
实时计算Flink版支持使用Hive方言创建批处理作业,通过兼容Hive SQL语法增强与Hive互操作性,便于从现有Hive作业平滑迁移至实时计算管理控制台。
前提条件
如果您使用RAM用户或RAM角色等身份访问,需要确认已具有Flink控制台相关权限,详情请参见权限管理。
已创建Flink工作空间,详情请参见开通实时计算Flink版。
使用限制
仅VVR 8.0.11及以上版本支持使用Hive方言。
目前仅支持Hive方言INSERT Statements语法,且需要在INSERT Statements之前声明
USE Catalog <yourHiveCatalog>。暂不支持Hive和Flink自定义函数。
步骤一:创建Hive Catalog
配置Hive元数据,详情请参见配置Hive元数据。
创建Hive Catalog,详情请参见创建Hive Catalog。
本示例创建的Hive Catalog命名为hdfshive。
步骤二:准备Hive示例数据表
在页面,单击
 新建,创建查询脚本。
新建,创建查询脚本。执行如下SQL示例。
重要Hive源表和结果表必须使用
CREATE TABLE创建永久表,而不是CREATE TEMPORARY TABLE创建临时表。-- 使用Hive Catalog,其中hdfshive为步骤一创建的示例名称 USE CATALOG hdfshive; -- 源数据表 CREATE TABLE source_table ( id INT, name STRING, age INT, city STRING, salary FLOAT )WITH ('connector' = 'hive'); -- 结果数据表 CREATE TABLE target_table ( city STRING, avg_salary FLOAT, user_count INT )WITH ('connector' = 'hive'); -- 写入测试数据 INSERT INTO source_table VALUES (1, 'Alice', 25, 'New York', 5000.0), (2, 'Bob', 30, 'San Francisco', 6000.0), (3, 'Charlie', 35, 'New York', 7000.0), (4, 'David', 40, 'San Francisco', 8000.0), (5, 'Eva', 45, 'Los Angeles', 9000.0);
步骤三:创建Hive SQL作业
在左侧导航栏,单击。
单击新建后,在新建作业草稿对话框,选择空白的批作业草稿(BETA),单击下一步。
填写作业信息。
作业参数
说明
示例
文件名称
作业的名称。
说明作业名称在当前项目中必须保持唯一。
hive-sql
存储位置
指定该作业的代码文件所属的文件夹。
您还可以在现有文件夹右侧,单击
 图标,新建子文件夹。
图标,新建子文件夹。作业草稿
引擎版本
当前作业使用的Flink引擎版本。
vvr-8.0.11-flink-1.17
SQL方言
SQL数据处理语言。
说明仅支持Hive方言的引擎版本才会显示该配置项。
Hive SQL
单击创建。
步骤四:编写Hive SQL作业并部署
编写SQL语句。
本示例计算各城市年龄大于30的用户数量和平均工资,您可复制如下SQL示例到SQL编辑区域。
-- 使用Hive Catalog,其中hdfshive为步骤一创建的示例名称 USE CATALOG hdfshive; INSERT INTO TABLE target_table SELECT city, AVG(salary) AS avg_salary, -- 计算平均工资 COUNT(id) AS user_count -- 计算用户数量 FROM source_table WHERE age > 30 -- 筛选年龄大于 30 的用户 GROUP BY city; -- 按城市分组单击右上方部署,在对话框中根据需要配置相关参数(本示例保持默认),单击确定。
(可选)步骤五:配置作业运行参数
如果您通过JindoSDK访问Hive集群,则需要执行该步骤。
在左侧导航栏,单击。
在下拉框中选择批作业,单击目标作业的详情。

在部署详情对话框中,单击运行参数配置区域右侧的编辑。
在其他配置中,增加如下配置信息。
fs.oss.jindo.endpoint: <YOUR_Endpoint> fs.oss.jindo.buckets: <YOUR_Buckets> fs.oss.jindo.accessKeyId: <YOUR_AccessKeyId> fs.oss.jindo.accessKeySecret: <YOUR_AccessKeySecret>参数说明的详细信息请参见写OSS-HDFS。
单击保存。
步骤六:启动作业并查看结果
单击目标作业的启动。

作业状态变为已完成后,查看计算结果。
在页面,执行以下SQL示例,查看各城市年龄超过30岁的用户数量及其平均工资的数据结果。
-- 使用Hive Catalog,其中hdfshive为步骤一创建的示例名称 USE CATALOG hdfshive; select * from target_table;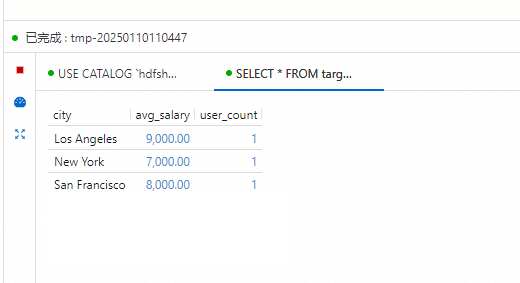
Hive Jar作业开发
当前VVP支持运行Hive方言作业通过Jar作业的形式运行。为了支持Jar作业运行,需要使用11.2版本及以上的"ververica-connector-hive-2.3.6" jar包,同时Jar作业中和VVP配置需要同步Hive相关配置。
VVP配置。
上传Jar作业Jar包在JAR Uri中。
附加依赖文件中上传hive集群中的四个配置:core-site.xml, mapred-site.xml, hdfs-site.xml和hive-site.xml文件。并上传"ververica-connector-hive-2.3.6" jar包。
运行参数配置。根据hive集群配置,若需写入oss-hdfs,可参照(可选)步骤五:配置作业运行参数的配置。
table.sql-dialect: HIVE classloader.parent-first-patterns.additional: org.apache.hadoop;org.antlr.runtime kubernetes.application-mode.classpath.include-user-jar: true
Jar作业写法示例。
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); Configuration conf = new Configuration(); conf.setString("type", "hive"); conf.setString("default-database", "default"); conf.setString("hive-version", "2.3.6"); conf.setString("hive-conf-dir", "/flink/usrlib/" ); conf.setString("hadoop-conf-dir", "/flink/usrlib/"); CatalogDescriptor descriptor = CatalogDescriptor.of("hivecat", conf); tableEnv.createCatalog("hivecat", descriptor); tableEnv.loadModule("hive", new HiveModule()); tableEnv.useModules("hive"); tableEnv.useCatalog("hivecat"); tableEnv.executeSql("insert into `hivecat`.`default`.`test_write` select * from `hivecat`.`default`.`test_read`;");
相关文档
Hive方言的INSERT语法,详情请参见INSERT Statements | Apache Flink。
使用Flink SQL数据批处理,详情请参见Flink批处理快速入门。