您可以对分片集群实例中的集合设置数据分片,以充分利用Shard节点的存储空间和计算性能。
背景信息
如果没有对集合设置数据分片,数据将被集中存放在一个Shard节点中,这将导致其他Shard节点的存储空间和计算性能无法被充分利用。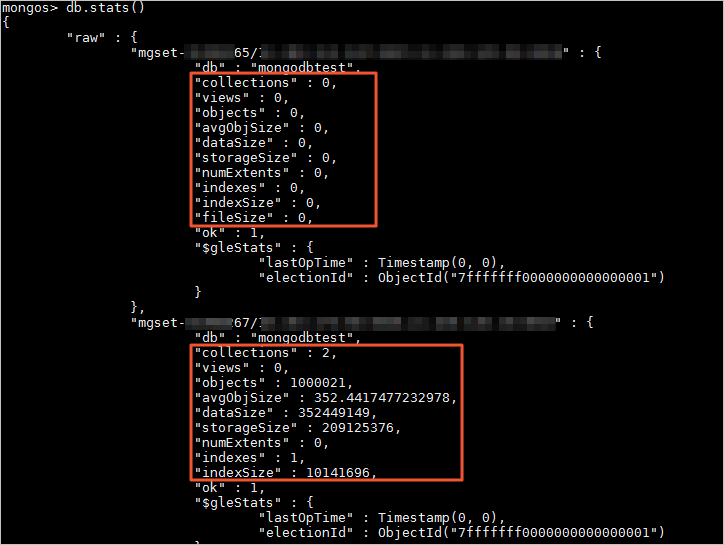
前提条件
实例类型为分片集群实例。
注意事项
MongoDB 对片键(Shard Key)的修改能力随着版本迭代不断增强:
4.4 版本以前:片键一旦设置,则固定不变,无法修改或删除。
从 4.4 版本开始:可以使用 refineCollectionShardKey 命令,通过为片键添加后缀字段的方式来优化它。
从 5.0 版本开始:引入了 reshardCollection 命令,支持完全更换一个集合的片键。
执行了数据分片操作后,均衡器会对满足条件的数据进行拆分,这将占用实例的资源,请在业务低峰期操作。
说明您可以在设置数据分片之前,调整均衡器的活动窗口,指定它在业务低峰期执行均衡操作。详情请参见设置Balancer的活动窗口。
片键的选取将影响分片集群实例的性能,关于片键选取的案例介绍,请参见如何选择Shard Key和Shard Keys。
分片策略介绍
分片策略 | 说明 | 适用场景 |
基于范围的分片 | MongoDB按照片键的值的范围将数据拆分为不同的块(chunk),每个块包含了一段范围内的数据。
| 片键的值不是单调递增或单调递减、片键的值基数大且重复的频率低、需要范围查询等业务场景。 |
基于Hash值的分片 | MongoDB计算单个字段的哈希值作为索引值,并以哈希值的范围将数据拆分为不同的块。
| 片键的值存在单调递增或递减、片键的值基数大且重复的频率低、需要写入的数据随机分发、数据读取随机性较大等业务场景。 |
除了上述两种分片策略,您还可以配置复合片键,例如由一个低基数的键和一个单调递增的键组成,详情请参见如何选择Shard Key。
操作步骤
本文以mongodbtest数据库,customer集合为例介绍操作流程。
对集合所在的数据库启用分片功能。
重要如果您的实例是MongoDB 6.0及以上版本,可跳过此步骤,更多信息,请参见sh.enableSharding()。
sh.enableSharding("<database>")参数说明:
<database>为数据库名。示例:
sh.enableSharding("mongodbtest")说明您可以通过
sh.status()查看分片状态。对片键的字段建立索引。
db.<collection>.createIndex(<keyPatterns>,<options>)参数说明:
<collection>:集合名。<keyPatterns>:包含用于建立索引的字段和索引类型。常见的索引类型如下:
1:创建升序索引
-1:创建降序索引
"hashed":创建哈希索引
<options>:表示接收可选参数,详情请参见db.collection.createIndex(),本操作示例中暂未使用到该字段。
创建升序索引示例:
db.customer.createIndex({name:1})创建哈希索引示例:
db.customer.createIndex({name:"hashed"})对集合设置数据分片。
sh.shardCollection("<database>.<collection>",{ "<key>":<value> } )参数说明:
<database>:数据库名。<collection>:集合名。<key>:分片的键,MongoDB将根据片键的值进行数据分片。<value>1:表示基于范围分片,通常能很好地支持基于片键的范围查询。
“hashed”:表示基于哈希分片,通常能将写入均衡分布到各Shard节点中。
基于范围分片的配置示例:
sh.shardCollection("mongodbtest.customer",{"name":1})基于哈希分片的配置示例:
sh.shardCollection("mongodbtest.customer",{"name":"hashed"})
后续操作
经过一段时间的运行或数据写入后,您可以在Mongo Shell中执行sh.status(),查看数据在各Shard节点中的分布信息。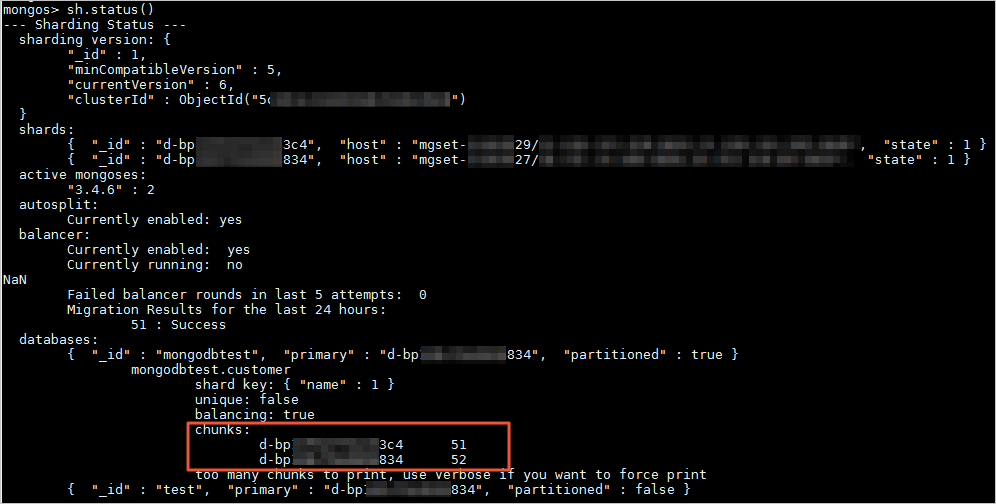
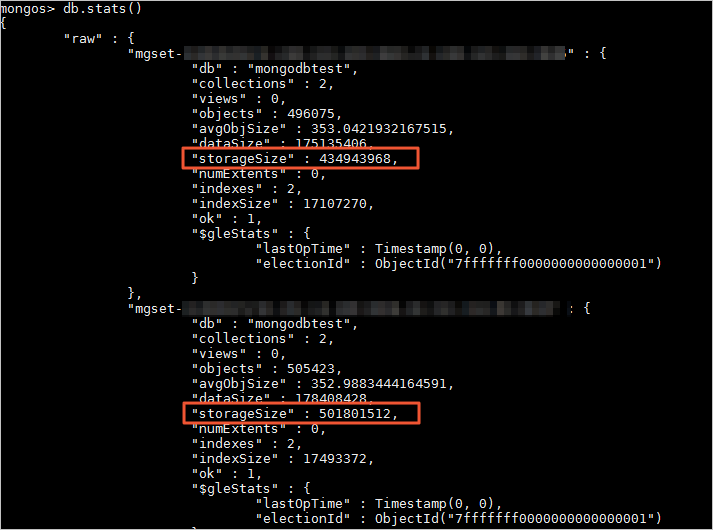
您也可以通过执行db.stats()查看该数据库在各Shard节点的数据存储情况。