
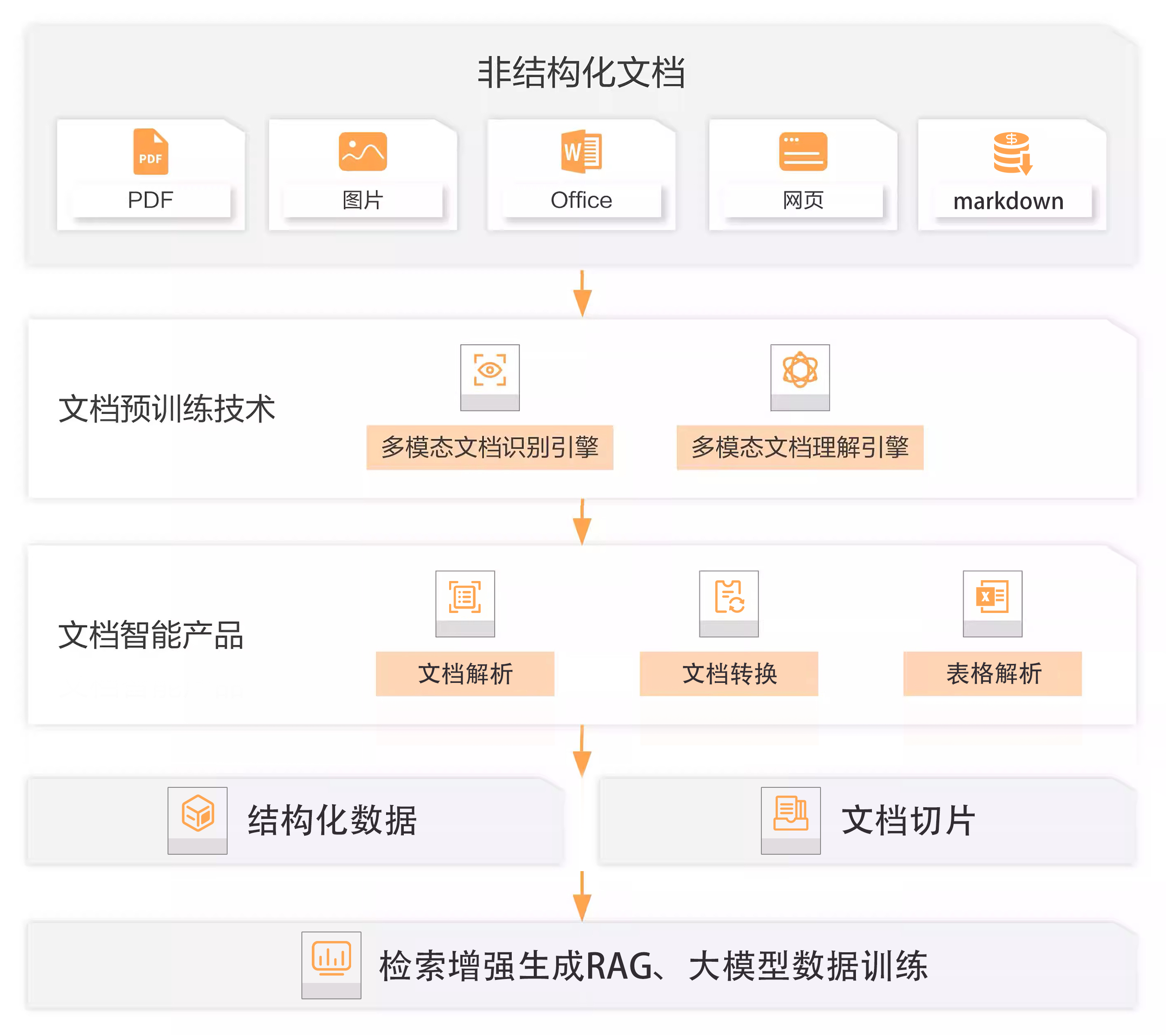
文档理解是对各类文档和表格进行结构化识别与理解,返回层级树和版面分析等相关信息。本文介绍文档理解的功能特性、功能优势和应用场景。
功能特性
文档解析(大模型版)
对各类的文档,包括图文文档(含扫描版和电子版)、音视频文档进行解析,从文档中提取出层级树和版面信息,支持输出Markdown格式。可作为大模型预训练、RAG的文档预处理链路,提供高质量、高精度的文档解析服务,能够帮助企业高效地进行大模型应用的场景建设。详情请参见文档解析(大模型版)。
电子文档解析
适用于纯电子文档的解析,从电子文档半结构化内容中解析出所包含的结构化对象,从文档中提取出逻辑层级结构,支持输出Markdown格式。详情请参见电子文档解析。
文档智能解析
进行通用文档解析,从文档中提取出逻辑层级结构、文本内容、表格内容、Key-Value键值字段、样式信息等。基于对文档的内容信息、版面信息和逻辑信息的分析理解,以结构化数据的形态输出抽取结果。详情请参见文档智能解析。
三者能力比对
版本 | 支持格式 | 输出 | 特点 | ||
文档解析(大模型版) | 支持市面上绝大部分格式的文档:
|
| 功能较全,推荐使用 | 效果最好 | 速度较快 |
电子文档解析 | 纯电子解析,支持格式:
|
| 功能中等 | 效果中等 | 速度最快 |
文档智能解析 | 支持格式:
|
| 功能较全 | 效果较好 | 速度较快 |
表格智能解析
进行通用表格解析,从表格中提取出表格样式、表格内容、文本KV、表格KV等。基于对表格的内容信息、版面信息和逻辑信息的分析理解,以结构化数据的形态输出抽取结果。详情请参见表格智能解析。
文档抽取
进行文档关键信息抽取,对各种类型的文档和表格中的关键信息进行智能化抽取,返回Key-Value内容。既包括文本段落中的KV字段,也包括表格中的KV字段。详情请参见文档抽取。
应用场景
大模型训练
支持对PDF、Word、Markdown等多种文档格式的处理,返回文档的层级结构,并结合文档语义信息,处理成文档切片后用于大模型训练,方便下游结合大模型开发智能问答等应用。
检索增强生成RAG
可以精准识别并解析包括企业日常办公中常见的Office文档(Word/Excel/PPT)、PDF、图片等在内的主流文件类型,返回文档的样式、版面信息和层级树结构,从而为RAG输入高精准度、高连贯语义的切块(Chunk),保障了整个RAG方案的基础效果。
办公文档处理
对各类办公文档和表单进行智能化处理,实现文档的结构化信息提取,提升办公场景下的生产力。