout=0, -oclose_to_open" } -
DLC/DSW场景中同时打开过多文件导致OOM:在DLC或DSW场景中,由于任务并发量较高,可能会同时打开大量文件,从而引发OOM(内存不足)问题。通过以下配置来缓解内存压力。
{ "mountType":"ossfs", "fs.ossfs.args": "-oreaddirplus=false, -oinode_cache_eviction_threshold=300000" } -
写入大文件失败:
-oupload_buffer_size用于设置分片上传缓冲区大小(Bytes)。该参数决定了能够写入文件最终大小,计算方式为upload_buffer_size * 10000。ossfs 2.0默认配置的分片大小为8 MiB,因此最大支持写入78.125 GiB的文件。当您写入的文件大小超过此限制时,写入操作将会失败。您可以通过配置
-oupload_buffer_size选项来增加分片大小,从而提高支持的文件大小上限。例如,将Part大小设置为32 MiB(即33554432字节),可支持最大312.5 GiB的文件。请注意,增加-upload_buffer_size会消耗更多内存资源。您可以通过配置-total_mem_limit来控制内存使用,详情请参见挂载选项说明{ "mountType":"ossfs", "fs.ossfs.args": "-oupload_buffer_size=33554432" }
OSS Connector for AI/ML
使用OSS Connector for AI/ML加速模型训练是阿里云OSS团队专为人工智能和机器学习场景设计的客户端库,能在大规模Pytorch框架训练场景下提供便捷的数据加载体验,显著减少数据传输时间和复杂度,加速模型训练,提高效率,从而避免不必要的步骤和数据加载瓶颈。为优化PAI用户体验并加速数据访问流程,PAI平台集成了OSS Connector for AI/ML,可在PyTorch代码中直接流式读取OSS文件,实现简易高效的数据读取。
使用限制
-
官方镜像:仅在分布式训练(DLC)任务或DSW实例中选择Pytorch 2.0及其以上版本的镜像时,才能使用OSS Connector for AI/ML模块。
-
自定义镜像:仅支持Pytorch 2.0及其以上版本,对于满足版本要求的镜像,您可以通过下述指令安装OSS Connector for AI/ML模块。
pip install -i http://yum.tbsite.net/aliyun-pypi/simple/ --extra-index-url http://yum.tbsite.net/pypi/simple/ --trusted-host=yum.tbsite.net osstorchconnector -
Python版本:仅支持Python 3.8~3.12版本。
准备工作
-
配置credential文件。
您可以使用以下任意一种方式配置credential:
-
您可以参考配置DLC RAM角色,为分布式训练(DLC)任务配置免密访问OSS的credential。通过这种方式,DLC任务将获取STS临时访问凭证,能够安全地访问OSS或其他云资源,无需显式配置认证信息,从而降低密钥泄露的风险。
-
在代码项目中配置credential文件,管理认证信息。配置示例如下:
说明明文配置AK信息存在安全风险,建议您使用角色配置在DLC实例内自动配置credential,详情请参见配置DLC RAM角色。
在使用OSS Connector for AI/ML接口时,您可以通过指定credential文件的路径,自动获取认证信息,以便进行OSS数据请求的认证。
{ "AccessKeyId": "<Access-key-id>", "AccessKeySecret": "<Access-key-secret>", "SecurityToken": "<Security-Token>", "Expiration": "2024-08-20T00:00:00Z" }具体配置项说明如下:
配置项
是否必填
说明
示例值
AccessKeyId
是
阿里云账号或者RAM用户的AccessKey ID和AccessKey Secret。
说明当使用从STS获取的临时访问凭证访问OSS时,请设置为临时访问凭证的AccessKey ID和AccessKey Secret。
NTS****
AccessKeySecret
是
7NR2****
SecurityToken
否
临时访问令牌。当使用从STS获取的临时访问凭证访问OSS时,需要设置此参数。
STS.6MC2****
Expiration
否
鉴权信息过期时间,Expiration为空表示永不过期,鉴权时间过期后OSS Connector会重新读取鉴权信息。
2024-08-20T00:00:00Z
-
-
配置config.json文件,内容示例如下:
在代码项目中配置config.json文件,管理诸如并发处理数量、预取参数以及其他核心参数,同时定义日志文件的存储位置等重要信息。使用OSS Connector for AI/ML接口时,通过指定config.json文件的路径,系统可以自动获取到读取时并发处理量、预取值,并将请求OSS数据的相关日志输出到指定的日志文件中。
{ "logLevel": 1, "logPath": "/var/log/oss-connector/connector.log", "auditPath": "/var/log/oss-connector/audit.log", "datasetConfig": { "prefetchConcurrency": 24, "prefetchWorker": 2 }, "checkpointConfig": { "prefetchConcurrency": 24, "prefetchWorker": 4, "uploadConcurrency": 64 } }具体配置项说明如下:
配置项
是否必填
说明
示例值
logLevel
是
日志记录级别。默认为INFO级别。取值如下:
-
0:表示Debug。
-
1:表示INFO。
-
2:表示WARN。
-
3:表示ERROR。
1
logPath
是
connector日志路径。默认路径为
/var/log/oss-connector/connector.log。/var/log/oss-connector/connector.log
auditPath
是
connector IO的审计日志,记录延迟大于100毫秒的读写请求。默认路径为
/var/log/oss-connector/audit.log。/var/log/oss-connector/audit.log
DatasetConfig
prefetchConcurrency
是
使用Dataset从OSS预取数据时的并发数,默认为24。
24
prefetchWorker
是
使用Dataset从OSS预取可使用vCPU数,默认为4。
2
checkpointConfig
prefetchConcurrency
是
使用checkpoint read从OSS预取数据时的并发数,默认为24。
24
prefetchWorker
是
使用checkpoint read从OSS预取可使用vCPU数,默认为4。
4
uploadConcurrency
是
使用checkpoint write上传数据时的并发数,默认为64。
64
-
使用方式
OSS Connector for AI/ML提供了OssMapDataset和OssIterableDataset两种数据集访问接口,分别是对Dataset和IterableDataset接口的扩展。OssIterableDataset进行了预取优化,因此训练效率相对较高。OssMapDataset的数据读取顺序由DataLoader决定,支持shuffle操作。因此,您可以参考以下建议选择数据集访问接口:
-
如果内存较小或数据量较大,只需要顺序读取且对并行处理的要求不高,建议您使用OssIterableDataset来构建Dataset。
-
相反,如果内存充足、数据量较小,并且需要随机操作和并行处理,建议您使用OssMapDataset来构建Dataset。
同时,OSS Connector for AI/ML也提供了OssCheckpoint接口以支持模型加载和保存。当前,OssCheckpoint功能仅限于在通用资源环境下使用。
以下内容为您介绍这三种接口的使用方式:
OssMapDataset
支持以下三种数据集访问模式:
-
根据OSS路径前缀访问文件夹
您只需指定文件夹名称,无需配置索引文件,更简单直观,便于维护和扩展。如果您的OSS文件夹结构如下,则可以选择采用该方式访问数据集:
dataset_folder/ ├── class1/ │ ├── image1.JPEG │ └── ... ├── class2/ │ ├── image2.JPEG │ └── ...在使用时需要指定OSS路径前缀,并自定义文件流的解析方式。以下是解析和转换图片文件的方法:
def read_and_transform(data): normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) transform = transforms.Compose([ transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), normalize, ]) try: img = accimage.Image((data.read())) val = transform(img) label = data.label # 文件名 except Exception as e: print("read failed", e) return None, 0 return val, label dataset = OssMapDataset.from_prefix("{oss_data_folder_uri}", endpoint="{oss_endpoint}", transform=read_and_transform, cred_path=cred_path, config_path=config_path) -
根据manifest_file获取文件
支持访问多个OSS Bucket的数据,提供更灵活的数据管理方式。如果您的OSS文件夹结构如下,并且存在一个管理文件名和Label对应关系的manifest_file,则可以选择采用manifest_file的方式访问数据集。
dataset_folder/ ├── class1/ │ ├── image1.JPEG │ └── ... ├── class2/ │ ├── image2.JPEG │ └── ... └── .manifest其中manifest_file格式如下:
{'data': {'source': 'oss://examplebucket.oss-cn-wulanchabu.aliyuncs.com/dataset_folder/class1/image1.JPEG'}} {'data': {'source': ''}}在使用时,您需要自定义manifest_file的解析方式,使用示例如下:
def transform_oss_path(input_path): pattern = r'oss://(.*?)\.(.*?)/(.*)' match = re.match(pattern, input_path) if match: return f'oss://{match.group(1)}/{match.group(3)}' else: return input_path def manifest_parser(reader: io.IOBase) -> Iterable[Tuple[str, str, int]]: lines = reader.read().decode("utf-8").strip().split("\n") data_list = [] for i, line in enumerate(lines): data = json.loads(line) yield transform_oss_path(data["data"]["source"]), "" dataset = OssMapDataset.from_manifest_file("{manifest_file_path}", manifest_parser, "", endpoint=endpoint, transform=read_and_trans, cred_path=cred_path, config_path=config_path) -
根据OSS_URI列表的方式获取文件
您只需指定OSS_URI,无需配置索引文件,即可访问OSS文件。使用示例如下:
uris =["oss://examplebucket.oss-cn-wulanchabu.aliyuncs.com/dataset_folder/class1/image1.JPEG", "oss://examplebucket.oss-cn-wulanchabu.aliyuncs.com/dataset_folder/class2/image2.JPEG"] dataset = OssMapDataset.from_objects(uris, endpoint=endpoint, transform=read_and_trans, cred_path=cred_path, config_path=config_path)
OssIterableDataset
OssIterableDataset也支持三种数据集访问方式,与OssMapDataset相同。以下内容为您介绍如何使用这三种数据集访问方式:
-
根据OSS路径前缀访问文件夹
dataset = OssIterableDataset.from_prefix("{oss_data_folder_uri}", endpoint="{oss_endpoint}", transform=read_and_transform, cred_path=cred_path, config_path=config_path) -
根据manifest_file获取文件
dataset = OssIterableDataset.from_manifest_file("{manifest_file_path}", manifest_parser, "", endpoint=endpoint, transform=read_and_trans, cred_path=cred_path, config_path=config_path) -
根据OSS_URI列表的方式获取文件
dataset = OssIterableDataset.from_objects(uris, endpoint=endpoint, transform=read_and_trans, cred_path=cred_path, config_path=config_path)
OssCheckpoint
当前,OssCheckpoint功能仅支持在通用计算资源环境下使用。OSS Connector for AI/ML支持通过OssCheckpoint访问OSS模型文件,以及将模型文件保存到OSS中,接口使用方法如下:
checkpoint = OssCheckpoint(endpoint="{oss_endpoint}", cred_path=cred_path, config_path=config_path)
checkpoint_read_uri = "{checkpoint_path}"
checkpoint_write_uri = "{checkpoint_path}"
with checkpoint.reader(checkpoint_read_uri) as reader:
state_dict = torch.load(reader)
model.load_state_dict(state_dict)
with checkpoint.writer(checkpoint_write_uri) as writer:
torch.save(model.state_dict(), writer)代码示例
以下是OSS Connector for AI/ML的示例代码,您可以使用该示例代码访问OSS数据:
from osstorchconnector import OssMapDataset, OssCheckpoint
import torchvision.transforms as transforms
import accimage
import torchvision.models as models
import torch
cred_path = "/mnt/.alibabacloud/credentials" # 为DLC任务和DSW实例配置角色信息之后credential的默认路径。
config_path = "config.json"
checkpoint = OssCheckpoint(endpoint="{oss_endpoint}", cred_path=cred_path, config_path=config_path)
model = models.__dict__["resnet18"]()
epochs = 100 # 指定epoch
checkpoint_read_uri = "{checkpoint_path}"
checkpoint_write_uri = "{checkpoint_path}"
with checkpoint.reader(checkpoint_read_uri) as reader:
state_dict = torch.load(reader)
model.load_state_dict(state_dict)
def read_and_transform(data):
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
])
try:
img = accimage.Image((data.read()))
value = transform(img)
except Exception as e:
print("read failed", e)
return None, 0
return value, 0
dataset = OssMapDataset.from_prefix("{oss_data_folder_uri}", endpoint="{oss_endpoint}", transform=read_and_transform, cred_path=cred_path, config_path=config_path)
data_loader = torch.utils.data.DataLoader(
dataset, batch_size="{batch_size}",num_workers="{num_workers"}, pin_memory=True)
for epoch in range(args.epochs):
for step, (images, target) in enumerate(data_loader):
# batch processing
# model training
# save model
with checkpoint.writer(checkpoint_write_uri) as writer:
torch.save(model.state_dict(), writer)上述代码的关键实现说明如下:
-
使用OssMapDataset直接基于给定的OSS URI,构建一个与Pytorch Dataloader使用范式一致的dataset。
-
使用该dataset,构建Torch的标准Dataloader,并通过loop dataloader进行标准的训练流程,如对当前batch的处理、模型训练与保存等。
-
同时,这一过程无需将数据集挂载到容器环境中,也无需事先将数据存储至本地,实现了数据的按需加载。
OSS SDK
OSS Python SDK
您可以直接使用OSS Python SDK读写OSS中的数据,具体操作步骤如下:
-
安装OSS Python SDK。详情请参见安装(Python SDK V1)。
-
为OSS Python SDK配置访问凭证,详情请参见配置访问凭证(Python SDK V1)。
-
读写OSS数据。
# -*- coding: utf-8 -*- import oss2 from oss2.credentials import EnvironmentVariableCredentialsProvider # 使用环境变量中获取的RAM用户访问密钥配置访问凭证 auth = oss2.ProviderAuth(EnvironmentVariableCredentialsProvider()) bucket = oss2.Bucket(auth, '<Endpoint>', '<your_bucket_name>') # 读取一个完整文件。 result = bucket.get_object('<your_file_path/your_file>') print(result.read()) # 按Range读取数据。 result = bucket.get_object('<your_file_path/your_file>', byte_range=(0, 99)) # 写数据至OSS。 bucket.put_object('<your_file_path/your_file>', '<your_object_content>') # 对Appendable类型文件进行Append。 result = bucket.append_object('<your_file_path/your_file>', 0, '<your_object_content>') result = bucket.append_object('<your_file_path/your_file>', result.next_position, '<your_object_content>')您需要根据实际需要修改以下配置项:
配置项
描述
<Endpoint>
填写Bucket所在地域对应的Endpoint。以华东1(杭州)为例,Endpoint填写为https://oss-cn-hangzhou.aliyuncs.com。关于获取Endpoint的更多信息,请参见地域和Endpoint。
<your_bucket_name>
填写存储空间名称。
<your_file_path/your_file>
表示待读写的文件路径。填写不包含Bucket名称在内的Object完整路径,例如
testfolder/exampleobject.txt。<your_object_content>
表示待Append的内容,需要根据实际情况修改。
OSS Python API
使用OSS Python API,您可以方便地在OSS中存储训练数据和模型。在开始操作之前,请确保已安装OSS Python SDK,并正确设置访问凭据,详情请参见安装(Python SDK V1)和配置访问凭证(Python SDK V1)。
-
加载训练数据
您可以将数据存放在一个OSS Bucket中,且将数据路径和对应的Label存储在同一个OSS Bucket的索引文件中。通过自定义DataSet,在PyTorch中使用
DataLoaderAPI多进程并行读取数据,示例如下。import io import oss2 from oss2.credentials import EnvironmentVariableCredentialsProvider import PIL import torch class OSSDataset(torch.utils.data.dataset.Dataset): def __init__(self, endpoint, bucket, auth, index_file): self._bucket = oss2.Bucket(auth, endpoint, bucket) self._indices = self._bucket.get_object(index_file).read().split(',') def __len__(self): return len(self._indices) def __getitem__(self, index): img_path, label = self._indices(index).strip().split(':') img_str = self._bucket.get_object(img_path) img_buf = io.BytesIO() img_buf.write(img_str.read()) img_buf.seek(0) img = Image.open(img_buf).convert('RGB') img_buf.close() return img, label # 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。 auth = oss2.ProviderAuth(EnvironmentVariableCredentialsProvider()) dataset = OSSDataset(endpoint, bucket, auth, index_file) data_loader = torch.utils.data.DataLoader( dataset, batch_size=batch_size, num_workers=num_loaders, pin_memory=True)其中关键配置说明如下:
关键配置
描述
endpoint
填写Bucket所在地域对应的Endpoint。以华东1(杭州)为例,Endpoint填写为https://oss-cn-hangzhou.aliyuncs.com。关于获取Endpoint的更多信息,请参见地域和Endpoint。
bucket
填写存储空间名称。
index_file
索引文件的路径。
说明示例中,索引文件格式为每条样本使用英文逗号(,)分隔,样本路径与Label之间使用英文冒号(:)分隔。
-
Save或Load模型
您可以使用OSS Python API Save或Load PyTorch模型(关于PyTorch如何Save或Load模型,详情请参见PyTorch),示例如下:
-
Save模型
from io import BytesIO import torch import oss2 from oss2.credentials import EnvironmentVariableCredentialsProvider auth = oss2.ProviderAuth(EnvironmentVariableCredentialsProvider()) # bucket_name bucket_name = "<your_bucket_name>" bucket = oss2.Bucket(auth, endpoint, bucket_name) buffer = BytesIO() torch.save(model.state_dict(), buffer) bucket.put_object("<your_model_path>", buffer.getvalue())其中
-
endpoint为Bucket所在地域对应的Endpoint。以华东1(杭州)为例,Endpoint填写为https://oss-cn-hangzhou.aliyuncs.com。
-
<your_bucket_name>为OSS Bucket名称,且开头不带oss://。
-
<your_model_path>为模型路径,都需要根据实际情况修改。
-
-
Load模型
from io import BytesIO import torch import oss2 from oss2.credentials import EnvironmentVariableCredentialsProvider auth = oss2.ProviderAuth(EnvironmentVariableCredentialsProvider()) bucket_name = "<your_bucket_name>" bucket = oss2.Bucket(auth, endpoint, bucket_name) buffer = BytesIO(bucket.get_object("<your_model_path>").read()) model.load_state_dict(torch.load(buffer))其中
-
endpoint为Bucket所在地域对应的Endpoint。以华东1(杭州)为例,Endpoint填写为https://oss-cn-hangzhou.aliyuncs.com。
-
<your_bucket_name>为OSS Bucket名称,且开头不带oss://。
-
<your_model_path>为模型路径,都需要根据实际情况修改。
-
-