
本文为您介绍PySpark开发示例。
如果要访问MaxCompute表,则需要编译datasource包,详细步骤请参见搭建Linux开发环境。
SparkSQL应用示例(Spark1.6)
详细代码
from pyspark import SparkContext, SparkConf
from pyspark.sql import OdpsContext
if __name__ == '__main__':
conf = SparkConf().setAppName("odps_pyspark")
sc = SparkContext(conf=conf)
sql_context = OdpsContext(sc)
sql_context.sql("DROP TABLE IF EXISTS spark_sql_test_table")
sql_context.sql("CREATE TABLE spark_sql_test_table(name STRING, num BIGINT)")
sql_context.sql("INSERT INTO TABLE spark_sql_test_table SELECT 'abc', 100000")
sql_context.sql("SELECT * FROM spark_sql_test_table").show()
sql_context.sql("SELECT COUNT(*) FROM spark_sql_test_table").show()提交运行
./bin/spark-submit \
--jars cupid/odps-spark-datasource_xxx.jar \
example.pySparkSQL应用示例(Spark2.3)
详细代码
from pyspark.sql import SparkSession
if __name__ == '__main__':
spark = SparkSession.builder.appName("spark sql").getOrCreate()
spark.sql("DROP TABLE IF EXISTS spark_sql_test_table")
spark.sql("CREATE TABLE spark_sql_test_table(name STRING, num BIGINT)")
spark.sql("INSERT INTO spark_sql_test_table SELECT 'abc', 100000")
spark.sql("SELECT * FROM spark_sql_test_table").show()
spark.sql("SELECT COUNT(*) FROM spark_sql_test_table").show()提交运行
Cluster模式提交运行
spark-submit --master yarn-cluster \ --jars cupid/odps-spark-datasource_xxx.jar \ example.pyLocal模式运行
cd $SPARK_HOME ./bin/spark-submit --master local[4] \ --driver-class-path cupid/odps-spark-datasource_xxx.jar \ /path/to/odps-spark-examples/spark-examples/src/main/python/spark_sql.py说明Local模式访问表需要依赖Tunnel。
Local模式要用--driver-class-path而非--jars。
Spark SQL应用示例(Spark2.4)
相关代码如下,您需要在本地创建Python项目,自行打包。
spark-test.py
# -*- coding: utf-8 -*- import os from pyspark.sql import SparkSession from mc.service.udf.udfs import udf_squared, udf_numpy def noop(x): import socket import sys host = socket.gethostname() + ' '.join(sys.path) + ' '.join(os.environ) print('host: ' + host) print('PYTHONPATH: ' + os.environ['PYTHONPATH']) print('PWD: ' + os.environ['PWD']) print(os.listdir('.')) return host if __name__ == '__main__': # 本地调试时添加,MaxCompute运行时需要删除,否则会报错 # .master("local[4]") \ spark = SparkSession \ .builder \ .appName("test_pyspark") \ .getOrCreate() sc = spark.sparkContext # 验证系统当前环境变量 rdd = sc.parallelize(range(10), 2) hosts = rdd.map(noop).distinct().collect() print(hosts) # 验证UDF # https://docs.databricks.com/spark/latest/spark-sql/udf-python.html# spark.udf.register("udf_squared", udf_squared) spark.udf.register("udf_numpy", udf_numpy) tableName = "test_pyspark1" df = spark.sql("""select id, udf_squared(age) age1, udf_squared(age) age2, udf_numpy() udf_numpy from %s """ % tableName) print("rdf count, %s\n" % df.count()) df.show()udfs.py
# -*- coding: utf-8 -*- import numpy as np def udf_squared(s): """ spark udf :param s: :return: """ if s is None: return 0 return s * s def udf_numpy(): rand = np.random.randn() return rand if __name__ == "__main__": print(udf_numpy())
提交运行
Spark客户端提交
Spark客户端配置。
配置Spark客户端。
Linux系统配置方式请参考搭建Linux开发环境。
Windows系统配置方式请参考搭建Windows开发环境。
在Spark客户端
conf文件夹下的spark-defaults.conf中添加以下配置项(以公共资源为例):spark.hadoop.odps.cupid.resources = public.python-2.7.13-ucs4.tar.gz spark.pyspark.python = ./public.python-2.7.13-ucs4.tar.gz/python-2.7.13-ucs4/bin/python说明上述配置项的值为Python包所在路径,您可以选择使用自行下载的Python包或者直接采用公共资源。
提交运行。
# mc_pyspark-0.1.0-py3-none-any.zip为通用业务逻辑代码 spark-submit --py-files mc_pyspark-0.1.0-py3-none-any.zip spark-test.py说明如遇到自行下载的第三方依赖包不匹配问题
ImportError: cannot import name _distributor_init,建议直接使用公共资源,详情请参考PySpark Python版本和依赖支持。
DataWorks Spark节点提交。
创建Spark节点:创建方式请参考开发ODPS Spark任务。
提交运行。
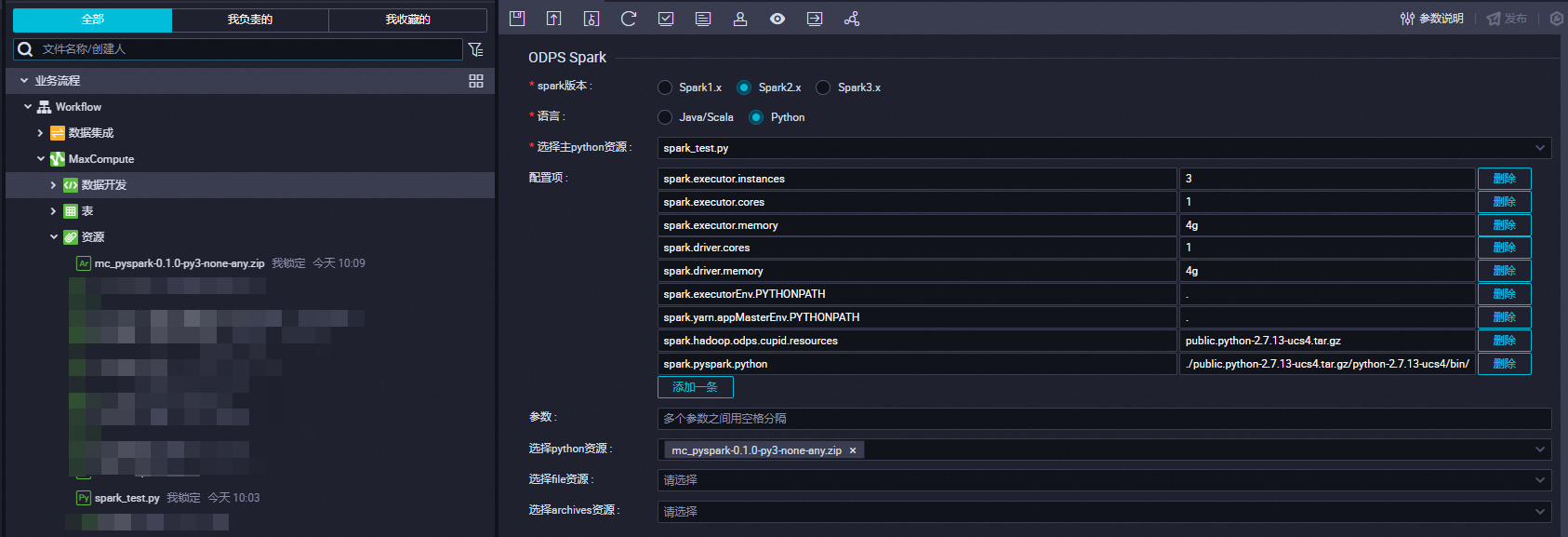
在DataWorks的ODPS Spark节点配置以下参数:
参数名
配置详情
spark版本
Spark2.x
语言
Python
选择主python资源
spark_test.py
配置项
-- 资源申请相关配置 spark.executor.instances=3 spark.executor.cores=1 spark.executor.memory=4g spark.driver.cores=1 spark.driver.memory=4g -- spark.executorEnv.PYTHONPATH=. spark.yarn.appMasterEnv.PYTHONPATH=. -- 指定需要引用的资源 spark.hadoop.odps.cupid.resources = public.python-2.7.13-ucs4.tar.gz spark.pyspark.python = ./public.python-2.7.13-ucs4.tar.gz/python-2.7.13-ucs4/bin/python选择python资源
mc_pyspark-0.1.0-py3-none-any.zip
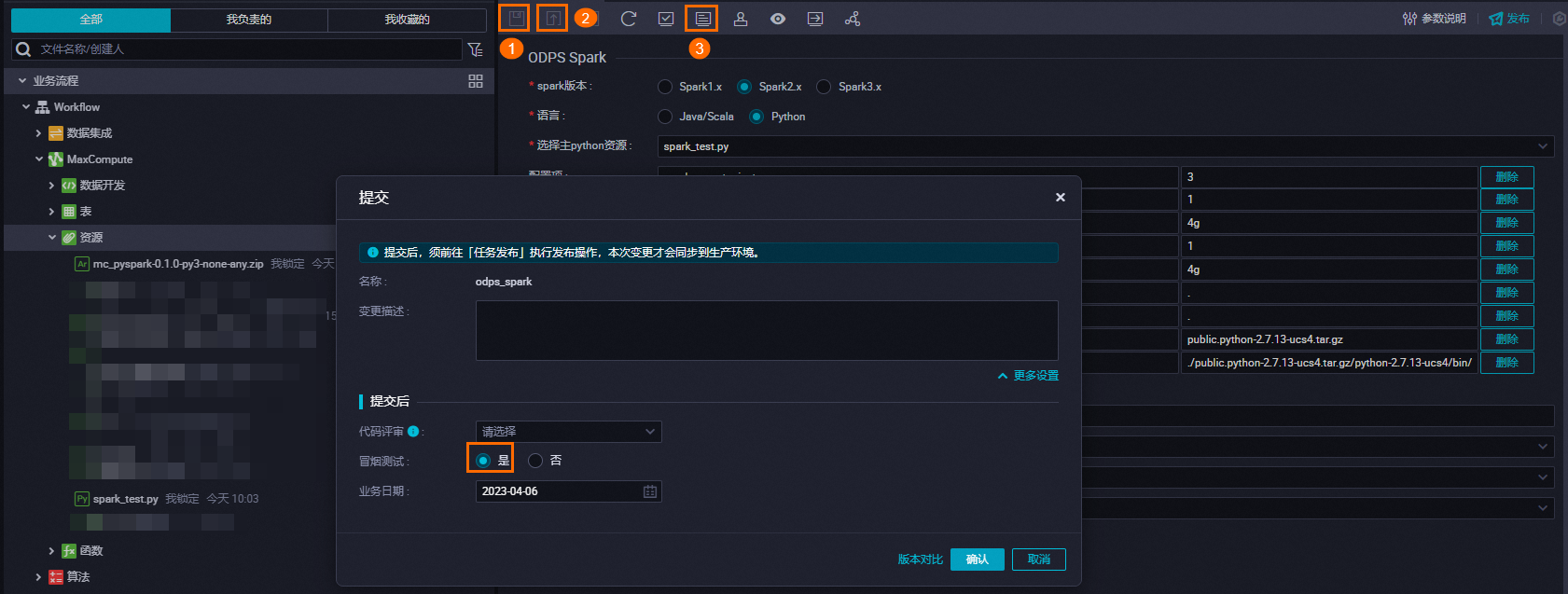
资源上传。
# 修改业务逻辑代码包的后缀名为.zip cp /Users/xxx/PycharmProjects/mc-pyspark/dist/mc_pyspark-0.1.0-py3-none-any.whl /Users/xxx/PycharmProjects/mc-pyspark/dist/mc_pyspark-0.1.0-py3-none-any.zip # 在ODPSCMD添加到MaxCompute资源中 # -f指令会覆盖MaxCompute项目中已存在相同资源,请确认是否覆盖或更换名称。 add archive /Users/xxx/PycharmProjects/mc-pyspark/dist/mc_pyspark-0.1.0-py3-none-any.zip -f;任务配置与执行。
配置
执行
Package依赖
由于MaxCompute集群无法自由安装Python库,PySpark依赖其它Python库、插件、项目时,通常需要在本地打包后通过Spark-submit上传。对于特定依赖,打包环境需与线上环境保持一致。打包方式如下,请根据业务的复杂度进行选择:
不打包直接采用公共资源
默认提供Python 2.7.13环境配置
spark.hadoop.odps.cupid.resources = public.python-2.7.13-ucs4.tar.gz spark.pyspark.python = ./public.python-2.7.13-ucs4.tar.gz/python-2.7.13-ucs4/bin/python第三方库列表如下。
$./bin/pip list Package Version ----------------------------- ----------- absl-py 0.11.0 aenum 2.2.4 asn1crypto 0.23.0 astor 0.8.1 astroid 1.6.1 atomicwrites 1.4.0 attrs 20.3.0 backports.functools-lru-cache 1.6.1 backports.lzma 0.0.14 backports.weakref 1.0.post1 beautifulsoup4 4.9.3 bleach 2.1.2 boto 2.49.0 boto3 1.9.147 botocore 1.12.147 bz2file 0.98 cachetools 3.1.1 category-encoders 2.2.2 certifi 2019.9.11 cffi 1.11.2 click 6.7 click-plugins 1.1.1 cligj 0.7.0 cloudpickle 0.5.3 configparser 4.0.2 contextlib2 0.6.0.post1 cryptography 2.6.1 cssutils 1.0.2 cycler 0.10.0 Cython 0.29.5 dask 0.18.1 DBUtils 1.2 decorator 4.2.1 docutils 0.16 entrypoints 0.2.3 enum34 1.1.10 fake-useragent 0.1.11 Fiona 1.8.17 funcsigs 1.0.2 functools32 3.2.3.post2 future 0.16.0 futures 3.3.0 gast 0.2.2 gensim 3.8.3 geopandas 0.6.3 getpass3 1.2 google-auth 1.23.0 google-auth-oauthlib 0.4.1 google-pasta 0.2.0 grpcio 1.33.2 h5py 2.7.0 happybase 1.1.0 html5lib 1.0.1 idna 2.10 imbalanced-learn 0.4.3 imblearn 0.0 importlib-metadata 2.0.0 ipaddress 1.0.23 ipython-genutils 0.2.0 isort 4.3.4 itchat 1.3.10 itsdangerous 0.24 jedi 0.11.1 jieba 0.42.1 Jinja2 2.10 jmespath 0.10.0 jsonschema 2.6.0 kafka-python 1.4.6 kazoo 2.5.0 Keras-Applications 1.0.8 Keras-Preprocessing 1.1.2 kiwisolver 1.1.0 lazy-object-proxy 1.3.1 libarchive-c 2.8 lightgbm 2.3.1 lml 0.0.2 lxml 4.2.1 MarkupSafe 1.0 matplotlib 2.2.5 mccabe 0.6.1 missingno 0.4.2 mistune 0.8.3 mock 2.0.0 more-itertools 5.0.0 munch 2.5.0 nbconvert 5.3.1 nbformat 4.4.0 networkx 2.1 nose 1.3.7 numpy 1.16.1 oauthlib 3.1.0 opt-einsum 2.3.2 packaging 20.4 pandas 0.24.2 pandocfilters 1.4.2 parso 0.1.1 pathlib2 2.3.5 patsy 0.5.1 pbr 3.1.1 pexpect 4.4.0 phpserialize 1.3 pickleshare 0.7.4 Pillow 6.2.0 pip 20.2.4 pluggy 0.13.1 ply 3.11 prompt-toolkit 2.0.1 protobuf 3.6.1 psutil 5.4.3 psycopg2 2.8.6 ptyprocess 0.5.2 py 1.9.0 py4j 0.10.6 pyasn1 0.4.8 pyasn1-modules 0.2.8 pycosat 0.6.3 pycparser 2.18 pydot 1.4.1 Pygments 2.2.0 pykafka 2.8.0 pylint 1.8.2 pymongo 3.11.0 PyMySQL 0.10.1 pynliner 0.8.0 pyodps 0.9.3.1 pyOpenSSL 17.5.0 pyparsing 2.2.0 pypng 0.0.20 pyproj 2.2.2 PyQRCode 1.2.1 pytest 4.6.11 python-dateutil 2.8.1 pytz 2020.4 PyWavelets 0.5.2 PyYAML 3.12 redis 3.2.1 requests 2.25.0 requests-oauthlib 1.3.0 rope 0.10.7 rsa 4.5 ruamel.ordereddict 0.4.15 ruamel.yaml 0.11.14 s3transfer 0.2.0 scandir 1.10.0 scikit-image 0.14.0 scikit-learn 0.20.3 scipy 1.2.3 seaborn 0.9.1 Send2Trash 1.5.0 setuptools 41.0.0 Shapely 1.7.1 simplegeneric 0.8.1 singledispatch 3.4.0.3 six 1.15.0 sklearn2 0.0.13 smart-open 1.8.1 soupsieve 1.9.6 SQLAlchemy 1.3.20 statsmodels 0.11.0 subprocess32 3.5.4 tabulate 0.8.7 tensorflow 2.0.0 tensorflow-estimator 2.0.1 termcolor 1.1.0 testpath 0.3.1 thriftpy 0.3.9 timeout-decorator 0.4.1 toolz 0.9.0 tqdm 4.32.2 traitlets 4.3.2 urllib3 1.24.3 wcwidth 0.2.5 webencodings 0.5.1 Werkzeug 1.0.1 wheel 0.35.1 wrapt 1.11.1 xgboost 0.82 xlrd 1.2.0 XlsxWriter 1.0.7 zipp 1.2.0默认提供Python 3.7.9环境配置
spark.hadoop.odps.cupid.resources = public.python-3.7.9-ucs4.tar.gz spark.pyspark.python = ./public.python-3.7.9-ucs4.tar.gz/python-3.7.9-ucs4/bin/python3第三方库列表如下。
Package Version ----------------------------- ----------- appnope 0.1.0 asn1crypto 0.23.0 astroid 1.6.1 attrs 20.3.0 autopep8 1.3.4 backcall 0.2.0 backports.functools-lru-cache 1.5 backports.weakref 1.0rc1 beautifulsoup4 4.6.0 bidict 0.17.3 bleach 2.1.2 boto 2.49.0 boto3 1.9.147 botocore 1.12.147 bs4 0.0.1 bz2file 0.98 cached-property 1.5.2 cachetools 3.1.1 category-encoders 2.2.2 certifi 2019.11.28 cffi 1.11.2 click 6.7 click-plugins 1.1.1 cligj 0.7.0 cloudpickle 0.5.3 cryptography 2.6.1 cssutils 1.0.2 cycler 0.10.0 Cython 0.29.21 dask 0.18.1 DBUtils 1.2 decorator 4.2.1 docutils 0.16 entrypoints 0.2.3 fake-useragent 0.1.11 Fiona 1.8.17 future 0.16.0 gensim 3.8.3 geopandas 0.8.0 getpass3 1.2 h5py 3.1.0 happybase 1.1.0 html5lib 1.0.1 idna 2.10 imbalanced-learn 0.4.3 imblearn 0.0 importlib-metadata 2.0.0 iniconfig 1.1.1 ipykernel 5.3.4 ipython 7.19.0 ipython-genutils 0.2.0 isort 4.3.4 itchat 1.3.10 itsdangerous 0.24 jedi 0.11.1 jieba 0.42.1 Jinja2 2.10 jmespath 0.10.0 jsonschema 2.6.0 jupyter-client 6.1.7 jupyter-core 4.6.3 kafka-python 1.4.6 kazoo 2.5.0 kiwisolver 1.3.1 lazy-object-proxy 1.3.1 libarchive-c 2.8 lightgbm 2.3.1 lml 0.0.2 lxml 4.2.1 Mako 1.0.10 MarkupSafe 1.0 matplotlib 3.3.3 mccabe 0.6.1 missingno 0.4.2 mistune 0.8.3 mock 2.0.0 munch 2.5.0 nbconvert 5.3.1 nbformat 4.4.0 networkx 2.1 nose 1.3.7 numpy 1.19.4 packaging 20.4 pandas 1.1.4 pandocfilters 1.4.2 parso 0.1.1 patsy 0.5.1 pbr 3.1.1 pexpect 4.4.0 phpserialize 1.3 pickleshare 0.7.4 Pillow 6.2.0 pip 20.2.4 plotly 4.12.0 pluggy 0.13.1 ply 3.11 prompt-toolkit 2.0.1 protobuf 3.6.1 psutil 5.4.3 psycopg2 2.8.6 ptyprocess 0.5.2 py 1.9.0 py4j 0.10.6 pycodestyle 2.3.1 pycosat 0.6.3 pycparser 2.18 pydot 1.4.1 Pygments 2.2.0 pykafka 2.8.0 pylint 1.8.2 pymongo 3.11.0 PyMySQL 0.10.1 pynliner 0.8.0 pyodps 0.9.3.1 pyOpenSSL 17.5.0 pyparsing 2.2.0 pypng 0.0.20 pyproj 3.0.0.post1 PyQRCode 1.2.1 pytest 6.1.2 python-dateutil 2.8.1 pytz 2020.4 PyWavelets 0.5.2 PyYAML 3.12 pyzmq 17.0.0 qtconsole 4.3.1 redis 3.2.1 requests 2.25.0 retrying 1.3.3 rope 0.10.7 ruamel.yaml 0.16.12 ruamel.yaml.clib 0.2.2 s3transfer 0.2.0 scikit-image 0.14.0 scikit-learn 0.20.3 scipy 1.5.4 seaborn 0.11.0 Send2Trash 1.5.0 setuptools 41.0.0 Shapely 1.7.1 simplegeneric 0.8.1 six 1.15.0 sklearn2 0.0.13 smart-open 1.8.1 SQLAlchemy 1.3.20 statsmodels 0.12.1 tabulate 0.8.7 testpath 0.3.1 thriftpy 0.3.9 timeout-decorator 0.4.1 toml 0.10.2 toolz 0.9.0 tornado 6.1 tqdm 4.32.2 traitlets 4.3.2 urllib3 1.24.3 wcwidth 0.2.5 webencodings 0.5.1 wheel 0.35.1 wrapt 1.11.1 xgboost 1.2.1 xlrd 1.2.0 XlsxWriter 1.0.7 zipp 3.4.0
上传单个WHEEL包
如果依赖较为简单,则可以只上传单个WHEEL包,通常需要选用manylinux版本。使用方式如下:
将WHEEL包重命名为ZIP包,例如将pymysql的WHEEL包重命名为pymysql.zip。
将重命名后的ZIP包上传,文件类型为ARCHIVE。
在DataWorks Spark节点引用,文件类型为ARCHIVE。
在代码中修改环境变量后即可导入。
sys.path.append('pymysql') import pymysql
利用脚本一键打包
若需要的额外依赖较多,上传单个WHEEL包会导致重复操作量倍增。您可以下载脚本,只需提供一个编辑好的requirements文件,就能够直接生成完整的Python环境用于PySpark使用,具体如下。
使用
$ chmod +x generate_env_pyspark.sh $ generate_env_pyspark.sh -h Usage: generate_env_pyspark.sh [-p] [-r] [-t] [-c] [-h] Description: -p ARG, the version of python, currently supports python 2.7, 3.5, 3.6 and 3.7 versions. -r ARG, the local path of your python requirements. -t ARG, the output directory of the gz compressed package. -c, clean mode, we will only package python according to your requirements, without other pre-provided dependencies. -h, display help of this script.示例
# 带有预装依赖的打包方式 $ generate_env_pyspark.sh -p 3.7 -r your_path_to_requirements -t your_output_directory # 不带预装依赖的打包方式(clean mode) generate_env_pyspark.sh -p 3.7 -r your_path_to_requirements -t your_output_directory -c说明
脚本适用于Mac或Linux环境,需要预先安装Docker,安装指导请参见Docker帮助文档。
目前仅支持Python 2.7、3.5、3.6和3.7版本,如果对Python版本不敏感,推荐使用Python 3.7。
-c选项表示是否开启clean mode。clean mode无法使用预装依赖,但输出的Python包更小。各版本的依赖请参见Python 2.7预装依赖、Python 3.5预装依赖、Python 3.6预装依赖、Python 3.7预装依赖。当前MaxCompute对上传资源的大小有500 MB的限制,因此如果大部分预装依赖用不到,推荐使用
-c选项打包。
Spark中使用
generate_env_pyspark.sh脚本的输出为在指定目录下(
-t选项)生成指定Python版本(-p选项)的GZ包。以Python3.7为例,将生成py37.tar.gz,后续再将此包上传为ARCHIVE资源。您可以通过MaxCompute客户端上传,也可以使用odps-sdk上传。各种资源操作,请参见资源操作。以MaxCompute客户端为例,使用方式如下。在MaxCompute客户端中执行如下命令添加资源。
# -f指令会覆盖MaxCompute项目中已存在相同资源,请确认是否覆盖或更换名称。 add archive /your/path/to/py37.tar.gz -f;在Spark配置中增加如下两个参数。
spark.hadoop.odps.cupid.resources = your_project.py37.tar.gz spark.pyspark.python = your_project.py37.tar.gz/bin/python若上述两个参数不生效,还需在Spark作业中增加如下两项配置。例如使用Zeppelin调试Pyspark时,notebook中的Python环境配置。
spark.yarn.appMasterEnv.PYTHONPATH = ./your_project.py37.tar.gz/bin/python spark.executorEnv.PYTHONPATH = ./your_project.py37.tar.gz/bin/python
利用Docker容器打包Python环境
该方式适用于如下场景:
需要引入的依赖包含so文件时,无法通过上述ZIP文件的方式使用,无法进行
pip install安装。对除2.7、3.5、3.6、3.7以外的Python版本有特殊需求。
针对以上特殊情况,同时保证打包环境与线上环境一致(Mac打出来的Python环境与线上环境存在兼容性问题)。以Python3.7为例,基于Docker的打包步骤如下。
在安装Docker环境的宿主机新建一个Dockerfile文件。
Python 3示例参考如下。
FROM centos:7.6.1810 RUN set -ex \ # 预安装所需组件 && yum install -y wget tar libffi-devel zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make initscripts zip\ && wget https://www.python.org/ftp/python/3.7.0/Python-3.7.0.tgz \ && tar -zxvf Python-3.7.0.tgz \ && cd Python-3.7.0 \ && ./configure prefix=/usr/local/python3 \ && make \ && make install \ && make clean \ && rm -rf /Python-3.7.0* \ && yum install -y epel-release \ && yum install -y python-pip # 设置默认为python3 RUN set -ex \ # 备份旧版本python && mv /usr/bin/python /usr/bin/python27 \ && mv /usr/bin/pip /usr/bin/pip-python27 \ # 配置默认为python3 && ln -s /usr/local/python3/bin/python3.7 /usr/bin/python \ && ln -s /usr/local/python3/bin/pip3 /usr/bin/pip # 修复因修改python版本导致yum失效问题 RUN set -ex \ && sed -i "s#/usr/bin/python#/usr/bin/python27#" /usr/bin/yum \ && sed -i "s#/usr/bin/python#/usr/bin/python27#" /usr/libexec/urlgrabber-ext-down \ && yum install -y deltarpm # 更新pip版本 RUN pip install --upgrade pipPython 2示例参考如下。
FROM centos:7.6.1810 RUN set -ex \ # 预安装所需组件 && yum install -y wget tar libffi-devel zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make initscripts zip\ && wget https://www.python.org/ftp/python/2.7.18/Python-2.7.18.tgz \ && tar -zxvf Python-2.7.18.tgz \ && cd Python-2.7.18 \ && ./configure prefix=/usr/local/python2 \ && make \ && make install \ && make clean \ && rm -rf /Python-2.7.18* # 设置默认为python RUN set -ex \ && mv /usr/bin/python /usr/bin/python27 \ && ln -s /usr/local/python2/bin/python /usr/bin/python RUN set -ex \ && wget https://bootstrap.pypa.io/get-pip.py \ && python get-pip.py RUN set -ex \ && rm -rf /usr/bin/pip \ && ln -s /usr/local/python2/bin/pip /usr/bin/pip # 修复因修改python版本导致yum失效问题 RUN set -ex \ && sed -i "s#/usr/bin/python#/usr/bin/python27#" /usr/bin/yum \ && sed -i "s#/usr/bin/python#/usr/bin/python27#" /usr/libexec/urlgrabber-ext-down \ && yum install -y deltarpm # 更新pip版本 RUN pip install --upgrade pip
构建镜像并运行容器。
# 在Dockerfile文件的目录下运行如下命令。 docker build -t python-centos:3.7 docker run -itd --name python3.7 python-centos:3.7进入容器安装所需的Python依赖库。
docker attach python3.7 pip install [所需依赖库]打包Python环境。
cd /usr/local/ zip -r python3.7.zip python3/拷贝容器中的Python环境到宿主机。
# 退出容器 ctrl+P+Q # 在宿主机运行命令。 docker cp python3.7:/usr/local/python3.7.zip上传Python3.7.zip包为MaxCompute资源。DataWorks最大只能上传50 MB的包,如果大于50 MB可以通过MaxCompute客户端上传,文件类型为ARCHIVE。上传资源操作,请参见添加资源。
# -f指令会覆盖MaxCompute项目中已存在相同资源,请确认是否覆盖或更换名称。 add archive /path/to/python3.7.zip -f;提交作业时只需要在spark-default.conf或DataWorks配置项中添加以下配置即可。
spark.hadoop.odps.cupid.resources=[project名称].python3.7.zip spark.pyspark.python=./[project名].python3.7.zip/python3/bin/python3.7说明通过Docker容器打包,如果遇到so包找不到的情况,则需要手动将so包放到Python环境中。一般so包在容器中都能找到,并在Spark作业中添加以下环境变量。
spark.executorEnv.LD_LIBRARY_PATH=$LD_LIBRARY_PATH:./[project名].python3.7.zip/python3/[创建的so包目录] spark.yarn.appMasterEnv.LD_LIBRARY_PATH=$LD_LIBRARY_PATH:./[project名].python3.7.zip/python3/[创建的so包目录]
引用用户自定义的Python包
通常情况下,用户需要使用自定义的Python文件,可以打包提交,这样避免了上传多个“.py”文件,步骤如下:
将用户代码打包为ZIP包,需要在目录下自定义一个空白的__init__.py。
将用户代码ZIP包以MaxCompute资源形式上传,并重命名,该资源在工作目录中将会被解压。
说明MaxCompute支持上传的资源类型请参考资源。
配置参数
spark.executorEnv.PYTHONPATH=。完成上述步骤,主Python文件就可以导入该目录下的Python文件。