产品整体介绍
云原生数据仓库AnalyticDB PostgreSQL版提供PB级数据实时交互式分析、ETL/ELT、BI报表展示功能,支持数据高吞吐实时写入与批量导入,提供ACID保证和标准事务隔离级别,采用MPP全并行架构,是一款具有高性价比的云原生数仓产品,提供基于阿里云生态的公共云和混合云服务。
概述
AnalyticDB PostgreSQL版支持JDBC/ODBC连接,支持SQL 2003语法标准,兼容PostgreSQL,Greenplum,和部分Oracle语法,同时提供PL/pgSQL存储过程。另外在SQL基础上,支持Apache MADLib机器学习,PostGIS地理位置分析,以及JSON/JSONB半结构化数据,图片音频等非结构化数据与结构化数据融合分析功能。
在部署形态层面,AnalyticDB PostgreSQL版提供阿里云公共云服务,按量付费,支持垂直升降配和水平扩容,另外支持存储容量独立在线扩容;同时提供阿里云企业版,和敏捷版DBStack混合云部署形态,同时支持X86和ARM平台。
在第三方认证层面,AnalyticDB PostgreSQL版通过了“国际数据库TPC官方TPC-H 30TB认证”(性价比综合排名第一),信通院“分布式事务型数据库基础能力评测”(TPC-C)和“分布式分析型数据库大规模性能认证”(640节点 TPC-DS 100TB)。
技术架构
以下为AnalyticDB PostgreSQL版的架构图,主要包含Master Node和Compute Node两大组件,中间通过Interconnect进行互联通信和数据交换传输。
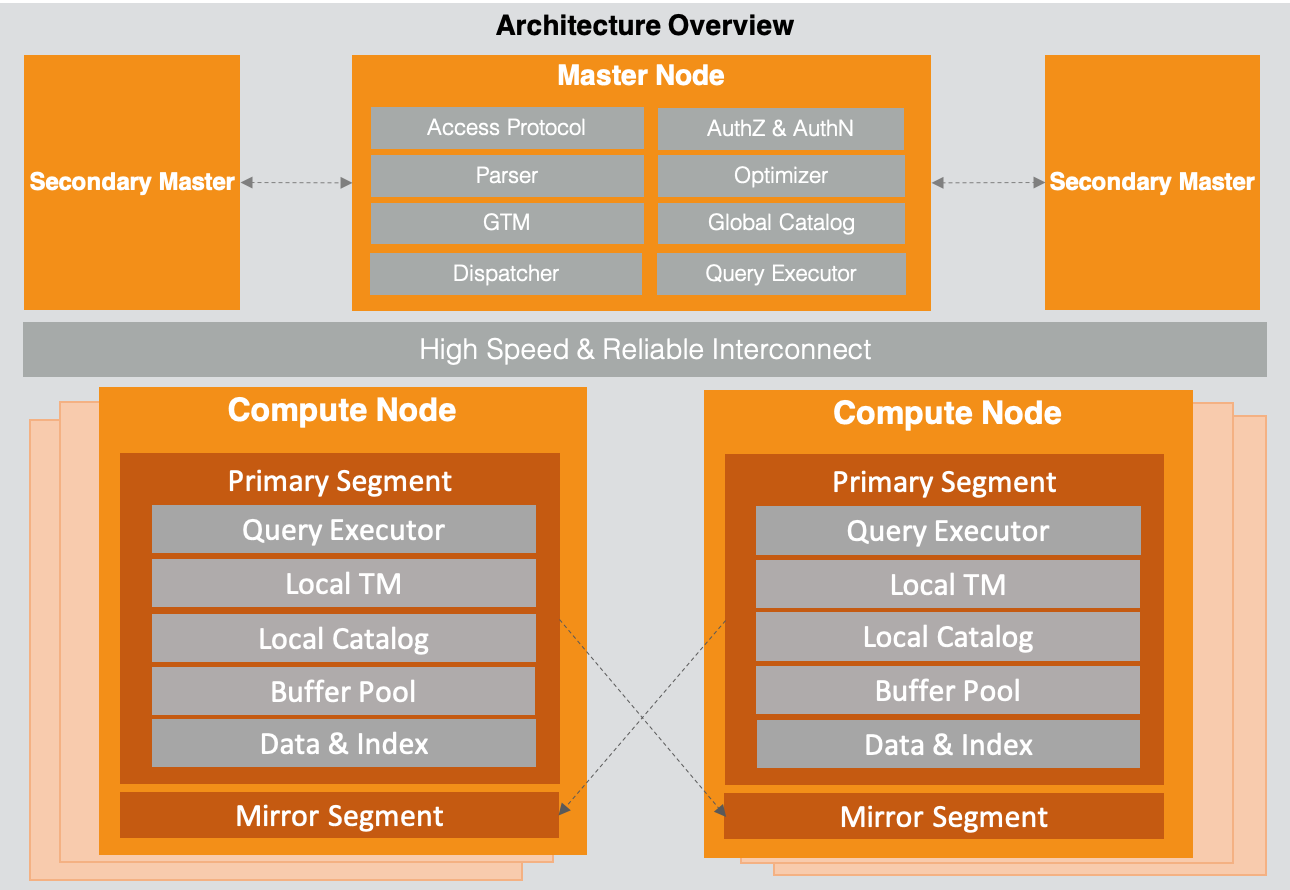
Master Node和Compute Node提供多副本保障服务高可用和数据高可靠,同时均支持通过Scale Out水平扩展来提高集群整体写入查询并发和吞吐。
模块组件
Master Node
Master Node主要负责客户端连接协议层接入(Access Protocol),认证和鉴权(Authorization & Authentication),SQL解析(Parser),重写(Rewrite),优化(Optimizer),和执行分发协调(Dispatcher)。
另外,Master Node还包含全局事务管理器(Global Transaction Manager),负责全局事务ID、快照生成和分布式事务管理;全局元数据目录(Global Catalog)则记录了用户,库,表,视图,索引,分布分区等数据库对象的元数据信息。
Compute Node
Compute Node包含了一组Segment,部署形态上可以是物理机,VM或者容器。
Segment
Segment是负责具体的SQL执行和数据存储节点。其中本地元数据(Local Catalog,与Master Node Global Catalog保持同步)起到加速执行的功能(Segment无需每次访问Master Node获得元数据信息);本地事务管理器(Local Transaction Manager)提供本地事务能力;缓存管理器(Buffer Pool)则提供了数据的读写缓存,用于提升读写性能。
执行引擎(Query Executor)通过向量化(Vectorization)和即时编译(JIT)等技术,相比传统逐行计算的火山模型获得数倍性能提升。
数据和索引(Data & Index)支持行存表,列存表,和外表以及相应索引:
行存表:数据按行存放,支持主键,B+树索引,Bitmap索引,GIN索引等,适合数据实时写入更新删除,点查,范围查,通过MVCC提供事务能力。
列存表:数据按列存放,高压缩比,适合追加写(少量更新删除)场景。通过B+树索引支持高效点查,同时在block级别提供min&max轻量级索引,数据可按多列进行多维排序,支持任意排序列的组合过滤,支持高效分析场景。
外表:元数据存放在本地系统表,数据存放在OSS,支持的数据格式包括ORC,Parquet,CSV,JSON,支持表分区,其中ORC和Parquet支持列过滤和谓词下推,提升分析性能。除OSS外,同时也支持Hadoop(HDFS, Hive)外表。

组件交互
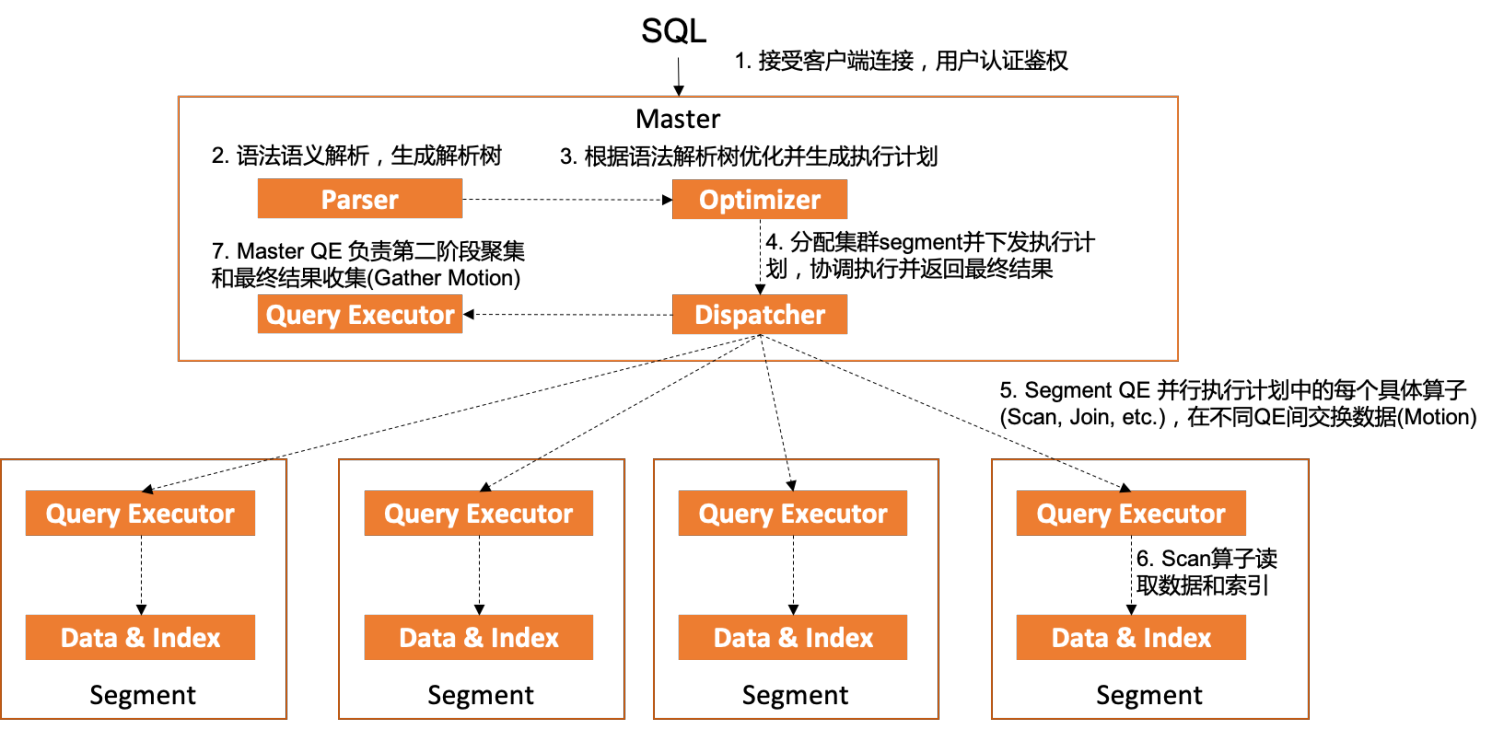
下图展示了客户端从建立连接到执行一条完整SQL整个过程中上述主要模块组件的交互和执行流程。
数据模型
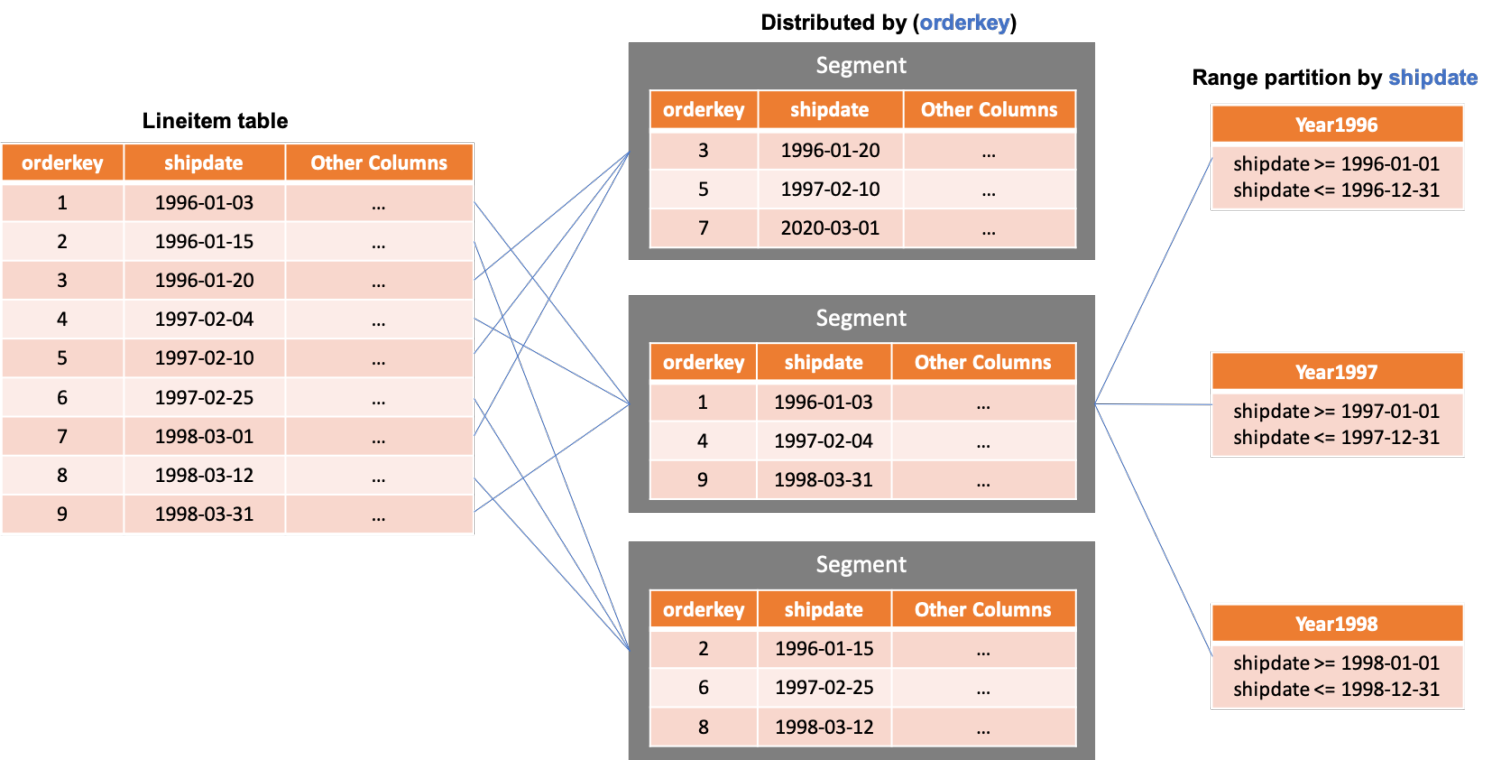
将表数据均匀的分布到各个节点中,是发挥集群整体IO性能,提升存储容量,优化计算与网络传输效率的关键。除了默认的哈希分布策略,AnalyticDB PostgreSQL版还支持复制分布和随机分布。复制分布是指在每个存储节点上都存放该表的全量数据,通常用于经常被关联查询的小表,在执行相应查询时无需数据广播或重分布环节,提升查询性能。另外也支持随机分布策略,主要场景是当前表字段中无合适字段作为hash分布列(比如会引起各个节点数据倾斜),同时该表也不小(不适合复制策略),随机分布可以让该表数据被均匀摆放到各节点。
在将表数据分布到各个存储节点后,在单个节点上根据业务场景可对表数据进行分区,在执行具体查询时进行分区裁剪,缩小查找和数据处理范围。AnalyticDB PostgreSQL版支持范围和列表分区类型,同时支持多级分区。下图展示了一张用户表显示通过ID列hash分布到3个节点,然后在每个节点上按date列进行范围分区,然后再按city列进行列表分区。图中最右边的每个分区都对应了一份数据存储和索引。这些分区表可以是行存表,也可以是列存表,或者外表。比如业务上完全可以对最近需要写入的分区(Mar)使用行存表,过去已经归档的分区(Feb)使用列存表,出于降低成本考虑,也可以对较少查询的分区(Jan)使用OSS外表。
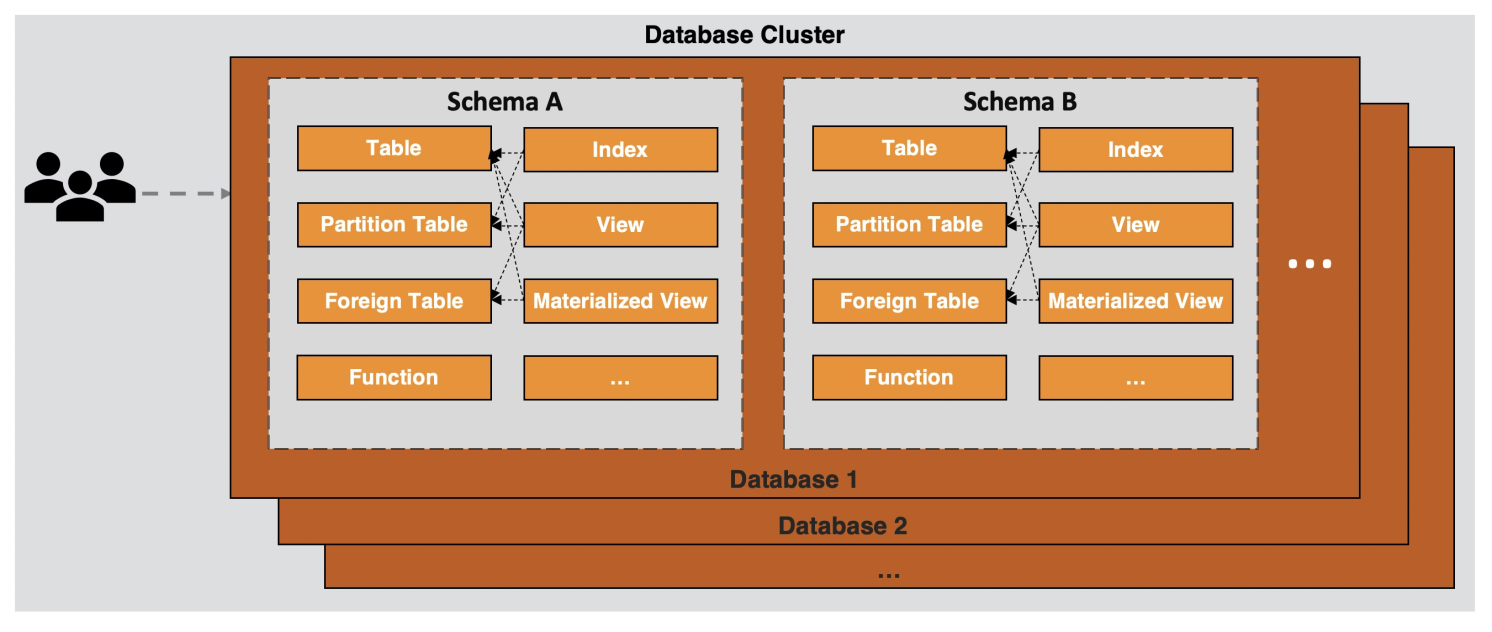
数据库对象
AnalyticDB PostgreSQL版不仅仅是关系型也是对象-关系型,数据库的对象通常包括:表、视图、函数、序列、索引、分区子表、外部表等,而对象-关系型则进一步支持用户自定义对象和它的属性,包括数据类型、函数、操作符,域和索引,甚至复杂的数据结构也可以被创建,存储和检索。这些对象将按照逻辑划分成不同的集合即组成模式(schema),每当新数据库创建后,都会默认为数据库创建模式public,这也是该数据库的默认模式,并且允许每个用户(角色)进行访问,所有为此数据库创建的对象一般都将默认在这个模式中。
数据库是数据库对象的物理集合,而模式则是数据库内部用于组织管理数据库对象的逻辑集合,模式之下则是各种应用程序会接触到的对象,比如表、索引、数据类型、函数、操作符等。使用模式把数据库对象组织成逻辑组,让它们便于管理,允许多个用户(角色)使用同一个数据库不会互相干扰。
用户(角色)是数据库(集群)全局范围内的权限控制系统,用于各种集群范围内所有的对象权限管理。用户不特定于某个单独的数据库,如果需要登录数据库管理系统则必须连接到一个数据库上,用户可以拥有各种数据库对象。
缺省情况下,用户看不到模式中不属于他们所有的对象,需要对象所有者赋予相应权限。如果已经被赋予适当的权限,用户也可以在别的用户模式里创建对象。请注意,缺省每个用户都在public模式上有创建对象的权限,比如新建一个表并读写数据。
在AnalyticDB PostgreSQL版数据库中,所有对象作为系统元数据将同时被保存在Master服务器和Segment服务器上。