
本文介绍如何使用Prometheus监控Cassandra。
步骤一:自行部署Cassandra JMX Agent(可选)
若所属环境为ECS,您需要部署Agent。若所属环境为容器环境,请忽略此步骤。
您需要根据Cassandra的版本下载合适的Cassandra JMX Agent到Cassandra所在的ECS内。
解压缩下载的Agent压缩包到
MCAC_ROOT,修改cassandra-env.sh文件,追加以下内容。MCAC_ROOT=/path/to/directory JVM_OPTS="$JVM_OPTS -javaagent:${MCAC_ROOT}/lib/datastax-mcac-agent.jar"重要Cassandra JMX Agent给Prometheus暴露的数据抓取端口为9103,如果需要修改为其他的端口,则修改${MCAC_ROOT}/config/collectd.conf.tmpl文件中的如下图所示的内容为想要提供的端口。
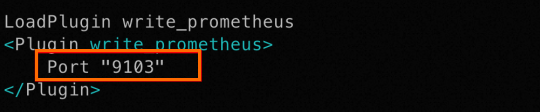
完成上述配置之后,重新启动Cassandra应用程序,在ECS服务器上执行命令
curl localhost:{jmx端口}/metrics,查看是否正常有数据返回,如果有数据返回,则说明Cassandra JMX Agent已经正确安装。
步骤二:接入 Cassandra
在左侧导航栏,单击接入中心。
在接入中心页面的数据库区域,单击 Cassandra。

在Cassandra面板的开始接入页签完成接入,然后单击确定。
参数
说明
选择所属环境类型
可以接入以下两种服务环境:
容器服务环境
ECS(VPC)
选择集群
选择目标集群。
Pod 标签
部署 Cassandra 服务 Pod 的标签(建议使用有特定标识的标签)
服务端口
步骤一中安装的 Cassandra JMX Agent 的端口,默认端口号会自动填充。
Metrics 采集路径
步骤一中安装的 Cassandra JMX Agent 指标透出路径,默认路径会自动填充。
Metric 采集间隔(单位/秒)
可观测监控 Prometheus 版采集指标数据的时间间隔,默认30秒。
步骤三:查看Cassandra大盘数据
在左侧导航栏,单击接入管理。
在接入管理页面的已接入环境页签中,选择目标环境,在目标环境列表中,单击目标环境名称进入容器环境详情页面。

在组件管理页签下的组件类型区域,单击Cassandra,然后单击大盘,即可查看所有的大盘名称。

单击目标大盘名称,查看对应的Grafana大盘。
步骤四:配置 Cassandra 监控告警
在组件管理页签下的组件类型区域,单击Cassandra,然后单击告警规则,即可查看默认创建的告警规则。
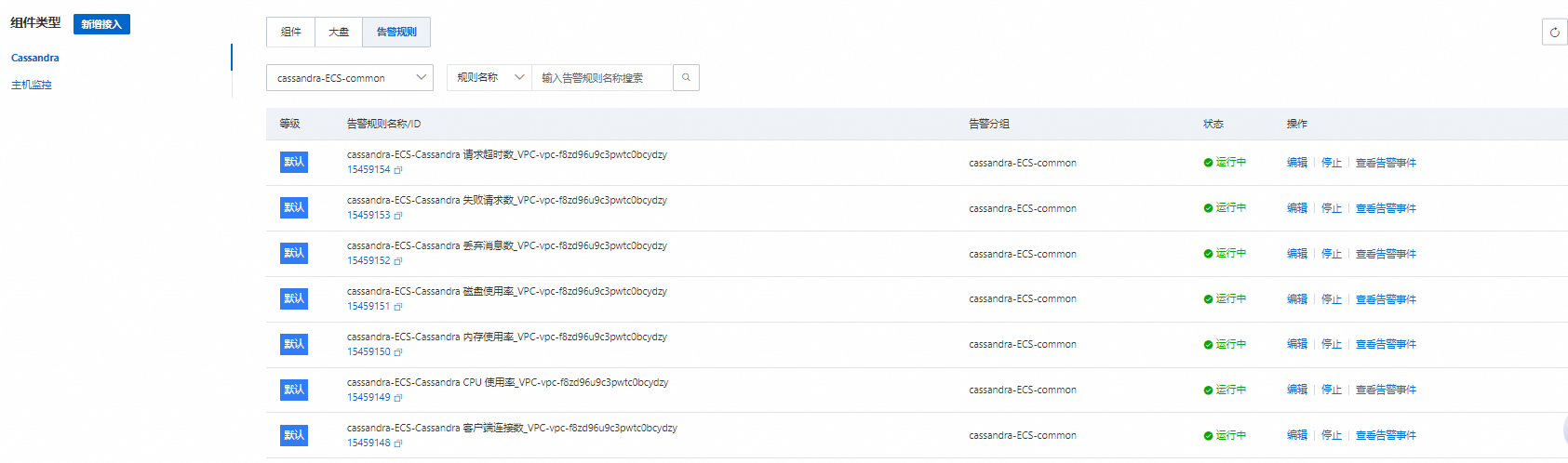
您还可以根据业务需求新增告警规则,创建Prometheus告警规则的具体操作,请参见创建Prometheus告警规则。
关键指标说明
集群/节点基础信息
指标名称 | 关键级别 | 指标描述 | 指标说明 |
mcac_client_connected_native_clients | Major | CQL连接数 | 连接数过多会占用系统过多资源,导致客户端延迟变高。 |
mcac_table_live_disk_space_used_total | Major | cassandra占据的空间 | 该指标过高可能导致硬盘空间不足以及数据存取延迟增加。 |
mcac_table_snapshots_size | Recommand | cassandra快照文件大小 | 快照用于数据恢复,该指标过高可能导致硬盘空间不足从而无法存储下完整的快照。 |
collectd_uptime | Major | 节点开机时间 | 该指标过高说明系统长期没有进行重启,存在漏洞的系统可能会带来安全隐患。 |
关键性能指标
指标名称 | 重要级别 | 指标描述 | 指标说明 |
mcac_table_read_latency | Critical | 客户端读取数据的延迟 | 该指标过高会导致应用程序的读取速度变慢,影响用户体验。 |
mcac_table_write_latency | Critical | 客户端写数据的延迟 | 该指标过高会导致应用程序的写入速度变慢,影响用户体验。 |
异常和错误
指标名称 | 重要级别 | 指标描述 | 指标说明 |
mcac_client_request_timeouts_total | Critical | 超时的客户端请求 | 该指标过高,说明系统负载较高,会严重影响用户体验。 |
mcac_client_request_failures_total | Critical | 出现异常的客户端请求 | 该指标过高,说明系统负载较高,会严重影响用户体验。 |
mcac_dropped_message_dropped_total | Critical | 丢弃的消息 | 该指标过高,说明系统负载较高,会严重影响用户体验。 |
缓存和布隆过滤器
指标名称 | 重要级别 | 指标描述 | 指标说明 |
mcac_table_key_cache_hit_rate | Major | key_cache的命中率 | 该指标过低可能会导致应用程序的读取速度变慢,影响用户体验。 |
mcac_table_row_cache_hit_total | Major | row_cache的命中次数 | 该指标过低可能会导致应用程序的读取速度变慢,影响用户体验。 |
mcac_table_row_cache_miss_total | Recommand | row_cache未命中的次数 | 该指标过高可能会导致应用程序的读取速度变慢,影响用户体验。 |
mcac_table_row_cache_hit_out_of_range_total | Recommand | row_cache命中但还是去访问磁盘的次数 | 该指标过高可能会导致应用程序的读取速度变慢,影响用户体验。 |
mcac_table_bloom_filter_false_ratio | Major | 布隆过滤器的误判率 | 当布隆过滤器误报比例过高时,会导致查询结果中有很多本来不存在的元素被判断为存在,从而浪费查询时间和资源。这会降低查询性能并增加查询成本。 |
CPU/内存/硬盘使用趋势
指标名称 | 重要级别 | 指标描述 | 指标说明 |
collectd_cpu_total | Critical | CPU的使用率 | 该指标过高说明系统负载较高,会导致客户端请求延迟过高,严重影响用户体验。 |
collectd_memory | Critical | 内存的使用率 | 该指标过高说明系统负载较高,会导致客户端请求延迟升高,严重影响用户体验。 |
collectd_df_df_complex | Critical | 硬盘的使用率 | 该指标过高说明硬盘可用空间不足,会导致数据无法正常持久化存储,有宕机的风险。 |
SSTable压缩
指标名称 | 重要级别 | 指标描述 | 指标说明 |
mcac_table_pending_compactions | Major | 进行中的SSTable压缩任务 | 该指标过高说明系统负载较高,会导致客户端请求延迟升高,建议合理配置SSTable的压缩间隔。 |
mcac_table_compaction_bytes_written_total | Major | SSTable的压缩速率 | 该指标过低说明系统压缩速率较慢,会导致压缩任务累积,建议提高节点的硬件配置。 |
mcac_table_compression_ratio | Major | SSTable的压缩率 | 该指标过高说明压缩后的文件仍然过大,压缩没有达到预期的效果。 |
磁盘文件
指标名称 | 重要级别 | 指标描述 | 指标说明 |
mcac_table_live_ss_table_count | Major | SSTable的数量 | 该指标越高会导致硬盘占用过高并且读写延迟增加,需合理配置SSTable的压缩策略。 |
mcac_table_live_disk_space_used_total | Major | SSTable占用的硬盘空间 | 该指标越高会导致硬盘占用过高并且读写延迟增加,需合理配置SSTable的压缩策略。 |
mcac_table_ss_tables_per_read_histogram | Major | 一次read操作需要读取的SSTable数量 | 该指标越高会导致客户端读取延迟增加。 |
mcac_commit_log_total_commit_log_size | Major | Commit Log占用的硬盘空间 | 该指标过高会导致硬盘空间不足,读写性能下降以及数据恢复时间增加。 |
mcac_table_memtable_live_data_size | Major | MemTable占用的空间 | 该指标过高会导致数据写入性能下降,节点稳定性下降。 |
mcac_table_waiting_on_free_memtable_space | Major | 等待释放MemTable花费的时间 | 该指标过高会导致数据写入性能下降,节点稳定性下降。 |
线程池状态
指标名称 | 重要级别 | 指标描述 | 指标说明 |
mcac_thread_pools_active_tasks | Critical | 线程池中正在活跃的任务数量 | 阻塞任务过多会导致占用系统资源过高,响应速度下降甚至系统崩溃。 |
mcac_thread_pools_total_blocked_tasks_total | Critical | 线程池中正处于阻塞状态的任务数量 | 阻塞任务过多会导致占用系统资源过高,响应速度下降甚至系统崩溃。 |
mcac_thread_pools_pending_tasks | Critical | 线程池中处于pending状态的任务数量 | 处于pending状态的任务过多会导致占用系统资源过高,这些任务对应的请求超时,甚至导致系统崩溃。 |
mcac_thread_pools_completed_tasks | Major | 线程池中已经完成的任务数量 | 该指标可以反映系统的吞吐量,该指标越高说明系统的性能优秀。 |
JVM相关
指标名称 | 重要级别 | 指标描述 | 指标说明 |
mcac_jvm_memory_used | Critical | 已经使用的JVM堆内存大小 | 该指标越高,可能导致内存不足,触发频繁的垃圾回收,降低应用的吞吐率。 |
mcac_jvm_gc_time | Critical | 应用程序用于GC的时间 | 该指标过高说明GC过于频繁,系统用于执行用户任务时间较少,可能导致客户端请求超时,甚至导致系统崩溃等。 |