
日志审计提供一键式跨账号采集云产品日志及中心化存储功能。对于已开通日志审计的阿里云产品,日志服务默认采集所有符合限定条件的云产品日志。而通过采集策略,可对账号、地域或实例等因素进行限制,实现精细化的日志采集目的。本文介绍如何配置采集策略。
产品支持
采集策略目前支持RDS、PolarDB-X 1.0、PolarDB、SLB、ALB、DNS、Kubernetes容器和IDaaS,详细说明如下所示。
云产品 | 采集对象 | 属性 | 说明 |
RDS | RDS实例 | 账号:account.id | RDS实例所属的阿里云账号ID。 |
地域:region | RDS实例所属的地域,例如:cn-shanghai。 | ||
实例ID:instance.id | RDS实例ID。 | ||
实例名:instance.name | RDS实例名。 | ||
DB类型:instance.db_type | DB类型,可取值为mysql、pgsql、mssql。 | ||
DB版本号:instance.db_version | DB版本号,例如:8.0。 | ||
标签:tag.* | 用户自定义的标签名。 将tag.*中的星号(*)替换为您自定义的标签名。 | ||
PolarDB | PolarDB集群 | 账号:account.id | PolarDB集群所属的阿里云账号ID。 |
地域:region | PolarDB集群所属的地域,如cn-shanghai。 | ||
集群ID:cluster.id | PolarDB集群ID。 | ||
集群名:cluster.name | PolarDB集群名称。 | ||
集群兼容的DB类型:cluster.db_type | PolarDB集群兼容的DB类型,目前只支持MySQL。 | ||
集群兼容的DB版本:cluster.db_version | DB版本号,可选值为8.0、5.7和5.6。 | ||
标签:tag.* | 用户自定义的标签名。 将tag.*中的星号(*)替换为您自定义的标签名。 | ||
PolarDB-X 1.0 | PolarDB-X 1.0实例 | 账号:account.id | PolarDB-X 1.0实例所属的阿里云账号ID。 |
地域:region | PolarDB-X 1.0实例所属的地域,例如:cn-shanghai。 | ||
实例ID:instance.id | PolarDB-X 1.0实例ID。 | ||
实例名:instance.name | PolarDB-X 1.0实例名。 | ||
SLB | SLB实例 | 账号:account.id | SLB实例所属的阿里云账号ID。 |
地域:region | SLB实例所属的地域,例如:cn-shanghai。 | ||
实例ID:instance.id | SLB实例ID。 | ||
实例名:instance.name | SLB实例名。 | ||
网络类型:instance.network_type | SLB网络类型,包括专有网络(VPC)和经典网络(Classic)。 | ||
VPC ID:instance.vpc_id | SLB实例所属的专有网络VPC ID。 | ||
地址类型:instance.address_type | SLB实例的地址类型,包括阿里云内网(intranet)和公网(internet)。 | ||
标签:tag.* | 用户自定义的标签名。 将tag.*中的星号(*)替换为您自定义的标签名。 | ||
ALB | ALB实例 | 账号:account.id | ALB实例所属的阿里云账号ID。 |
地域:region | ALB实例所属的地域,例如:cn-shanghai。 | ||
实例ID:instance.id | ALB实例ID。 | ||
实例名:instance.name | ALB实例名。 | ||
VPC ID:instance.vpc_id | ALB实例所属的专有网络VPC ID。 | ||
地址类型:instance.address_type | ALB实例的地址类型,包括阿里云内网(Intranet)和公网(Internet)。 | ||
标签:tag.* | 用户自定义的标签名。 将tag.*中的星号(*)替换为您自定义的标签名。 | ||
DNS内网 | VPC实例 | 账号:account.id | VPC实例所属的阿里云账号ID。 |
地域:region | VPC实例所在的地域。 | ||
实例ID:instance.id | VPC实例ID。 | ||
实例名:instance.name | VPC实例名。 | ||
标签:tag.* | 用户自定义的标签名。 将tag.*中的星号(*)替换为您自定义的标签名。 | ||
DNS 公网解析日志和全局流量管理日志 | 域名 | 账号:account.id | 域名所属的阿里云账号ID。 |
域名:domain | 域名Domain。 | ||
Kubernetes容器(Kubernetes审计日志) | Kubernetes集群 | 地域:region | Kubernetes集群所属地域,例如:cn-shanghai。 |
集群ID:cluster.id | Kubernetes集群ID。 | ||
集群名:cluster.name | Kubernetes集群名称。 | ||
集群类型:cluster.type | Kubernetes集群类型,包括专有版Kubernetes Kubernetes、托管版Kubernetes ManagedKubernetes、Serverless Kubernetes ASK。 | ||
网络类型:cluster.network_mode | Kubernetes集群的网络类型,包括专有网络(VPC)和经典网络(Classic)。 | ||
标签:tag.* | 用户自定义的标签名。 将tag.*中的星号(*)替换为您自定义的标签名。 | ||
Kubernetes容器(Kubernetes事件中心) | Kubernetes集群 | 地域:region | Kubernetes集群所属地域,例如:cn-shanghai。 |
集群ID:cluster.id | Kubernetes集群ID。 | ||
集群名:cluster.name | Kubernetes集群名称。 | ||
集群类型:cluster.type | Kubernetes集群类型,包括专有版Kubernetes、托管版Kubernetes、Serverless Kubernetes。 | ||
网络类型:cluster.network_mode | Kubernetes集群的网络类型,包括专有网络和经典网络。 | ||
标签:tag.* | 用户自定义的标签名。 将tag.*中的星号(*)替换为您自定义的标签名。 | ||
Kubernetes容器( Ingress访问日志) | Kubernetes集群 | 地域:region | Kubernetes集群所属地域,例如:cn-shanghai。 |
集群ID:cluster.id | Kubernetes集群ID。 | ||
集群名:cluster.name | Kubernetes集群名称。 | ||
集群类型:cluster.type | Kubernetes集群类型,包括专有版Kubernetes、托管版Kubernetes、Serverless Kubernetes。 | ||
网络类型:cluster.network_mode | Kubernetes集群的网络类型,包括专有网络(VPC)和经典网络(Classic)。 | ||
标签:tag.* | 用户自定义的标签名。 将tag.*中的星号(*)替换为您自定义的标签名。 | ||
日志内容:log.* | 日志内容。 | ||
IDaaS | IDaaS应用身份服务实例 | 账号:account.id | IDaaS应用身份服务实例所属的阿里云账号ID。 |
实例ID:instance.id | IDaaS应用身份服务实例ID。 | ||
实例名:instance.name | IDaaS应用身份服务实例名。 |
配置采集策略
登录日志服务控制台。
进入日志审计服务页面。
说明自2025年1月21日起,日志审计服务控制台入口已移除。但存量用户(2025年1月21日前开通)仍可见。新增用户如需使用旧版,可访问新版日志审计服务,利用其返回旧版功能。
在日志应用区域的审计与安全页签,单击新版日志审计服务。

在新版日志审计页面右上角,单击返回旧版,您可以继续使用日志审计(旧版)的各项功能。
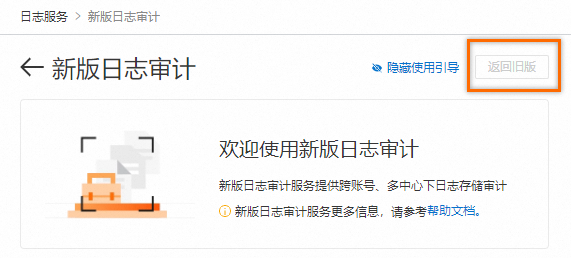
选择,单击修改。
单击目标云产品右侧的采集策略。
配置采集策略。
日志服务支持通过默认采集策略模式或高级编辑模式配置采集策略。默认采集策略模式配置简单,当默认采集策略模式无法满足您的需求时,可开启高级编辑模式,灵活配置复杂的采集策略。
说明您可以根据实际需求,配置多条采集策略。
在高级编辑模式下,您可以手动编辑策略语句,但在手动编辑策略语句后,无法返回到默认采集策略模式。
在高级编辑模式下,清空策略语句并保存,再次打开可恢复到默认采集策略模式。
默认采集策略
在待添加策略区域,配置如下参数,并单击添加策略。
说明如果打开默认采集策略的保留开关,则说明采集策略的最后一行为
accept "*"(默认策略--接受);如果关闭默认采集策略的保留开关,则说明采集策略的最后一行为drop "*"(默认策略--丢弃)。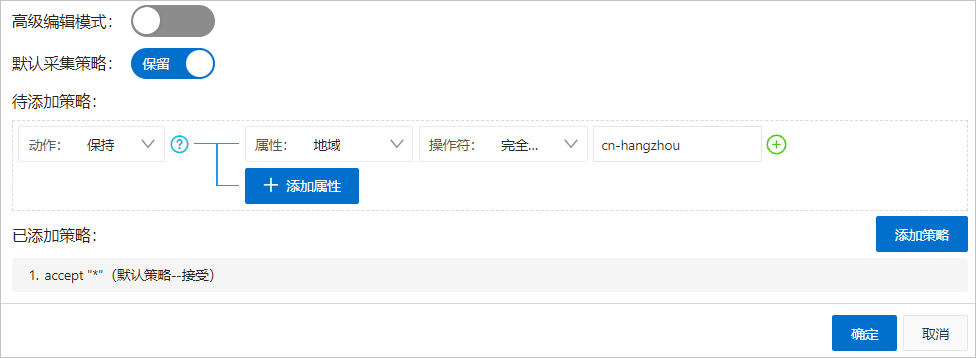
参数
说明
动作
通过您配置的采集策略,执行相应的动作。更多信息,请参见策略语法。
属性
选择采集对象的属性,不同采集对象对应的属性不同。更多信息,请参见产品支持。
操作符
选择操作符,例如选择完全匹配,则对应的操作符为==。更多信息,请参见策略语法。
属性取值
输入属性的值,支持配置多个属性值。
在已添加策略区域,确认策略配置结果。
您也可以修改已添加的采集策略以及调整采集策略的顺序。
单击目标采集策略右侧的编辑,修改已添加的采集策略。
单击目标采集策略右侧的上下箭头,调整采集策略的顺序。
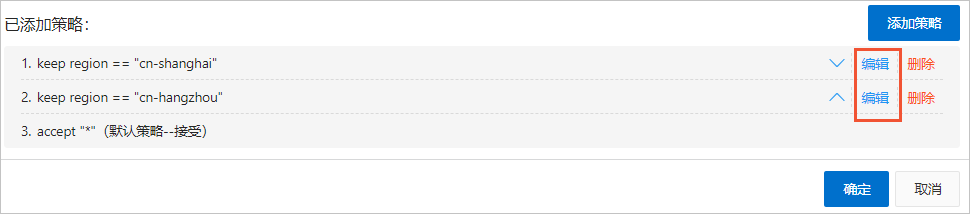
确认无误后,单击确定。
高级编辑模式
开启高级编辑模式。
在规则文本框中,配置采集策略,并单击确定。
详细的语法说明请参见策略语法。
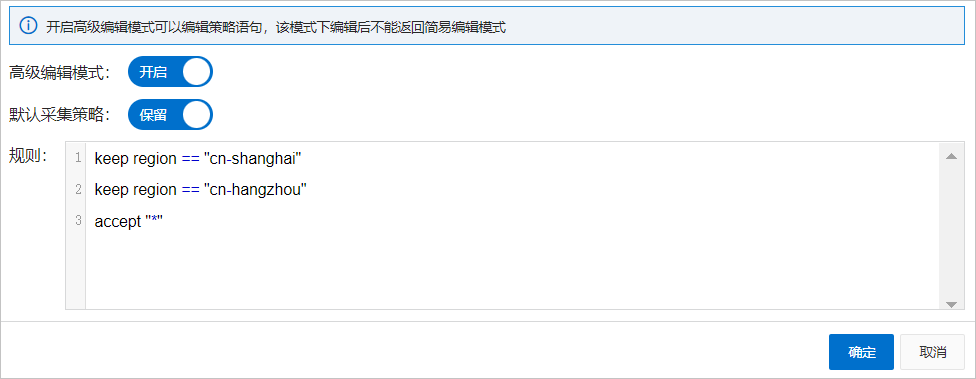
在全局配置页面,单击确定。
策略语法
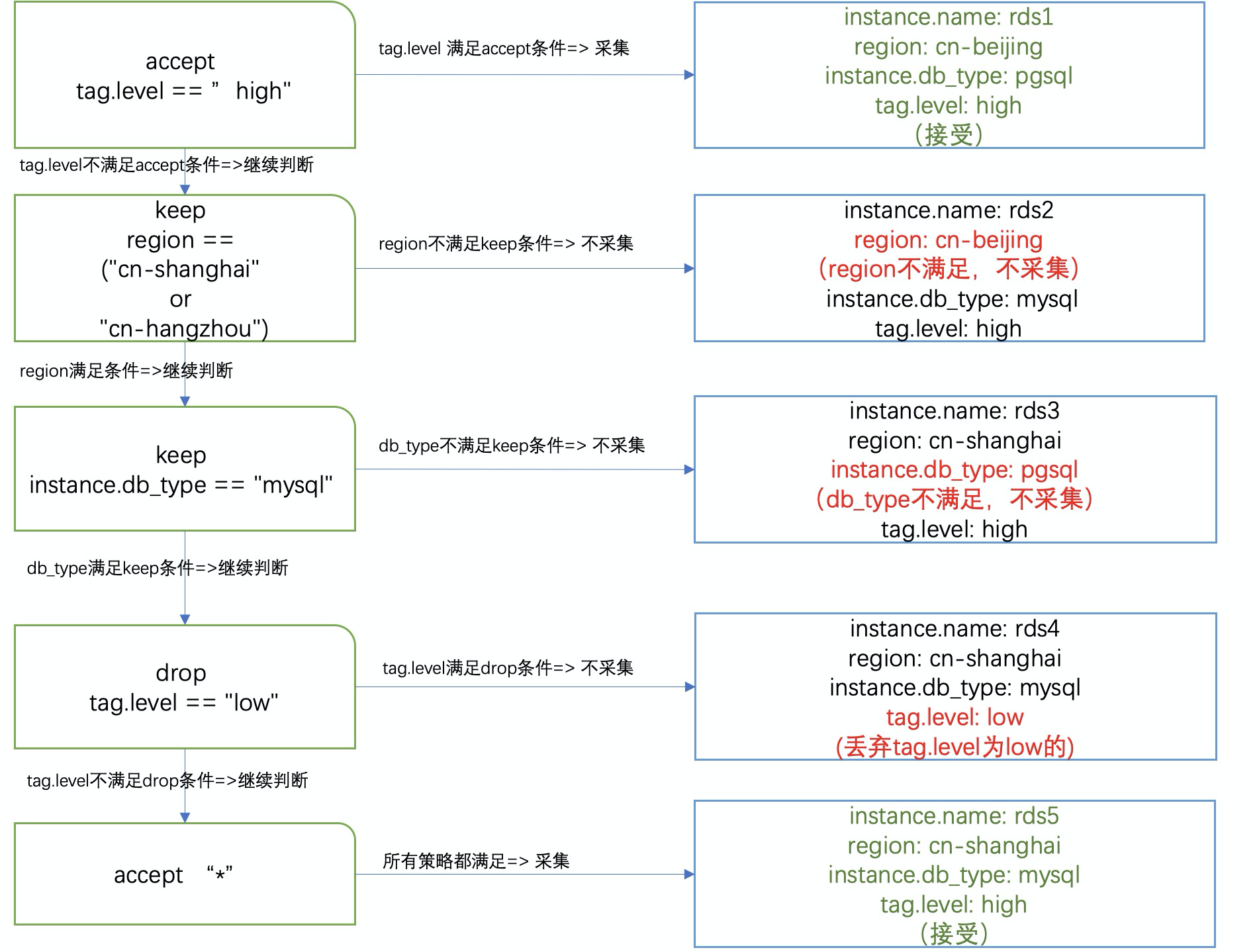
动作
保持(keep):当采集对象满足采集策略时继续执行下一条策略,由后续策略判断是否采集日志。不满足则拒绝采集日志,不再做后续策略判断。
拒绝(drop):当采集对象满足采集策略时拒绝采集日志,不再执行下一条策略。不满足则继续执行下一条策略,由后续策略判断是否采集。
接受(accept):当采集对象满足采集策略时采集日志,不再执行下一条策略。不满足则继续执行下一条策略,由后续策略判断是否采集。
匹配模式
匹配模式
说明
完全匹配
通过字符串的完全匹配,进行采集策略的匹配。
操作符:==
示例:keep instance.db_type == "mysql"表示MySQL类型的RDS实例通过当前判断。
通配符匹配
通过通配符星号(*)和半角问号(?)进行采集策略的匹配。星号(*) 表示0个或多个字符,半角问号(?)表示一个字符。
操作符:==
示例:
keep instance.name == "backend*" 表示实例名以backend开头的实例,通过当前判断。
keep instance.name == "active?"表示实例名以active开头且其后面还有一个任意字符的实例,通过当前判断。
正则表达式匹配
通过正则表达式进行采集策略的匹配。
操作符:~=
示例:keep instance.name ~= "^\d+$"表示纯数字的实例名通过当前判断。
说明默认为部分匹配,如果需要完全匹配,需要在开头和结尾加上^和$。
数值比较
对数值进行比较。
操作符:
直接比较:>、>=、=、<=、<
闭区间比较:: [*, 100],支持用星号(*)表示无边界。
示例:
keep tag.level >= 2表示tag.level大于等于2的实例,通过当前判断。
keep tag.level : [*, 10]表示tag.level小于等于10的实例,通过当前判断。
keep tag.level : [1, 10]表示tag.level位于[1, 10]之间的实例,通过当前判断。
逻辑关系
关键字:
且:使用and、AND、&&等关键词,不区分大小写。
或:使用or、OR等关键词,不区分大小写。
否:使用not,NOT,感叹号(!)等关键词,不区分大小写。
示例:
keep (tag.level > 10) and (region == "cn-shanghai")表示tag.level大于10且位于上海的实例,通过当前判断。
keep (tag.level > 10) or (region == "cn-shanghai")表示tag.level大于10或位于上海的实例,通过当前判断。
keep not region == "cn-shanghai"表示非上海的示例,通过当前判断。
全局匹配
如果策略中没有指定属性名,则表示全局匹配。例如:
keep "abc"表示含有abc字符串的采集项都可以通过当前判断。
accept "*"表示接受所有采集项。
说明全局匹配,必须带双引号(" ")。
仅在高级编辑模式下,支持全局匹配。
字符转义
采集策略中,需要对星号(*)、反斜线(\)等特殊字符进行转义,例如:keep instance.name == "abc\*"表示实例名为abc*的实例通过当前判断。
操作视频
常见案例
采集特定区域的实例日志
例如:只采集中国区域的实例日志,采集策略如下所示。
# only scan cn region keep region == "cn-*" # accept by default accept "*"采集特定标签的实例日志
例如:只采集所有标签打上type值是production(大小写不敏感)的实例日志,采集策略如下所示。
# only scan "production" instances keep tag.type ~= "(?i)^production$" # accept by default accept "*"复杂场景
例如:只采集RDS MySQL实例日志,但是如果标签打上level: high的实例,无论数据库类型是MySQL、SQL Server或PostgreSQL,都采集,采集策略如下所示。
# accept all high level instances accept tag.level == "high" # only scan mysql keep instance.db_type == "mysql" # accept by default accept "*"