
当您的集群负载长时间处于低水平且大量集群资源处于闲置状态时,您可以考虑对集群的Core节点组或Task节点组进行缩容,以避免资源的浪费。对于按量付费Task节点组的缩容,可通过控制台进行操作。而其他类型的按量付费Core节点组、包年包月Task节点组及包年包月Core节点组的缩容,则需遵循本文所述操作流程。
使用限制
如果您的集群Core节点的数量与HDFS的副本数量相等,请勿对core节点进行缩容,以避免数据丢失。
如果您的集群为旧版Hadoop集群,并且该集群为高可用(HA)集群,Master节点数量为2,则请勿缩容emr-worker-1节点(在旧版高可用集群中,Zookeeper将部署在work-1上)。
注意事项
本文操作均不可逆,一旦开始下线操作后,无法恢复原有状态。
本文操作为最佳实践操作演示,请结合集群实际情况进行评估后谨慎操作,避免集群任务调度失败以及数据安全的风险。
步骤一:选择下线节点
您可以根据集群服务的负载情况,选择需要下线的节点。本文提供两种方法以供您查看集群资源的使用情况,从而判断需要下线的节点。
方法一:EMR控制台监控诊断
在指标监控页面查看YARN-Queues仪表盘的AvailableVCores指标。如果AvailableVCores指标长时间保持较高水平,说明队列中存在较多可用核数,此时可考虑对集群的Core节点组或Task节点组进行缩容。
在指标监控页面查看YARN-NodeManagers仪表盘中的AvailableGB指标。如果某个节点的AvailableGB指标长时间保持较高水平,则表明该节点拥有较多可用内存,此时可以考虑释放该节点。
您可以根据您的业务需求结合其他指标作为判断依据。有关更多指标的信息,请参见集群指标。
方法二:YARN的WEB UI页面
查看集群队列资源使用情况,如果发现队列资源经常使用得很少,此时可考虑对集群的Core节点组或Task节点组进行缩容。

在Nodes页面,按照Nodes Address进行排序,可以快速找出哪个节点可用内存较多,此时可以考虑释放该节点。
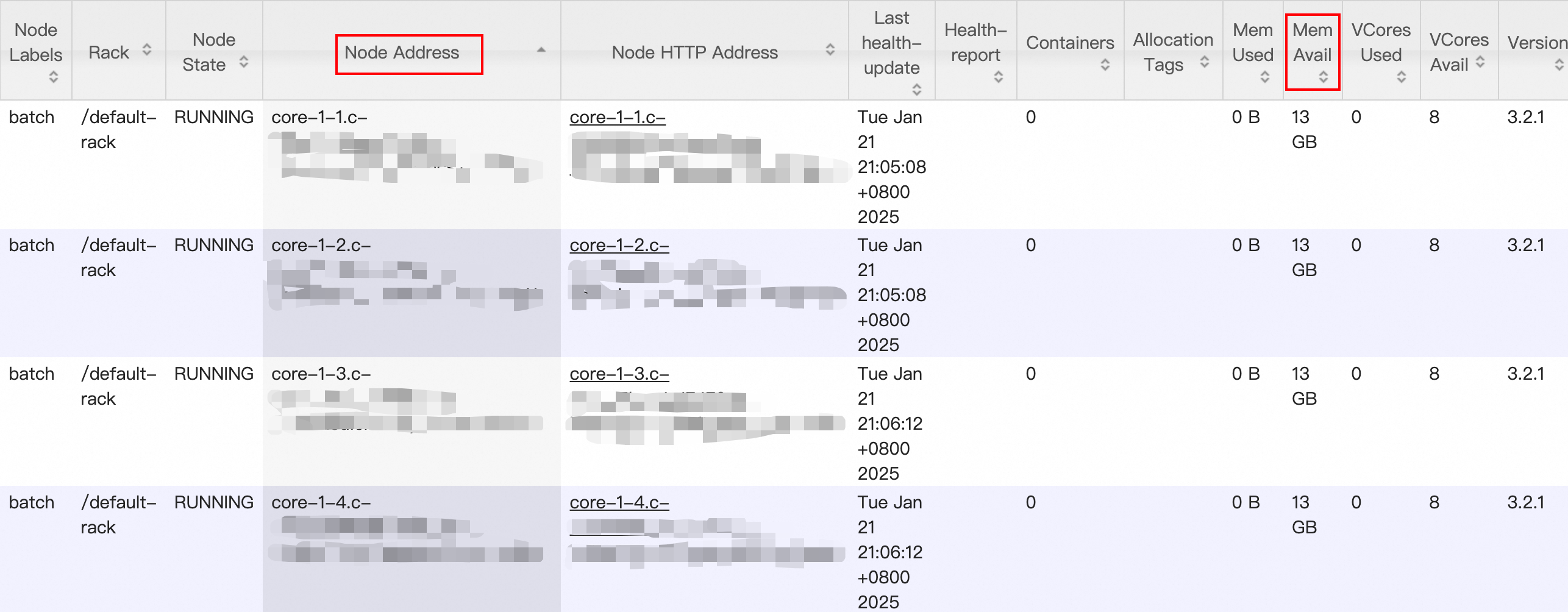
如果您的集群是旧版Hadoop集群且有以下情况,需要特别注意:
如果您的集群为非高可用集群,请不要下线emr-worker-1和emr-worker-2 节点。
如果您的集群为高可用集群,但Master节点数为2,请不要下线emr-worker-1节点。
步骤二:查看下线节点服务
在对Core节点组或Task节点组进行缩容时,需要先将对应节点的相关组件服务下线,才能释放相应的节点资源。可以在控制台的节点管理页面查看节点部署组件情况。
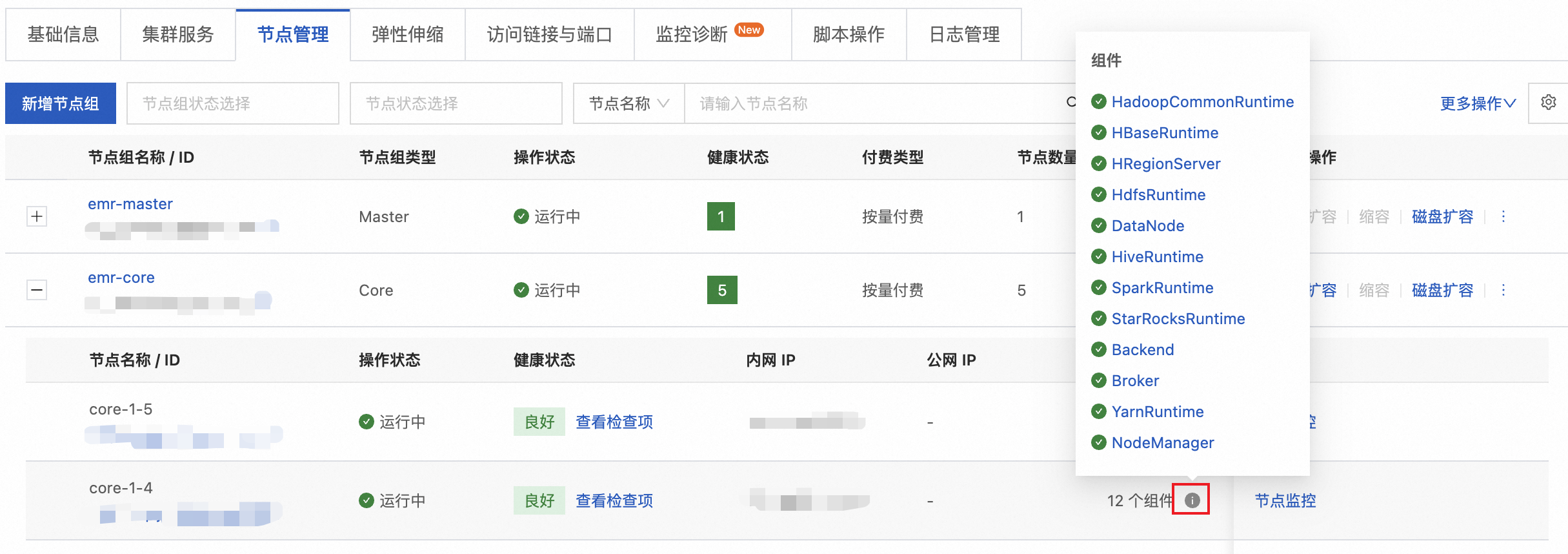
步骤三:节点组件服务下线
如果您选择的下线节点已安装以下组件服务,请在释放节点之前对已安装的这些服务组件先行进行下线操作,否则可能会导致任务调度失败及数据安全的问题。
YARN NodeManager下线
进入YARN服务的状态页面。
在顶部菜单栏处,根据实际情况选择地域和资源组。
在EMR on ECS页面,单击目标集群操作列的集群服务。
在集群服务页面,单击YARN服务区域的状态。
下线目标节点的NodeManager。
在组件列表中,单击NodeManager操作列中的
 > 下线。
> 下线。在弹出的对话框中,选择、输入执行原因、单击确定。
在弹出的对话框中,单击确定。
单击右上角的操作历史,可以查看操作进度。
HDFS DataNode下线
通过SSH方式登录集群Master节点,详见请参见登录集群。
切换到hdfs用户,并查看当前NameNode的个数。
sudo su - hdfs hdfs haadmin -getAllServiceState依次ssh到NameNode所在节点,编辑dfs.exclude文件,加入需要下线的节点,每次建议只新增一台。
旧版Hadoop集群
touch /etc/ecm/hadoop-conf/dfs.exclude vim /etc/ecm/hadoop-conf/dfs.exclude在vim下输入
o,新开始一行,填写下线的DataNode的hostname。emr-worker-3.cluster-xxxxx emr-worker-4.cluster-xxxxx非旧版Hadoop集群
touch /etc/taihao-apps/hdfs-conf/dfs.exclude vim /etc/taihao-apps/hdfs-conf/dfs.exclude在vim下输入
o,新开始一行,填写下线的DataNode的hostname。core-1-3.c-0894dxxxxxxxxx core-1-4.c-0894dxxxxxxxxx
在任一NameNode所在节点,切换到hdfs用户,执行刷新命令,HDFS自动启动下线。
sudo su - hdfs hdfs dfsadmin -refreshNodes确认下线结果。
输入以下命令,判断下线过程是否已经完成。
hadoop dfsadmin -report当指定节点的下线Status为Decommissioned,即表示该节点DataNode的数据已经迁移至其他节点,下线操作已经完成。
StarRocks下线
登录集群并使用客户端访问集群,详情请参见快速入门。
执行如下命令,通过
DECOMMISSION方式下线BE。ALTER SYSTEM DECOMMISSION backend "be_ip:be_heartbeat_service_port";以下参数请根据集群实际情况替换。
be_ip:在节点管理页面找到待缩容BE的内网IP地址。be_heartbeat_service_port:默认是9050,可以通过show backends命令查看。
如果Decommission很慢,您可以使用
DROP方式强制下线BE。重要如果您使用
DROP方式下线BE节点,请确保系统三副本完整。ALTER SYSTEM DROP backend "be_ip:be_heartbeat_service_port";执行以下命令,观察BE状态。
show backends;
SystemDecommissioned为true的节点,表示正在进行Decommission。当BE节点的TabletNum为0时,系统会清理元数据。
如果图中查看不到BE节点,则说明下线成功。
HBase HRegionServer下线
进入HBase服务的状态页面。
在顶部菜单栏处,根据实际情况选择地域和资源组。
在EMR on ECS页面,单击目标集群操作列的集群服务。
在集群服务页面,单击HBase服务区域的状态。
下线目标节点的HRegionServer。
在组件列表中,单击HRegionServer操作列中的停止。
在弹出的对话框中,选择、输入执行原因、单击确定。
在弹出的对话框中,单击确定。
单击右上角的操作历史,可以查看操作进度。
HBASE-HDFS DataNode下线
通过SSH方式登录集群Master节点,详见请参见登录集群。
执行以下命令,切换到hdfs用户并设置环境变量。
sudo su - hdfs export HADOOP_CONF_DIR=/etc/taihao-apps/hdfs-conf/namenode执行以下命令,查看当前NameNode的信息。
hdfs dfsadmin -report依次ssh到NameNode所在节点,编辑dfs.exclude文件,加入需要下线的节点,每次建议只新增一台。
touch /etc/taihao-apps/hdfs-conf/dfs.exclude vim /etc/taihao-apps/hdfs-conf/dfs.exclude在vim下输入
o,新开始一行,填写下线的DataNode的hostname。core-1-3.c-0894dxxxxxxxxx core-1-4.c-0894dxxxxxxxxx在任一NameNode所在节点,切换到hdfs用户,执行刷新命令,HDFS自动启动下线。
sudo su - hdfs export HADOOP_CONF_DIR=/etc/taihao-apps/hdfs-conf/namenode hdfs dfsadmin -refreshNodes确认下线结果。
输⼊以下命令,判断下线过程是否已经完成。
hadoop dfsadmin -report当指定节点的下线Status为Decommissioned,即表示该节点DataNode的数据已经迁移⾄其他节点,下线操作已经完成。
SmartData JindoStorageService下线(旧版Hadoop集群)
进入SmartData服务的状态页面。
在顶部菜单栏处,根据实际情况选择地域和资源组。
在EMR on ECS页面,单击目标集群操作列的集群服务。
在集群服务页面,单击SmartData服务区域的状态。
下线目标节点的JindoStorageService。
在组件列表中,单击JindoStorageService操作列中的
> 下线。在弹出的对话框中,选择、输入执行原因、单击确定。
在弹出的对话框中,单击确定。
单击右上角的操作历史,可以查看操作进度。
步骤四:释放下线节点
您需要登录ECS控制台对集群节点进行操作,如果您是RAM用户,则需要具有ECS相关权限,建议授权AliyunECSFullAccess。
进入节点管理页面。
在顶部菜单栏处,根据实际情况选择地域和资源组。
在EMR on ECS页面,单击目标集群操作列的节点管理。
在节点管理页面,单击待释放节点的ECS ID。
即可进入ECS控制台。
在ECS控制台上对实例进行释放操作,详情请参见释放实例。