
本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
Hadoop是由Apache基金会使用Java语言开发的分布式开源软件框架,本文介绍如何在Linux操作系统的ECS实例上快速搭建Hadoop分布式和伪分布式环境。
背景信息
Apache Hadoop软件库是一个框架,它允许通过简单的编程模型在由多台计算机组成的集群上对大规模数据集进行分布式处理。该框架设计能够从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储能力。Hadoop并不依赖硬件来实现高可用性,而是将其自身设计为能够在应用层检测并处理故障,因此能在可能各自存在故障风险的计算机集群之上,提供高度可用的服务。
Hadoop的核心部件是HDFS(Hadoop Distributed File System)和MapReduce:
HDFS:是一个分布式文件系统,可用于应用程序数据的分布式存储和读取。
MapReduce:是一个分布式计算框架,MapReduce的核心思想是把计算任务分配给集群内的服务器执行。通过对计算任务的拆分(Map计算和Reduce计算),再根据任务调度器(JobTracker)对任务进行分布式计算。
特性 | 伪分布式模式 | 完全分布式模式 |
节点数量 | 单节点(所有服务在同一台机器上)。 | 多节点(服务分布在多台机器上)。 |
资源利用率 | 使用单台机器的资源。 | 充分利用多台机器的计算和存储资源。 |
容错性 | 容错性低,单点故障会导致整个集群不可用。 | 容错性高,支持数据复制和高可用性配置。 |
应用场景 |
|
|
快速部署
您可以单击一键运行进入Terraform Explorer查看并执行Terraform代码,从而实现自动化地在ECS实例中搭建Hadoop环境。
前提条件
搭建Hadoop环境时,已有的ECS实例必须满足以下条件:
环境 | 要求 | |
实例 | 伪分布式 | 1台实例 |
分布式 | 3台及以上实例 说明 建议您将实例加入到高可用策略的部署集中,可以提高应用的高可用性和容灾能力,便于Hadoop集群的管理。 | |
操作系统 | Linux | |
公网IP | 实例已分配公网IP地址或绑定弹性公网IP(EIP)。 | |
实例安全组 | 放行22、443、8088(Hadoop YARN默认的Web UI端口)、9870(Hadoop NameNode默认的Web UI端口)。 说明 如果部署分布式环境,还需放行Hadoop Secondary Namenode的自定义Web UI端口,现定义端口为9868。 具体操作,请参见管理安全组规则。 | |
Java开发工具包(JDK) 本文使用的版本为Hadoop 3.2.4和Java 8,如您使用其他版本,请参考Hadoop官网指南。更多信息,请参见Hadoop Java Versions。 | Hadoop版本 | Java版本 |
Hadoop 3.3 | Java 8和Java 11 | |
Hadoop 3.0.x~3.2.x | Java 8 | |
Hadoop 2.7.x~2.10.x | Java 7和Java 8 | |
操作步骤
分布式
在部署Hadoop前需对节点进行规划。以三台实例为例,hadoop001节点为master节点,hadoop002和hadoop003节点为worker节点。
功能组件 | hadoop001 | hadoop002 | hadoop003 |
HDFS |
| DataNode |
|
YARN | NodeManager |
| NodeManager |
步骤一:安装JDK。
所有节点均需安装JDK环境。
以普通用户远程连接已创建的ECS实例。
具体操作,请参见使用Workbench工具以SSH协议登录Linux实例。
重要出于系统安全和稳定性考虑,Hadoop官方不推荐使用root用户来启动Hadoop服务,直接使用root用户会因为权限问题无法启动Hadoop。您可以通过非root用户身份启动Hadoop服务,例如
ecs-user用户等。执行以下命令,下载JDK 1.8安装包。
wget https://download.java.net/openjdk/jdk8u41/ri/openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz执行以下命令,解压下载的JDK 1.8安装包。
tar -zxvf openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz执行以下命令,移动并重命名JDK安装包。
本示例中将JDK安装包重命名为
java8,您可以根据需要使用其他名称。sudo mv java-se-8u41-ri/ /usr/java8执行以下命令,配置Java环境变量。
如果您将JDK安装包重新命名为其他名称,需将以下命令中的
java8替换为实际的名称。sudo sh -c "echo 'export JAVA_HOME=/usr/java8' >> /etc/profile" sudo sh -c 'echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> /etc/profile' source /etc/profile执行以下命令,查看JDK是否成功安装。
java -version返回如下信息,表示JDK已安装成功。
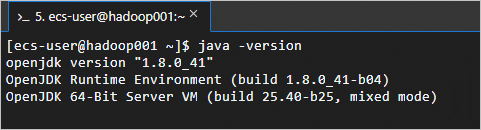
步骤二:配置SSH免密登录。
所有实例均需执行此操作。
通过设置SSH免密登录,可以让这些节点之间实现无缝连接,无需每次都输入密码验证身份,从而使得Hadoop集群的管理和维护变得更加便捷高效。
配置主机名和通信。
sudo vim /etc/hosts添加所有实例的信息
<主私网IP 主机名>到/etc/hosts文件中。如下:主私网IP hadoop001 主私网IP hadoop002 主私网IP hadoop003执行以下命令,创建公钥和私钥。
ssh-keygen -t rsa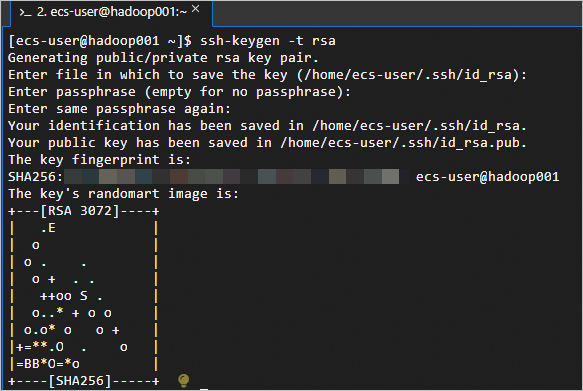
执行
ssh-copy-id <主机名>,替换主机名为正确的名称。如下:hadoop001上依次执行ssh-copy-id hadoop001、ssh-copy-id hadoop002、ssh-copy-id hadoop003。执行每一个命令后需要输入yes和对应ECS实例的ID密码。ssh-copy-id hadoop001 ssh-copy-id hadoop002 ssh-copy-id hadoop003返回如下信息,表示免密登录配置成功。
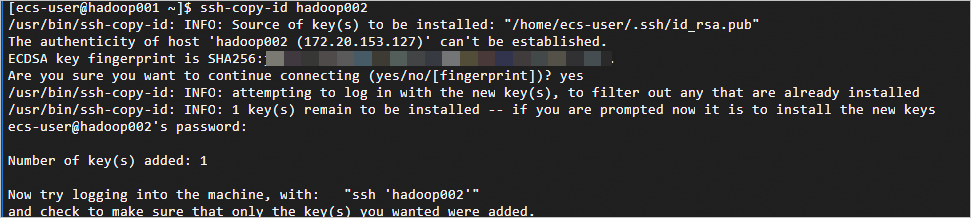
步骤三:安装Hadoop。
以下命令需在所有实例中执行。
执行以下命令,下载Hadoop安装包。
wget http://mirrors.cloud.aliyuncs.com/apache/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz执行以下命令,将Hadoop安装包解压至
/opt/hadoop。sudo tar -zxvf hadoop-3.2.4.tar.gz -C /opt/ sudo mv /opt/hadoop-3.2.4 /opt/hadoop执行以下命令,配置Hadoop环境变量。
sudo sh -c "echo 'export HADOOP_HOME=/opt/hadoop' >> /etc/profile" sudo sh -c "echo 'export PATH=\$PATH:/opt/hadoop/bin' >> /etc/profile" sudo sh -c "echo 'export PATH=\$PATH:/opt/hadoop/sbin' >> /etc/profile" source /etc/profile执行以下命令,修改配置文件
yarn-env.sh和hadoop-env.sh。sudo sh -c 'echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh' sudo sh -c 'echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh'执行以下命令,测试Hadoop是否安装成功。
hadoop version返回如下信息,表示Hadoop已安装成功。
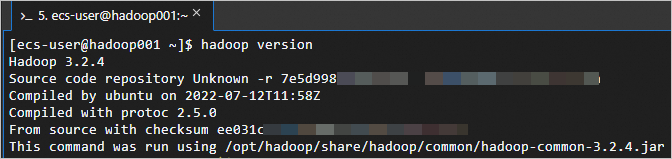
步骤四:配置Hadoop。
在所有节点上修改Hadoop的配置文件。
修改Hadoop配置文件
core-site.xml。执行以下命令,进入编辑页面。
sudo vim /opt/hadoop/etc/hadoop/core-site.xml在
<configuration></configuration>节点内,插入如下内容。<!--指定namenode的地址--> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop001:8020</value> </property> <!--用来指定使用hadoop时产生文件的存放目录--> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop/data</value> </property> <!--配置HDFS网页登录使用的静态用户为hadoop--> <property> <name>hadoop.http.staticuser.user</name> <value>hadoop</value> </property>
修改Hadoop配置文件
hdfs-site.xml。执行以下命令,进入编辑页面。
sudo vim /opt/hadoop/etc/hadoop/hdfs-site.xml在
<configuration></configuration>节点内,插入如下内容。<!-- namenode web 端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>hadoop001:9870</value> </property> <!-- secondary namenode web 端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop003:9868</value> </property>
修改Hadoop配置文件
yarn-site.xml。执行以下命令,进入编辑页面。
sudo vim /opt/hadoop/etc/hadoop/yarn-site.xml在
<configuration></configuration>节点内,插入如下内容。<!--NodeManager获取数据的方式是shuffle--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--指定Yarn(ResourceManager)的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop002</value> </property> <!--指定NodeManager允许传递给容器的环境变量白名单--> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property>
修改Hadoop配置文件
mapred-site.xml。执行以下命令,进入编辑页面。
sudo vim /opt/hadoop/etc/hadoop/mapred-site.xml在
<configuration></configuration>节点内,插入如下内容。<!--告诉hadoop将MR(Map/Reduce)运行在YARN上--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
修改Hadoop配置文件
workers。执行以下命令,进入编辑页面。
sudo vim /opt/hadoop/etc/hadoop/workers在文件
workers内,插入实例信息。hadoop001 hadoop002 hadoop003
步骤五:启动Hadoop。
执行以下命令,初始化
namenode。警告仅在第一次启动时需要初始化
namenode。三台实例均需执行。hadoop namenode -format启动Hadoop。
重要出于系统安全和稳定性考虑,Hadoop官方不推荐使用root用户来启动Hadoop服务,直接使用root用户会因为权限问题无法启动Hadoop。您可以通过非root用户身份启动Hadoop服务,例如
ecs-user用户等。如果您一定要使用root用户启动Hadoop服务,请在了解Hadoop权限控制及相应风险之后,修改以下配置文件。
请注意:使用root用户启动Hadoop服务会带来严重的安全风险,包括但不限于数据泄露、恶意软件更容易获得系统最高权限、意料之外的权限问题或行为。更多权限说明,请参见Hadoop官方文档。
一般情况下,以下配置文件位于
/opt/hadoop/sbin目录下。在
start-dfs.sh和stop-dfs.sh两个文件中添加以下参数。HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root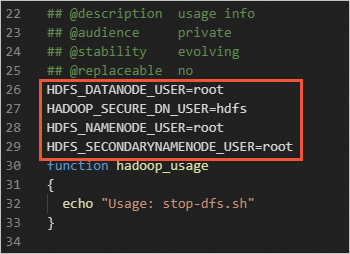
在
start-yarn.sh和stop-yarn.sh两个文件中添加以下参数。YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root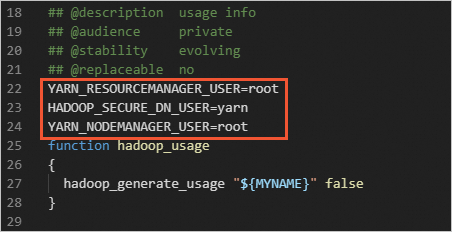
在
hadoop001上执行start-dfs.sh脚本,启动HDFS服务。这个脚本会启动NameNode、SecondaryNameNode和DataNode等组件,从而启动HDFS服务。
start-dfs.sh执行命令
jps回显信息如下所示时,表示HDFS服务已启动。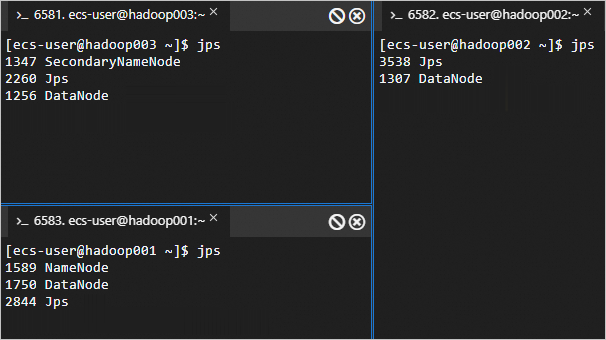
在
hadoop002上执行start-yarn.sh脚本,启动YARN服务。这个脚本会启动ResourceManager、NodeManager等组件,从而启动YARN服务。
start-yarn.sh回显信息如下所示时,表示YARN服务已启动。
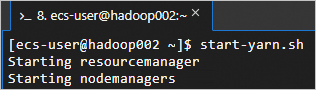
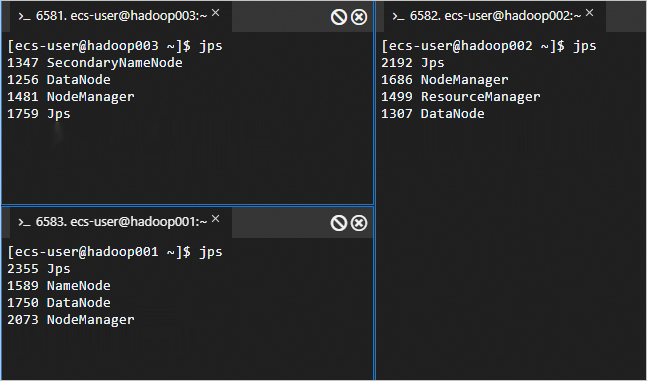
在三台节点上执行以下命令,可以查看成功启动的进程。
jps成功启动的进程如下所示。
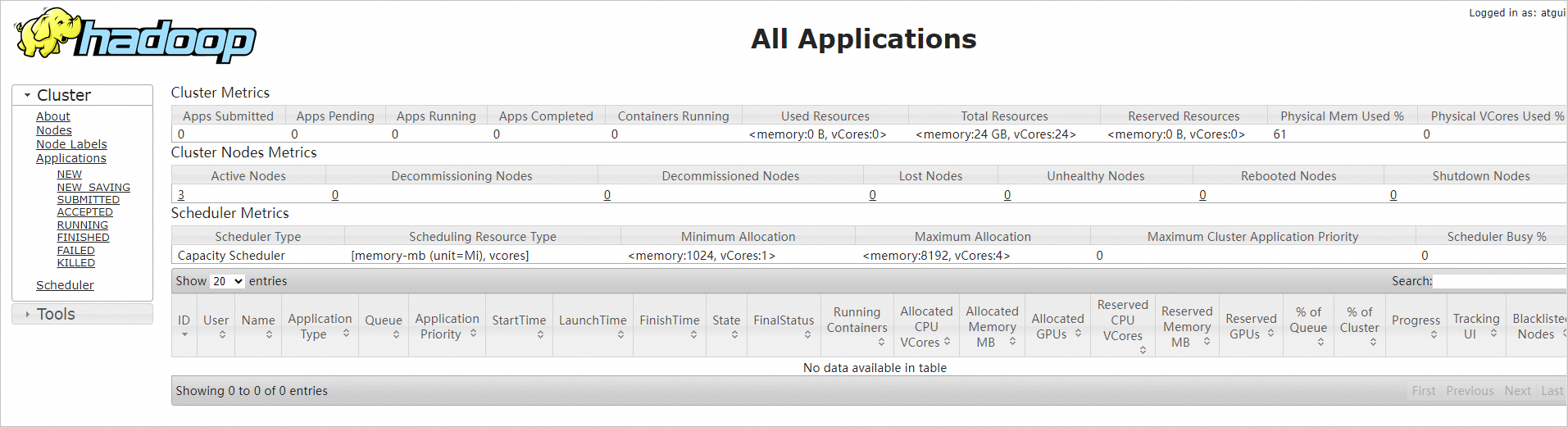
在本地浏览器地址栏输入
http://<hadoop002 ECS公网IP>:8088,访问YARN的Web UI界面。通过该界面可以查看整个集群的资源使用情况、应用程序状态(比如MapReduce作业)、队列信息等。
重要需确保在ECS实例所在安全组的入方向中放行Hadoop YARN所需的8088端口,否则无法访问。具体操作,请参见添加安全组规则。
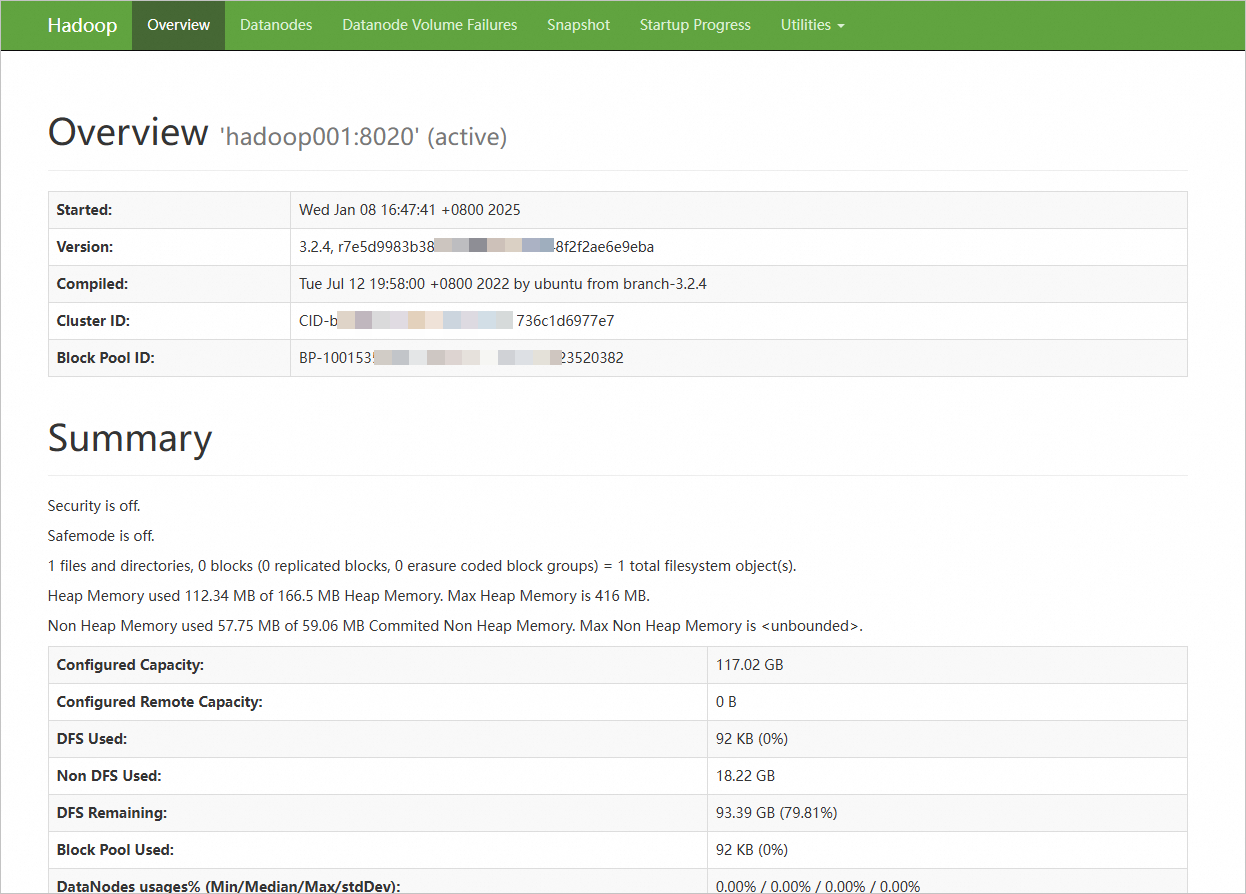
在本地浏览器地址栏输入
http://<hadoop001 ECS公网IP>:9870,访问NameNode的Web UI界面;输入http://<hadoop003 ECS公网IP>:9868,访问SecondaryNameNode的Web UI界面。该界面提供了有关HDFS文件系统状态、集群健康状况、活动节点列表、NameNode日志等信息。
显示如下界面,则表示Hadoop分布式环境已搭建完成。
重要需确保在ECS实例所在安全组的入方向中放行Hadoop NameNode所需9870端口,否则无法访问。具体操作,请参见添加安全组规则。
伪分布式
步骤一:安装JDK。
以普通用户远程连接已创建的ECS实例。
具体操作,请参见使用Workbench工具以SSH协议登录Linux实例。
重要出于系统安全和稳定性考虑,Hadoop官方不推荐使用root用户来启动Hadoop服务,直接使用root用户会因为权限问题无法启动Hadoop。您可以通过非root用户身份启动Hadoop服务,例如
ecs-user用户等。执行以下命令,下载JDK 1.8安装包。
wget https://download.java.net/openjdk/jdk8u41/ri/openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz执行以下命令,解压下载的JDK 1.8安装包。
tar -zxvf openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz执行以下命令,移动并重命名JDK安装包。
本示例中将JDK安装包重命名为
java8,您可以根据需要使用其他名称。sudo mv java-se-8u41-ri/ /usr/java8执行以下命令,配置Java环境变量。
如果您将JDK安装包重新命名为其他名称,需将以下命令中的
java8替换为实际的名称。sudo sh -c "echo 'export JAVA_HOME=/usr/java8' >> /etc/profile" sudo sh -c 'echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> /etc/profile' source /etc/profile执行以下命令,查看JDK是否成功安装。
java -version返回如下信息,表示JDK已安装成功。
步骤二:配置SSH免密登录。
单节点也需要配置SSH免密登录;否则,在尝试启动NameNode和DataNode时,会出现权限拒绝错误。
执行以下命令,创建公钥和私钥。
ssh-keygen -t rsa执行以下命令,将公钥添加到
authorized_keys文件中。cd .ssh cat id_rsa.pub >> authorized_keys
步骤三:安装Hadoop。
执行以下命令,下载Hadoop安装包。
wget http://mirrors.cloud.aliyuncs.com/apache/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz执行以下命令,将Hadoop安装包解压至
/opt/hadoop。sudo tar -zxvf hadoop-3.2.4.tar.gz -C /opt/ sudo mv /opt/hadoop-3.2.4 /opt/hadoop执行以下命令,配置Hadoop环境变量。
sudo sh -c "echo 'export HADOOP_HOME=/opt/hadoop' >> /etc/profile" sudo sh -c "echo 'export PATH=\$PATH:/opt/hadoop/bin' >> /etc/profile" sudo sh -c "echo 'export PATH=\$PATH:/opt/hadoop/sbin' >> /etc/profile" source /etc/profile执行以下命令,修改配置文件
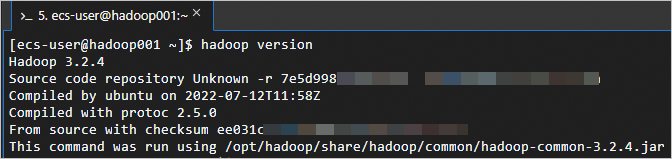
yarn-env.sh和hadoop-env.sh。sudo sh -c 'echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh' sudo sh -c 'echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh'执行以下命令,测试Hadoop是否安装成功。
hadoop version返回如下信息,表示Hadoop已安装成功。
步骤四:配置Hadoop
修改Hadoop配置文件
core-site.xml。执行以下命令,进入编辑页面。
sudo vim /opt/hadoop/etc/hadoop/core-site.xml在
<configuration></configuration>节点内,插入如下内容。<property> <name>hadoop.tmp.dir</name> <value>file:/opt/hadoop/tmp</value> <description>location to store temporary files</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property>
修改Hadoop配置文件
hdfs-site.xml。执行以下命令,进入编辑页面。
sudo vim /opt/hadoop/etc/hadoop/hdfs-site.xml在
<configuration></configuration>节点内,插入如下内容。<property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/opt/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/opt/hadoop/tmp/dfs/data</value> </property>
步骤五:启动Hadoop
执行以下命令,初始化
namenode。hadoop namenode -format启动Hadoop。
重要出于系统安全和稳定性考虑,Hadoop官方不推荐使用root用户来启动Hadoop服务,直接使用root用户会因为权限问题无法启动Hadoop。您可以通过非root用户身份启动Hadoop服务,例如
ecs-user用户等。如果您一定要使用root用户启动Hadoop服务,请在了解Hadoop权限控制及相应风险之后,修改以下配置文件。
请注意:使用root用户启动Hadoop服务会带来严重的安全风险,包括但不限于数据泄露、恶意软件更容易获得系统最高权限、意料之外的权限问题或行为。更多权限说明,请参见Hadoop官方文档。
一般情况下,以下配置文件位于
/opt/hadoop/sbin目录下。在
start-dfs.sh和stop-dfs.sh两个文件中添加以下参数。HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root在
start-yarn.sh和stop-yarn.sh两个文件中添加以下参数。YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
执行以下命令,启动HDFS服务。
这个脚本会启动NameNode、SecondaryNameNode和DataNode等组件,从而启动HDFS服务。
start-dfs.sh回显信息如下所示时,表示HDFS服务已启动。
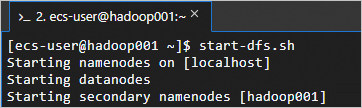
执行以下命令,启动YARN服务。
这个脚本会启动ResourceManager、NodeManager和ApplicationHistoryServer等组件,从而启动YARN服务。
start-yarn.sh回显信息如下所示时,表示YARN服务已启动。
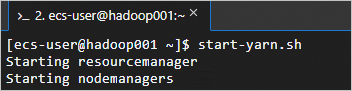
执行以下命令,可以查看成功启动的进程。
jps成功启动的进程如下所示。
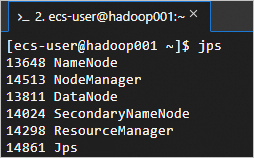
在本地浏览器地址栏输入
http://<ECS公网IP>:8088,访问YARN的Web UI界面。通过该界面可以查看整个集群的资源使用情况、应用程序状态(比如MapReduce作业)、队列信息等。
重要需确保在ECS实例所在安全组的入方向中放行Hadoop YARN所需的8088端口,否则无法访问。具体操作,请参见添加安全组规则。
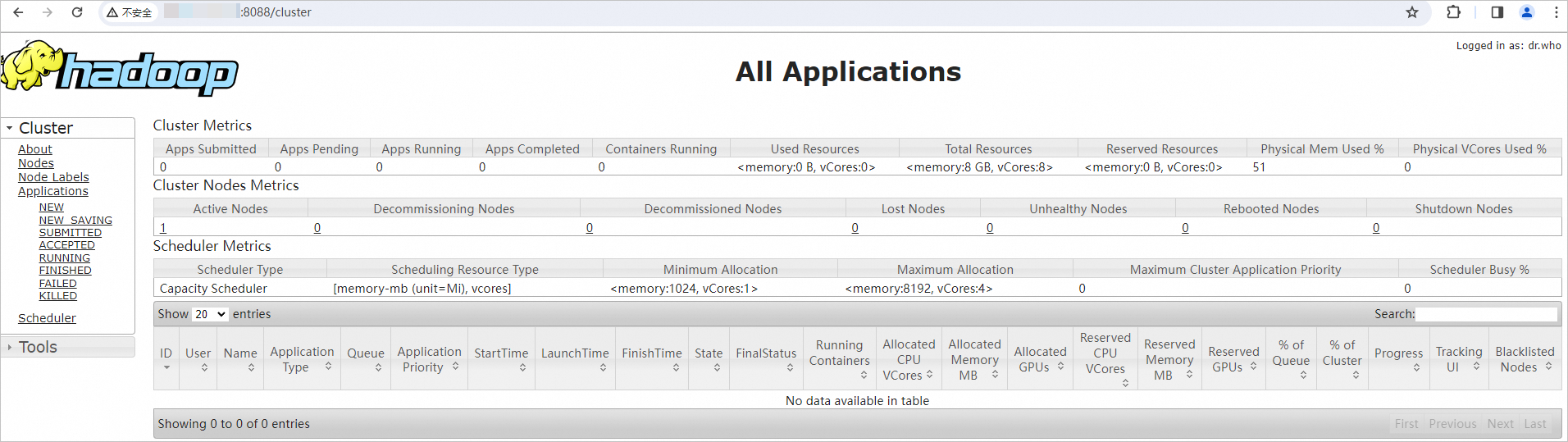
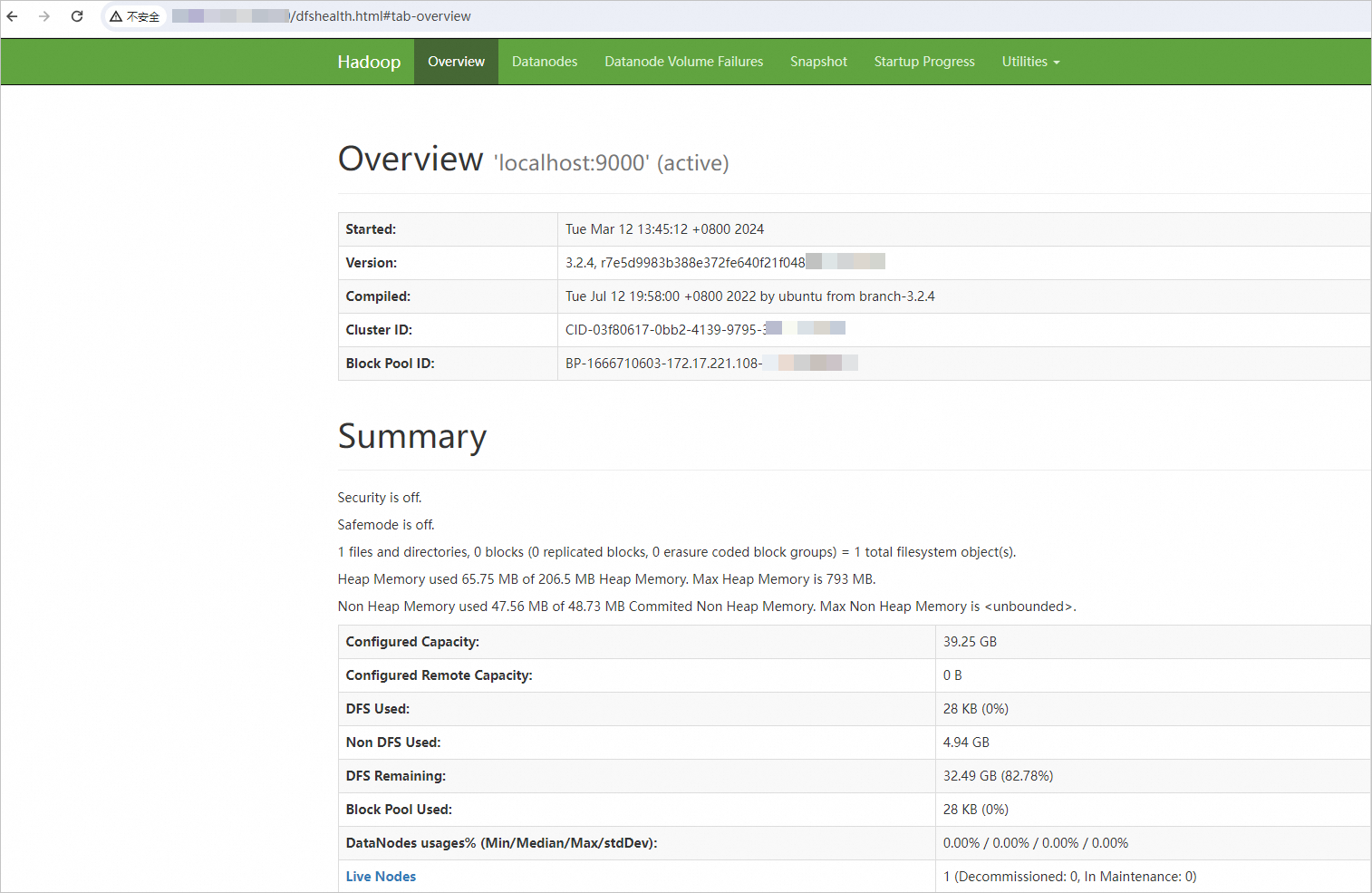
在本地浏览器地址栏输入
http://<ECS公网IP>:9870,访问NameNode的Web UI界面。该界面提供了有关HDFS文件系统状态、集群健康状况、活动节点列表、NameNode日志等信息。
显示如下界面,则表示Hadoop分布式环境已搭建完成。
重要需确保在ECS实例所在安全组的入方向中放行Hadoop NameNode所需9870端口,否则无法访问。具体操作,请参见添加安全组规则。
相关操作
创建快照一致性组
如果使用分布式Hadoop,建议您使用快照一致性组,可以确保Hadoop集群数据的一致性和可靠性,为后续的数据处理和分析提供稳定的环境支持。具体操作,请参见创建快照一致性组。
Hadoop相关操作
HDFS组件操作,请参见HDFS常用命令。
相关文档
如果您希望使用,在ECS上阿里云已经集成的大数据环境,具体操作,请参见E-MapReduce快速入门。
如果您想要使用数据湖开发和治理的环境,具体操作,请参见DataWorks快速入门。
如果您希望了解并使用阿里云大数据的更多产品,请参见阿里云大数据&AI。