
1. 千寻大模型搜索算法服务搭建
千寻大模型搜索服务是基于大规模分布式搜索引擎搭建的,面向企业提供的一站式智能搜索PaaS服务,为企业开发人员提供基础结构、API 和搜索工具。服务集成全自研多语言query分析能力(分词、NER、纠错、改写、分类等),多模型结构的预训练向量表示能力(encoder-only、decoder-only),混合召回和多因子排序能力(文本匹配、深度语义匹配)等,相对比纯向量检索,提升为行业领先搜索效果。
更多细节参考:企业智能搜索_自然语言处理(NLP)-阿里云帮助中心
由于目前服务尚未完全对外开放,需要采用定向加白配置方式试用产品,未来会正式对外开放。因此当前搭建一个千寻大模型搜索服务需要以下五个步骤:
-
申请试用
-
购买资源
-
准备数据
-
配置服务
-
测试服务
1.1. 申请试用流程
-
step1,开通nlp服务
-
step2,进入nlp管控台
-
step3,登录阿里云账号
-
step4,点击进入千寻大模型搜索平台
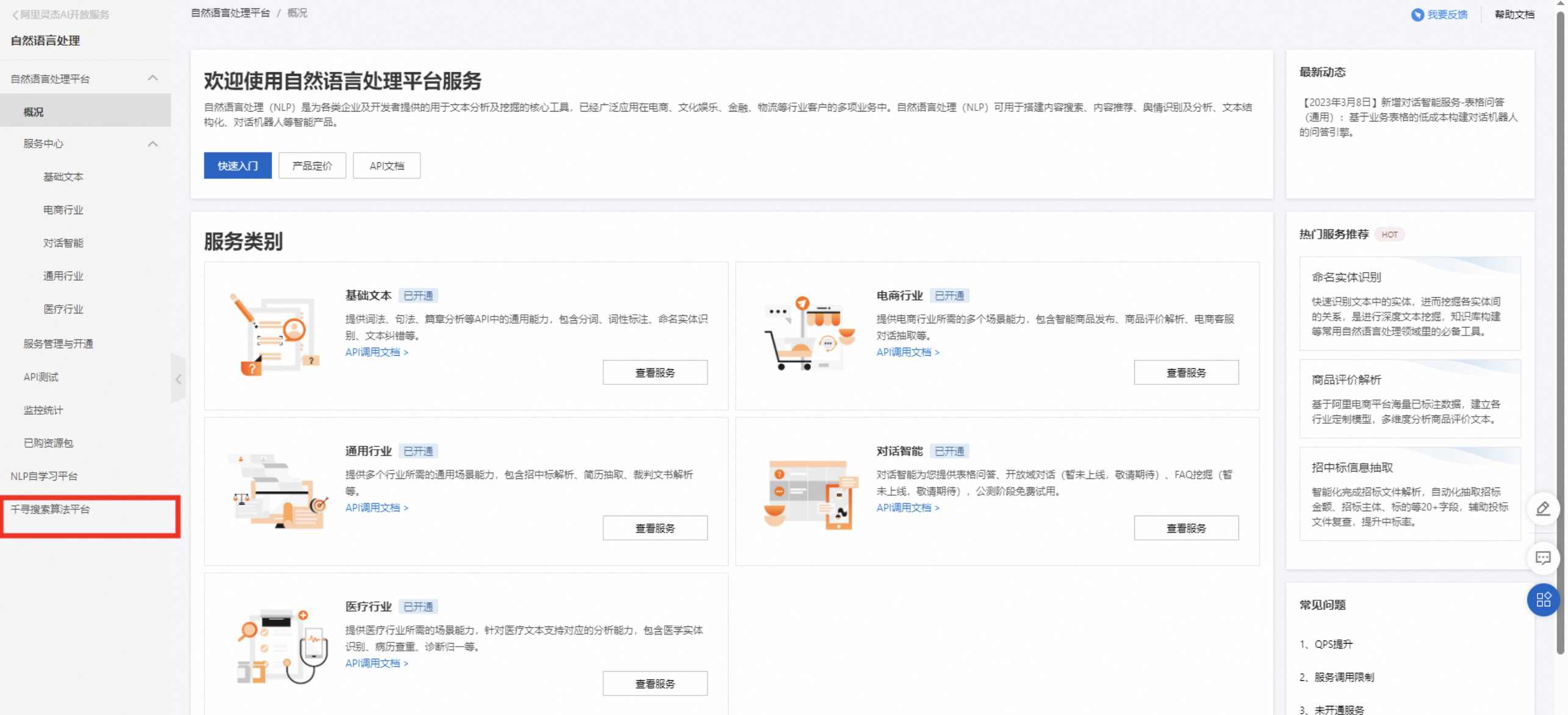
付费开通产品之后即可使用。
1.2. 购买资源
需要购买的资源包括:
-
搜索引擎
-
数据存储
1.2.1. 搜索引擎
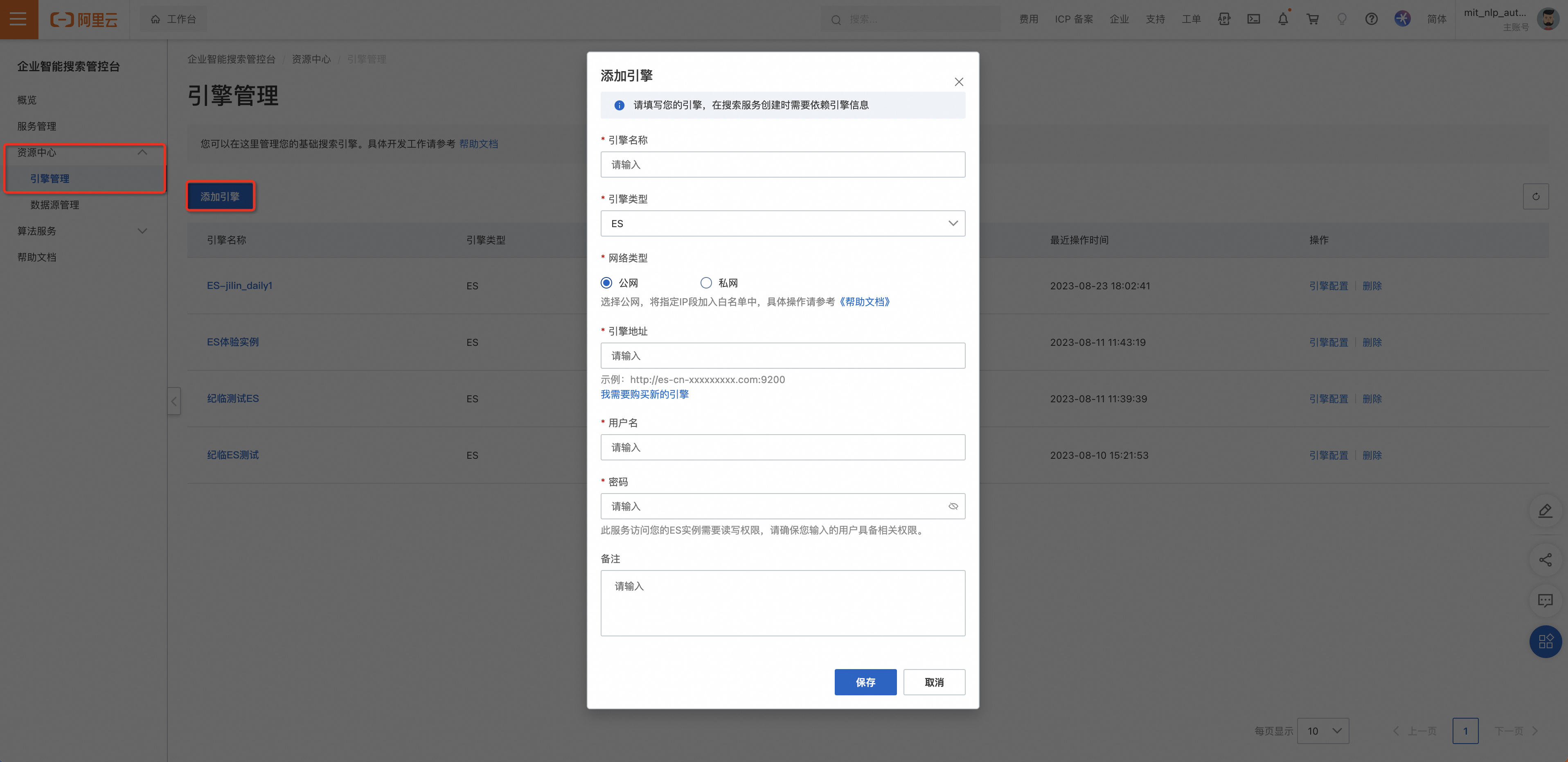
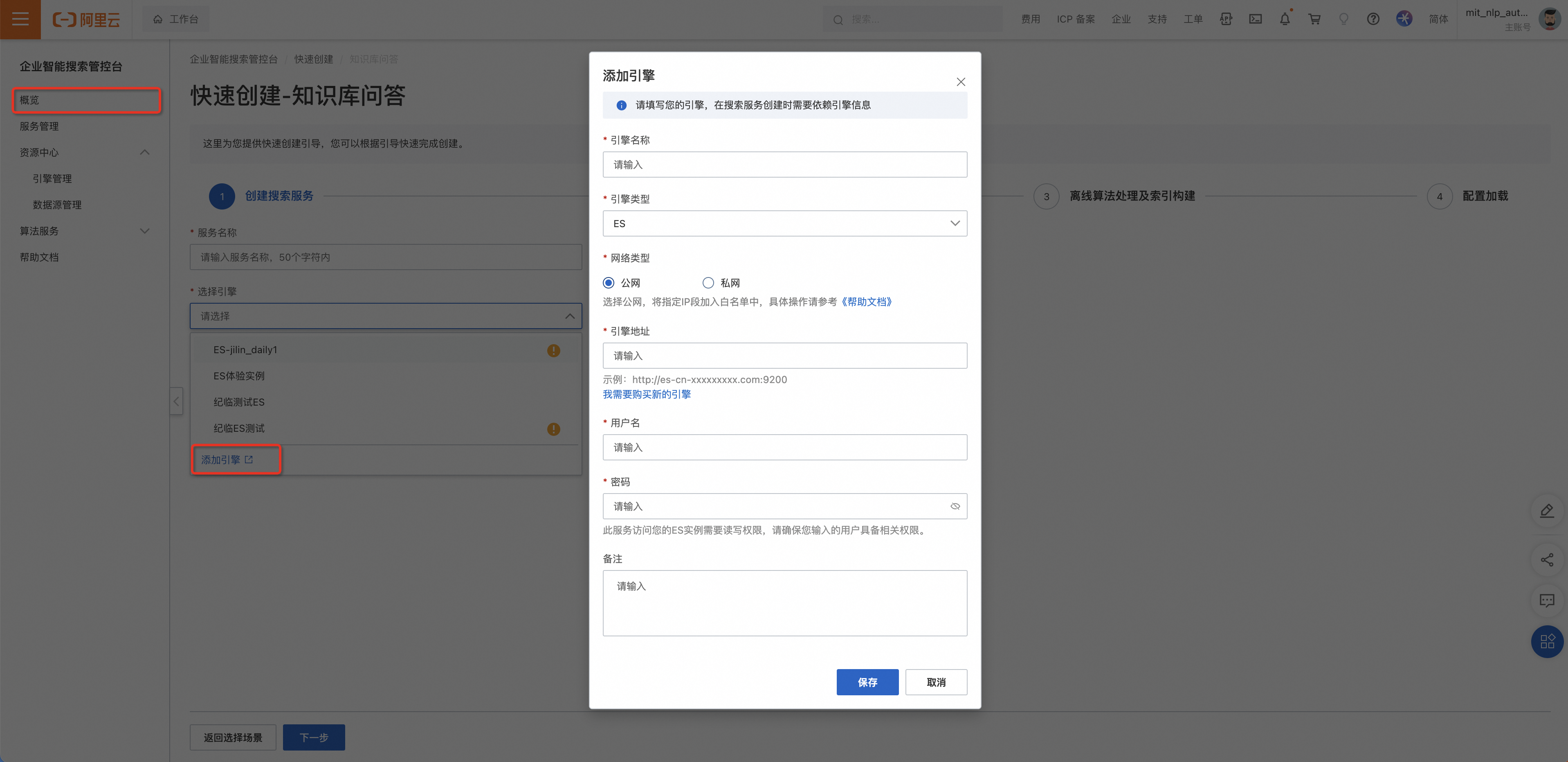
搜索引擎提供检索服务的基础组建,可在资源中心-引擎管理添加引擎,也可在概览-创建服务直接选择或添加。若没有可用的引擎,点击我需要购买新的引擎。
以下是已适配的引擎列表,可以根据实际需求进行调整:
|
已适配引擎列表 |
版本 |
配置 |
插件 |
链接 |
|
阿里云Elasticsearch |
|
|
|
-
引擎配置流程:
-
选择规格:非向量需求场景不小于2核8G,向量需求场景建议不小于8核32G。
-
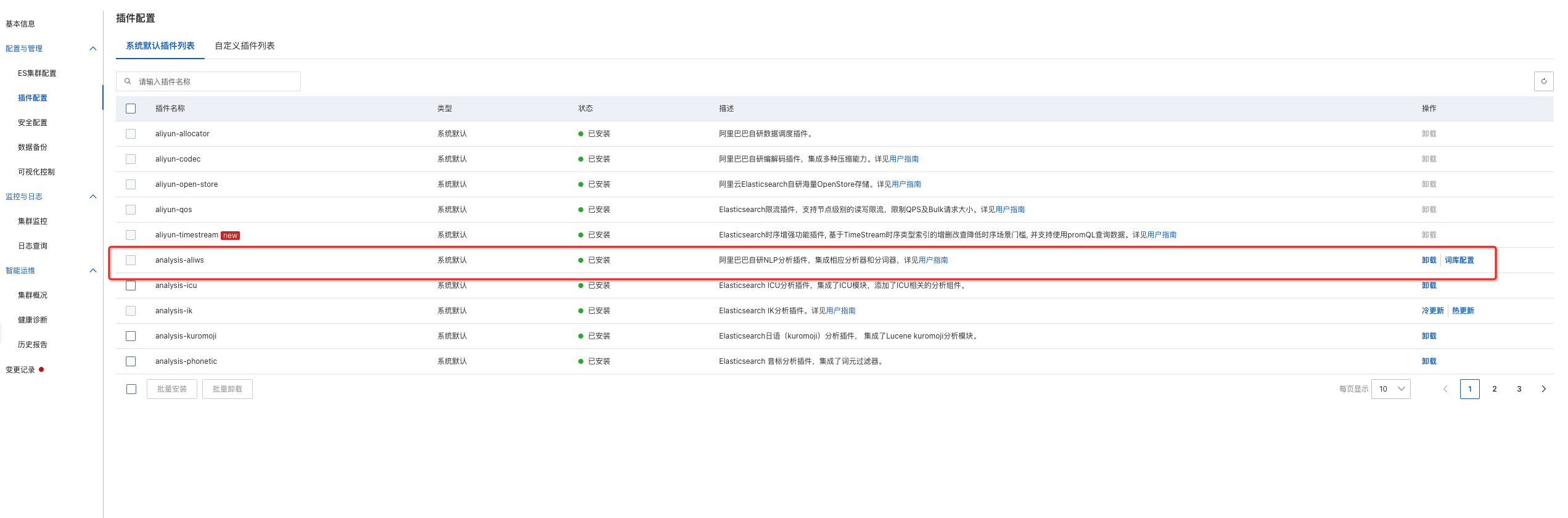
选择插件:需要安装aliws插件,配置与管理-插件配置-系统默认插件列表。
-
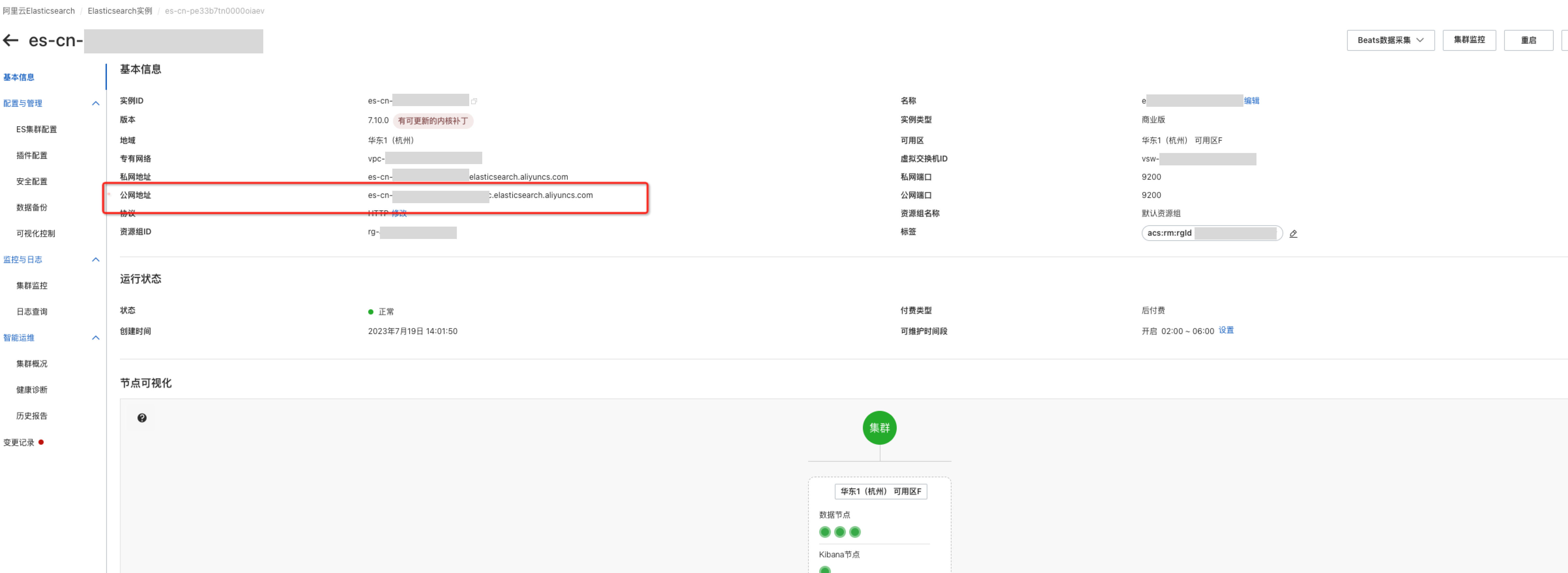
配置安全链接:在ES实例的配置与管理-安全配置中开启公网访问,然后IP段加入白名单中(具体IP段配置联系@张家栋,钉钉群二维码可见文档最后)。

-
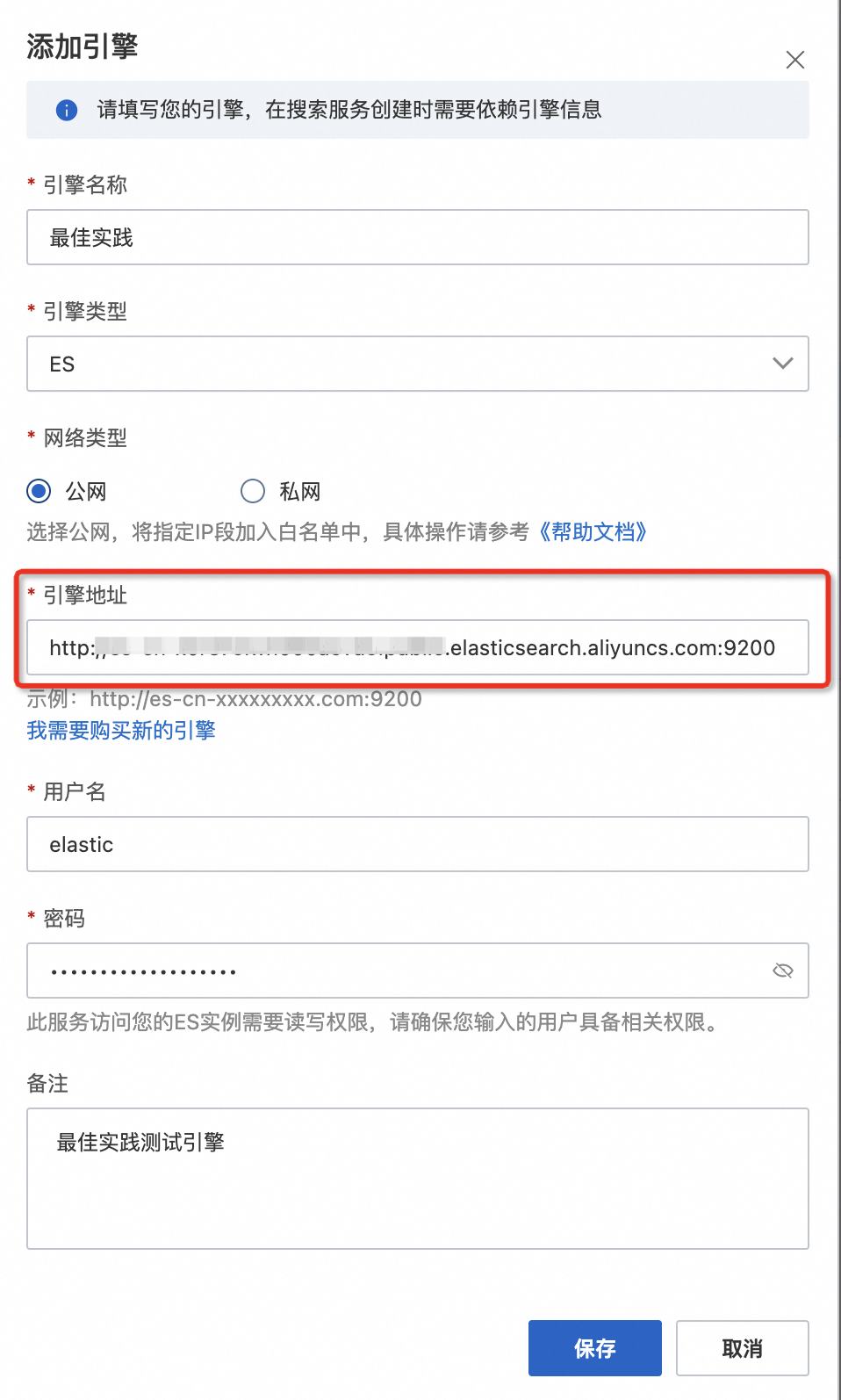
添加引擎:
引擎配置完成后即可将ES实例的基本信息中公网地址和公网端口添加到千寻大模型搜索的引擎管理中。操作如下:
1.2.2. 数据存储服务
数据存储用于保存企业知识库,可在资源中心进行数据源管理也可在快速创建页面直接选择或添加。以下是已适配数据源列表:
|
已适配数据源列表 |
链接 |
|
阿里云 RDS MySQL |
|
|
阿里云 MaxCompute |
|
|
阿里云 OSS |
根据数据源的类型不同建议选择不同的数据构建方式:
-
RDS数据源:适用于存储数据库类型的数据,可灵活选择数据库库表字段进行解析,构建索引。
-
OSS数据源:适用于存储文件类型的数据,可指定bucket及子路径并对指定文件类型进行解析,构建索引。
-
混合数据源:当接入数据源同时存在文件类型及数据库类型数据时,需要选择混合数据源的方式进行接入。
其中混合数据源接入需购买RDS,购买后进入RDS管控台进行如下配置:
-
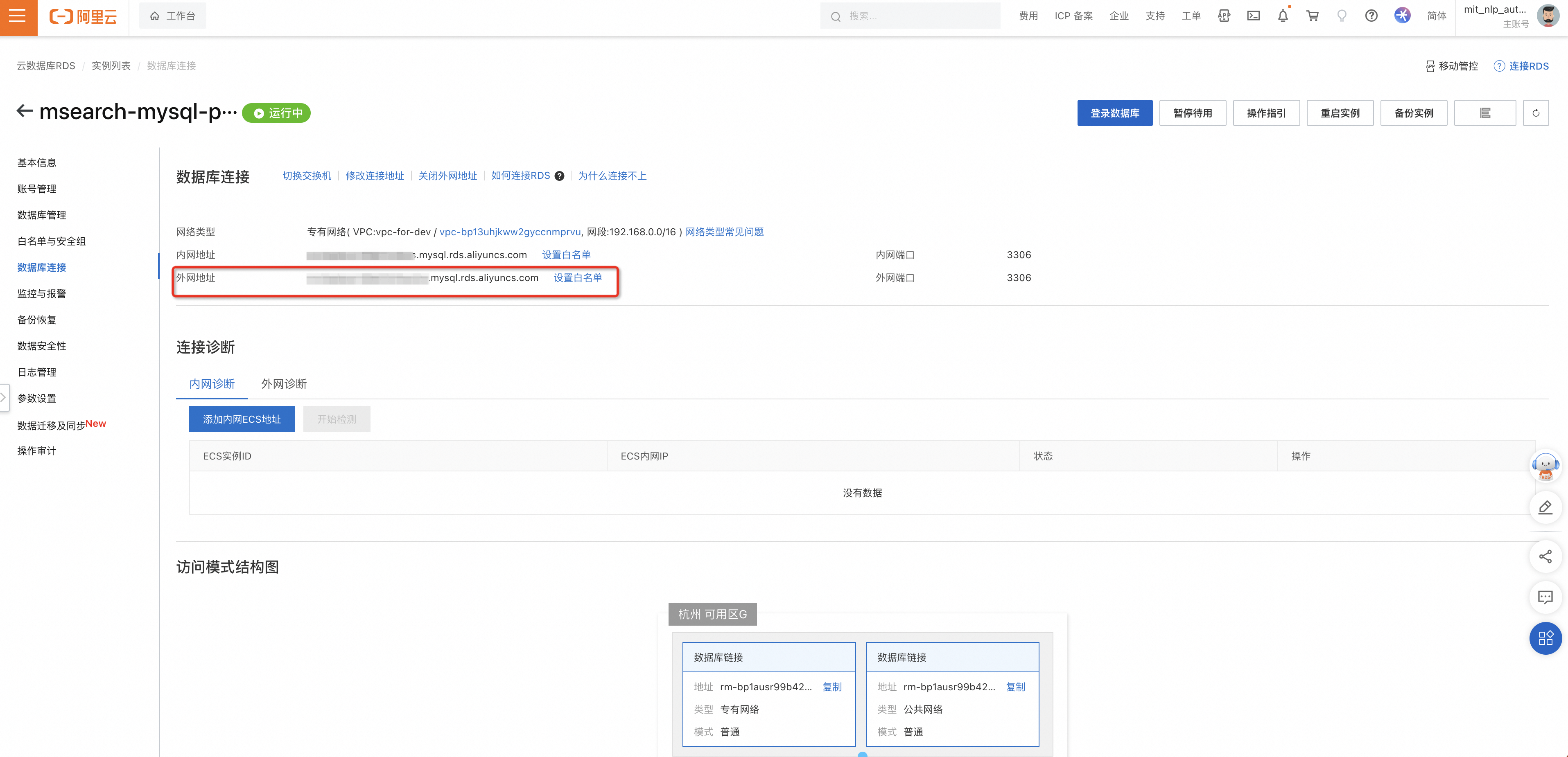
服务地址:开启外网地址后,将该外网地址用于企业搜索管控台录入数据库地址。
-
网络配置:进入RDS实例,白名单与安全组-白名单设置-添加白名单分组(具体IP段配置联系@张家栋,钉钉群二维码可见文档最后)。
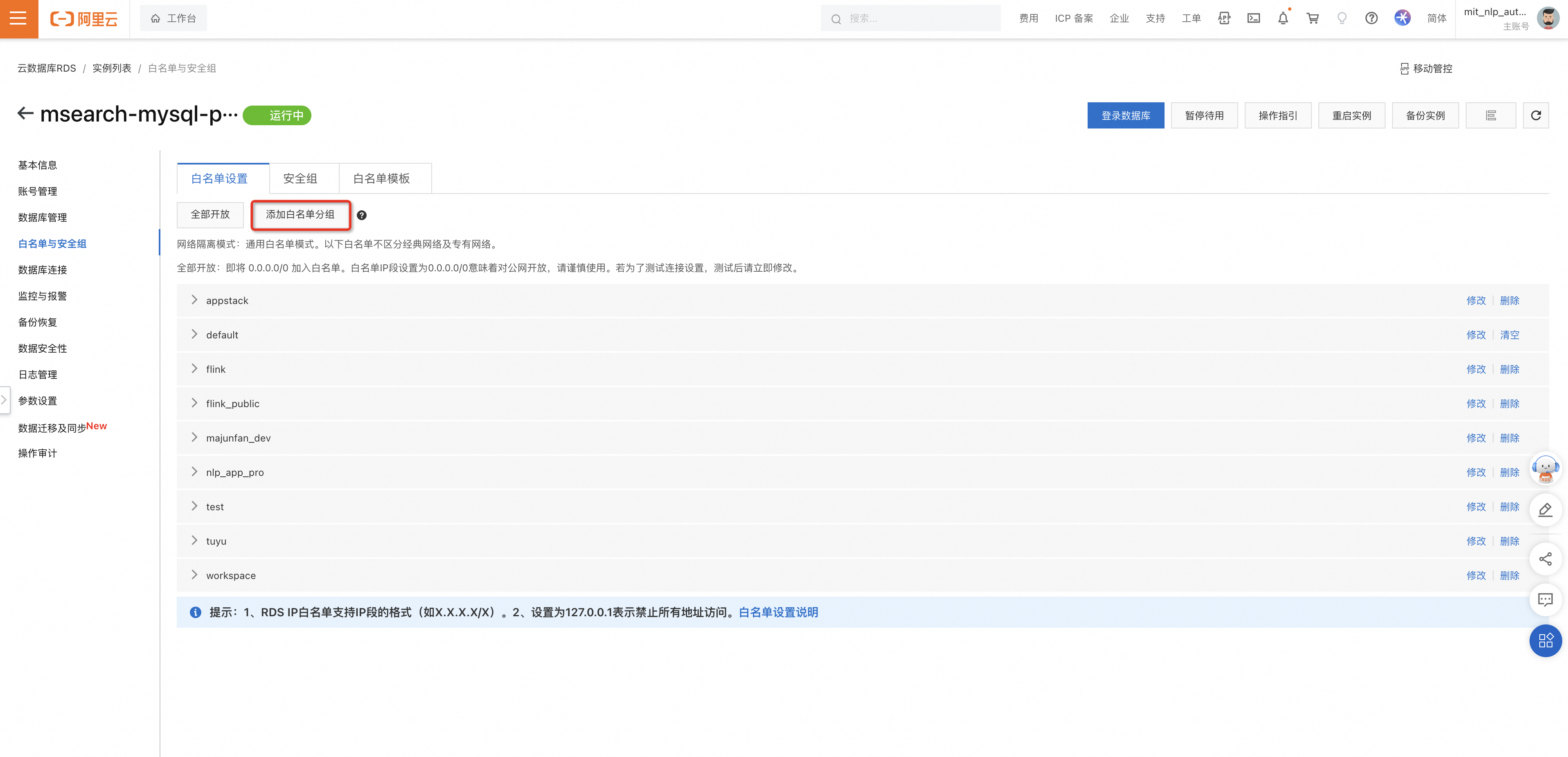
-
账号创建:进入RDS实例,账号管理-用户账号-创建账号。
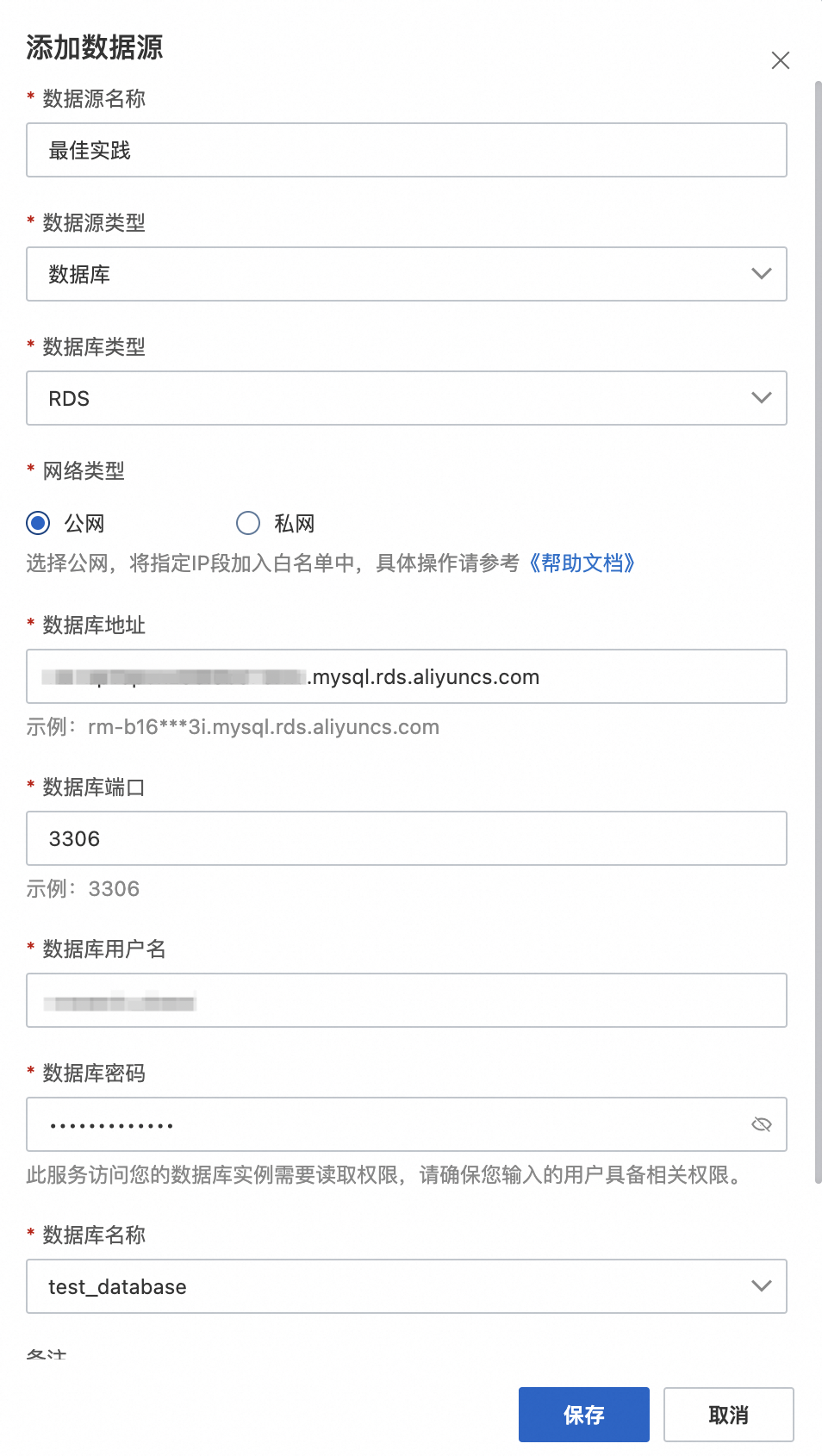
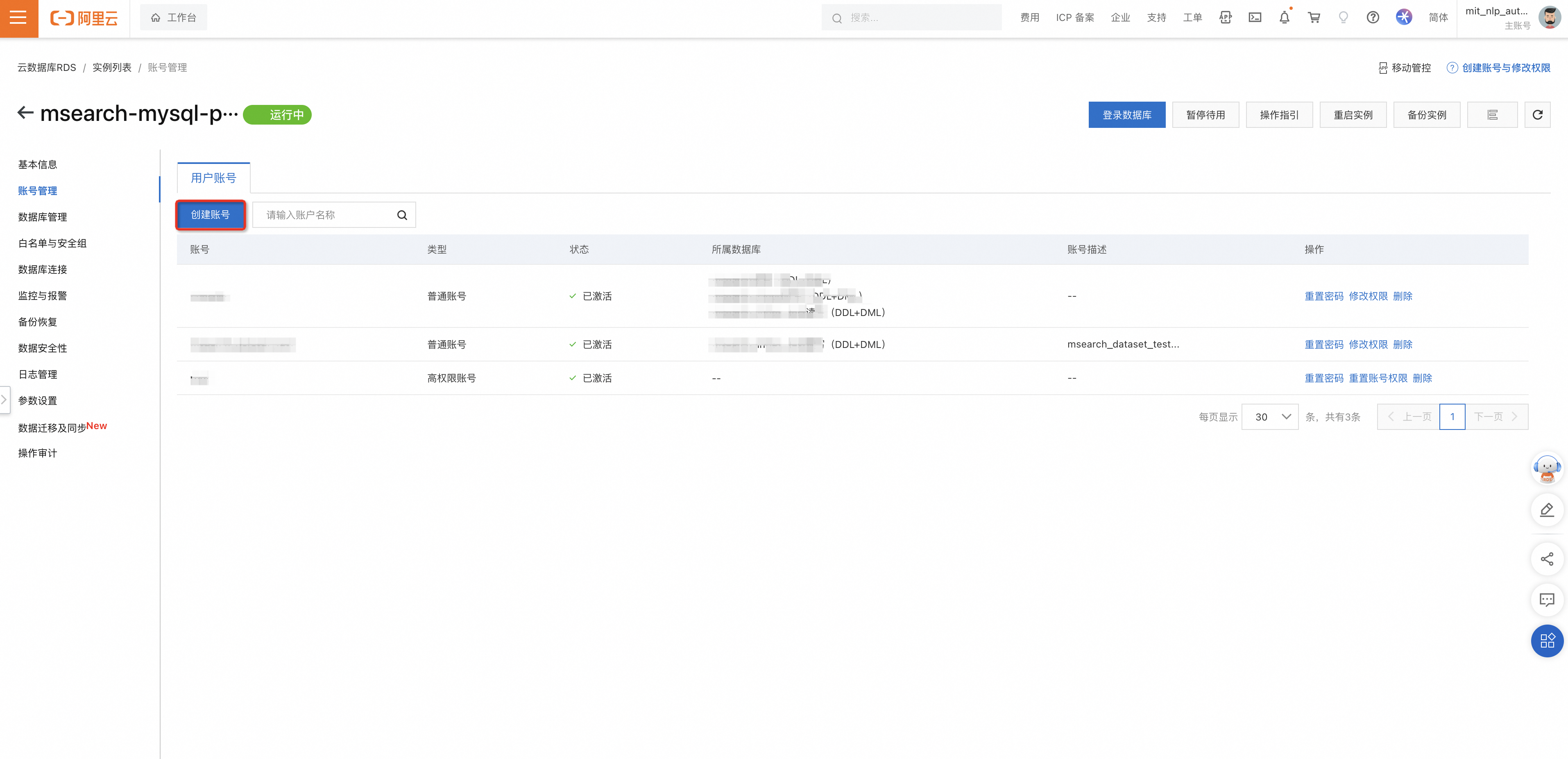 将RDS实例的数据库链接信息中外网地址和外网端口添加到千寻大模型搜索的数据源管理中。
将RDS实例的数据库链接信息中外网地址和外网端口添加到千寻大模型搜索的数据源管理中。
1.3. 准备数据
在数据存储服务准备完成后,可以对数据存储服务中进行数据导入和对接,在格式上需要做一些对齐操作:
-
RDS数据源:支持数据库类型数据的接入。解析字段同所选数据库库表字段,非固定可选。若解析数据为faq类型,要求数据库库表字段类型为:id、question、answer、sim_question、url、gmt_modified。
-
OSS数据源:支持文件类型数据的接入。支持解析的文件格式.pdf/.docx/.txt/.md/.html,解析字段为默认字段,固定全选。若解析数据为faq类型,则支持解析的文件格式为.csv/.xlsx,要求数据源字段类型为id、question、answer、sim_question、url。
-
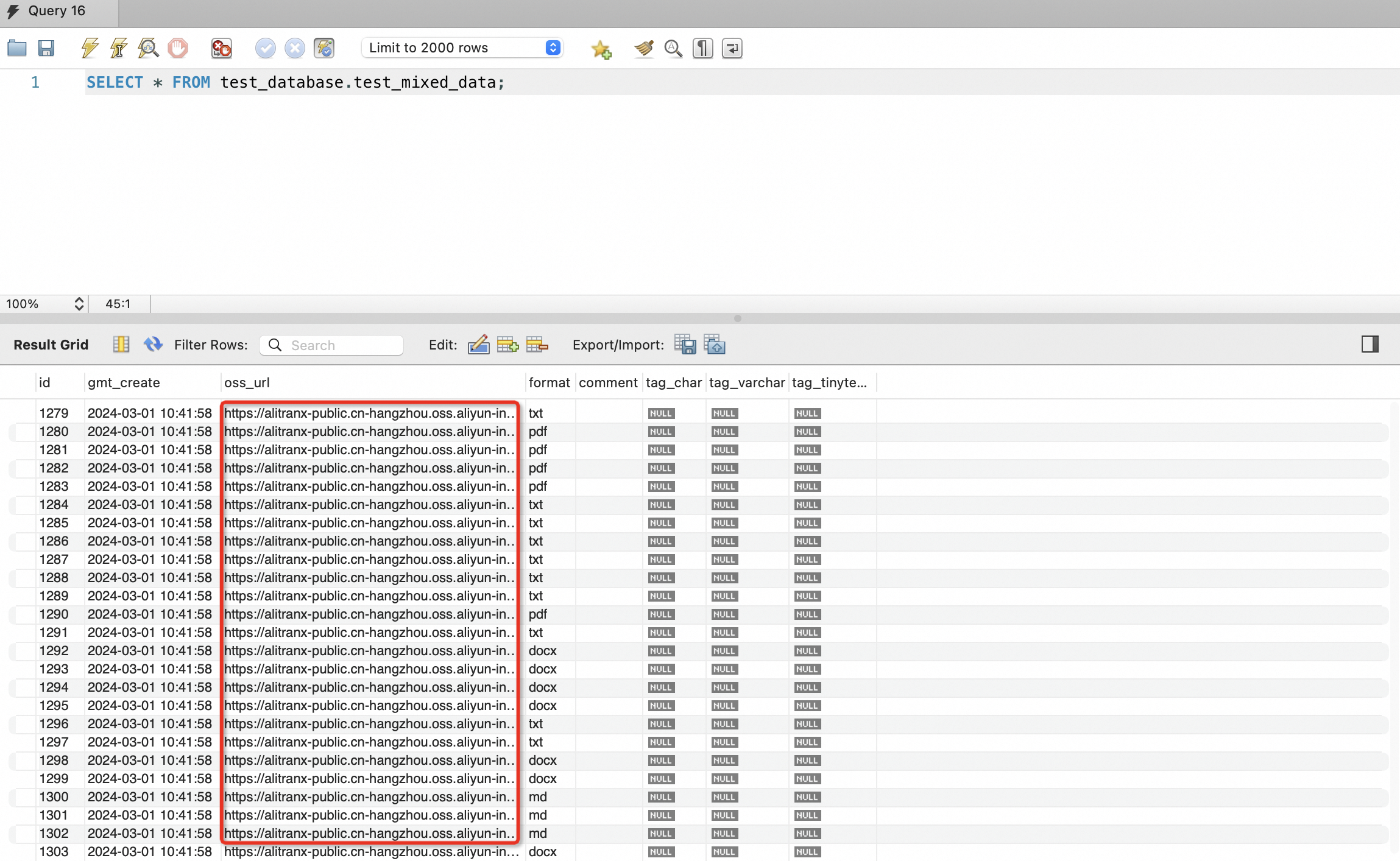
混合数据源:支持数据库类型数据+文件类型数据的方式接入。数据库类型数据存储在对应需要解析的字段,若还需要文件类型数据,则RDS中必须字段为主键、文件路径字段、文件类型字段,例如示例中的id、oss_url、format。其中文件路径字段中支持传入可下载链接或OSS文件路径,如下图所示,若使用OSS文件路径,则索引构建阶段还需要配置对应的OSS数据源。若解析数据为faq类型,需满足上述不同数据源的格式要求。
1.4. 配置服务
在搜索引擎和数据准备完成之后,便可以回到千寻大模型搜索服务的控制台开始搜索服务的创建和配置了,具体步骤如下:
1.4.1. 创建搜索服务
-
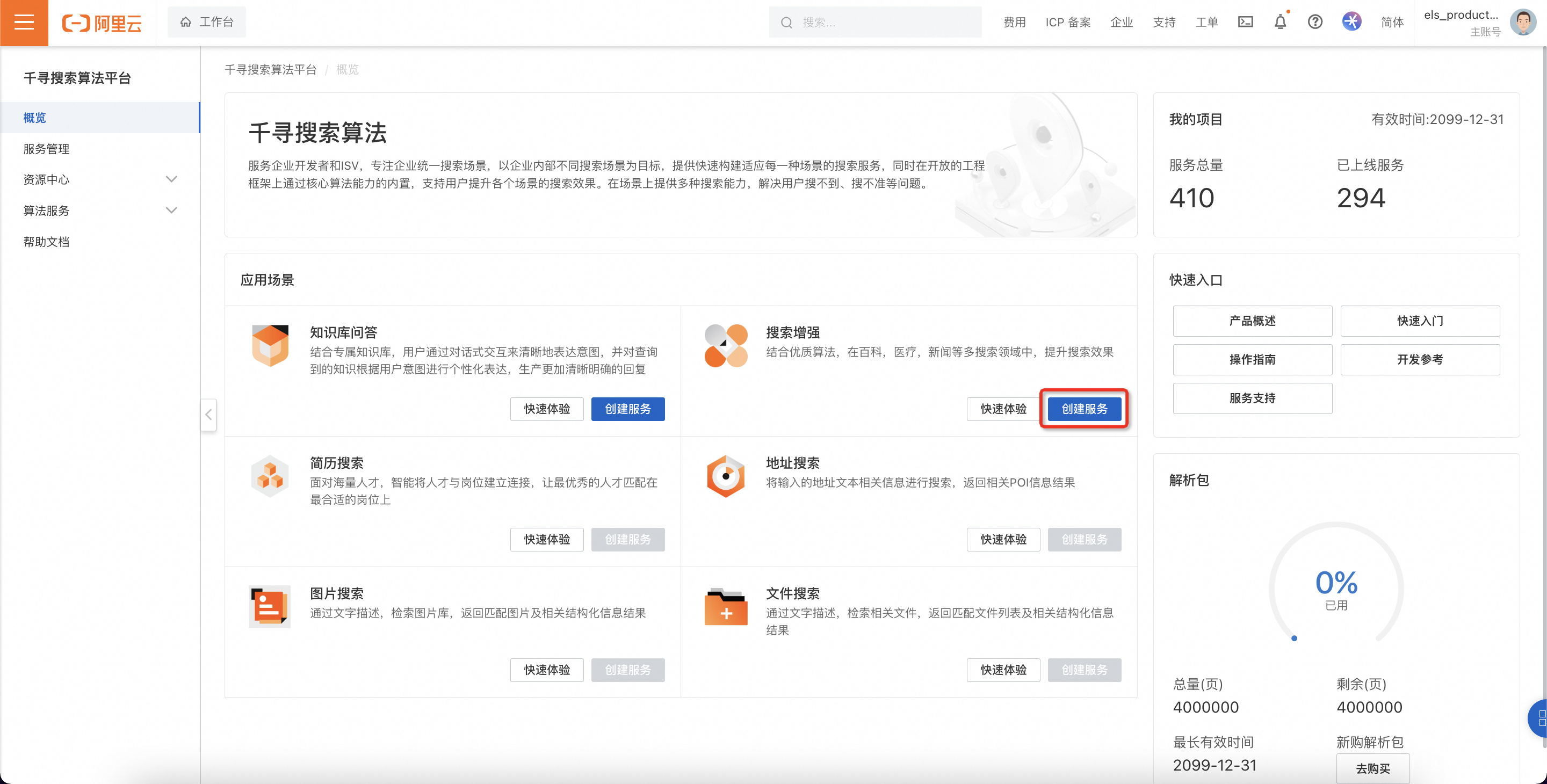
概览-搜索增强-创建服务,进入服务创建界面。
-
编辑服务名称并选择服务所使用的引擎,完成创建中进入索引配置。
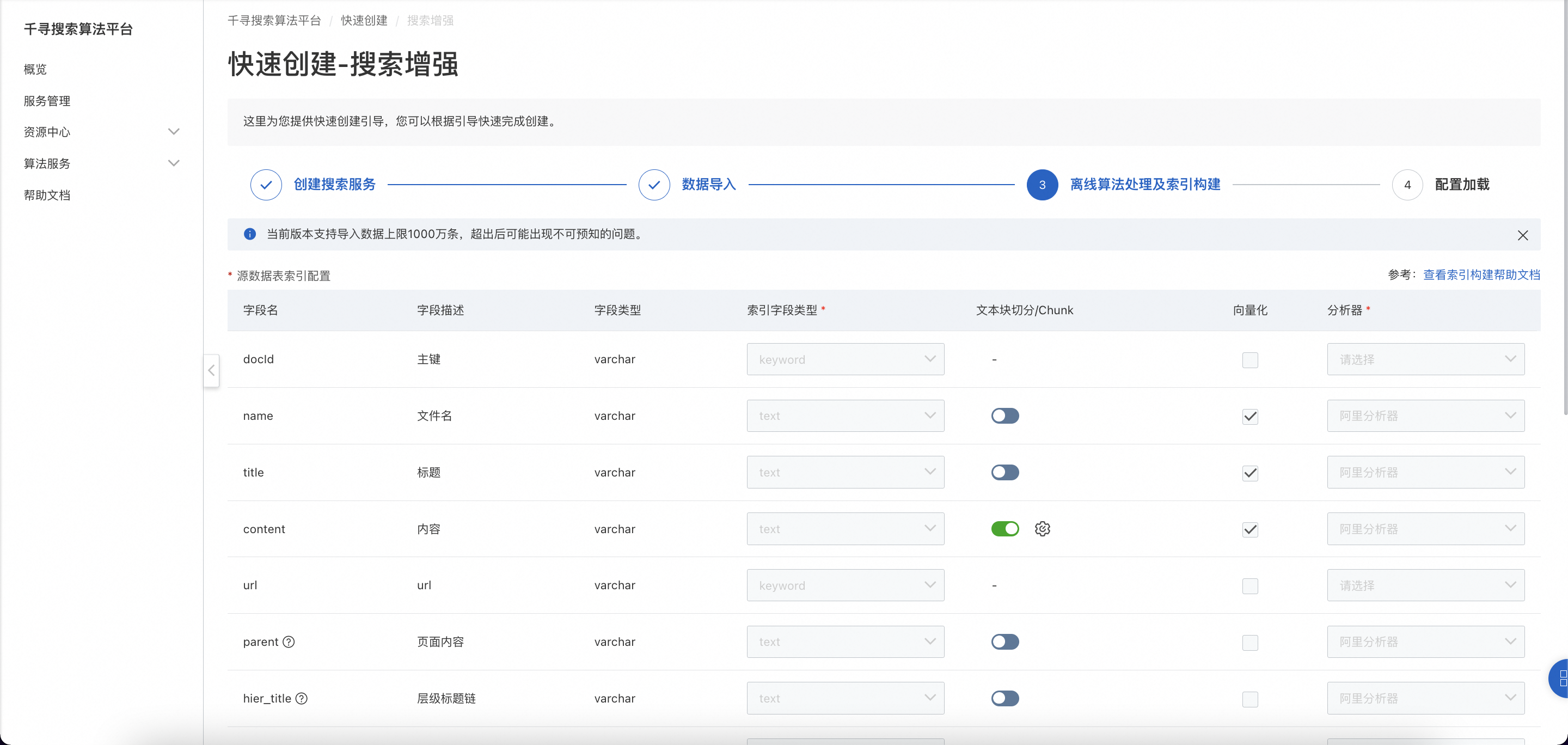
其中,索引配置的关键概念如下:
-
字段名
字段名称,对采用数据表作为数据源的实例,字段名和表格字段名一一对应,字段类型跟源数据表中定义的字段类型保持一致。对采用OSS文件格式作为数据源的实例,字段名称跟离线数据解析结果字段对应。
-
索引字段类型
索引字段类型定义了字段的数据类型,以便搜索引擎(例如ElasticSearch)能够正确地处理和索引这些字段的值。以ElasticSearch为例,常见的索引字段类型:
|
索引字段类型 |
字段类型说明 |
|
text |
用于索引长文本,例如文章内容、描述等。文本类型会进行分词处理,以便能够根据单词进行搜索和匹配。 |
|
keyword |
用于索引短文本,例如标签、关键字等。关键字类型不会进行分词处理,整个字段作为一个整体进行索引和匹配。 |
|
interger |
用于索引INT类型数字,数字类型可以用于排序、范围查询等操作 |
|
long |
用于索引LONG类型数字,数字类型可以用于排序、范围查询等操作 |
|
double |
用于索引DOUBLE类型数字,数字类型可以用于排序、范围查询等操作 |
|
float |
用于索引FLOAT类型数字,数字类型可以用于排序、范围查询等操作 |
|
date |
用于索引日期和时间。日期类型可以进行日期范围查询、排序等操作。 |
|
boolean |
用于索引布尔值,即true或false |
|
binary |
用于索引二进制数据,例如图片、文件等 |
-
文本块切分/Chunk
当该字段文本长度比较长且需要作为大模型回答的参考内容时,建议勾选该字段。勾选后该字段的长文本会被切分为短的文本块;若不勾选,部分较长的文本后半段会被直接截断。OSS数据源的content字段默认勾选。
-
向量化
文本向量化是将文本数据转换为数值向量的过程。它将文本中的词语、句子表示为向量形式,以便能够信息检索等任务中进行相关性计算。勾选向量化后,搜索的准确性能够得到提升,对于用户输入的问题与相关知识库内容字面不一致的情况也能搜到正确的知识。
-
分析器
在索引构建过程中,分析器(OR 分词器)是用于将文本数据分割成词的工具。它是文本分析过程中的一个重要组件,用于构建倒排索引,以便能够对文本进行搜索和匹配。分析器将输入的文本按照一定的规则进行分割,分析器可以将一个长文本分割成多个词,以便能够对这些词进行索引和搜索。
1.4.2. 向量化版本选择
目前可以选择text-embedding-v1和text-embedding-v2两个向量化版本。
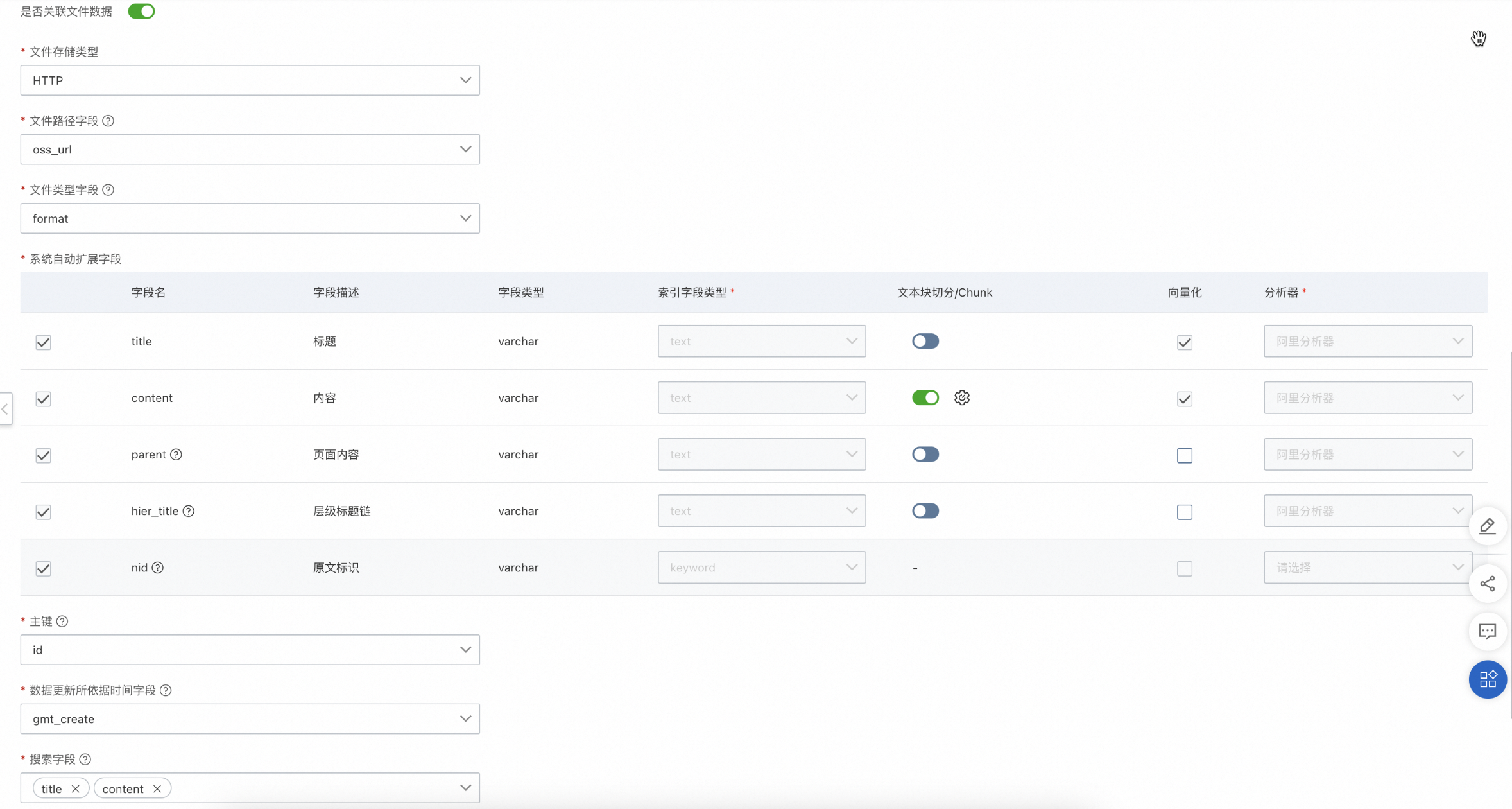
1.4.3. 是否关联文件数据
当接入数据源同时存在文件类型及数据库类型数据时,且“文件路径字段”和“文件类型字段”都是数据库中的字段,需要开启“关联文件数据”功能,开启后,系统会自动校验,若源数据表中字段和系统自动扩展字段中的“title、content、parent、hier_title、nid”有重复,则需退出流程,更改字段名称。
-
打开关联文件数据开关,文件存储类型支持OSS和HTTP两种。选择OSS需要配置对应的OSS数据源,文件路径字段内容为源文件的OSS路径;选择HTTP,文件路径字段为可下载链接。
-
设置主键、数据更新所依据时间字段、搜索字段、接口返回字段、是否自动更新。
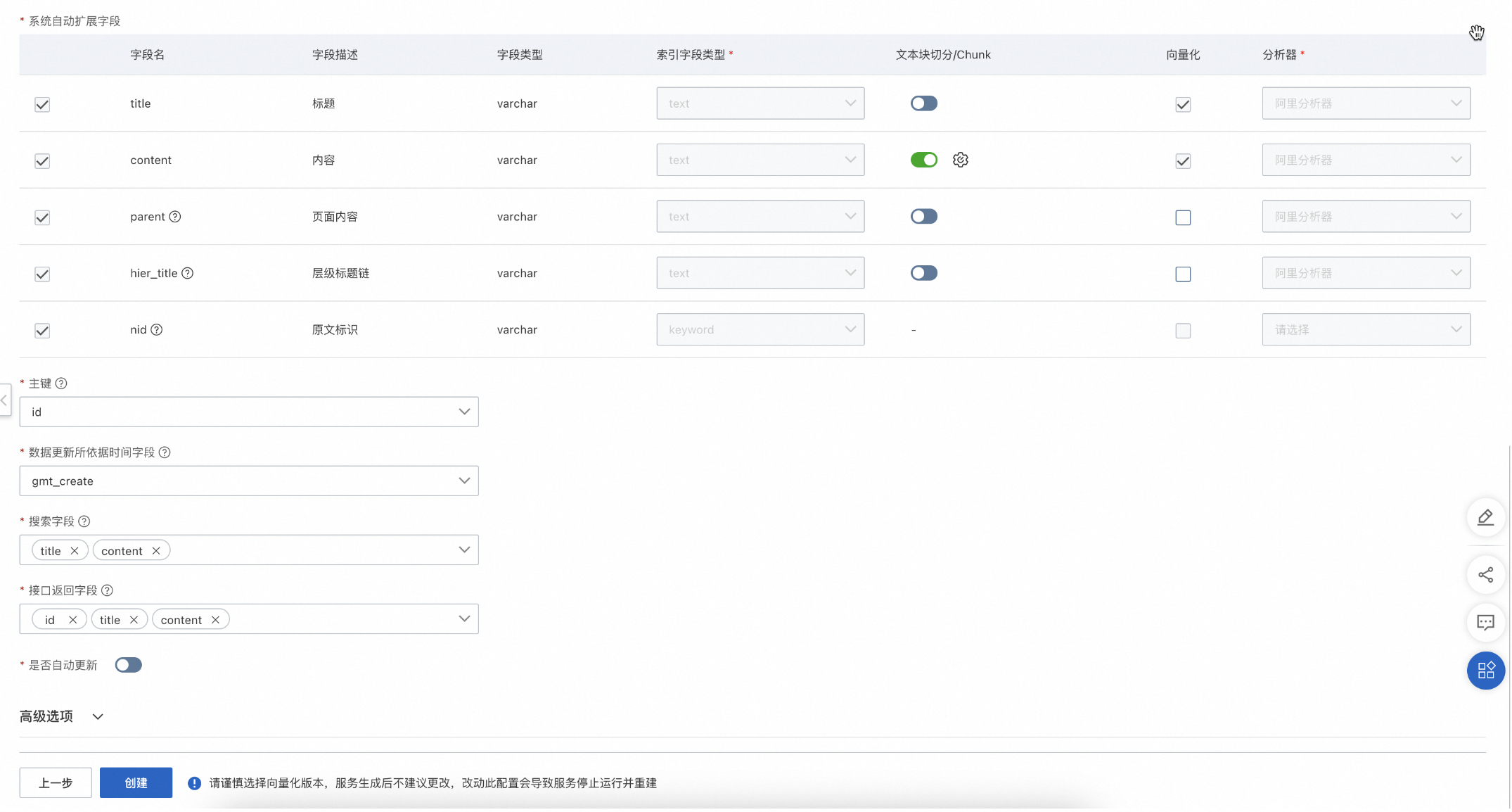
概念解释如下:
-
主键
数据的唯一标识
-
数据更新所依据时间字段
指定更新时间字段,用户后续索引更新标识,如不指定,索引数据只会执行首次构建,不会做增量更新。
-
搜索字段
全文检索字段,需要为keywords或text类型,用来执行搜索操作,匹配查询条件,限制搜索范围。
-
接口返回字段
接口返回字段是指搜索请求后的返回结果字段,可在索引配置字段中选择业务所需字段,后续可应用于大模型多轮对话中的参考内容。
-
是否自动更新
若数据源索引配置需要定期更新,则需要打开此开关。支持每小时/每天/每月三种周期自动更新,支持配置对应更新的时间点以及时区。
1.4.4. 配置加载
-
点击创建,开始创建服务,等待数据处理和导入引擎。
-
服务创建成功。
1.5. 测试服务
目前服务测试提供两种方式:
-
管控台测试;
-
SDK测试。
1.5.1. 管控台测试:
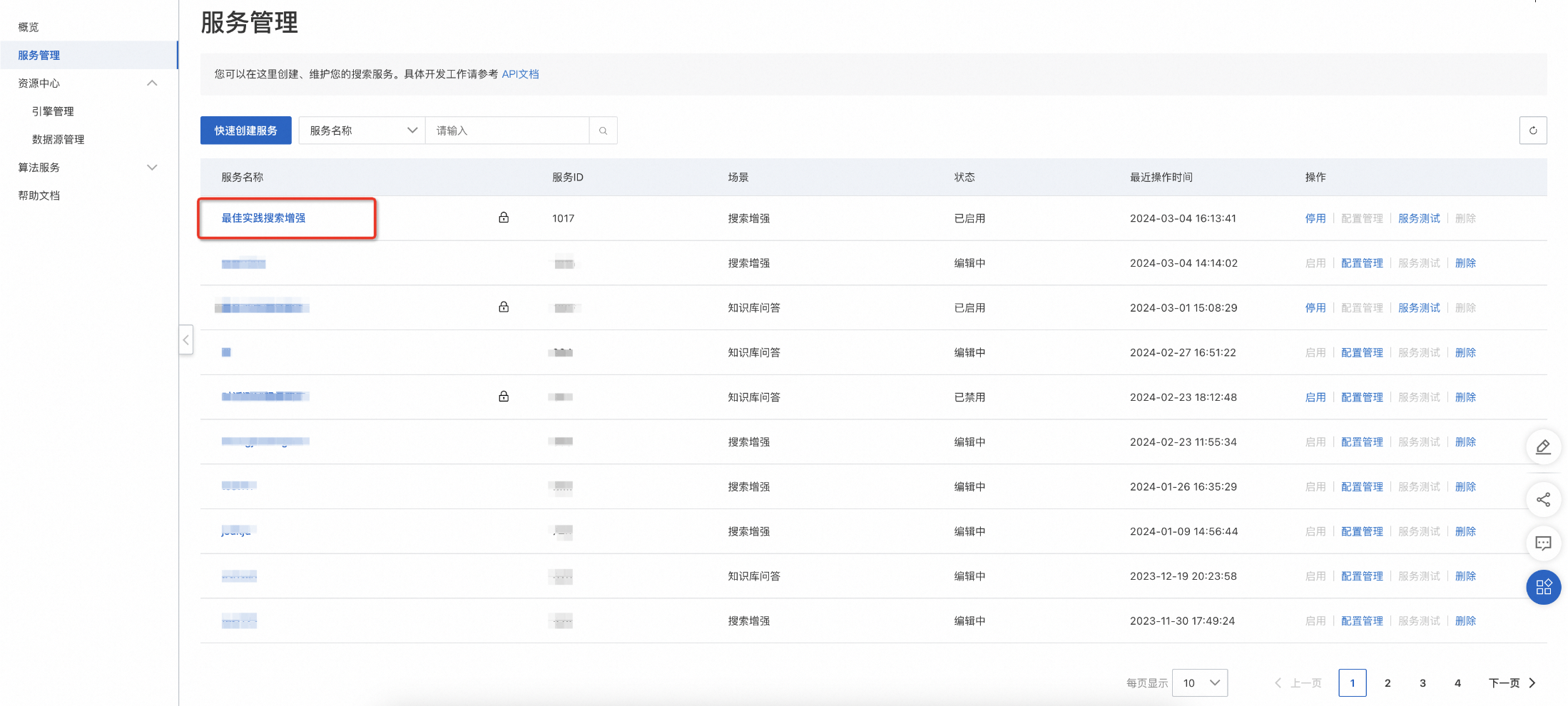
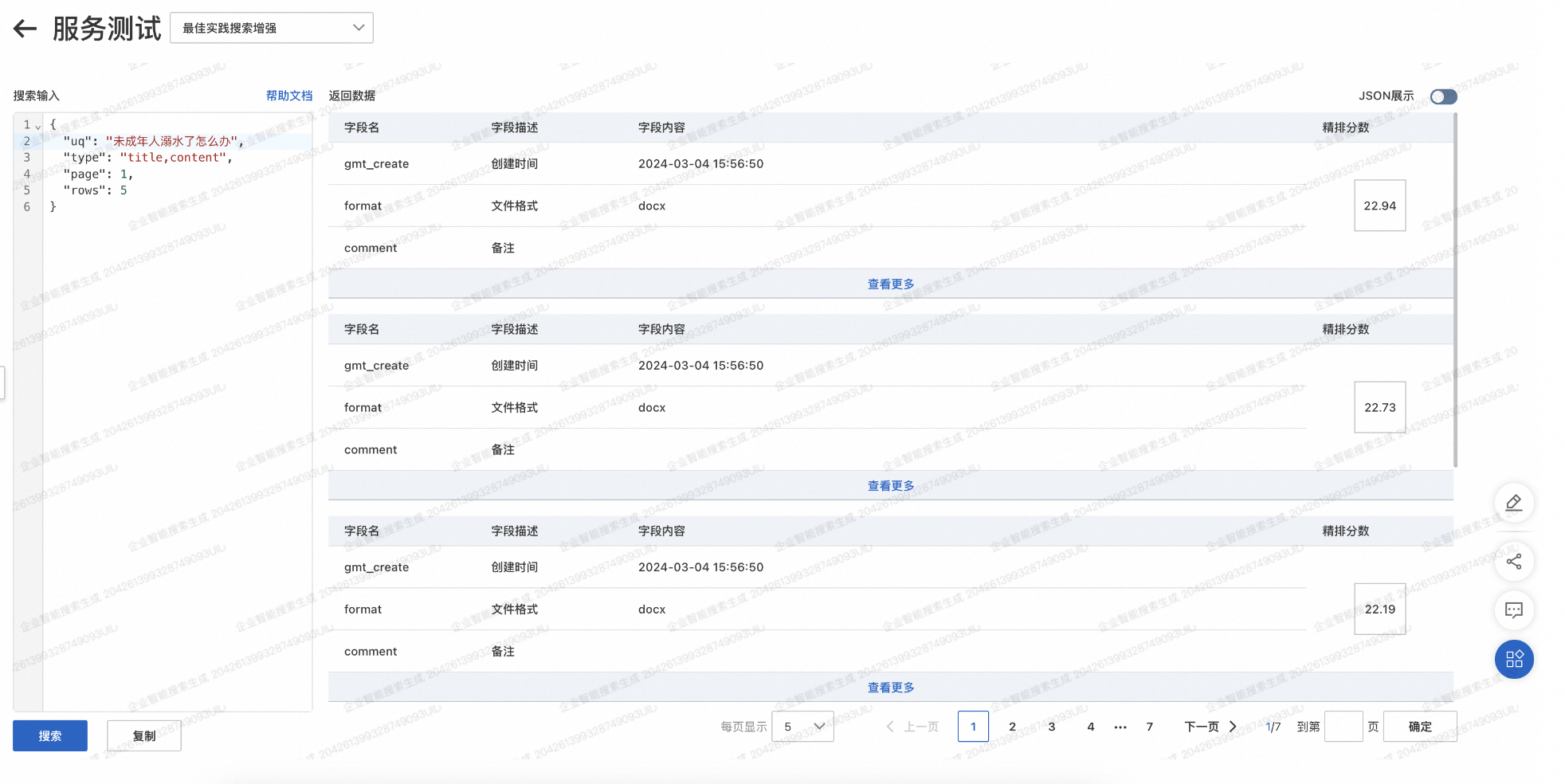
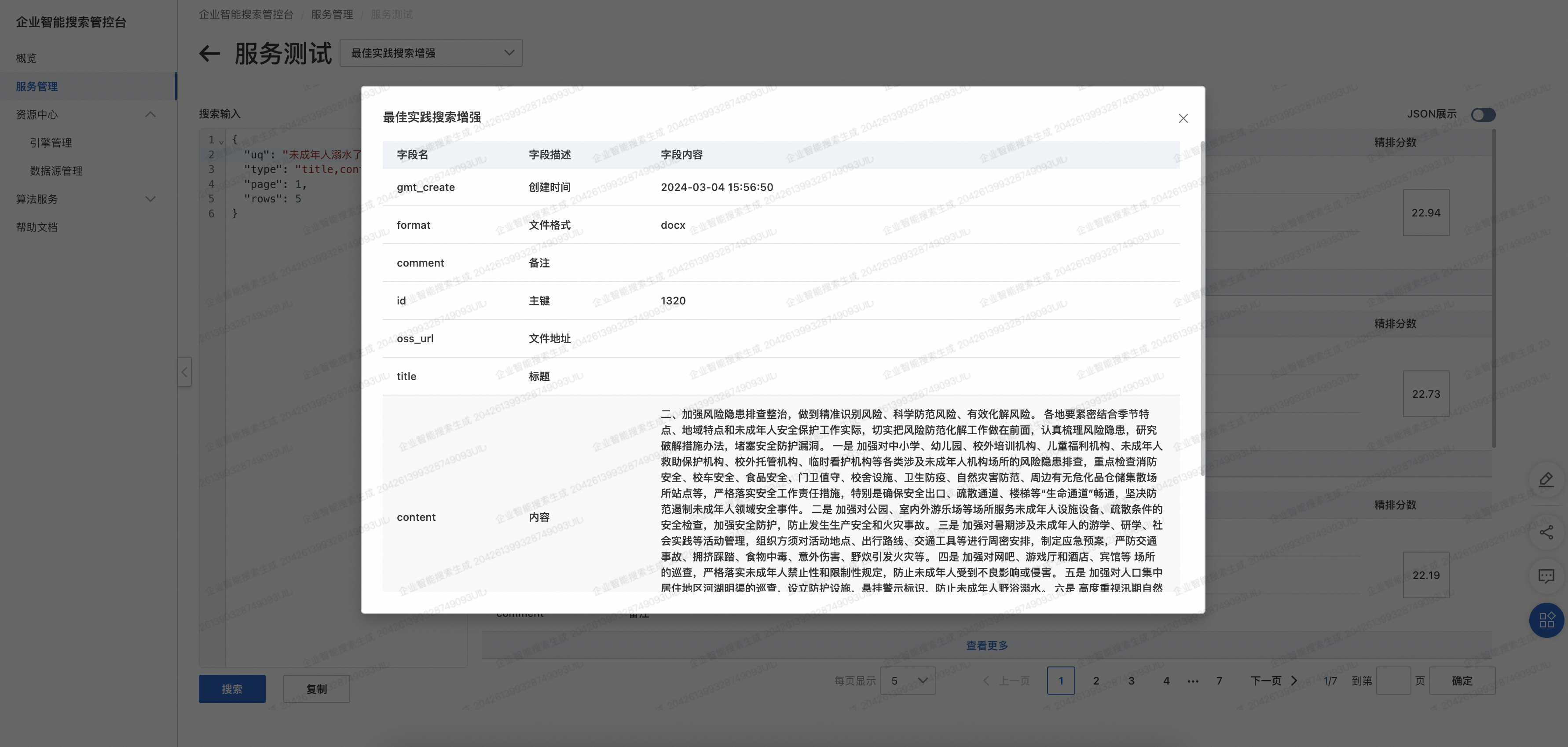
-
进入服务管理,找到创建的服务,点击服务测试。
-
输入搜索参数进行搜索,搜索参数配置详见产品文档中的请求入参:。
1.5.2. SDK测试
-
配置环境变量:
export ALIBABA_CLOUD_ACCESS_KEY_ID=YOUR_ALIBABA_CLOUD_ACCESS_KEY_ID
export ALIBABA_CLOUD_ACCESS_KEY_SECRET=YOUR_ALIBABA_CLOUD_ACCESS_KEY_SECRET1.5.2.1. Python SDK
-
pip安装依赖:
pip install alibabacloud-alinlp20200629-
Python示例代码:
import os
import json
from alibabacloud_alinlp20200629 import client, models
from alibabacloud_tea_openapi import models as api_models
# 创建一个搜索client
config = api_models.Config(
access_key_id=os.environ['ALIBABA_CLOUD_ACCESS_KEY_ID'],
access_key_secret=os.environ['ALIBABA_CLOUD_ACCESS_KEY_SECRET'],
region_id="cn-beijing")
nlp_client = client.Client(config)
# 配置一个搜索request
request = models.PostMSSearchEnhanceRequest()
request.service_id = 1017 # 服务id
# 线上query
query = '测试'
# 配置并请求搜索服务
request.uq = query # 用户输入检索值
request.page = 1 # 分页(页码)
request.rows = 5 # 分页(行数)
response = nlp_client.post_mssearch_enhance(request)
# 打印搜索结果
print(json.dumps(response.body.data, ensure_ascii=False))
1.5.2.2. Java SDK
-
Maven依赖:
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>alinlp20200629</artifactId>
<version>3.0.0</version>
</dependency>
<!--出现java.lang.NoSuchMethodError: com.aliyun.credentials.Client.getCredential()Lcom/aliyun/credentials/models/CredentialModel;异常则引入-->
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>credentials-java</artifactId>
<version>0.3.0</version>
</dependency>-
Java示例代码:
public static void main(String[] args) throws Exception {
// 创建一个搜索client
Config config = new Config();
config.setEndpoint("alinlp.cn-beijing.aliyuncs.com");
config.setAccessKeyId("xxxx");
config.setAccessKeySecret("xxxx");
Client client = new Client(config);
// 配置一个搜索request
PostMSSearchEnhanceRequest postMSSearchEnhanceRequest = new PostMSSearchEnhanceRequest();
postMSSearchEnhanceRequest.setServiceId(1017L); // 服务id
// 线上query
postMSSearchEnhanceRequest.setUq("测试"); // 用户输入检索值
// 配置并请求搜索服务
postMSSearchEnhanceRequest.setPage(1); // 分页(页码)
postMSSearchEnhanceRequest.setRows(5); // 分页(行数)
postMSSearchEnhanceRequest.setFields(Lists.newArrayList("name","title", "content")); // 召回字段(正排)
PostMSSearchEnhanceResponse response = client.postMSSearchEnhance(postMSSearchEnhanceRequest);
// 打印搜索结果
System.out.println(JacksonUtils.toJson(response));
}2. 阿里云百炼服务搭建
2.1. 阿里云百炼简介
一条完整的知识库问答链路,在完成相关问题的知识检索之后,需要有LLM来基于提问和检索到的知识库内容进行最终的总结和回答。但将一个大模型本身封装成一个稳定、可靠、易维护、易扩展的服务是一个复杂的工程。阿里云百炼将各类AI模型通过标准化的封装形成API服务,以方便应用开发者调用。
目前在阿里云百炼中可以支持多种大模型,包括千问系列的独有模型以及第三方模型(包括Llama、百川等),更多模型相关内容参考文档:模型列表。
2.2. 开通和搭建
阿里云百炼的开通和搭建可以参考阿里云官网的相关信息:快速入门
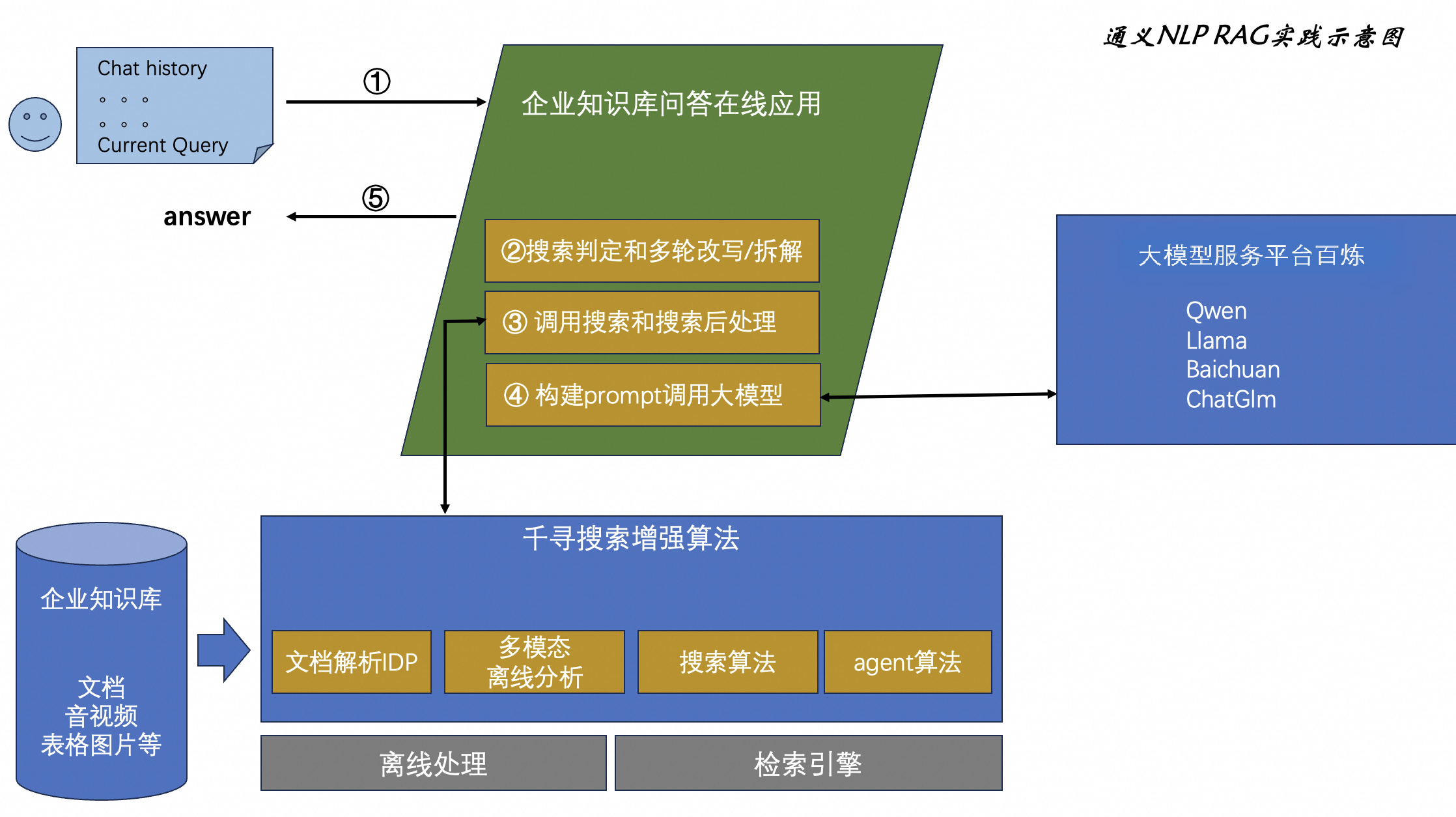
3. 问答在线链路搭建
在完成了搜索服务搭建并打通了阿里云百炼服务之后,我们便具备了:
-
知识库搜索的能力;
-
大模型的生成能力。
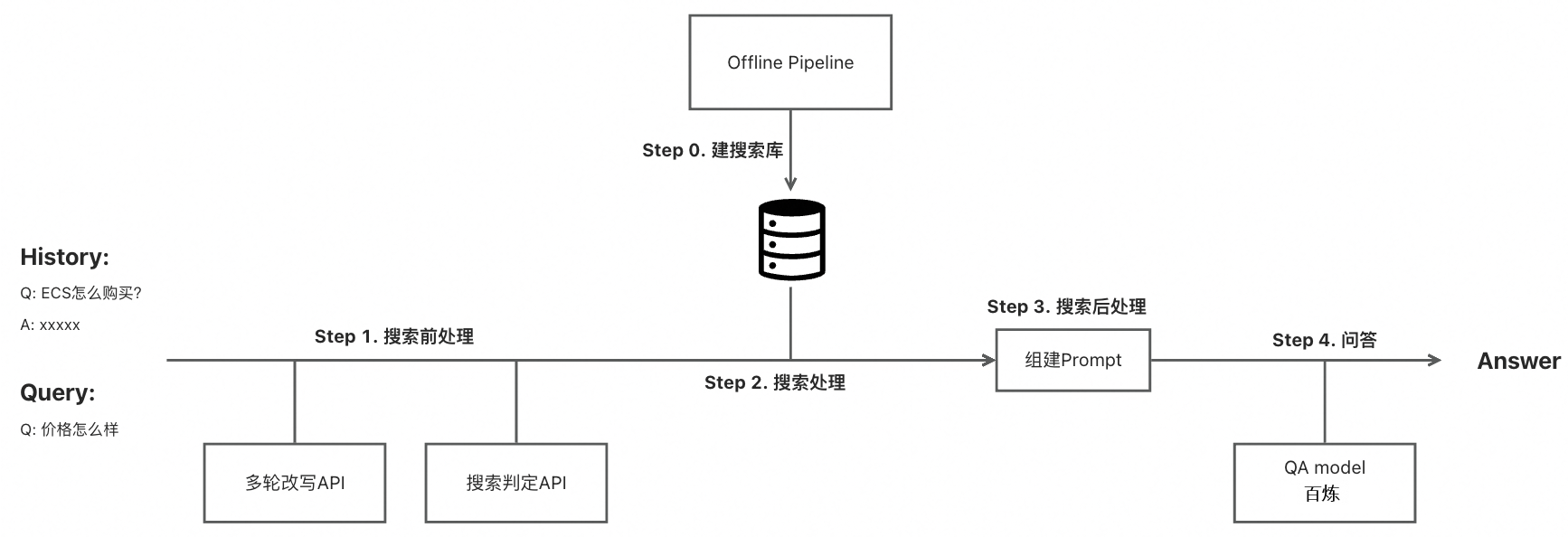
接下来可以这两种能力相结合,组建一个完整的知识库在线问答的链路,流程如下图所示:
分阶段样例说明
Step1. 搜索前处理-多轮搜索意图判定
搜索前处理的输入是问答的历史轮问答信息(History)和当前轮的原始输入(Query),输出是将要传入搜索服务的改写后Query,因此可以通过调用多轮改写API来完成。同时真实场景中还存在一些并不需要搜索的特殊情况(比如"你好" 这种query,不需要进行知识库的搜索),这类问题可以通过搜索判定API来完成。因此,我们先进行多轮改写,总结多轮query的核心意图,搜索判定模块对改写后的query进行分类。
对应的API细节可以查看文档:开发参考_自然语言处理(NLP)-阿里云帮助中心,以下是API调用示例。
搜索判定API功能和调用示例
功能简述:在很多场景中,我们不一定需要搜索引擎,大模型就能回答的很好,但也有很多像开放域实时问题没有搜索引擎就无法回答。因此,搜索判定模块的目标是判定什么时候需要进行检索,从而提高RAG的利用效率,提高整体效果。
调用示例:
import os
import json
from alibabacloud_alinlp20200629 import client, models
from alibabacloud_tea_openapi import models as api_models
# 创建一个搜索client
config = api_models.Config(
access_key_id=os.environ['ALIBABA_CLOUD_ACCESS_KEY_ID'],
access_key_secret=os.environ['ALIBABA_CLOUD_ACCESS_KEY_SECRET'],
region_id="cn-beijing")
nlp_client = client.Client(config)
# 配置一个搜索判定request
request = models.PostISRetrieveRouterRequest()
# 配置并请求搜索判定服务
request.algorithm = 'retrieve_router'
input_str = '{\"query\": \"搜索判定测试\"}'
request.input = json.loads(input_str)
response = nlp_client.post_isretrieve_router(request)
# 打印搜索判定结果
print(json.dumps(response.body.data, ensure_ascii=False))
多轮query改写API功能和调用示例
功能简述:在与用户进行多轮对话互动的场景里,搜索引擎通常不能直接处理用户的查询和对话记录。因此,在RAG流程中,结合对话历史的理解和重新构思用户的查询至关重要。多轮查询的改写可以显著提升RAG的检索效率、内容生成质量以及用户体验,从而增强RAG的整体表现。
调用示例:
import os
import json
from alibabacloud_alinlp20200629 import client, models
from alibabacloud_tea_openapi import models as api_models
# 创建一个搜索client
config = api_models.Config(
access_key_id=os.environ['ALIBABA_CLOUD_ACCESS_KEY_ID'],
access_key_secret=os.environ['ALIBABA_CLOUD_ACCESS_KEY_SECRET'],
region_id="cn-beijing")
nlp_client = client.Client(config)
# 配置一个多轮query改写request
request = models.PostISConvRewriterRequest()
# 配置并请求多轮query改写服务
request.algorithm = 'conversation_rewriter'
request.model = 'dashscope-conv-rewrite-1.8b'
input_str = '{\n' + \
' \"query\": \"贵吗\",\n' + \
' \"history\": [\n' + \
' {\n' + \
' \"role\": \"user\",\n' + \
' \"content\": \"什么是黑梓木\"\n' + \
' },\n' + \
' {\n' + \
' \"role\": \"assistant\",\n' + \
' \"content\": \"黑梓木是一种用材最广的木头,在我国东北地区也称之为臭梧桐,分布比较广泛,产量也大,很多装饰部件都会用黑梓木制作。\"\n' + \
' }\n' + \
' ]\n' + \
'}'
request.input = json.loads(input_str)
response = nlp_client.post_isconv_rewriter(request)
# 打印多轮query改写结果
print(json.dumps(response.body.data, ensure_ascii=False))
Step2. 搜索处理
from alibabacloud_alinlp20200629 import client, models
from alibabacloud_tea_openapi import models as api_models
# 创建一个搜索client
config = api_models.Config(
access_key_id=os.environ['ALIBABA_CLOUD_ACCESS_KEY_ID'],
access_key_secret=os.environ['ALIBABA_CLOUD_ACCESS_KEY_SECRET'],
region_id="cn-beijing")
search_client = client.Client(config)
# 配置一个搜索request
request = models.PostMSSearchEnhanceRequest()
request.service_id = YOUR_SERVICE_ID # 控制台搭建完后拿到service_id
# 线上query
query = '灯泡相机TD3B的镜头焦距是多少'
# 请求搜索服务
request.uq = query
request.rows = 5 # 设置搜索参数:返回文档数
response = search_client.post_mssearch_enhance(request)
search_results = response.body.data["data"]["docs"]
print(search_results)
Step3. 搜索后处理
为了使LLM最终的问答效果更好,在调用搜索服务拿到搜索结果之后通常还需要做一些后处理。最常见的后处理是将搜索结果放入prompt中,并采用一些思维链(Chain of Thought)来提升LLM的回答效果。
结合搜索结果的prompt构建样例代码
通过对搜索服务response的数据进行解析可以得到一个搜索结果的列表,列表中的每个元素搜是一个相关的文档片段,在预设的格式中每个文档片段至少会包含“title”和“content”两个字段来保存文本信息,可以通过以下的Python原生代码构建用于LLM回答的prompt和message:
# 搜索结果样例
search_results = [
{"title": "搜索结果的title文本。", "content": "搜索结果的content文本。"}
]
# 将搜索结果组建成prompt/messages
system = f'You are a helpful assistant.\n\n'
messages = [{'role': 'system', 'content': system}]
if len(search_results) != 0:
text_result_str = '\n\n'.join([f'{x.get("title", "")}: {x.get("content", "")}' for x in search_results]).strip()
ctx = f'\n\n以下信息来自你的知识库,可能会对回答某些问题有帮助:\n\n{text_result_str}\n\n请记住这些知识库的信息。'
messages.append({'role': 'user', 'content': ctx})
a = '好的,我已经记住这些知识库的信息。有什么我可以帮助你解答的问题吗?'
messages.append({'role': 'assistant', 'content': a})
messages.append({'role': 'user', 'content': query})
print(messages)
对于时间敏感的问题还可以加上当前时间的信息来组成prompt:
import datetime
def get_current_date_str() -> str:
beijing_time = datetime.datetime.utcnow() + datetime.timedelta(hours=8)
cur_time = beijing_time.timetuple()
date_str = f'当前时间:{cur_time.tm_year}年{cur_time.tm_mon}月{cur_time.tm_mday}日,星期'
date_str += ['一', '二', '三', '四', '五', '六', '日'][cur_time.tm_wday]
date_str += '。'
return date_str
system = f'You are a helpful assistant.\n\n{date_str}'
messages = [{'role': 'system', 'content': system}]Step4. 调用阿里云百炼做问答
完成prompt的组装之后可以调用dashscope的SDK来做问答
import dashscope
# 请求dashscope做QA
response = dashscope.Generation.call(
model=dashscope.Generation.Models.qwen_max,
prompt=prompt)
if response.status_code == 200:
print(response.output) # The output text
print(response.usage) # The usage information
else:
print(response.code) # The error code.
print(response.message) # The error message.
全链路样例代码
把以上全链路的代码整合到一起有如下实践:
配置环境变量
export ALIBABA_CLOUD_ACCESS_KEY_ID=YOUR_ALIBABA_CLOUD_ACCESS_KEY_ID
export ALIBABA_CLOUD_ACCESS_KEY_SECRET=YOUR_ALIBABA_CLOUD_ACCESS_KEY_SECRET
export DASHSCOPE_API_KEY=YOUR_DASHSCOPE_API_KEY单轮问答Python示例代码
import datetime
import dashscope
from alibabacloud_alinlp20200629 import client, models
from alibabacloud_tea_openapi import models as api_models
# 创建一个搜索client
config = api_models.Config(
access_key_id=os.environ['ALIBABA_CLOUD_ACCESS_KEY_ID'],
access_key_secret=os.environ['ALIBABA_CLOUD_ACCESS_KEY_SECRET'],
region_id="cn-beijing")
search_client = client.Client(config)
# 配置一个搜索request
request = models.PostMSSearchEnhanceRequest()
request.service_id = YOUR_SERVICE_ID # 控制台搭建完后拿到service_id
# 线上query
query = '灯泡相机TD3B的镜头焦距是多少'
# 请求搜索服务
request.uq = query
request.rows = 5 # 设置搜索参数:返回文档数
response = search_client.post_mssearch_enhance(request)
search_results = response.body.data["data"]["docs"]
# 将搜索结果组建成prompt/messages
def get_current_date_str() -> str:
beijing_time = datetime.datetime.utcnow() + datetime.timedelta(hours=8)
cur_time = beijing_time.timetuple()
date_str = f'当前时间:{cur_time.tm_year}年{cur_time.tm_mon}月{cur_time.tm_mday}日,星期'
date_str += ['一', '二', '三', '四', '五', '六', '日'][cur_time.tm_wday]
date_str += '。'
return date_str
system = f'You are a helpful assistant.\n\n{date_str}'
messages = [{'role': 'system', 'content': system}]
if len(search_results) != 0:
text_result_str = '\n\n'.join([f'{x.get("title", "")}: {x.get("content", "")}' for x in search_results]).strip()
ctx = f'\n\n以下信息来自你的知识库,可能会对回答某些问题有帮助:\n\n{text_result_str}\n\n请记住这些知识库的信息。'
messages.append({'role': 'user', 'content': ctx})
a = '好的,我已经记住这些知识库的信息。有什么我可以帮助你解答的问题吗?'
messages.append({'role': 'assistant', 'content': a})
messages.append({'role': 'user', 'content': query})
# 请求dashscope做QA
response = dashscope.Generation.call(
model=dashscope.Generation.Models.qwen_max,
messages=messages,
result_format='message')
if response.status_code == 200:
print(response.output) # The output text
print(response.usage) # The usage information
else:
print(response.code) # The error code.
print(response.message) # The error message.
多轮问答Python示例代码
import json
import dashscope
from alibabacloud_alinlp20200629 import client, models
from alibabacloud_tea_openapi import models as api_models
# 创建一个搜索client
config = api_models.Config(
access_key_id=os.environ['ALIBABA_CLOUD_ACCESS_KEY_ID'],
access_key_secret=os.environ['ALIBABA_CLOUD_ACCESS_KEY_SECRET'],
region_id="cn-beijing")
aliyun_client = client.Client(config)
# query & history
query = '那镜头光圈呢?'
history = [
{
"role": "user",
"content": "灯泡相机TD3B的镜头焦距是多少"
},
{
"role": "assistant",
"content": "灯泡相机TD3B的镜头焦距是2.8毫米。"
}
]
# 多轮改写
# 配置并请求多轮query改写服务
rewrite_request = models.PostISConvRewriterRequest()
rewrite_request.algorithm = 'conversation_rewriter'
rewrite_request.model = 'dashscope-conv-rewrite-1.8b'
rewrite_request.input = {
"query": query,
"history": history
}
rewrite_response = aliyun_client.post_isconv_rewriter(rewrite_request)
# 配置一个搜索request
search_request = models.PostMSSearchEnhanceRequest()
search_request.service_id = 1007 # 控制台搭建完后拿到
# 请求搜索并打印结果
search_request.uq = query
search_request.rows = 5 # 返回文档数
response = aliyun_client.post_mssearch_enhance(search_request)
search_results = response.body.data["data"]["docs"]
# 构建prompt
prompt = f'你是一个问答机器人助理,你可以回答一些问题,但你只能回答一些你所知道的问题。'
if len(search_results) != 0:
text_result_str = '\n\n'.join([f'{x.get("title", "")}: {x.get("content", "")}' for x in search_results]).strip()
prompt += f'\n\n以下信息来自你的知识库,可能会对回答某些问题有帮助:\n\n{text_result_str}\n\n请记住这些知识库的信息。'
prompt += f'\n\n请回答问题:{query}'
# 请求LLM
response = dashscope.Generation.call(
model=dashscope.Generation.Models.qwen_max,
prompt=prompt
)
# 打印结果
if response.status_code == 200:
print(response.output) # The output text
print(response.usage) # The usage information
else:
print(response.code) # The error code.
print(response.message) # The error message.4.补充说明
千寻大模型搜索服务管控台可以提供知识库问答服务,其搭建流程与搜索增强服务一致,具体流程参考前述第二章的千寻大模型搜索服务搭建(在离线算法处理及索引构建过程中需要配置大模型引用字段)。搭建完成后可以按照下述步骤进行服务测试:
-
进入服务管理,找到创建的服务,点击服务测试。
-
进行LLM配置和搜索配置,具体见产品文档中的多轮对话搜索。
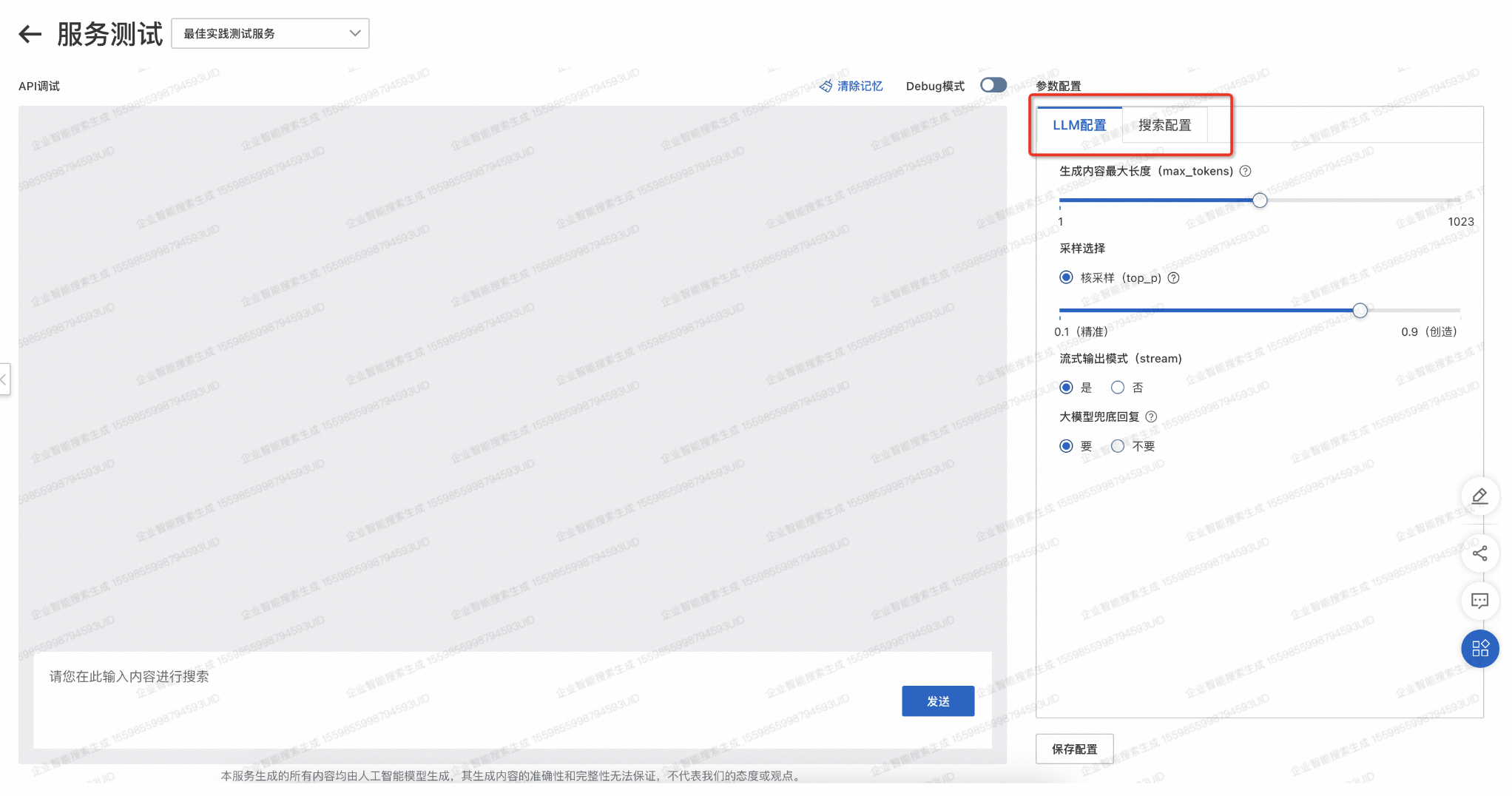
-
输入内容进行搜索。
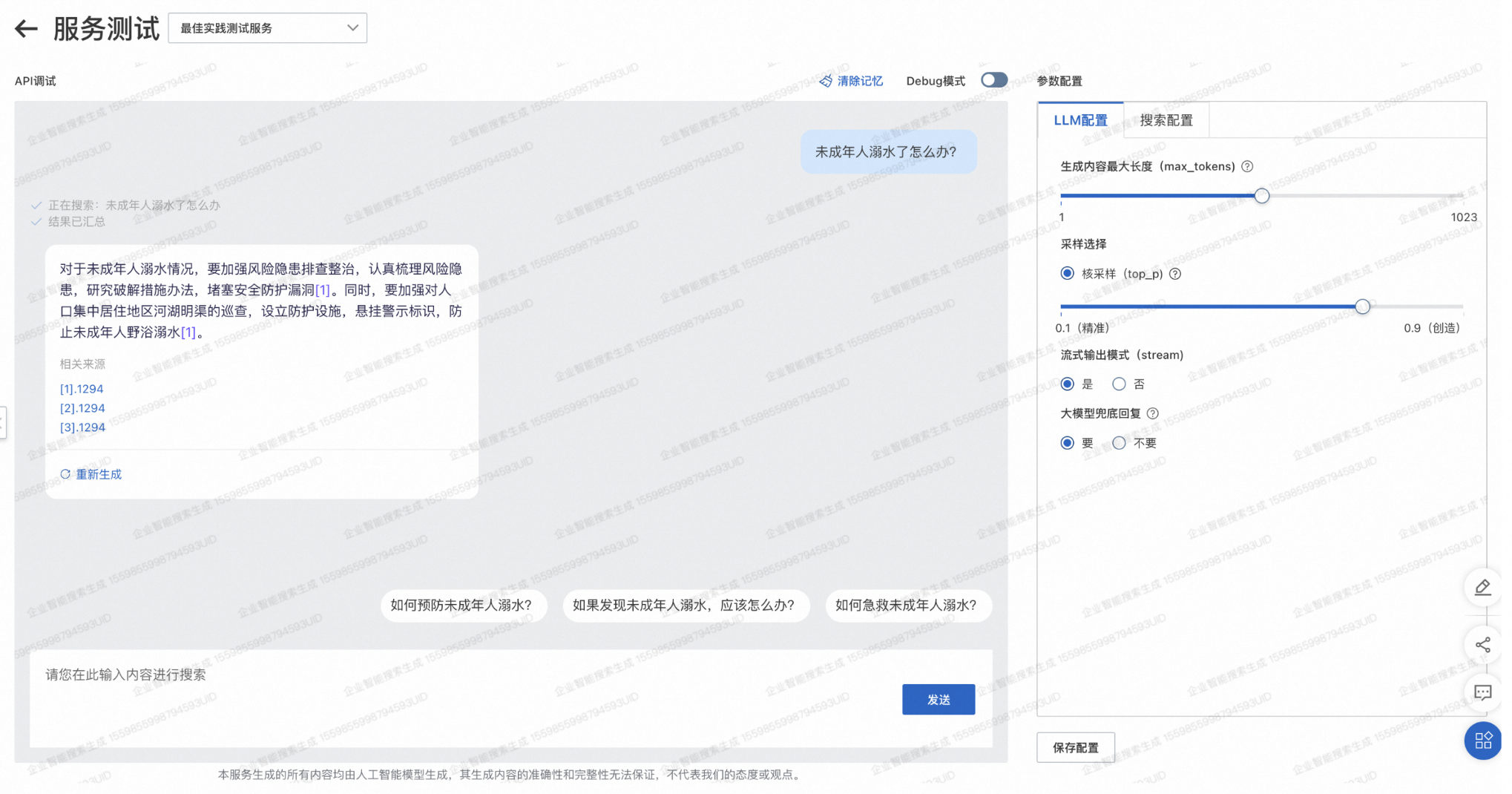
-
具体API调用参考产品文档Java SDK。
5. 联系我们
扫码加入钉钉群:
