
扩展性原理
扩展性本质在于分而治之,PolarDB-X 1.0计算资源通过水平拆分(分库分表)和垂直拆分,将数据分散到多个存储资源MySQL以实现获取数据读写并发和存储容量分散的效果。
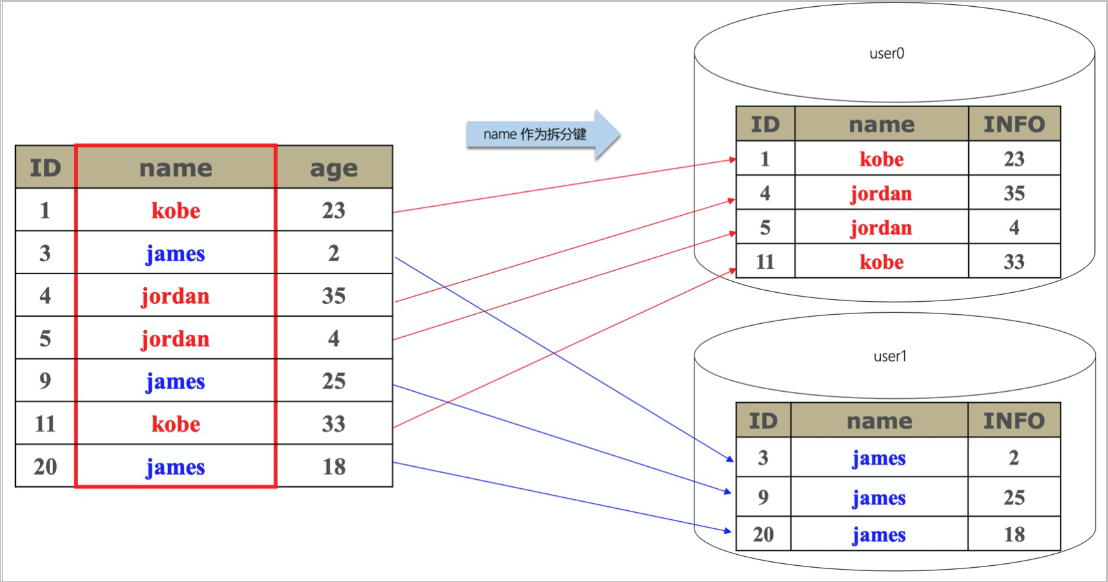
水平拆分(分库分表)PolarDB-X 1.0具备数据水平拆分的能力,将数据库数据按某种规则分散存储到多个稳定的MySQL数据库上。这些MySQL数据库可分布于多台机器乃至跨机房,对外服务(增删改查)尽可能保证如同单MySQL数据库体验。拆分后,在MySQL上物理存在的数据库称为分库,物理的表称为分表(每个分表数据是完整数据的一部分)。PolarDB-X 1.0通过在不同MySQL实例上挪动分库,实现数据库扩容,提升PolarDB-X 1.0数据库总体访问量和存储容量。
您可以通过一定的计算或路由规则放置数据,实现将数据分散到多个存储资源MySQL中。PolarDB-X 1.0具备丰富的算法来应对各种场景。
数据拆分原理如下图所示:
 计算扩展性
计算扩展性无论是水平拆分还是垂直拆分,PolarDB-X 1.0常常碰到需要对远超单机容量数据进行复杂计算的需求,例如需要执行多表JOIN、多层嵌套子查询、Grouping、Sorting、Aggregation等组合的SQL操作语句。
针对这类在线数据库上复杂SQL的处理, PolarDB-X 1.0额外扩展了单机并行处理器(Symmetric Multi-Processingy,简称SMP)和多机并行处理器(DAG)。前者完全集成在PolarDB-X 1.0内核中;而对于后者,PolarDB-X 1.0构建了一个计算集群,能够在运行时动态获取执行计划并进行分布式计算,通过增加节点提升计算能力。
平滑扩容
PolarDB-X 1.0扩容是通过增加RDS/PolarDB MySQL实例数,将原有的分库迁移到新的RDS/PolarDB MySQL实例上,达到扩容的目标。PolarDB-X 1.0采用基于存储计算分离的Shared-Nothing架构,最大限度地发挥了云数据库的弹性扩展能力。
- 创建扩容计划
选择新增加RDS/PolarDB MySQL,并选定需要迁移到新RDS/PolarDB MySQL实例上的分库,提交任务后系统自动在目标RDS/PolarDB MySQL上创建数据库和账号,并提交任务进行数据迁移同步。
- 全量迁移
系统选择当前时间之前的一个时间点,将这个时间点之前的数据进行全量的数据复制迁移。
- 增量数据同步
完成全量迁移后,基于全量迁移开始之前时间点的增量变更日志进行增量同步,最终原分库和目标分库数据实时同步。
- 数据校验
增量达到准实时同步后,系统自动做全数据校验,并且订正因为同步延迟造成的不一致数据。
- 应用停写和路由切换
校验完成后,并且增量依然维持准实时同步,业务选定时间进行切换,为确保数据严格一致,建议应用停服(也可以不停,但可能面临同一条数据高并发写入覆盖问题),引擎层进行分库规则的路由切换,将后续流量转向新库,切换过程秒级完成。
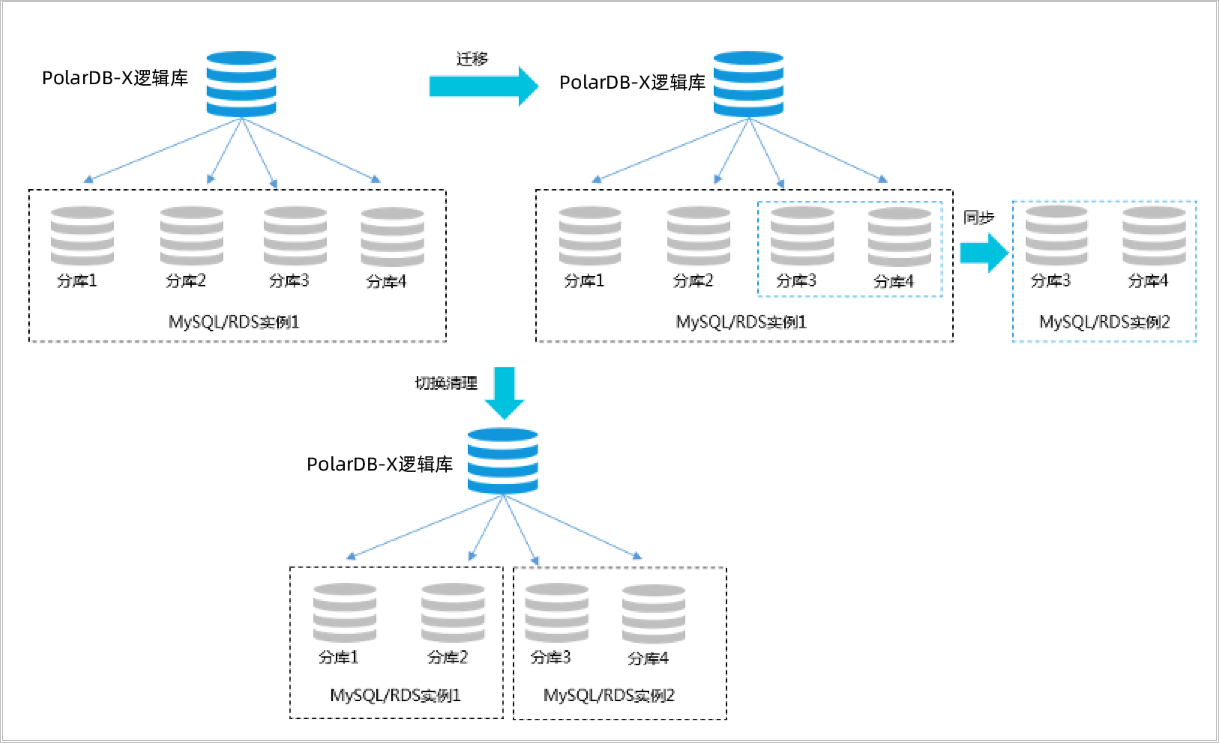
为了保证数据本身的安全,便于扩容回滚,在路由规则切换完成后,数据同步依然会运行,直到数据运维人员确认服务正常后在控制台主动发起旧分库数据的清理。
整个扩容过程对上层的业务正常服务几乎没有影响(如果RDS/MySQL实例规格过小或者压力过大则可能造成部分影响),切换时如果应用不停服,建议操作选择在数据库访问低谷期进行,降低同一条数据并发更新覆盖的概率。
读写分离
PolarDB-X 1.0的读写分离功能是基于RDS/MySQL只读实例所做的一种相对透明读流量切换策略。当PolarDB-X 1.0存储资源MySQL主实例的读请求较多、读压力比较大时,您可以通过读写分离功能对读流量进行分流,减轻存储层的读压力。
业务应用在能够忍受只读实例相对于主实例数据同步延迟的前提下,不需要修改代码,即可在PolarDB-X 1.0控制台中增加RDS/MySQL只读实例和调整读权重,将读流量按照需要的比例在RDS/MySQL主实例与多个RDS/MySQL只读实例之间调整,写操作和事务操作则统一走RDS/MySQL主实例。需要注意的是,主RDS/MySQL实例和只读RDS/MySQL存在数据同步延迟,并且在发生大的DDL或者数据订正时,有可能导致分钟级别以上的延迟,所以需要业务忍受该情况所带来的影响。添加只读实例可以使读性能线性提升。例如在初始有一个只读实例的情况下,挂载一个只读实例,读性能提升至原来两倍,挂载2个只读实例,则读性能为单个主库读性能的三倍。
读写分离流量分配与扩展PolarDB-X 1.0读写分离功能采用了对应用透明的设计。在不修改应用程序任何代码的情况下,只需在控制台中调整读权重,即可实现将读流量按自定义的权重比例在存储资源MySQL/RDS主实例与多个存储资源只读实例之间进行分流,而写流量则不做分流全部到指向主实例。
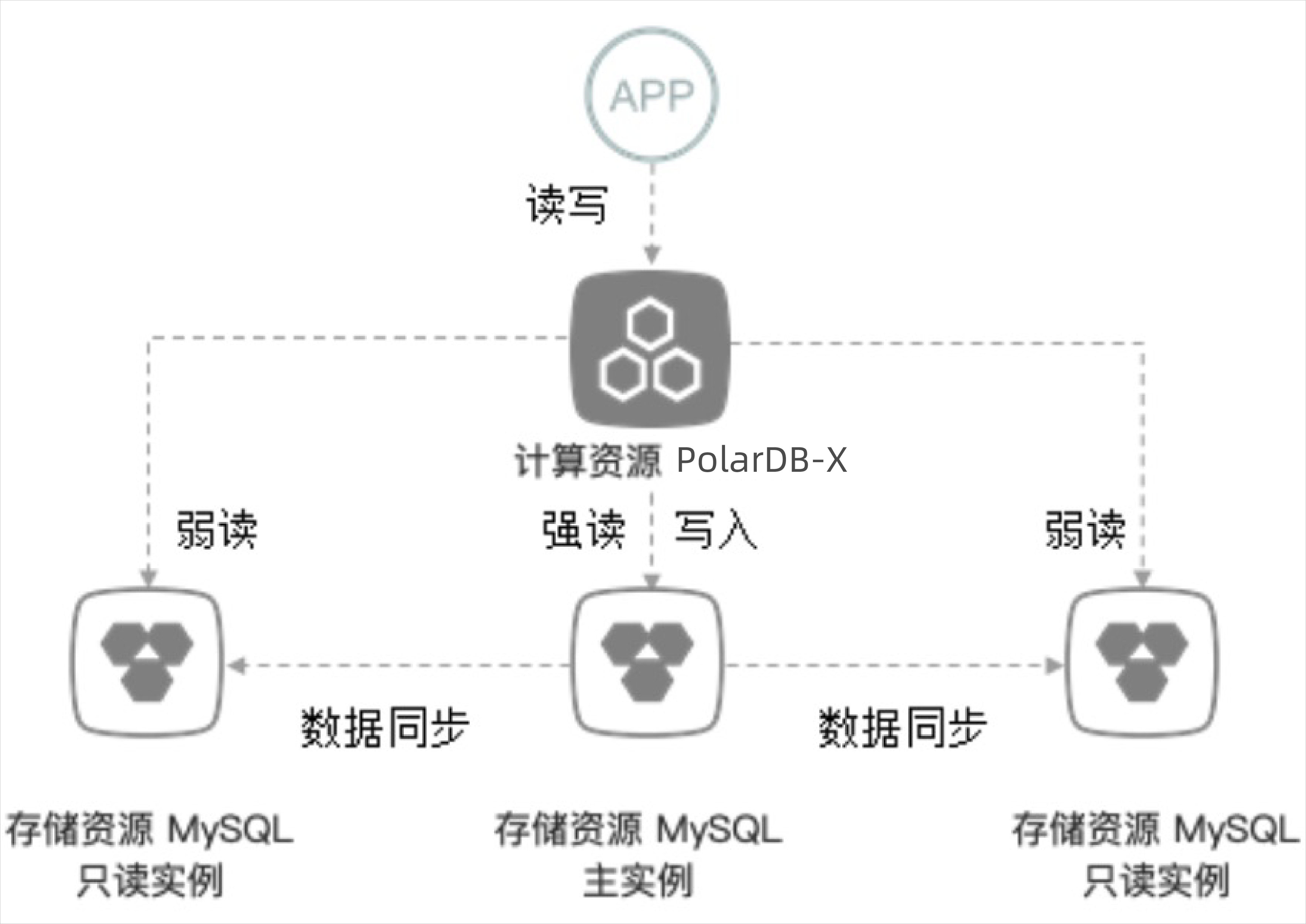
读写分离对事务的支持
读写分离仅对显式事务(即需要显式提交或回滚的事务)以外的读请求(即查询请求)有效,写请求和显式事务中的读请求(包括只读事务)均在主实例中执行,不会被分流到只读实例。
- 读请求:SELECT、SHOW、EXPLAIN、DESCRIBE。
- 写请求:INSERT、REPLACE、UPDATE、DELETE、CALL。
PolarDB-X 1.0的读写分离可以在非拆分模式下独立使用。
PolarDB-X 1.0控制台上创建PolarDB-X 1.0数据库时,在选定一个数据库实例的情况下,可以选择将底层数据库实例下的一个逻辑数据库直接引入PolarDB-X 1.0做读写分离,不需要做数据迁移。
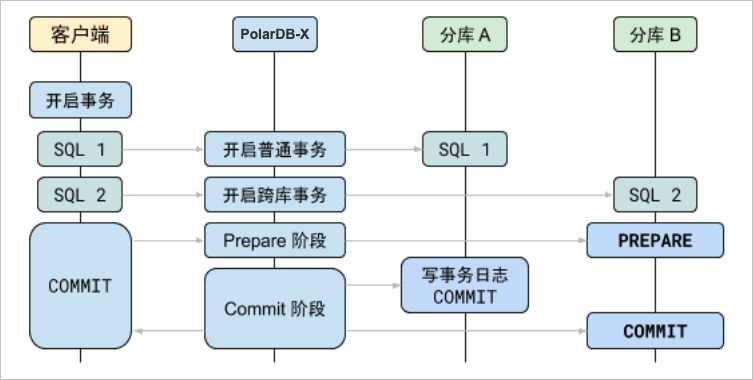
分布式事务
分布式事务通常使用二阶段提交来保证事务的原子性(Atomicity)和一致性(Consistency)。
- 准备(PREPARE)阶段:在PREPARE阶段,数据节点会准备好所有事务提交所需的资源(例如加锁、写日志等)。
- 提交(COMMIT)阶段:在COMMIT阶段,各个数据节点才会真正提交事务。
当提交一个分布式事务时,PolarDB-X 1.0服务器会作为事务管理器的角色,等待所有数据节点(MySQL服务器)PREPARE成功,之后再向各个数据节点发送COMMIT请求。
全局二级索引
全局二级索引(Global Secondary Index,GSI)支持按需增加拆分维度,提供全局唯一约束。每个GSI对应一张索引表,使用XA多写保证主表和索引表之间数据强一致。
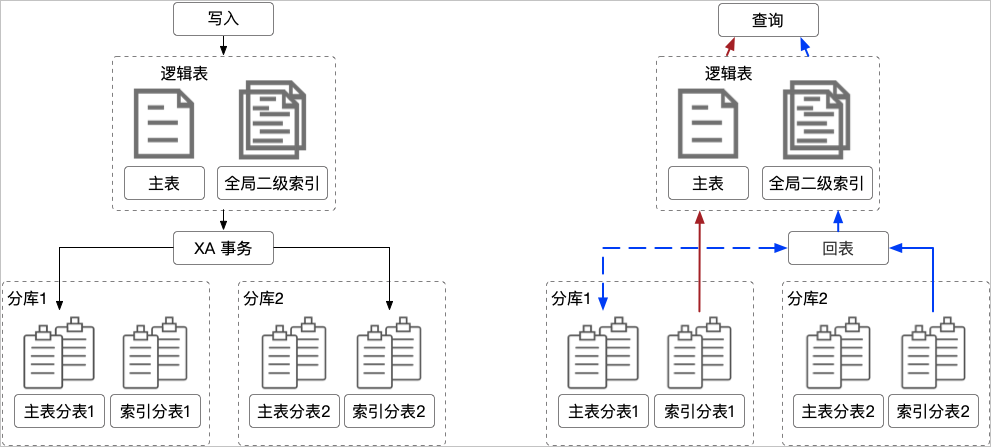
- 增加拆分维度。
- 支持全局唯一索引。
- XA多写,保证主表与索引表数据强一致。
- 支持覆盖列,减少回表操作,避免额外开销。
- Online Schema Change,添加GSI不锁主表。
- 支持通过HINT指定索引,自动判断是否需要回表。
HTAP
PolarDB-X 1.0解决了OLTP数据库面对海量数据下的存储、并发方面的扩展性问题,但由于缺失多机并行查询加速能力和列存储等能力,无法满足对实时性计算和复杂查询都要求较高的在线业务场景,同时还面临着ETL(Extract-Transform-Loa)数据异步传输链路运维复杂度高、数据一致性和查询实时性无法严格保障等挑战。
PolarDB-X 1.0由多个节点构成计算、存储内核一体化实例,在共用一份数据的基础上避免了ETL(Extract-Transform-Load)操作,实现了在线高并发OLTP联机事务处理以及OLAP海量数据分析,即HTAP。
原理架构
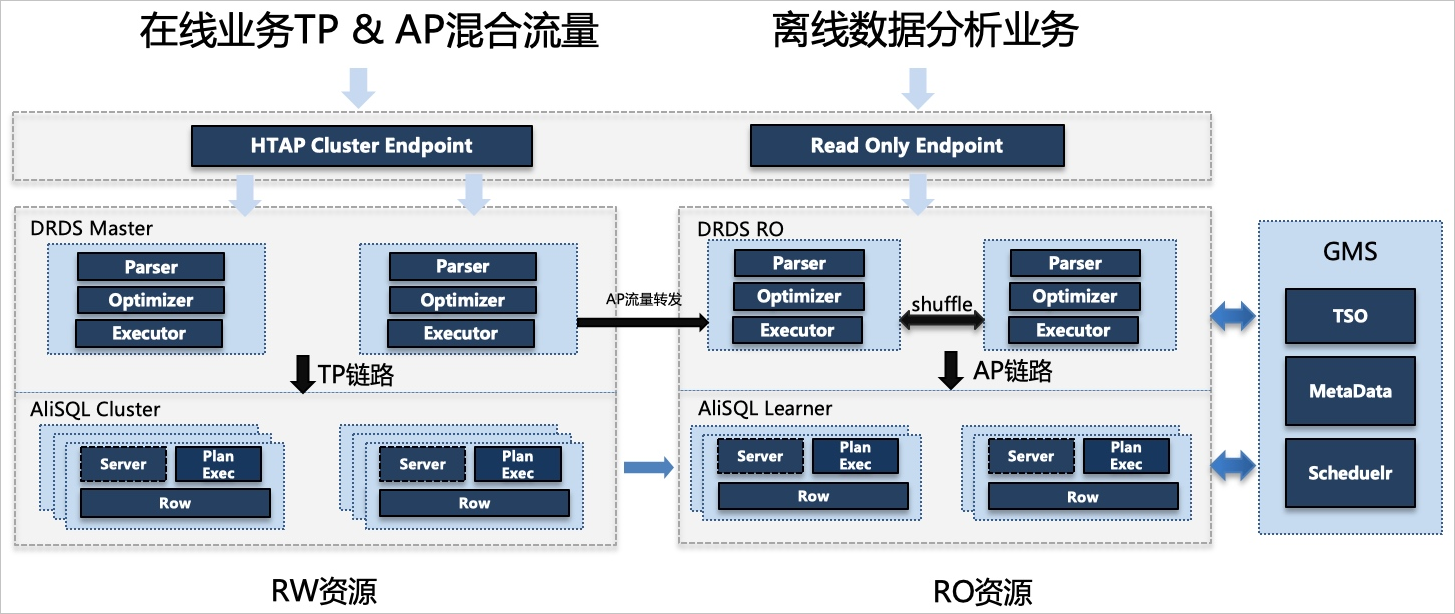
- MPP和只读资源
PolarDB-X 1.0通过多组DRDS计算节点提供大规模多级并行处理能力(Massively Parallel Processing,简称MPP),针对计算节点进行Scale-out完成MPP处理能力的线性扩展。
同时通过AiSQL三节点基于Paxos构建Row-based只读Learner配合DRDS只读计算节点,提供TP、AP资源链路隔离机制。
- 连接地址和数据源
PolarDB-X 1.0的TP和AP请求提供了统一连接地址(Endpoint),保持SQL语义以及兼容性完全一致。
主实例提供HTAP集群地址(Cluster Endpoint)面向在线通用业务场景,提供了智能读写分离和强一致读特性。只读实例提供HTAP只读地址(Private Read Only Endpoint),专注离线拖数、跑批等资源链路隔离场景,确保只读资源可被独享。
若PolarDB-X 1.0已添加只读实例,默认将AP workload转发至只读实例进行MPP并行加速;若未添加任何只读实例,则转发至主实例内部所有计算节点完成执行。
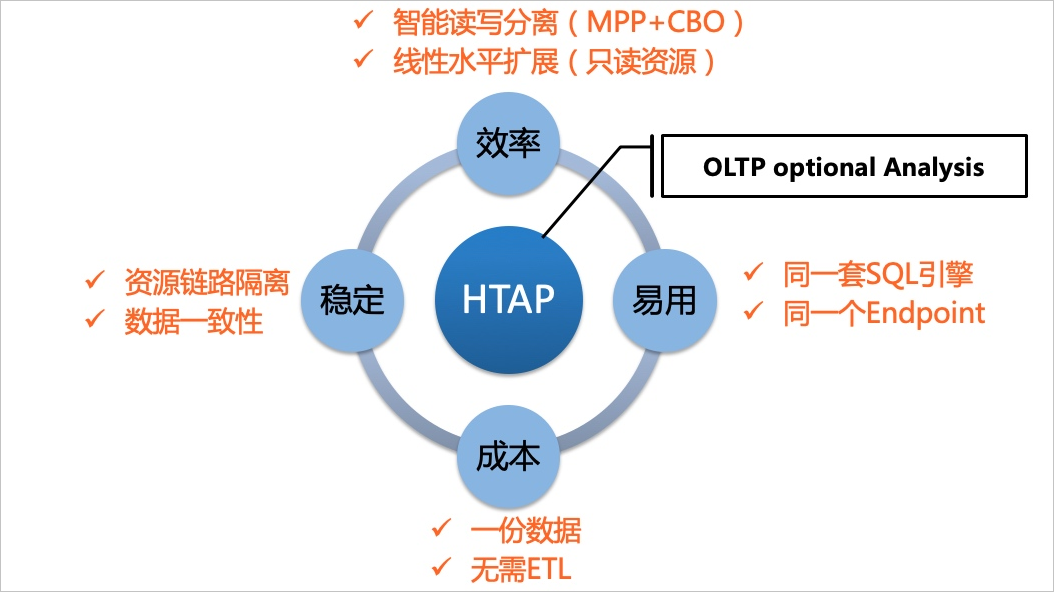
- 一份数据,一个数据源,一个Endpoint即可覆盖TP和AP业务场景,降低数据库选型成本。
- 支持线性水平扩展提升HTAP复杂查询加速能力,通过横向增加只读实例即可提高复杂查询速率。
- 避免数据异步传输,满足全局数据查询一致性,提升业务实时分析效率。
- 资源链路隔离,确保在线核心业务链路稳定性。