
数据集成目前支持将DataHub、Hologres等源头的数据单表实时同步至Kafka。实时ETL同步任务根据来源Hologres表结构对目标Kafka的Topic进行初始化,将Hologres数据实时同步至Kafka以供消费。本文为您介绍如何配置Hologres单表实时同步到Kafka。
使用限制
Kafka的版本需在0.10.2至3.6.0之间。
Hologres的版本要求必须为2.1及以上。
不支持Hologres分区表的增量同步。
不支持Hologres表DDL变更消息同步。
Hologres增量同步支持的数据类型包括:INTEGER、BIGINT、TEXT、CHAR(n)、VARCHAR(n)、REAL、JSON、SERIAL、OID、INT4[]、INT8[]、FLOAT8[]、BOOLEAN[]、TEXT[]、JSONB。
需开启源端的Hologres数据库的表Hologres Binlog,详情可参见订阅Hologres Binlog。
前提条件
已购买Serverless资源组。
已创建Hologres和Kafka数据源,详情请参见创建数据集成数据源。
已完成资源组与数据源间的网络连通,详情请参见网络连通方案。
操作步骤
一、选择同步任务类型
进入数据集成页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据集成。
在左侧导航栏单击同步任务,然后在页面顶部单击新建同步任务,进入同步任务的创建页面,配置如下基本信息。
数据来源和去向:
Hologres→Kafka新任务名称:自定义同步任务名称。
同步类型:
单表实时。同步步骤:选择
全量同步。
二、网络与资源配置
在网络与资源配置区域,选择同步任务所使用的资源组。您可以为该任务分配任务资源占用CU数。
来源数据源选择已添加的
Hologres数据源,去向数据源选择已添加的Kafka数据源后,单击测试连通性。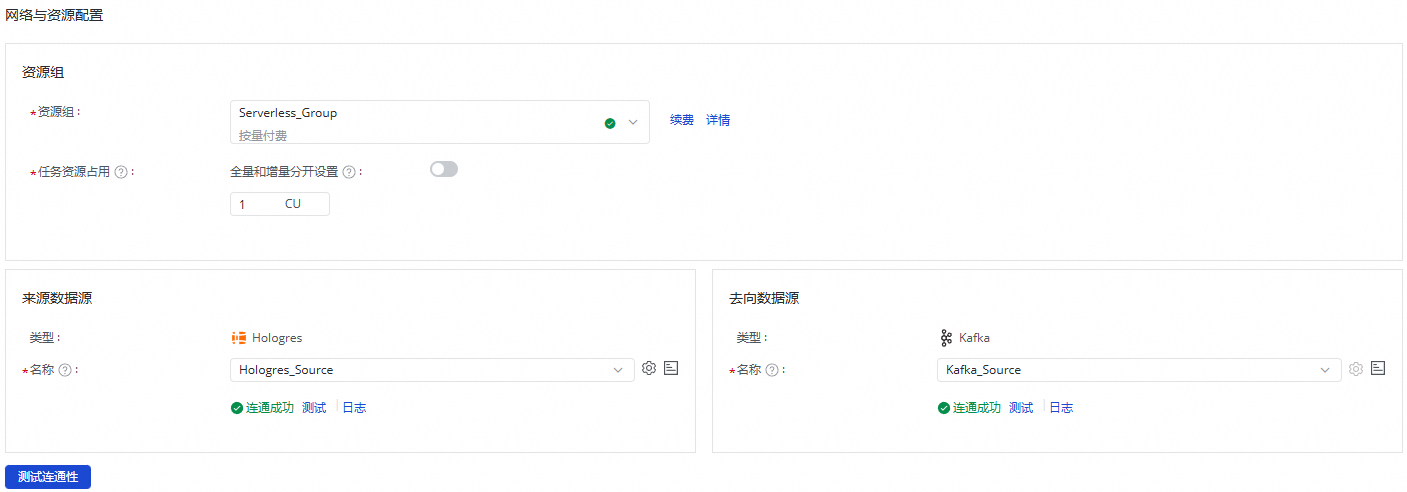
确保来源数据源与去向数据源均连通成功后,单击下一步。
三、配置同步链路
1、配置Hologres来源
在页面上方单击数据来源Hologres,编辑Holo来源信息。

在Holo来源信息区域,选择要读取的Hologres表所在的Schema,以及来源表。
单击右上角的数据采样。
在数据输出预览对话框中指定好采样条数,单击开始采集按钮,可以对指定的Hologres进行数据采样,预览Hologres中的数据,为后续数据处理节点的数据预览和可视化配置提供输入。
2、配置Kafka去向信息
在页面上方单击数据去向Kafka,编辑Kafka去向信息。

在Kafka去向信息区域,选择要写入的Kafka主题(Topic)。
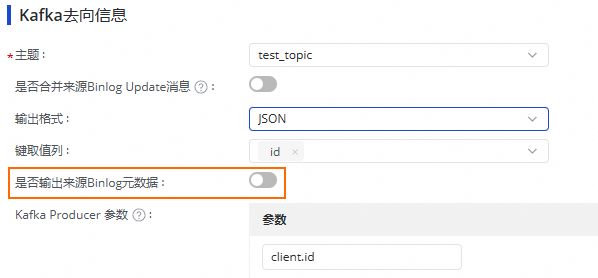
按需设置是否合并来源Binglog Update消息,开启后会将源端Binlog的一个Update动作对应的两条Update消息合并为一条消息写入。
设置输出格式、键取值列以及Kafka Producer参数。
输出格式:确认写入Kafka记录的Value内容格式,支持Canal CDC和JSON。的详细信息,请参见附录:输出格式说明。
键取值列:选取的是源端列,对应列值会序列化为字符串后,用逗号拼接作为写入Kafka Topic中记录的key。
说明列值序列化规则与JSON中的Hologres中列类型序列化规则说明一致。
Kafka Topic中记录的Key值决定写入的分区,相同Key值写入同一分区,为了保证下游消费Kafka Topic时数据能够保持顺序,建议选择Hologres表主键作为键取值列。
如果不选择任何源侧列作为键取值列,Kafka Topic 中记录的Key值为null,会导致Kafka写入分区呈随机写入。
Kafka Producer参数:是影响写入一致性、稳定性和异常处理行为的参数,一般情况默认配置即可,如有定制化需求可以指定特定参数,各个Kafka集群版本支持的Producer参数可参考Kafka官方文档。
四、报警配置
为避免任务出错导致业务数据同步延迟,您可以对同步任务设置报警策略。
单击页面右上方的报警配置,进入实时子任务报警设置页面。
单击新增报警,配置报警规则。
说明此处定义的报警规则,将对该任务产生的实时同步子任务生效,您可在任务配置完成后,进入实时同步任务运行与管理界面查看并修改该实时同步子任务的监控报警规则。
管理报警规则。
对于已创建的报警规则,您可以通过报警开关控制报警规则是否开启,同时,您可以根据报警级别将报警发送给不同的人员。
五、高级参数配置
同步任务提供部分参数可供修改,您可以按需对该参数值进行修改。
请在完全了解对应参数含义的情况下再进行修改,以免产生不可预料的错误或者数据质量问题。
单击界面右上方的高级参数配置,进入高级参数配置页面。
在高级参数配置页面修改相关参数值。
六、资源组配置
您可以单击界面右上方的资源组配置,查看并切换当前的任务所使用的资源组。
七、执行同步任务
完成所有配置后,单击页面底部的完成配置。
在界面,找到已创建的同步任务,单击操作列的启动。
单击任务列表中对应任务的名称/ID,查看任务的详细执行过程。
同步任务运维
查看任务运行状态
创建完成同步任务后,您可以在同步任务页面查看当前已创建的同步任务列表及各个同步任务的基本信息。

您可以在操作列启动或停止同步任务,在更多中可以对同步任务进行编辑、查看等操作。
已启动的任务您可以在执行概况中看到任务运行的基本情况,也可以单击对应的概况区域查看执行详情。
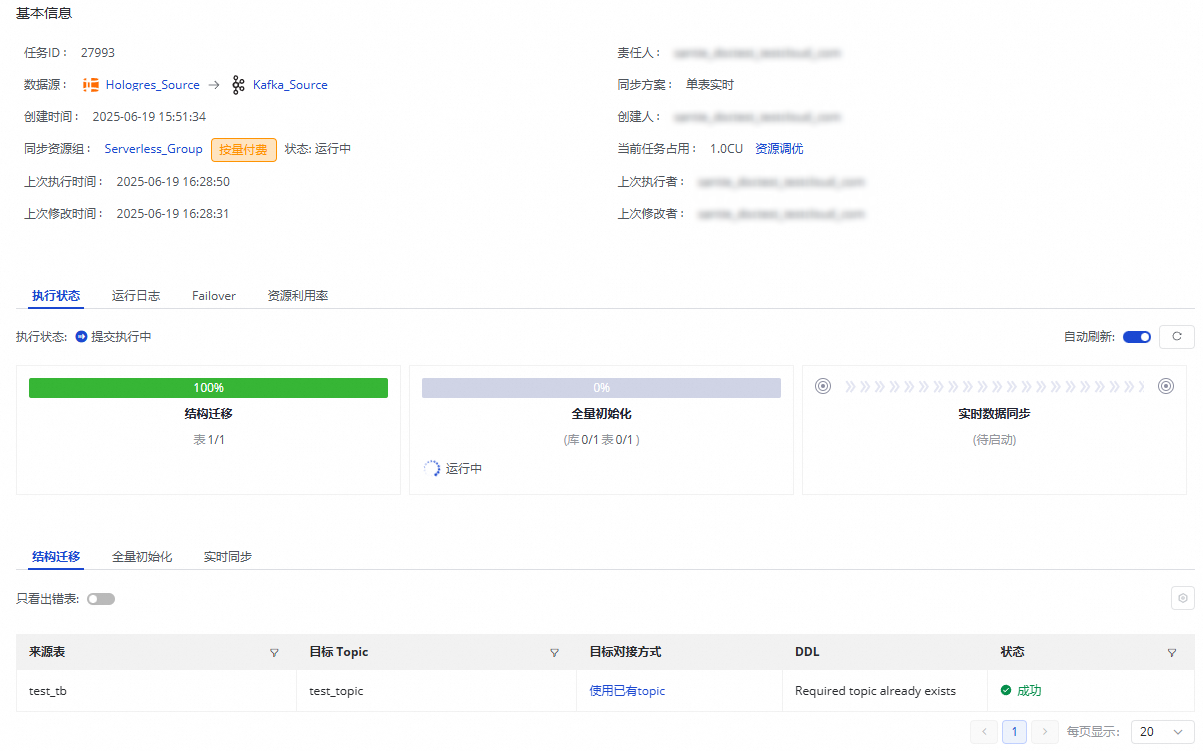
Hologres到Kafka的单表实时同步任务分为三个步骤:
结构迁移:包含目标表的创建方式(已有表或自动建表),如果是自动建表,将会为您展示建表的DDL。
全量初始化:如果您的任务同步步骤选择了全量同步,此处将展示全量初始化进度。
实时数据同步:包含实时同步的统计信息,包含实时的读写流量、脏数据、Failover和运行日志。
任务重跑
在某些特殊情况下,如果需要修改同步字段、调整目标表字段或表名信息时,您还可以单击同步任务操作列的重跑,系统会将调整的字段、变更的目标包等信息进行同步,之前同步过未修改的表将不会再进行同步。
不修改任务配置,直接单击重跑操作,重新运行一次同步任务。
编辑任务,进行修改操作后,单击完成配置。此时任务的操作会变成应用更新,单击应用更新会直接触发修改后的任务重跑。实时同步任务会按照新的配置运行。
附录:输出格式说明
Canal CDC
Canal CDC是Alibaba Canal定义的一种CDC数据格式。
Json
Json是将Hologres Binlog中的变更记录,以列表名作为Key,将列表的数据内容序列化为字符串后作为value,组装为JSON格式字符串写入Kafka Topic中。
Hologres中字段类型序列化说明
Hologres字段类型 | 写入Kafka序列化结果 |
bit | 不支持,任务启动报错。 |
inet | 不支持,任务启动报错。 |
interval | 不支持,任务启动报错。 |
money | 不支持,任务启动报错。 |
oid | 不支持,任务启动报错。 |
timetz | 不支持,任务启动报错。 |
uuid | 不支持,任务启动报错。 |
varbit | 不支持,任务启动报错。 |
jsonb | 不支持,数据写入后报错binlog解析错误。 |
bigint | 数字字符串:"2"。 |
decimal(38,18) | 小数位数跟精度定义一致的数字字符串,"1.234560000000000000"。 |
decimal(38,0) | 小数位数跟精度定义一致的数字字符串,"2"。 |
boolean | "true"/"false"。 |
date | yyyy-MM-dd格式日期字符串:"2024-02-02"。 |
float4/float8/double | 数值字符串,转换后与Holo查询结果一致,不会补零:"1.24"。 |
interger/smallint | 数字字符串:"2"。 |
json | json字符串:"{\"a\":2}"。 |
text/varchar | utf8编码字符串:"text"。 |
timestamp | 精确到微秒的时间字符串
|
timestamp with time zone | 精确到毫秒的时间字符串:"2020-01-01 09:01:01.123"。
|
bigserial | 数字字符串:"2"。 |
bytea | base64编码字符串:"ASDB=="。 |
char | 定长字符串:"char"。 |
serial | 数字字符串:"2" |
time | 精确到微秒时间字符串。
|
int4[]/int8[] | 字符串数组:["1","2","3","4"]。 |
float4[]/float8[] | 字符串数组:["1.23","2.34"]。 |
boolean[] | 字符串数组:["true","false"]。 |
text[] | 字符串数组:["a","b"]。 |
注意时间类型的字段在序列化时,若不在[0001-01-01,9999-12-31]范围内的数据,序列化结果与Hologres中的查询结果会有差异。
元数据字段内容说明
与Canal CDC格式一样,Hologres Binlog三种类型变更记录插入、更新和删除中,一次更新会生成两条JSON格式记录写入Kafka Topic中,一条对应更新前的数据内容,一条对应更新后的数据内容。
JSON格式可以选择是否输出来源Binlog元数据,如果勾选,在JSON格式字符串中会加入一些描述Hologres Binlog变更记录属性的字段。
字段名 | 字段值含义 |
_sequence_id_ | Hologres Binlog中记录的唯一标识,对于全量同步数据填充null。 |
_operation_type_ | DML变更类型,可选值为"I"/"U"/"D",对应插入、更新和删除,对于全量同步数据填充"I"。 |
_execute_time_ | 13位毫秒时间戳。
|
_before_image_ |
|
_after_image_ |
|