
日志服务提供的数据加工功能,通过编排内置的两百多个函数,使用协同消费组对日志数据进行消费,实现对日志数据的加工处理。本文档主要介绍进行数据加工时日志数据的调度原理,以及加工规则引擎的工作原理。
调度原理
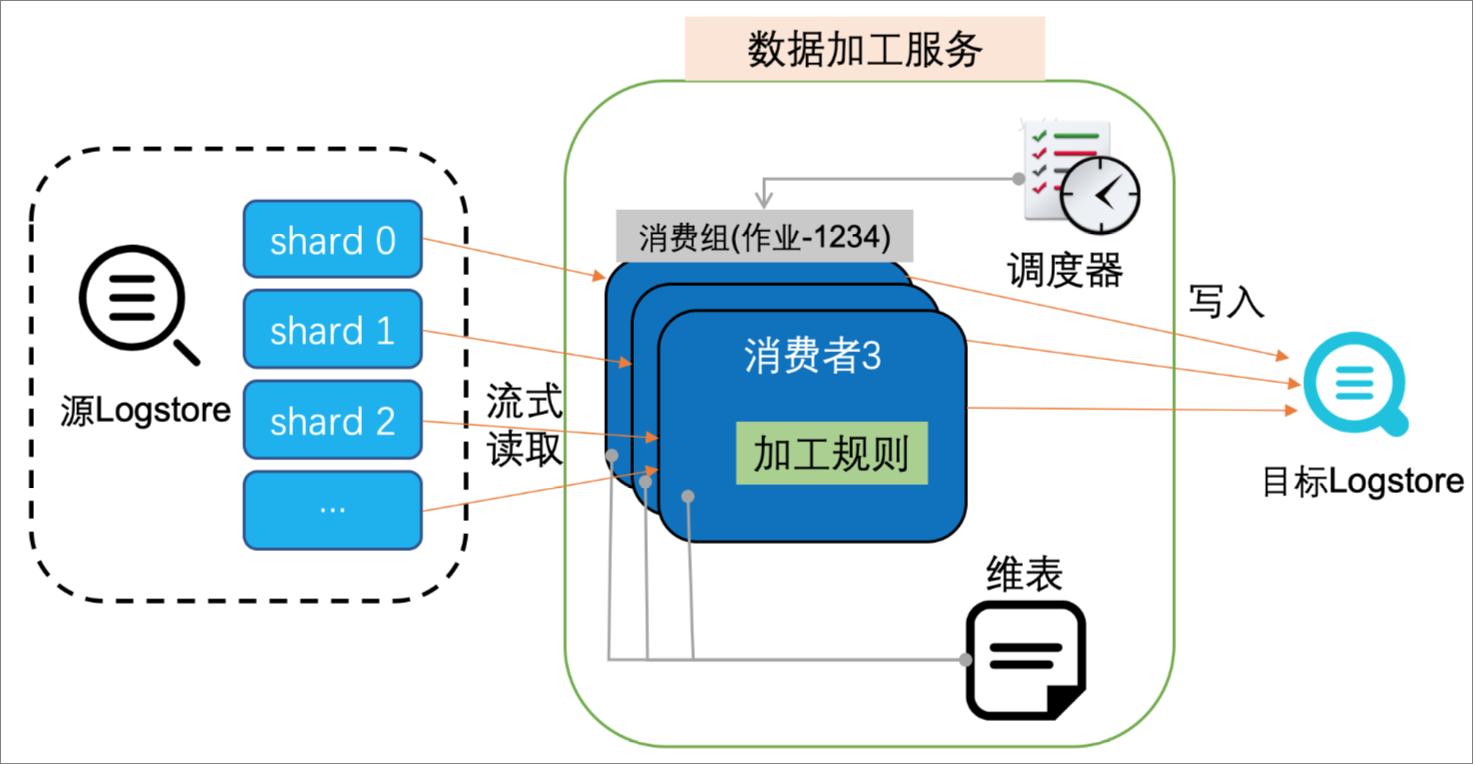
日志服务的数据加工功能使用协同消费组对源日志库的日志数据进行流式消费,将每一条日志通过加工规则处理后再输出。
调度机制
对每一个加工规则,加工服务的调度器会启动一个或多个运行实例,每个运行实例扮演一个消费者的角色去消费1个或者多个源LogStore的Shard,调度器会根据运行实例对内存与CPU的消耗情况决定并行的运行实例数,最多启动与源LogStore的Shard数量相同的运行实例。
运行实例
根据用户配置从分配的Shard中读取源日志数据,经过加工规则处理后再输出到目标LogStore。加工规则支持通过外部资源对日志数据进行富化。运行实例支持通过消费组机制保存Shard的消费位置,确保意外停止后可以从断点处继续消费。
任务停止
当用户没有配置任务的终点时间时,运行实例默认不会退出,则加工任务不会停止。
当用户配置了任务的终点时间时,运行实例处理到配置的终点时间所接收的日志后会自动退出,加工任务停止。
当任务因为某些原因被停止,再次启动时,默认会从上次保存的消费位置继续消费。
规则引擎原理:基本操作
使用SLS DSL提供的内置函数编写加工规则,每个函数可以看做一个加工步骤,规则引擎按步骤顺序执行函数。例如下面4个函数定义了4个主要步骤。
e_set("log_type", "access_log")
e_drop_fields("__action")
e_if(e_search("ret: pass"), e_set("result", "pass"))
e_if(e_search("ret: unknown"), DROP)对应的逻辑图: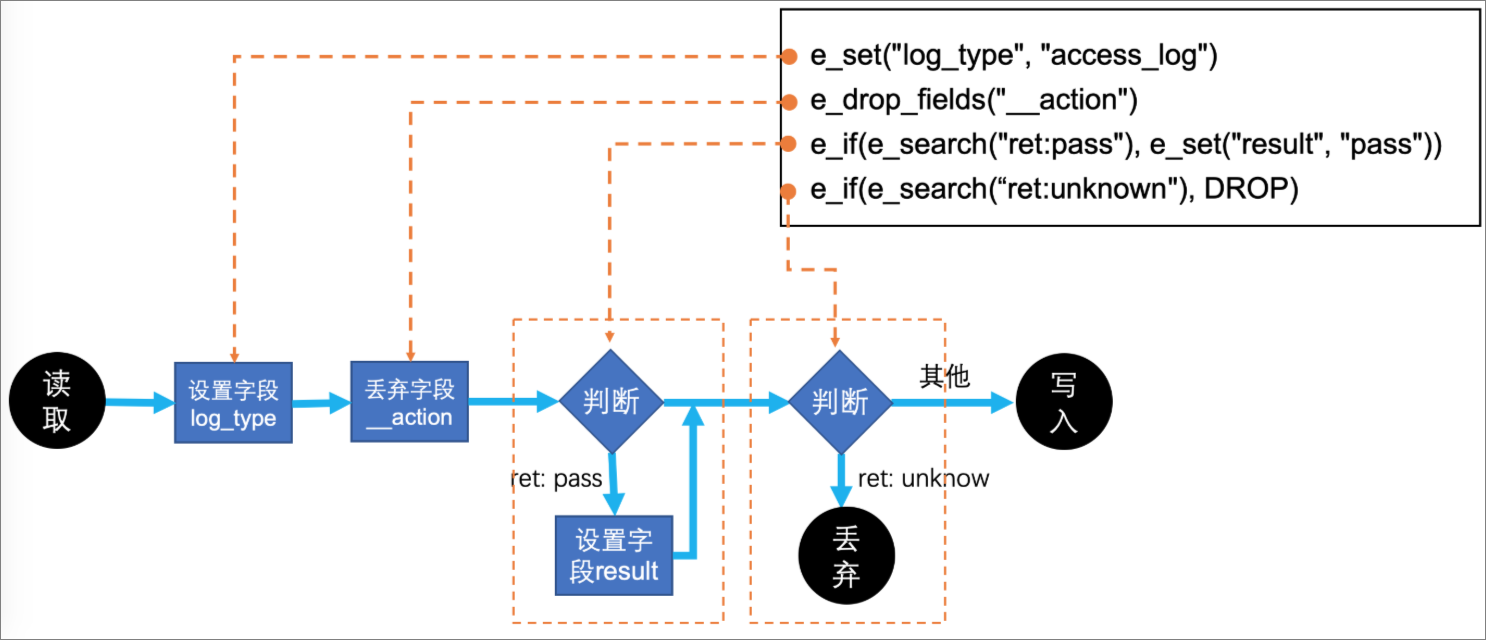
基本逻辑
规则中定义的每个事件函数会顺序执行,每一个函数会对每个事件处理和修改,返回一个处理后的事件。
例如
e_set("log_type", "access_log")会为每个事件添加一个值为access_log的字段log_type,下一个函数接收到的事件就是添加字段log_type后的最新事件。条件判断
步骤可以设置条件,不满足条件的事件会跳过本次操作。
例如
e_if(e_search("ret: pass"), e_set("result", "pass")),会首先检查字段ret是否包含pass,不满足条件不会做任何操作;如果满足条件,则会设置字段result的值为pass。停止处理
步骤返回0个事件,表示删除事件。
例如
e_if(e_search("ret: unknown"), DROP),丢弃字段ret的值是unknown的事件,这条事件被丢弃后,后续的操作将不再进行,自动重新开始下一条事件。
规则引擎原理:输出、复制与分裂
规则引擎也支持复制、输出与分裂事件, 例如下面4个函数定义了4个主要步骤。
e_coutput("archive_Logstore") )
e_split("log_type")
e_if(e_search("log_type: alert"), e_output("alert_Logstore") )
e_set("result", "pass")假设现在处理的一条源日志如下:
log_type: access,alert
content: admin login to database.对应的逻辑如图: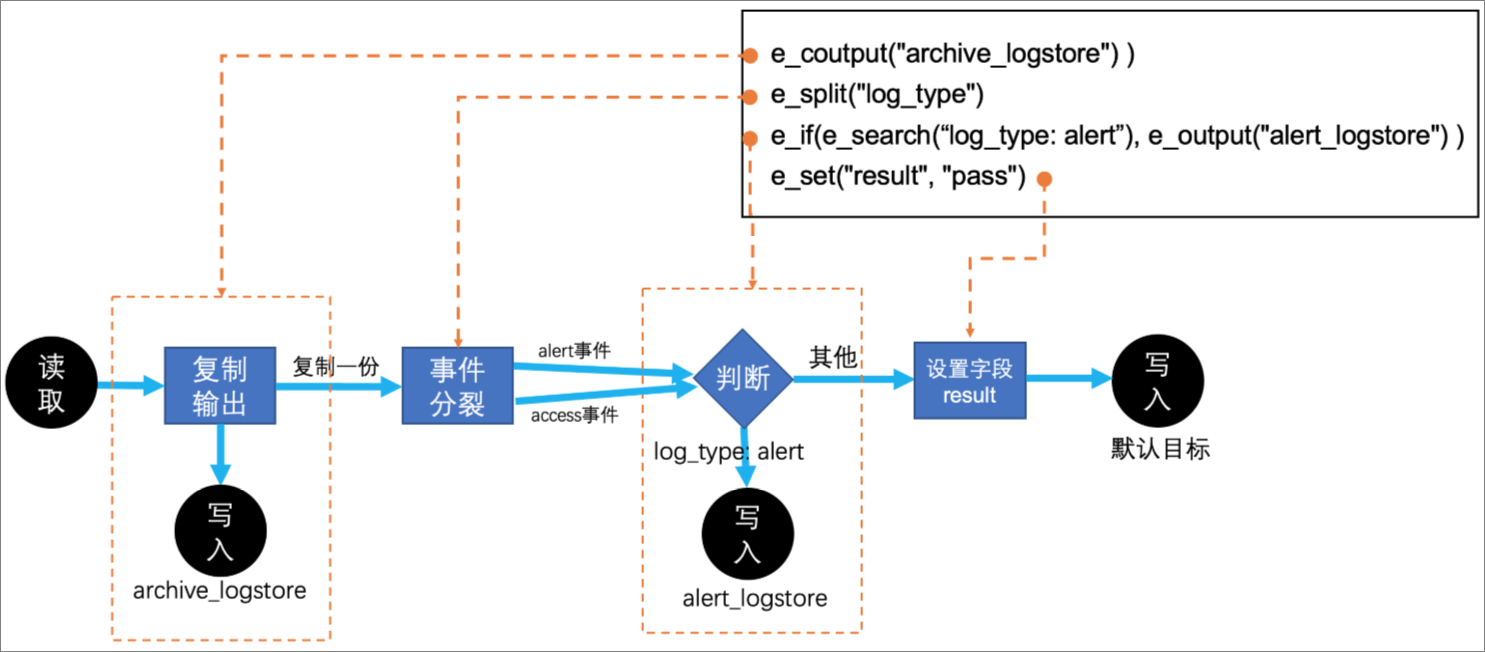
输出事件
默认输出事件可以视为一种特殊的停止处理,例如第3步中对字段
log_type的值为alert的事件调用e_output("alert_Logstore")函数,提前输出事件到指定目标并删除该事件,其后续的操作也不会再进行。复制输出事件
函数
e_coutput会复制当前的事件进行输出,输出后原事件会继续进行后续处理。例如第1步中,会将所有接收到的日志输出到archive_Logstore目标中。分裂并行
在第2步中,假如
log_type字段的值是access和alert,e_split("log_type")表示根据字段log_type的值分裂成两条事件,分裂后的两条事件除字段值分别为access和alert以外,其余完全一样。分裂后的每条事件都会分别继续进行后续的步骤。