
使用ECS实例时,可能会遇到镜像相关问题,如实例启动慢、系统负载高、编译内核等。本文介绍这些问题及解决方案。
Windows镜像问题
实例的操作系统为Windows Server,现在提示Windows副本不是正版怎么办?
需要激活Windows。具体操作,请参见如何使用KMS域名激活VPC网络中的Windows实例。
频繁调用Windows系统API:timeBeginPeriod导致系统时间异常,如何解决?
在Windows Server 2008上频繁调用系统API:timeBeginPeriod,导致Windows系统时间变慢或变快。您可以参考如下操作进行解决:
说明可能会造成系统时间精度变化的系统函数,请参见微软官方文档。
远程登录ECS实例。
具体操作,请参见使用Workbench工具以RDP协议登录Windows实例。
下载工具。
解压CheckTimeBeginPeriod.zip。
解压bin.zip并进入bin目录,然后双击.exe文件。
64位操作系统,双击InjectDllx64.exe。
32位操作系统,双击InjectDllx86.exe。
打印的进程就是调用timeBeginPeriod的进程。
根据业务实际情况,停止或更新调用timeBeginPeriod的程序。
如果问题仍未解决,您可以直接提交工单寻求技术支持。
Windows云服务器使用IE浏览器打开网站提示“增强安全配置正在阻止来自下列网站内容”如何处理?
在Windows操作系统的云服务器ECS或者轻量应用服务器中,使用IE浏览器打开网站时,提示“增强安全配置正在阻止来自下列网站内容”报错,解决方法请参见Windows云服务器使用IE浏览器打开网站提示“增强安全配置正在阻止来自下列网站内容”如何处理?。
更换Windows实例的系统盘或者重新初始化系统盘,为什么userdata不会自动执行?
问题原因
Windows系统的ECS实例正常启动后,会在
C:\ProgramData\aliyun\vminit\INSTANCE_实例ID}\METASERVER路径下创建缓存文件,该文件用于标记实例是否已经初始化。如果您通过该ECS实例创建了自定义镜像,并用这个自定义镜像重新初始化系统盘或更换系统盘,在C:\ProgramData\aliyun\vminit\INSTANCE_ID\METASERVER路径下会找到与当前重置实例ID一致的缓存文件。由于Vminit组件会根据缓存文件的存在与否来判断ECS实例是否是初次启动。如果找到与当前重置实例ID一致的缓存文件,Vminit组件会判断ECS实例不是初次启动,将不会自动执行userdata脚本。说明Vminit在创建Windows实例时会自动安装,为Windows实例在启动阶段提供了初始化配置的能力,类似于Linux系统的cloud-init。关于Vminit组件的更多信息,请参见初始化工具介绍。
解决方案
建议您在通过该ECS实例创建自定义镜像前,检查并删除
C:\ProgramData\aliyun\vminit\INSTANCE_{实例ID}\METASERVER路径下的缓存文件。
CentOS/Red Hat镜像问题
如何处理CentOS DNS解析超时?
问题原因
因CentOS 6和CentOS 7的DNS解析机制变动,导致2017年02月22日以前创建的ECS实例或使用2017年02月22日以前的自定义镜像创建的CentOS 6和CentOS 7实例可能出现DNS解析超时的情况。
解决方案
请按下列步骤操作修复此问题:
下载脚本fix_dns.sh。
将下载的脚本放至CentOS系统的/tmp目录下。
运行bash /tmp/fix_dns.sh命令,执行脚本。
脚本的作用和逻辑说明如下:
判断实例系统是否为CentOS。
如果实例为非CentOS系统(如Ubuntu和Debian):脚本停止工作。
如果实例为CentOS系统:脚本继续工作。
查询解析文件/etc/resolv.conf中
options的配置情况。如果不存在
options配置:默认使用阿里云
options配置options timeout:2 attempts:3 rotate single-request-reopen。
如果存在
options配置:不存在
single-request-reopen配置,则在options配置中追加该项。存在
single-request-reopen配置,则脚本停止工作,不更改DNS nameserver的配置。
如何检查与修复CentOS 7实例和Windows实例IP地址缺失问题?
问题原因及解决方案,请参见检查与修复CentOS 7实例和Windows实例IP地址缺失问题。
CentOS 7.9 ARM系统无法生成dump文件如何处理?
问题现象
CentOS 7.9 ARM系统宕机后,通过
ls /var/crash查询dump文件,没有生成vmcore文件。
问题原因
CentOS 7.9 ARM系统带有
CONFIG_ARM64_USER_VA_BITS_52=y特性的内核,系统中原生自带的makedumpfile软件版本与内核版本不匹配,因此无法生成dump文件。解决方案
重要该方案仅适用于已正确开启kdump服务的系统。如果您没有开启kdump服务且按照本文操作修复问题,请在
proc/cmdline文件中手动配置crashkernel参数。运行以下命令,下载相应的kexec-tools包。
wget http://mirrors.aliyun.com/centos-vault/7.9.2009/os/Source/SPackages/kexec-tools-2.0.15-51.el7.src.rpm运行以下命令,安装RPM包。
rpm -ivh kexec-tools-2.0.15-51.el7.src.rpm运行以下命令,下载patch补丁文件。
cd /root/rpmbuild/SOURCES wget https://ecs-image-tools.oss-cn-hangzhou.aliyuncs.com/patch/rhelonly-kexec-tools-2.0.20-makedumpfile-arm64-Add-support-for-ARMv8.2-LVA-52-bi.patch运行以下命令,修改kexec-tools.spec文件。
打开kexec-tools.spec文件。
cd /root/rpmbuild/SPECS/ vi kexec-tools.spec按
i键进入编辑模式,并在文件相应位置加入如下两行内容。Patch999: rhelonly-kexec-tools-2.0.20-makedumpfile-arm64-Add-support-for-ARMv8.2-LVA-52-bi.patch %patch999 -p1添加位置如下:
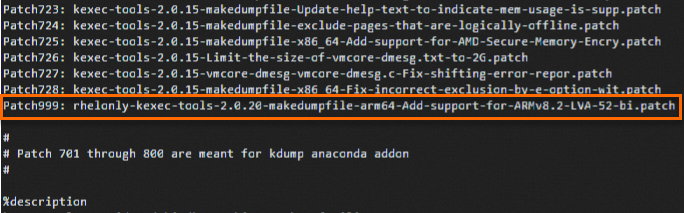
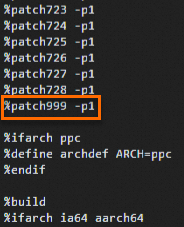
按
Esc键退出编辑模式,并输入:wq保存退出。
运行以下命令,检查安装依赖。
yum-builddep kexec-tools.spec运行以下命令,构建RPM包。
yum -y install rpm-build rpmbuild -ba kexec-tools.spec运行以下命令,安装修改后的RPM包。
cd /root/rpmbuild/RPMS/aarch64 rpm -ivh kexec-tools-2.0.15-51.el7.aarch64.rpm
如果再次发生宕机,通过
ls -lh /var/crash查询dump文件,可以正常生成vmcore文件,表示问题已解决。
CentOS/RedHat 7.x升级Systemd重启进入救援模式如何处理?
CentOS 7或RedHat 7系列的系统在升级Systemd至systemd-219-71.el7版本后,重启实例会进入救援模式,这样会导致系统网络服务和一般的应用软件服务异常。具体解决方案请参见CentOS 7.X或RedHat 7.X升级Systemd并重启后会进入救援模式。
如何将CentOS 7转换为Red Hat Enterprise Linux(RHEL)7?
CentOS 7将于2024年06月30日停止维护(EOL),阿里云将会同时停止对该操作系统的支持。为了避免操作系统停止维护带来的影响,您可以将CentOS 7转换为RHEL 7。以下是在阿里云上将CentOS 7转换成RHEL 7的简要步骤,您也可以参考Red Hat官方文档来进行转换。
重要转换前,建议您停止重要的应用程序、数据库服务和存储数据等服务,并创建快照备份重要数据,以避免误操作导致数据丢失或异常。
(条件必选)如果您是阿里云服务器并且安装了安骑士,需要先卸载安骑士。
具体操作,请参见卸载客户端。
说明安骑士是CentOS默认的安全增强工具,而RHEL 7则使用Red Hat提供的安全增强工具。安骑士与RHEL 7中的工具可能存在不兼容性和冲突,因此在转换过程中需要卸载安骑士,以确保系统的稳定性和兼容性。
运行以下命令,将系统软件包升级到最新版本。
sudo wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo sudo wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo运行以下命令,更新系统软件包并重启系统。
sudo yum -y update sudo reboot运行以下命令,从Red Hat官方网站下载并安装convert2rhel工具。
sudo curl -o /etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release https://www.redhat.com/security/data/fd431d51.txt sudo curl --create-dirs -o /etc/rhsm/ca/redhat-uep.pem https://ftp.redhat.com/redhat/convert2rhel/redhat-uep.pem sudo curl -o /etc/yum.repos.d/convert2rhel.repo https://ftp.redhat.com/redhat/convert2rhel/7/convert2rhel.repo sudo yum -y install convert2rhel在阿里云上购买RHEL订阅,并获取RHEL 7的repo RPM包地址。
具体操作,请提交工单咨询。
运行以下命令,安装RHEL 7的repo源包。
sudo rpm -ivh --replacefiles <repo rpm包地址> sudo sed -i 's/enabled=1/enabled=0/g' /etc/yum.repos.d/rh-cloud.repo其中,
<repo rpm包地址>需替换为RHEL 7实际的repo rpm包地址,该地址请在购买RHEL订阅时获取。运行以下命令,将CentOS 7转换为RHEL 7。
sudo convert2rhel -y --no-rhsm --enablerepo rhui-rhel-7-server-rhui-rpms --enablerepo rhui-rhel-7-server-rhui-extras-rpms --enablerepo rhui-rhel-7-server-rhui-optional-rpms转换过程需要花费一定时间,请您耐心等待。类似出现如下回显信息时,表示转换完成。
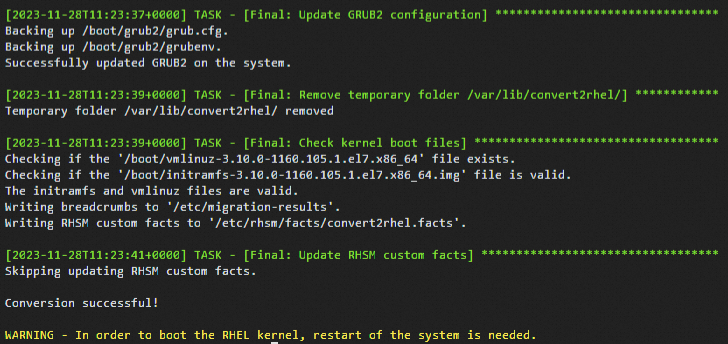
运行以下命令,重启系统。
转换结束后会提示重启系统,重启系统可以引导新的RHEL内核,然后检查操作系统是否转换成功。
sudo reboot说明CentOS 7转换为RHEL 7之后,如果您有需求将RHEL 7升级为RHEL 8,请参见Red Hat Enterprise Linux(RHEL)7升级为RHEL 8。
如何解决RedHat 8.1/8.2镜像在弹性裸金属服务器实例规格族的ECS实例下启动慢的问题?
在弹性裸金属服务器实例规格族的ECS实例中,RedHat 8.1/8.2镜像相较于RedHat 7镜像启动时长多1~2分钟。为解决该问题,您可以在RedHat 8.1/8.2系统的/boot/grub2/grubenv文件中,将内核启动参数
console=ttyS0 console=ttyS0,115200n8修改为console=tty0 console=ttyS0,115200n8,然后重启服务器使配置生效。
SUSE镜像问题
SLES for SAP常见问题
SUSE Linux Enterprise Server for SAP Applications(SLES for SAP)是专为SAP系统定制的商业Linux操作系统。以下是使用过程中常见的问题:
Ubuntu镜像问题
为什么Ubuntu某些版本的ECS实例中启动安骑士进程后系统负载较高?
在某些版本的Ubuntu(例如Ubuntu 18.04)的ECS实例中,启动安骑士进程(AliYunDun)后,系统平均负载较高。
具体的原因和解决方案,请参见Ubuntu 18.04版本的ECS实例中启动安骑士进程后系统负载较高。
FreeBSD镜像问题
FreeBSD系统如何打补丁编译内核?
阿里云的FreeBSD公共镜像已为内核添加了补丁,已满足系列V及以上的实例规格族的启动需求。具体的实例规格族可通过DescribeInstanceTypeFamilies接口的
Generation参数查询。以下情况可能导致系统无法正常启动,您可以通过FreeBSD内核源码打补丁编译内核的方式,避免或解决系统无法启动的问题。
使用非阿里云提供的FreeBSD镜像及相关自定义镜像创建ECS实例时,系列V及以上实例规格族的ECS实例可能出现无法正常启动的情况。
使用FreeBSD公共镜像创建ECS实例,并使用了freebsd-update等更新内核补丁,可能会导致系列V及以上实例规格族的ECS实例无法正常启动。
FreeBSD 13及以上不需要打补丁。本示例以FreeBSD 12.3为例,介绍如何使用FreeBSD内核源码打补丁编译内核。
下载并解压FreeBSD内核源码。
wget https://mirrors.aliyun.com/freebsd/releases/amd64/12.3-RELEASE/src.txz -O /src.txz cd / tar -zxvf /src.txz下载补丁包。
本示例中,为virtio驱动打补丁包
0001-virtio.patch。cd /usr/src/sys/dev/virtio/ wget https://ecs-image-tools.oss-cn-hangzhou.aliyuncs.com/0001-virtio.patch patch -p4 < 0001-virtio.patch复制内核文件,并编译安装内核。
make -j<N>表示指定编译时的并行数,需要根据您执行编译的环境配置来决定。例如,1 vCPU环境建议设置-j2,即vCPU核数与变量N的比值为1:2。cd /usr/src/ cp ./sys/amd64/conf/GENERIC . make -j2 buildworld KERNCONF=GENERIC make -j2 buildkernel KERNCONF=GENERIC make -j2 installkernel KERNCONF=GENERIC编译完成后,删除源码。
rm -rf /usr/src/* rm -rf /usr/src/.*
FreeBSD系统在KVM环境无法找到系统盘,如何处理?
问题现象
FreeBSD系统在KVM虚拟化环境上VNC登录时,无法找到系统盘,无法进入系统,如下图所示。
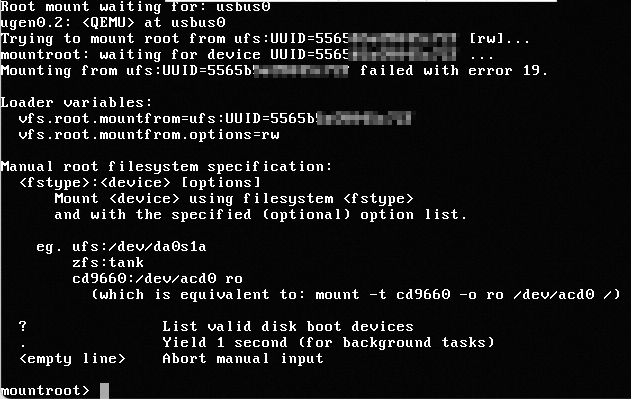
解决方案
在VNC中输入?,查看相关rootfs的ufsid。
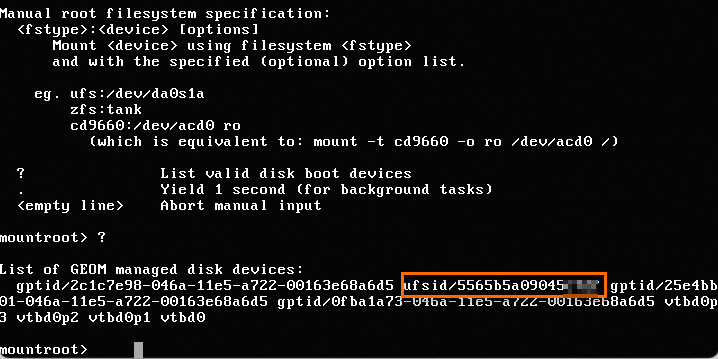
继续输入
ufs:/dev/ufsid/5565b5a09045****,按回车即可正常进入操作系统内部。输入用户名和密码,登录系统。
运行以下命令,查看
/etc/fstab配置。cat /etc/fstab如下图所示,说明
/etc/fstab配置是UUID的挂载方式。但是FreeBSD系统并不支持UUID的挂载方式,需要修改为ufsid方式。
将FreeBSD系统的挂载方式修改为ufsid。
运行以下命令,打开
/etc/fstab。vi /etc/fstab按i键进入编辑模式。
修改
UUID=5565b5a09045****为/dev/ufsid/5565b5a09045****。修改完成后按Esc键,并输入
:wq后按下回车键,保存并退出。
运行以下命令,重启系统使配置生效。
reboot
Fedora镜像问题
为什么我无法使用ssh-rsa签名算法的SSH密钥对远程连接Fedora 33 64位系统的实例?
当您使用Fedora 33 64位操作系统的ECS实例时,如果登录凭证设置的是ssh-rsa签名算法的SSH密钥对,可能无法顺利使用SSH远程连接实例。您可以通过以下任一方式解决该问题:
将ssh-rsa签名算法的SSH密钥对替换为ECDSA签名算法等其他签名算法的SSH密钥对。
在系统中运行update-crypto-policies --set LEGACY命令,将加密策略
POLICY切换为LEGACY,即可继续使用ssh-rsa签名算法的SSH密钥对。
为什么使用Fedora CoreOS镜像创建部分实例后,CPU信息只有实例规格的一半?
使用Fedora CoreOS镜像创建部分实例(例如,通用型实例规格族g5)后,执行lscpu命令查看CPU信息,
On-line CPU(s) list的总个数只有实例实际规格的一半。例如,创建实例时选择的CPU为2核,则On-line CPU(s) list个数只有1个。示例如下图所示。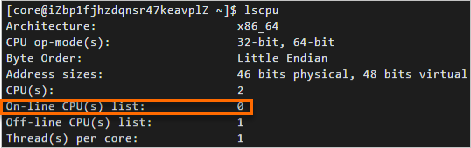 说明
说明On-line CPU(s) list参数值代表CPU编号,图中示例表示只有0号CPU可用。这是因为Fedora CoreOS镜像的内核默认配置了
mitigations=auto,nosmt启动参数,会自动为有漏洞的系统禁用同步多线程技术SMT(Simultaneous Multi-Threading ),导致可用CPU减半。mitigations=auto,nosmt参数可以通过执行cat /proc/cmdline命令查看。关于SMT的更多信息,请参见Automatically disable SMT when needed to address vulnerabilities和Policy for disabling SMT。
其他问题
Linux时间和时区说明
如何为已有自定义镜像安装NVMe驱动?
如何解决实例迁移后的宕机问题?
如何为Linux服务器安装GRUB?
如何收集操作系统宕机后的内核转储信息?
如何解决查看/proc/cpuinfo文件中CPU频率与实例规格说明不一致的问题
使用RSA密钥无法登录ECS实例问题
基于弹性裸金属实例规格的ECS实例,系统生成crash dump文件失败如何解决?
问题原因及解决方案,请参见部分ECS实例生成crash dump文件失败如何解决?。
Linux操作系统内核回写时出现softlockup异常如何解决?
部分低版本的Linux操作系统内核在回写(writeback)文件缓存时,会出现softlockup异常。具体的解决方案,请参见Linux操作系统内核回写时出现softlockup异常的解决方案。
在ECS实例内删除cgroup出现softlockup异常如何解决?
具体的解决方案,请参见在ECS实例内删除cgroup出现softlockup异常的解决方案。
公共镜像自带FTP上传吗?
不自带,需要您自己安装配置。具体操作,请参见手动搭建FTP站点(Windows)和搭建FTP站点(Linux)。
为什么ECS默认没有启用虚拟内存或Swap说明?
Swap分区或虚拟内存文件,是在系统物理内存不够用的时候,由系统内存管理程序将那些很长时间没有操作的内存数据,临时保存到Swap分区或虚拟内存文件中,以提高可用内存额度的一种机制。
但是,如果在内存使用率已经非常高,而同时I/O性能也不是很好的情况下,该机制其实会起到相反的效果。阿里云ECS云盘使用了分布式文件系统作为云服务器的存储,对每一份数据都进行了强一致的多份拷贝。该机制在保证用户数据安全的同时,由于3倍增涨的I/O操作,会降低本地磁盘的存储性能和I/O性能。
综上,为了避免当系统资源不足时进一步降低ECS云磁盘的I/O性能,Windows系统实例默认没有启用虚拟内存,Linux系统实例默认未配置Swap分区。
如何在公共镜像中开启kdump?
公共镜像中默认未开启kdump服务。若您需要实例在宕机时,生成core文件,并以此分析宕机原因,请参见以下步骤开启kdump服务。本步骤以公共镜像CentOS 7.2为例。实际操作时,请以您的操作系统为准。
设置core文件生成目录。
运行vim /etc/kdump.conf打开kdump配置文件。vim命令使用详情,请参见Vim编辑器。
设置path为core文件的生成目录。本示例中,在/var/crash目录下生成core文件,则path的设置如下。
path /var/crash保存并关闭/etc/kdump.conf文件。
开启kdump服务。
根据操作系统对命令的支持情况,选择开启方式。
方法一:依次运行以下命令开启kdump服务。
systemctl enable kdump.servicesystemctlstartkdump.service方法二:依次运行以下命令开启kdump服务。
chkconfig kdump onservice kdump start方法三:如果您的服务器已安装云助手,可参考如何解决实例迁移后的宕机问题?开启kdump服务。
如何设置Linux系统的ECS实例的静态IP地址?
您需要远程连接ECS实例进行设置。具体操作,请参见如何在Linux实例中设置静态IP地址。
如何在Linux实例中自定义配置DNS?
具体操作,请参见如何在Linux实例中自定义配置DNS。
Linux操作系统配置IPv6地址后,安装了NTP服务的服务器时间无法同步,如何处理?
问题现象
在服务器上执行
ntpq -p同步时间时,返回超时,如下图所示。
解决方案
说明本方法适用于CentOS 7及以下、Ubuntu 20.04及以下、Anolis OS(ANCK\RHCK)、Alibaba Cloud Linux、Debian等系列操作系统。
远程连接Linux实例。
具体操作,请参见使用Workbench工具以SSH协议登录Linux实例。
运行以下命令,修改/etc/ntp.conf配置文件。
vi /etc/ntp.conf按i键进入编辑模式。
在文件中添加
restrict -6 ::1内容,如下图所示。
修改完成后按Esc键,并输入
:wq后按下回车键,保存并退出。运行以下命令,重启NTP服务。
systemctl restart ntp
为什么使用自定义镜像创建的实例,热插拔云盘/网卡会失败?
问题现象
热插拔云盘指实例处于运行中状态时挂载/卸载云盘;热插拔网卡指实例处于运行中状态时绑定/解绑弹性网卡。
阿里云支持热插拔云盘和网卡,但热插拔是否成功需要操作系统内核(Kernel)支持。如果操作系统内核不支持,则会出现以下问题:
挂载云盘或绑定弹性网卡后,在操作系统内部查看不到对应的设备。
卸载云盘或解绑弹性网卡失败。
解决方案
普通云服务器和裸金属服务器的热插拔需要内核支持的功能不同,建议内核都支持PCI(Peripheral Component Interconnect)、ACPI(Advanced Configuration and Power Management Interface)热插拔功能(除CentOS 5等低版本系统外,一般都默认开启)。您可以通过以下步骤查看内核是否开启PCI/ACPI热插拔功能。
远程连接Linux实例。
具体操作,请参见使用Workbench工具以SSH协议登录Linux实例。
执行如下命令,查看当前实例内核版本。
uname -r返回信息如下所示,表示当前系统内核版本为
3.10.0-1127.19.1.el7.x86_64。
执行如下命令,查看
/boot目录下的文件。ll /boot返回信息如下所示,
config-3.10.0-1127.19.1.el7.x86_64即为系统内核的配置文件。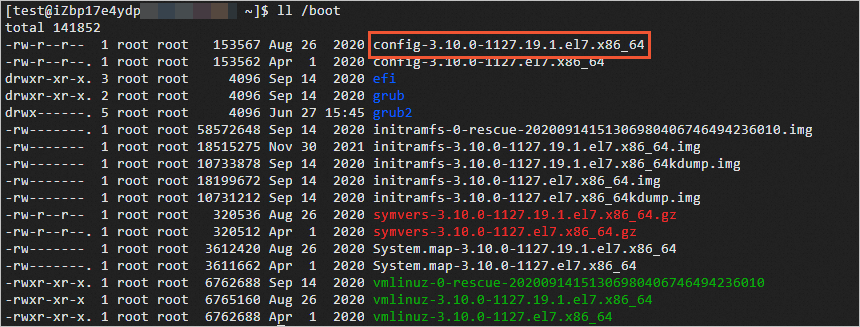
执行如下命令,查看系统内核配置文件。
cat /boot/config-3.10.0-1127.19.1.el7.x86_64当以下配置项都是
y,表示该功能已经编译进内核,操作系统支持对应的热插拔。CONFIG_HOTPLUG_PCI_PCIE=y CONFIG_HOTPLUG_PCI=y CONFIG_HOTPLUG_PCI_ACPI=y当某个配置项是
is not set,表示内核未编译该特性,需要重新编译内核以支持该特性。当某个配置项是
m,表示编译成module,例如以下CONFIG_HOTPLUG_PCI_ACPI是编译成module的,需要加载对应的module。CONFIG_HOTPLUG_PCI_PCIE=y CONFIG_HOTPLUG_PCI=y CONFIG_HOTPLUG_PCI_ACPI=m以CentOS 5.x操作系统2.6的内核为例,
CONFIG_HOTPLUG_PCI_ACPI对应的module为acpiphp.ko,如果需要加载,需要执行modprobe acpiphp命令。如果加载失败,您可以升级高版本内核或停止实例后进行冷插拔。重要不建议随意自行升级云服务器的内核和操作系统版本。如果需要升级内核,请参见避免Linux实例升级内核系统无法启动的方法。
操作系统内核错误后可能出现实例关机,如何处理?
问题现象
当操作系统内出现非预期内核错误(kernel panic)时,加载第二内核(捕获内核)进行内存转储生成Kdump日志。由于与裸金属实例规格存在兼容性问题,在第二内核启动过程中磁盘识别失败,导致Kdump日志采集失败并且第二内核启动失败,实例处于关机状态,后续需要在控制台重新启动实例。
更多关于裸金属实例规格的信息,请参见实例规格族。
问题原因
裸金属实例使用操作系统自带的Kdump服务生成dump文件时可能失败。
ebm*6代系列裸金属实例,在选用如下镜像时会出现该问题。
CentOS 8.3及以下CentOS版本
Ubuntu 16/18
Debian 10
Alibaba Cloud Linux 2的
4.19.91-24.al7之前的内核版本(4.19.91-24.al7版本已修复)
ebm*7代系列裸金属实例,在选用Debian 10镜像时会出现该问题。
解决方案
CentOS等镜像
建议更换更高版本的操作系统。具体操作,请参见更换操作系统(更换系统盘)。
Alibaba Cloud Linux 2镜像
建议按照以下操作,升级内核版本到
4.19.91-24.al7及以上。远程登录ECS实例。
具体操作,请参见使用Workbench工具以SSH协议登录Linux实例。
运行以下命令,查询内核版本。
uname -r运行以下命令,升级内核版本。
sudo yum update kernel运行以下命令,重启ECS实例,以使新的内核版本生效。
sudo reboot