
本文介绍了什么是AUTO模式数据库与DRDS模式数据库,以及这两者模式的区别。
PolarDB-X数据库模式概述
从PolarDB-X 5.4.13版本开始,新增支持AUTO模式的数据库(也称为自动分区数据库)。AUTO模式的数据库支持自动分区,即创建表时无需指定分区键,数据即可自动在集群内均匀分布;同时也支持使用标准的MySQL分区表语法,对表进行手动分区。可以让您便捷地享受到分布式数据库的透明式分布、弹性伸缩和分区管理等诸多红利。
PolarDB-X 5.4.13版本之前的数据库称为DRDS模式的数据库。这种模式的数据库不支持自动分区,创建表时需使用DRDS专用的分库分表语法,指定分库分表键,否则创建的是一张单表。
AUTO模式数据库和DRDS模式数据库在5.4.13及以上版本都支持,并且可以共存在一个实例中。
注意事项
创建AUTO模式数据库必须在
CREATE DATABASE语法中显式指定MODE='AUTO'。如果在
CREATE DATABASE语法中不指定MODE参数的值,默认创建DRDS模式的数据库。AUTO模式数据库下不支持使用DRDS分库分表的语法创建表,仅支持创建分区表。
DRDS模式数据库下不支持使用分区表的语法创建表,仅支持创建分库分表。
标准版集群不支持创建AUTO模式数据库。
通过MODE参数指定数据库模式
PolarDB-X在创建数据库时引入了MODE参数,以决定创建的数据库是AUTO模式还是DRDS模式。关于MODE参数的作用及其描述,如下表所示:
数据库创建完成后,MODE不允许修改。
参数 | 取值类型 | 作用 | 建库语法 | 建表语法 |
MODE | 'AUTO' | 创建的数据库为AUTO模式。 | 示例: 详情请参见CREATE DATABASE。 | AUTO模式数据库下创建的表称为分区表,采用MySQL标准语法,详情请参见MySQL分区表语法。 |
'DRDS'(默认值) 说明 若不指定MODE参数,则默认创建DRDS模式数据库。 | 创建的数据库为DRDS模式。 | 示例:
详情请参见CREATE DATABASE。 | DRDS模式数据库下创建的表称为分库分表,详情请参见DRDS分库分表语法。 |
自动分区与手动分区
自动分区
自动分区,指创建表时不指定任何分区定义(如分区键、分区策略等),PolarDB-X能够自动选择分区键并对表及其索引进行水平分区的功能。AUTO模式数据库支持自动分区,而DRDS模式数据库不支持。
示例如下:
使用标准的MySQL语法创建tb表,语法上不包含任何分区定义:
CREATE TABLE tb(a INT, b INT, PRIMARY KEY(a));上述DDL在DRDS模式数据库中创建出来的表是一张单表(如下图所示,默认不分区):
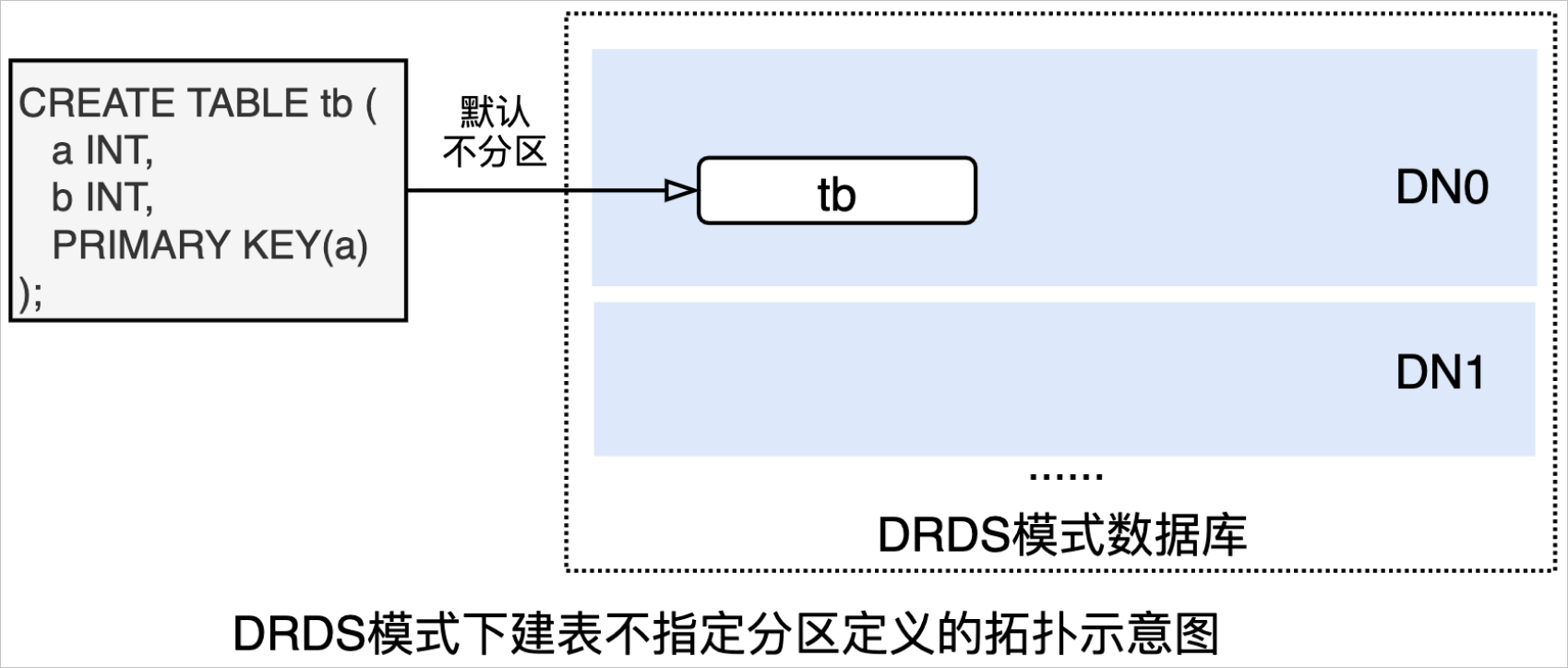
执行
SHOW语句,查看完整建表语句:SHOW FULL CREATE TABLE tb \G *************************** 1. row *************************** Table: tb Create Table: CREATE TABLE `tb` ( `a` int(11) NOT NULL, `b` int(11) DEFAULT NULL, PRIMARY KEY (`a`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 1 row in set (0.02 sec)上述DDL在AUTO模式数据库建来的表将是一分区表(如下图所示,默认按主键自动分区):
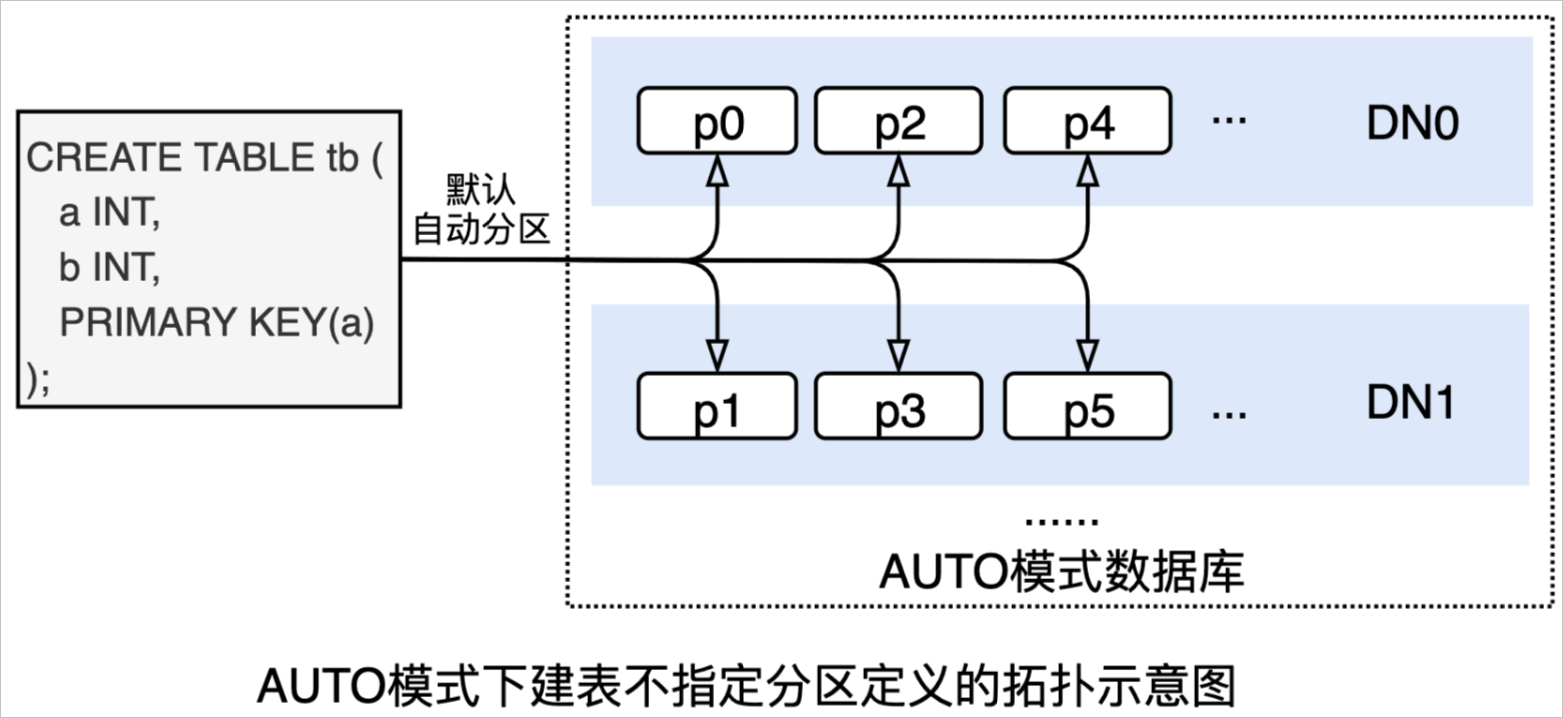 执行
执行SHOW语句,查看完整建表语句:SHOW FULL CREATE TABLE tb \G *************************** 1. row *************************** TABLE: tb CREATE TABLE: CREATE PARTITION TABLE `tb` ( `a` int(11) NOT NULL, `b` int(11) DEFAULT NULL, PRIMARY KEY (`a`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 PARTITION BY KEY(`a`) PARTITIONS 16 1 row in set (0.01 sec)
因此,在AUTO模式数据库下,只需要使用标准的MySQL建表语法(包括建索引语法等)创建表,PolarDB-X的自动分区功能可以让应用便捷地享受到分布式数据库所带来的弹性伸缩、分区管理等诸多红利。
手动分区
手动分区,即创建表时显式指定分区定义(如分区键、分区策略等)。AUTO模式数据库与DRDS模式数据库采用手动分区时的建表语法不同。
AUTO模式数据库:创建表使用标准的MySQL分区表语法,并支持HASH、RANGE、LIST等多种分区策略。
如下示例,创建tb表时使用
PARTITION BY HASH(a)语法,指定了分区键a列及HASH的分区策略:CREATE TABLE tb (a INT, b INT, PRIMARY KEY(a)) -> PARTITION by HASH(a) PARTITIONS 4; Query OK, 0 rows affected (0.83 sec) SHOW FULL CREATE TABLE tb\G *************************** 1. row *************************** TABLE: tb CREATE TABLE: CREATE TABLE `tb` ( `a` int(11) NOT NULL, `b` int(11) DEFAULT NULL, PRIMARY KEY (`a`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 PARTITION BY KEY(`a`) PARTITIONS 4 1 row in set (0.02 sec)DRDS模式数据库:创建表使用DRDS专用的分库分表语法,仅支持使用HASH策略。
如下示例,创建tb表时使用
DBPARTITION BY HASH(a) TBPARTITION BY HASH(a)语法,指定分库分表键为a列:CREATE TABLE tb (a INT, b INT, PRIMARY KEY(a)) -> DBPARTITION by HASH(a) -> TBPARTITION by HASH(a) -> TBPARTITIONS 4; Query OK, 0 rows affected (1.16 sec) SHOW FULL CREATE TABLE tb\G *************************** 1. row *************************** Table: tb Create Table: CREATE TABLE `tb` ( `a` int(11) NOT NULL, `b` int(11) DEFAULT NULL, PRIMARY KEY (`a`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 dbpartition by hash(`a`) tbpartition by hash(`a`) tbpartitions 4 1 row in set (0.02 sec)
分区表和分库分表的路由算法对比
分区表与分库分表最重要的区别,是它们的分区会使用完全不同的路由算法。如下图所示:
分库分表的路由算法是HASH值按物理分表数目取模,如果要变更分区数目(例如分表数目由4个变成5个),所有数据都需要进行rehash,因此,DRDS模式的分库分表无法提供分区级的变更能力;
分区表的默认路由算法是基于range的一致性HASH算法,这种算法天然支持通过分裂、合并操作等变更分区,并且无须rehash所有数据,因此,AUTO模式的分区表具备分区级的变更能力。
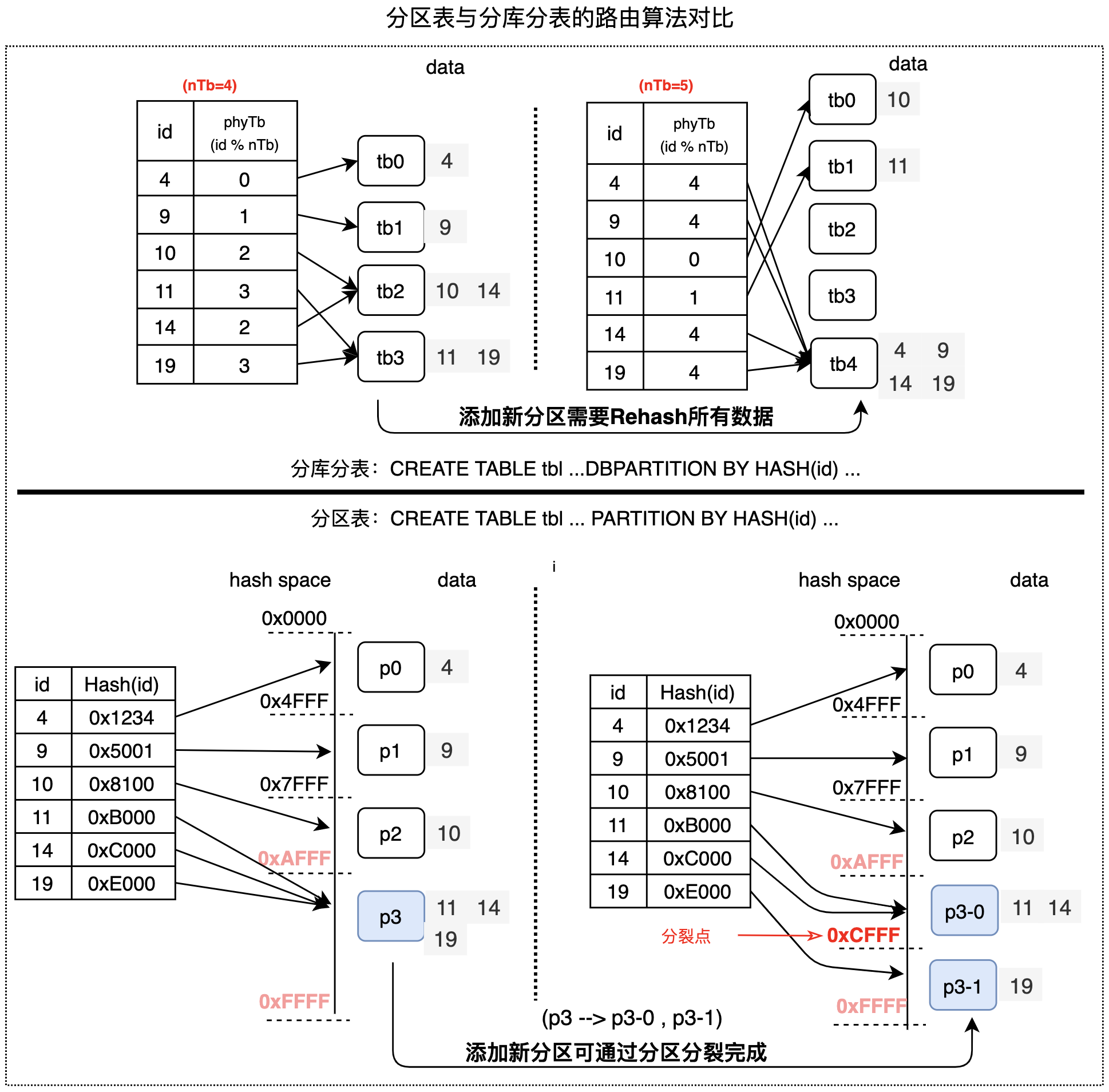
功能对比
与DRDS模式数据库相比,AUTO模式数据库新增了自动分区、热点分裂、分区调度和TTL表等新特性,并在很多其它方面(如分区管理、拆分变更等)做了大量工作以优化分布式体验。
AUTO模式数据库与DRDS模式数据库主要功能对比:
功能项 | AUTO模式数据库 | DRDS模式数据库 | |
透明分布式 | 默认主键分区 | 支持。若建表时不指定分区定义,将自动按主键进行分区。 | 不支持。 |
默认全局二级索引 | 支持。索引不指定分区列时,将自动索引列分区。 | 不支持。 | |
负载均衡调度 | 支持。 | 不支持。 | |
热点散列能力 | 支持。 | 不支持。 | |
分区策略 | Hash分区 & Key分区 | 支持。采用一致性哈希的路由算法,并支持热点散列。 | 支持采用按分区数取模的路由算法,不支持热点散列。 |
Range分区 & Range Columns分区 | 支持,支持热点散列。 | 不支持。 | |
List分区 & List Columns分区 | 支持。 | 不支持。 | |
向量分区键(使用多个列作为分区键) | 支持。分区键支持按向量分区,例如 | 不支持。 | |
分区键字符校验集 | 支持。 | 不支持。 | |
单表 & 广播表 | 支持。 | 支持。 | |
分区管理 | 创建、删除、修改分区 | 支持。 | 不支持。 |
分裂、合并分区 | 支持。 | 不支持。 | |
迁移分区 | 支持。 | 不支持。 | |
截断分区 | 支持。 | 不支持。 | |
分区透视 | 即将上线将支持自动分析热点分区。 | 不支持。 | |
拆分变更 | 调整表类型(单表、广播表与分区表互转) | 支持。 | 支持。 |
调整分区定义(包括分区数目、分区键类型、分区策略等) | 支持。 | 支持。 | |
弹性扩(缩)容 | 是否有停写阶段 | 否。 | 是(短暂的停写)。 |
是否允许其他DDL | 是。 | 否。 | |
Locality | 静态隔离 | 支持,创建库、表和分区时指定物理存储资源。 | 支持,创建库、表时指定物理存储资源。 |
动态隔离 | 支持,动态调整库表所在的物理存储资源。 | 不支持。 | |
是否与扩缩容兼容 | 是。 | 否。 | |
分区裁剪 | 前缀分区裁剪 | 支持。 例如,按 | 不支持。 |
计算表达式常量折叠 | 支持。 例如,对含计算表达式的条件 | 不支持。分区键条件要求必须是常量(如pk = 123);如果分区键是计算表达式如 | |
分区路由大小写敏感及忽略行尾空格 | 支持。 支持通过指定分区键的字符校验集(Collation)来决定分区路由是否需要区分大小写以及是否需要忽略行尾空格。 | 不支持。分区列不支持使用Collation,Hash算法只支持大小写敏感,不支持忽略行尾空格。 | |
JOIN计算下推 | 支持。 支持在分区的分裂、合并与迁移等操作期间,JOIN计算下推不受影响。 | 支持。 | |
分区选择 | 支持。 支持分区选择语法查询特定分区,例如 | 不支持。 | |
TTL(分区的生命周期管理) | 支持。 | 不支持。 | |
AUTO_INCREMENT | 支持。保证全局唯一性、单调递增和连续性。 | 支持。保证全局唯一性,不保证单调递增和连续性。 | |
性能对比
由于DRDS模式分库分表与AUTO模式分区表使用了不同的路由算法,为了评估这两种路由算法的性能差异,将使用Sysbench对PolarDB-X进行基准测试,观察它们在不同的Sysbench测试场景下的吞吐(单位:QPS)差异。
测试环境
PolarDB-X实例规格:polarx.x4.2xlarge.2e
CN (16C64G) × 2
DN (16C64G) × 2
版本:5.4.13-16415631
分区表和分库分表配置:
分区表:
32个分区
分区语句:partition by hash(id) partitions 32
表数据总量:16000W
分库分表:
32个物理分表
分库分表语句:dbpartition by hash(id) tbpartition by hash(id) tbpartition 2
表数据总量:16000W
测试场景
Sysbench细分场景说明:
oltp_point_select:仅含分区键的单点等值查询。
oltp_read_only:事务中同时混合分区键的单点查询与小范围查询(例如Between)。
oltp_read_write:事务中同时混合分区键的单点与小范围的查询与写入。
测试结果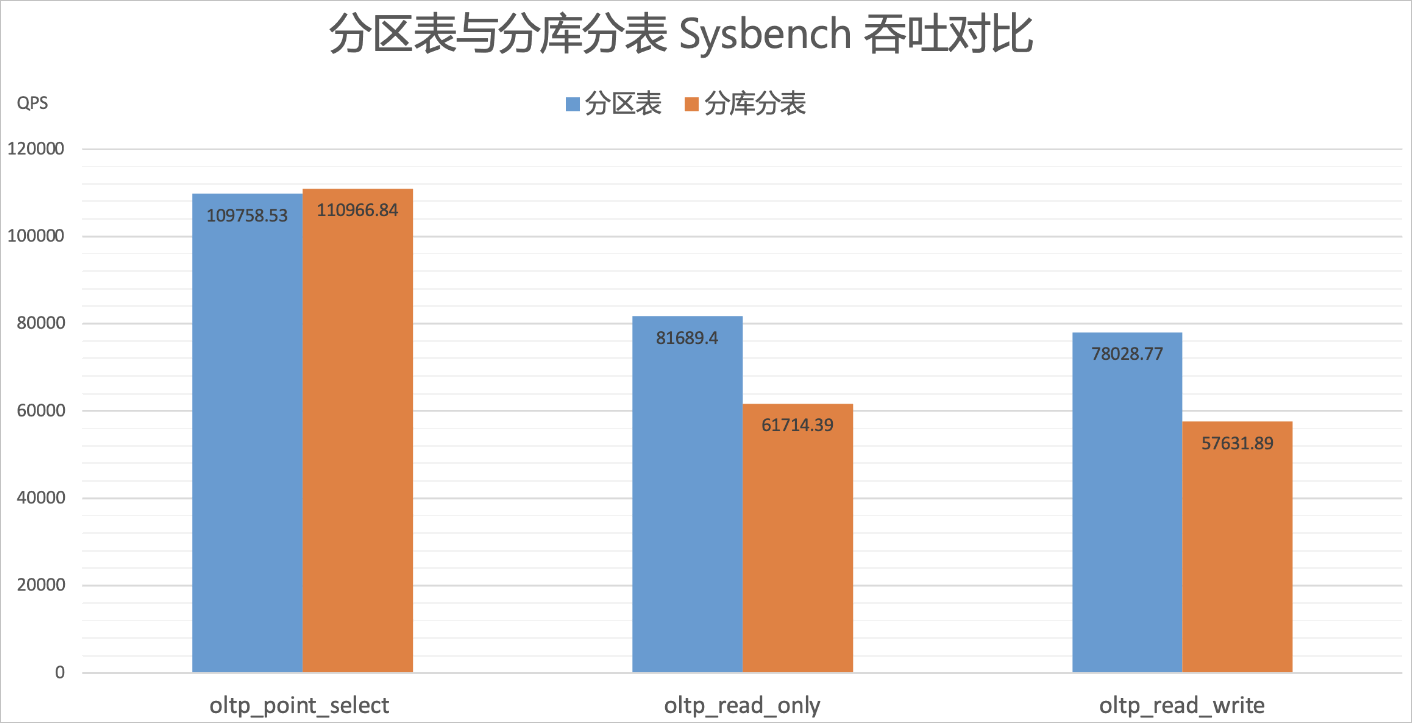
分析以上测试结果,可以得出以下结论:
分区表使用的一致性HASH路由算法虽然比原来分库分表中按HASH取模的路由算法更为复杂,但在oltp_point_select场景中吞吐并没有下降太多,基本与原来的持平。
在oltp_read_only&oltp_read_write场景中,由于这些场景会出现小范围的查询,SQL的查询条件表达式会比oltp_point_select复杂,得益于分区表的裁剪优化,整体吞吐比原来提升约33%。
FAQ
Q1:建库时,AUTO模式与DRDS模式应该如何选择?
A:从5.4.13及以上版本开始,从PolarDB-X 1.0迁移过来的或者全新的应用,均推荐使用AUTO模式。
Q2:在AUTO模式下,建表时自动分区与手动分区应该如何选择?
A:在测试阶段可以完全用自动分区的方式,当发现业务需要调优的时候,可以通过DDL(
ALTER PARTITION)语句变更表的分区方式。如果非常了解业务的具体SQL,知道具体的表与表之间的关联关系,可以按照手动分区的方式建表。Q3:DRDS模式的数据库如何切换到AUTO模式?
A:内核5.4.16及以上版本可以采用下列任意方式;低于5.4.16的版本,仅支持方法二和方法三。关于如何查看实例版本,请参见查看实例版本。
方法一:从5.4.16版本开始,内核提供了
create database like/as语法,可以一键将DRDS模式数据库切换为AUTO模式,使用方法请参见将DRDS模式数据库转换为AUTO模式数据库;方法二:在目标实例创建对应的AUTO模式数据库,在AUTO模式数据库下将表创建好,然后通过DTS服务,将原DRDS模式的库同步到AUTO模式的库。
方法三:通过
mysqldump命令将原来的DRDS模式数据库的数据文件dump下来(不含建表语句),然后创建对应的AUTO模式数据库,在AUTO模式数据库下将表创建好,然后将dump下来的数据文件通过source命令导入目标AUTO模式数据库。
Q4:AUTO模式自动分区的默认分区数是多少?
A:AUTO模式的自动分区数目=实例创建时的节点数目×8 。 例如,实例创建时使用2个节点,则默认的自动分区数目=2×8=16。 分区数在实例完成创建后将一直保持不变(它不会受实例扩缩容的影响),除非手动调整对应的参数值。
Q5:是否支持手动调整自动分区的默认分区数?
A:支持。默认分区数对应的参数名称是AUTO_PARTITION_PARTITIONS,参数的生效级别是实例级。因此,该参数被调整后,实例中所有的AUTO模式数据库下新创建的表的自动分区数都将发生改变。需要注意的是,如果新创建的表的分区数与原来已创建的表的分区数不一致,将会导致它们之间的JOIN计算下推失效,影响执行效率,建议手动调整分区数,详情请参见变更表级分区(AUTO模式)。