
本文将介绍关于事务以及Read/Write Concern的最佳实践,帮助您更好地使用云数据库 MongoDB 版的事务以及Read/Write Concern功能。
背景信息
MongoDB 4.0版本支持了单机事务(副本集事务),可以在副本集内的一个或多个集合进行事务操作。MongoDB 4.2版本支持了分布式事务(分片事务),可以跨多个分片执行多个集合的不同文档事务操作。
在MongoDB中,对于对单个文档的操作,系统始终保证其原子性。由于MongoDB文档结构的灵活性,业务侧总是可以使用嵌入式文档和数组结构来构造联系更紧密的单个文档结构,而不是像传统关系型数据库那样创建多个符合范式规则的集合并进行交互查询或联合更新。所以对于许多MongoDB的实际应用场景,在合理的数据建模下,单文档原子性保证已经消除了对分布式事务的需求。
当然,一些特殊的应用场景(比如金融、会计等)依然对于分布式事务有着强烈的需求。在4.2以上版本完全支持分布式文档以后,MongoDB也可以很好地支持这部分需求。
事务
基础信息
MongoDB事务的使用和交互习惯与关系型数据库的事务基本一致,API使用方法也类似,无额外的学习成本。
以下示例为一个完整事务,您可以看到API(startTransaction/abortTransaction/commitTransaction)以及相关联的session和readConcern/writeConcern设置。
// 创建集合
db.getSiblingDB("mydb1").foo.insertOne(
{abc: 0},
{ writeConcern: { w: "majority", wtimeout: 2000 } }
)
db.getSiblingDB("mydb2").bar.insertOne(
{xyz: 0},
{ writeConcern: { w: "majority", wtimeout: 2000 } }
)
// 开启一个会话
session = db.getMongo().startSession( { readPreference: { mode: "primary" } } );
coll1 = session.getDatabase("mydb1").foo;
coll2 = session.getDatabase("mydb2").bar;
// 开启一个事务
session.startTransaction( { readConcern: { level: "local" }, writeConcern: { w: "majority" } } );
// 在事务中执行若干操作
try {
coll1.insertOne( { abc: 1 } );
coll2.insertOne( { xyz: 999 } );
} catch (error) {
// 遇到问题时中止事务
session.abortTransaction();
throw error;
}
// 提交事务
session.commitTransaction();
session.endSession();事务的使用说明如下:
事务需要与会话(session)关联,一个会话同一时间只能有一个未完成事务。如果会话结束,其关联的未完成事务也会回滚。
一个分布式事务可以同时包含对不同库表的不同文档的操作。
在事务执行期间,事务能够读取自己未提交的写操作,但事务外部的其他操作不会读取到事务中未提交的写操作。
在事务提交之前,不会将未提交的写入数据复制到从节点。一旦事务被提交,写入的数据将被复制并自动应用于所有副本集中的从节点。
在修改文档时,事务将锁定文档,使文档无法被其他操作更改,直至事务完成。如果一个事务无法获得它需要修改文档上的锁,可能是因为另一个事务已经持有该锁,那么该事务将在5毫秒后立即终止(该时间由maxTransactionLockRequestTimeoutMillis内核参数控制),并提示写冲突(WriteConflicts)。
事务有重试机制,如果遇到了暂时的可重试错误(比如网络临时中断),事务会自动重试。而且客户端对重试操作无感知。
事务有生命周期,运行超过60秒的事务将会被后台线程强制终止(该时间由transactionLifetimeLimitSeconds内核参数控制)。
使用限制
分布式事务不能创建新的集合和索引。
事务不能写入capped集合。
事务不能使用快照(snapshot)的Read Concern读取capped集合(该限制存在于MongoDB 5.0及以上版本)。
事务不能读写
config/admin/local库里的集合。事务不能写形如
system.*的系统库表。事务不支持
explain。事务无法通过
getMore读取事务外创建的游标;事务外也无法通过getMore读取事务内创建的游标。事务内的第一个操作不能为
killCursors/hello等。事务内无法执行非CURD的命令,包括
listCollections/listIndexes/createUser/getParameter/count等。分布式事务不支持将分片上的writeConcernMajorityJournalDefault参数设置为false。
分布式事务不支持带arbiters的分片。
最佳实践
优先考虑使用单机事务而不是分布式事务
在大多数场景下,分布式事务的性能要差于单机事务或不使用事务的写入,因为涉及到事务的操作需要有处理更多复杂场景的逻辑。在MongoDB中,非范式化的数据模型(指嵌入式文档和数组结构)仍然是您数据建模的最佳选择。合理的数据建模加单机事务完全可以处理绝大多数场景下应用的事务需求。
避免执行长事务
默认情况下,MongoDB将自动中止任何运行超过60秒的分布式事务。为了解决超时问题,您应该将事务分解为更小的部分,以便在配置的时间限制内执行。您还需要确保已经优化过查询语句,查询语句具有适当的索引覆盖率,以便在事务中快速地访问数据。
避免在一个事务中修改过多文档
在一个事务中可以读取的文档数量没有硬性限制,但修改的文档数量太多时可能会增加主从同步的压力,从而导致从节点数据同步落后或者其他问题。推荐在一个事务中修改的文档数量不超过1000。对于需要修改超过1000个文档的事务,建议您将该事务分解为分批处理文档的多个事务。
避免执行超大事务(超出16 MB)
在MongoDB 4.0中,事务用单个oplog条目表示,oplog条目大小必须在16 MB以内。MongoDB事务的更新操作仅在oplog中存储更新的增量内容(即更改的内容),而插入操作将存储整个文档。因此,事务中所有语句的oplog记录组合必须小于16 MB,如果超过这个限制,事务将被中止并完全回滚。建议您将超大事务分解为较小的操作集,这些操作集可以用16 MB或更少的空间表示。
从MongoDB 4.2起,MongoDB开始支持创建多个oplog条目来存储一个事务中的所有写操作,相当于消除了单个超大事务16MB限制。但是依然建议您将事务的大小控制在16 MB以内,过大的事务还可能引起其他问题。
客户端需要有合理处理事务回滚(abort)的逻辑
当事务异常中止时,将向驱动程序返回一个异常并回滚。您应该为应用程序添加捕获并重试因临时异常(如主从切换,节点故障等)而终止事务的逻辑。由于Retryable Writes机制,MongoDB驱动程序将自动重试事务的提交,但应用程序侧依然需要处理那些无法被自动重试机制处理的事务异常及错误,包括TransactionTooLarge、TransactionTooOld、TransactionExceededLifetimeLimitSeconds等错误。
避免在事务中执行任何DDL操作
DDL操作(如createIndex或dropDatabase)会被对应库表正在运行的活动事务所阻塞。当DDL操作被阻塞时,所有尝试访问相同库表的事务都将无法在限定时间内获得锁,从而导致新事务中止。
MongoDB 4.4及以后版本优化了相关限制(由shouldMultiDocTxnCreateCollectionAndIndexes参数控制),您可以在分布式事务中执行createCollection或createIndex操作,但上述操作依旧存在以下限制:
只能隐式创建。
只能对当前不存在的集合执行。
只能对空集合执行。
因此,建议您避免在事务中执行DDL操作。
尽可能早地主动回滚不打算提交的事务以及遇到报错的事务
所有未提交事务所涉及的修改都会驻留在WiredTiger引擎缓存中。如果系统中同时有好几个不打算提交的事务或遇到报错的事务,可能会导致WiredTiger引擎的缓存面临很大压力,进而引起其他问题。您应尽量控制事务操作的时长,尽早回滚不会提交的事务来释放资源。
若事务经常因为获取锁超时而回滚,可以适当调大相关超时参数
默认情况下,事务里的操作如果在5毫秒内获取不到需要的锁就会自动回滚。当一个事务回滚或者提交时,事务会释放所有占用的锁。如果经常遇到事务因为锁获取超时而回滚的情况,可以适当调大maxTransactionLockRequestTimeoutMillis参数的值来规避。
如果调大参数依然不能解决此问题,请您重新审视事务里的操作,检查事务中是否包含了可能会长时间占用锁的操作(比如DDL、待优化的查询),并对其进行优化。
尽量避免在事务内外同时修改同一文档而导致写冲突
如果事务正在进行,事务外部的写操作修改了一个文档,而事务中的操作也试图修改该文档,事务将由于写冲突(Write Conflicts)而回滚。如果事务正在进行,并且已经获取了修改文档需要的锁,那么当事务外部的写操作试图修改该文档时,外部写操作将会等待,直到事务结束。
发生写冲突时,事务外的写操作既不会失败也不会返回报错给客户端,MongoDB内部会不断重试并且在writeConflicts计数器上加一,直到成功为止。从客户端的视角来看,操作并没有异常,只是请求耗时比较久。
少量的写冲突一般不会产生很大影响,但是如果存在大量的写冲突,则有可能导致数据库性能退化。您可以通过审计日志或慢日志确认是否存在写冲突过多的问题。
内核缺陷风险说明
创建长时间运行的大事务,或者试图在单个事务中执行过多的操作,都会给WiredTiger存储引擎的缓存带来很大压力。因为自最早的已创建未提交事务起,WiredTiger缓存必须能为所有后续的写入维持相关数据和状态。由于事务在运行时使用相同的快照,因此,在整个事务运行期间,新的写操作会持续累积在WiredTiger缓存中。当前运行在旧快照上的事务在提交或中止之前,缓存中的这些写操作都不能被逐出。而长事务引起的WiredTiger缓存压力超载(wt cache使用率以及dirty使用率超阈值)通常会带来更多的问题,包括数据库卡顿、请求延时大幅增加、CPU使用率满等问题,甚至出现“死锁”,导致业务受损。更多关于内核风险的介绍,请参见SERVER-50365和SERVER-51281。
云数据库 MongoDB 版建议所有重度使用事务的业务都将MongoDB实例升级至5.0及以上的版本来规避相关风险和隐患。
Read Concern
基础信息
控制一致性和隔离级别的Read Concern包括以下几种:
"local":副本集架构下读主或从节点时的默认级别,从本地读取,可能会读到被回滚的数据。"available":分片集群架构下读从节点时的默认级别,可能读到会被回滚的数据。读数据前不会进行shardVersion的检查,因此可能读到孤立文档。优点是提供了最优的访问延迟。"majority":读取的是已被大多数节点确认的数据,即不会被回滚的数据。"linearizable":数据一致性要求最严格的线性化级别,读操作需要等待所有前序写入都已经被大多数节点确认。性能最差,只能在主节点上使用。"snapshot":基于快照读取,同样读取的是已被大多数节点确认的数据,只不过可以关联某一个特定时间点的快照,比如配合atClusterTime使用。
Read Concern的使用说明如下:
无论Read Concern的级别如何,某一个mongod节点上最新的数据都不代表副本集中最近版本的数据。
可以为不同的操作指定不同的Read Concern,4.4及以上版本也可以设置服务器端默认的Read Concern,操作的Read Concern优先级高于服务器端设置的Read Concern。
当读取
local库时,您指定的Read Concern会被忽略,您总是能在local库里读到所有本地数据。分布式事务里仅支持3种Read Concern级别,分别为
"local"、"majority"、"snapshot"。因果一致性会话里,必须使用
"majority"级别的Read Concern。
最佳实践
对于分布式事务,只需设置事务的Read Concern,无需设置事务里每个操作
不需要为事务里的每个操作指定Read Concern。事务级别的Read Concern会覆盖其他地方设置或默认的Read Concern。
与Write Concern一样,Read Concern可以应用于对数据库执行的任何查询,而不管操作是对单个或一组文档进行常规读取,还是封装在多文档读取事务中。
一般场景尽量使用"majority"级别的Read Concern
为了确保隔离和一致性,建议将Read Concern级别设置为"majority",只有当数据被复制到副本集中的大多数节点时,应用程序才能读取到该数据,因此在选举新的主节点时,数据不会回滚。
Read Your Own Write的场景需要读主并使用"local"或"linearizable"级别的Read Concern
为了能在写操作完成后能尽快读到写入的修改,需要读主并使用"local"或"linearizable"的Read Concern。当配套的Write Concern为"majority"时,也可以使用"majority"的Read Concern。
从MongoDB 3.6版本开始,您也可以使用因果一致性会话来满足此场景。
一致性要求最强的场景需要配套maxTimeMS超时来使用"linearizable"的Read Concern
级别为"linearizable"的Read Concern可以确保在读取时节点仍然是副本集的主节点,并且如果随后另一个节点被选为新的主节点,则它返回的数据不会被回滚。而这个级别会对延迟产生重大影响,因此需要配套使用maxTimeMS超时来避免大多数节点不可用的情况下读操作被无限期地阻塞。
Write Concern
基础信息
指定Write Concern的格式如下。关于Write Concern的更多介绍,请参见Write Concern。
{ w: <value>, j: <boolean>, wtimeout: <number> }控制数据持久化保证级别的Write Concern可以简单分为以下几种主要级别:
{w: 0}:表示写(write)不确认,不确认写操作是否完成,可能发生写入数据丢失。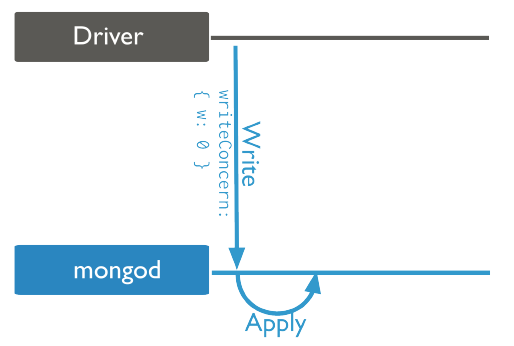
{w: 1}:表示写(write)确认,为MongoDB 5.0版本以前的默认行为。确认写操作在内存中已完成,但由于还没有持久化,依然可能发生数据丢失。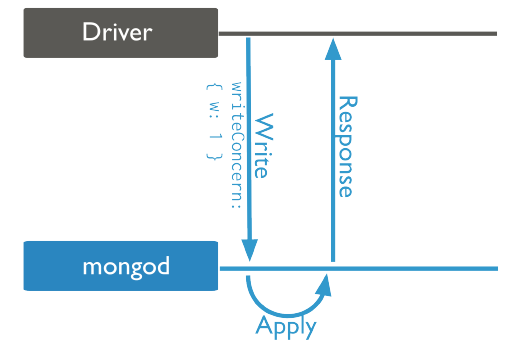
{j: true}:表示日志(journal)确认。确认写操作已完成并刷到持久化存储的WAL中,写操作不会丢失。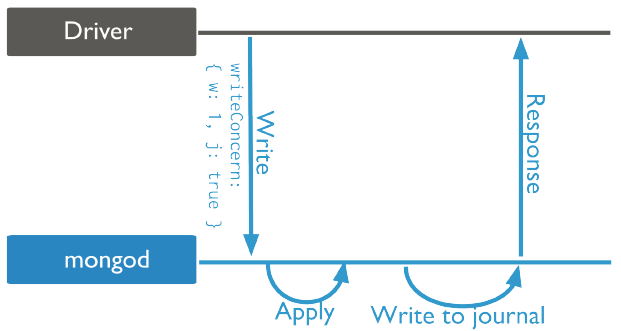
{ w: "majority" }:表示大多数(majority),为MongoDB 5.0及以上版本的默认行为。等待写操作被复制到副本集中大多数节点上后才确认,数据不会被回滚。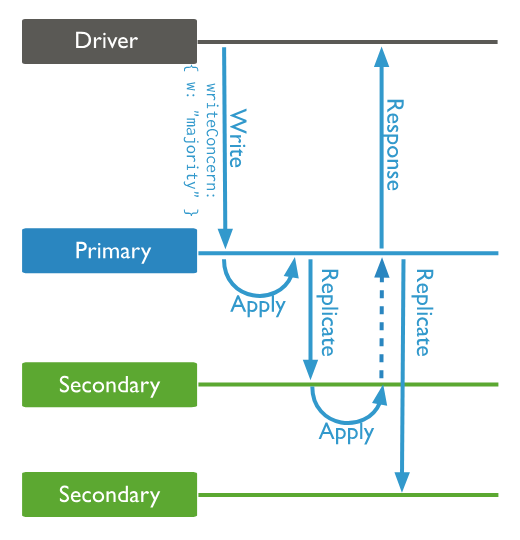
副本确认:等待写操作被复制到副本集中指定数量的节点上后才确认。
自定义确认:可以通过settings.getLastErrorModes参数指定其他自定义的带tag确认方式。
Write Concern的使用说明如下:
您可以在任何写操作或者事务中指定Write Concern,未显示指定时会使用默认值。
说明从MongoDB 5.0版本开始,标准3副本拓扑结构下,默认的全局Write Concern已经从之前的
{w:1}调整为{w:"majority"}。这可能会导致您将数据库版本升级至5.0及以上版本后出现性能退化问题。副本集中的隐藏(Hidden)节点、延迟(Delayed)节点、或其他优先级为0的可投票节点均可以视为
"majority"中的一员。您可以为不同的操作指定不同的Write Concern,4.4及以上版本也可以设置服务器端默认的Write Concern,操作的Write Concern优先级高于服务器端设置的Write Concern。
当写入
local库时,您指定的Write Concern会被忽略。因果一致性会话里,必须使用
"majority"的Write Concern。
最佳实践
对于分布式事务而言,只需设置事务的Write Concern,无需设置事务里每个操作
为事务内的各个写入操作设置Write Concern会返回错误。
一般场景尽量使用"majority"的Write Concern
“majority”的Write Concern可以确保副本集中大部分节点已经确认写入操作,即便此时发生节点故障或异常切换也不会产生数据丢失或者回滚的风险。
对写入性能要求高的情况酌情考虑使用{w:1}的Write Concern,并关注从节点复制延迟
{w:1}的Write Concern通常能带来更好的写入性能,适合重写入的场景。但应合理关注监控中的从节点复制延迟,当延迟过大时可能会出现主节点异常ROLLBACK的问题。而且当复制延迟超过了oplog的保留时长后,从节点将进入异常的RECOVERING状态且无法自愈,降低实例可用性,应优先关注并处理。
云数据库 MongoDB 版5.0以下版本进行批量灌数据或DTS迁移时可能会遇到上述延迟过大出现异常的问题,出现该问题时,建议您使用"majority"的Write Concern。
对于不同操作设置最适合的Write Concern
Write Concern可以在单个操作的粒度上进行设置。业务侧可以根据实际操作的需要来设置不同的Write Concern。比如金融交易数据使用带Write Concern的事务来确保原子性;核心玩家数据使用"majority"的Write Concern确保不会被回滚;日志数据使用默认或者{w:1}的Write Concern即可。
MongoDB在设计上为开发者提供了极强的灵活性,让不同的业务都可以根据自己的需要来设置合理的选项。